FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&A
Pith reviewed 2026-06-27 20:45 UTC · model grok-4.3
The pith
Min-cost flow on a multimodal graph assembles fragmented evidence from long documents into answer paths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
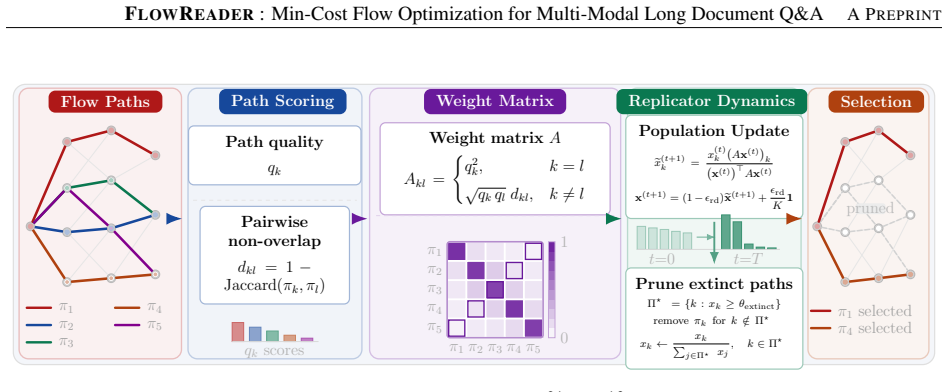
FLOWREADER reframes evidence assembly as a min-cost flow problem on a multimodal node graph: a single scoring vector h controls source selection via MMR, sink selection via a length-aware answerability proxy, and the costs and capacities of every edge. The optimal flow is decomposed into candidate evidence paths, a compact non-redundant subset is selected by entropy-regularized replicator dynamics, and parallel VLM workers under a dual-process gate produce the answer with a single System-2 refinement pass triggered when answer consistency is low or the routed flow is strained. On VisDoMBench it is strongest on the fragmented-evidence subsets PaperTab and SlideVQA and competitive on the remai
What carries the argument
Min-cost flow on a multimodal node graph whose single scoring vector h jointly governs source selection, sink selection, edge costs, and capacities.
If this is right
- Min-cost flow yields connected evidence paths that top-k retrieval misses on documents with evidence split across modalities.
- A single vector unifies control of scoring, routing, selection, and adaptive compute in one optimization.
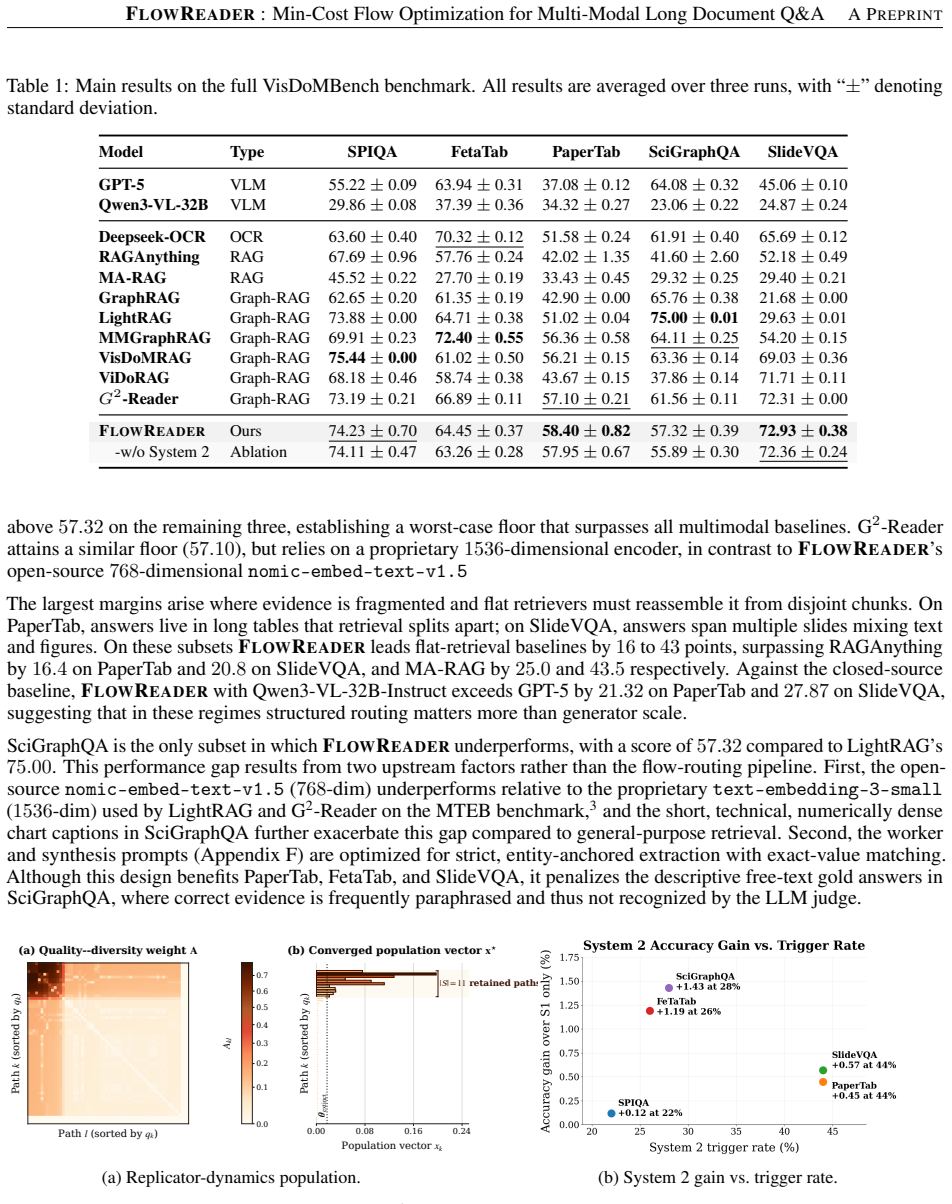
- Performance gains concentrate on the two subsets whose evidence is most fragmented (PaperTab +1.30, SlideVQA +0.62).
- The overall macro-average remains within 0.74 of the strongest baseline while adding explicit path connectivity.
Where Pith is reading between the lines
- The same flow formulation could be applied to any retrieval setting where evidence must be chained rather than ranked independently, such as multi-hop question answering over knowledge graphs.
- The dual-process gate offers a concrete mechanism for trading compute against answer consistency that could be tested on other generative retrieval pipelines.
- Because the graph construction and flow objective are modality-agnostic, the approach could be extended to additional input types such as audio transcripts or video keyframes without redesigning the optimizer.
Load-bearing premise
One scoring vector can simultaneously and effectively set source selection, sink selection, and all edge costs and capacities so that the resulting flow produces useful evidence paths.
What would settle it
A controlled experiment that replaces the min-cost flow step with independent top-k selection on the identical multimodal graph and measures whether accuracy on the fragmented subsets drops, stays the same, or rises.
Figures

read the original abstract
Long, multimodal documents force retrieval-augmented systems to assemble answers from evidence fragmented across text, tables, and slides broken across cells in a long table, spread over multiple slides, or split between a figure and its discussion. Top-$k$ chunk retrieval treats each fragment independently and cannot represent how evidence connects. We introduce FLOWREADER, which reframes evidence assembly as a min-cost flow problem on a multimodal node graph: a single scoring vector $h$ controls source selection (via MMR), sink selection (via a length-aware answerability proxy), and the costs and capacities of every edge. The optimal flow is decomposed into candidate evidence paths, a compact non-redundant subset is selected by entropy-regularized replicator dynamics, and parallel VLM workers under a dual-process gate produce the answer with a single System-2 refinement pass triggered when answer consistency is low or the routed flow is strained. On VisDoMBench, FLOWREADER is best on the two subsets dominated by fragmented evidence PaperTab ($58.40$, $+1.30$ over G^{2}-Reader) and SlideVQA ($72.93$, $+0.62$) and competitive on SPIQA, FetaTab, and SciGraphQA. Macro-averaged across all five subsets, FLOWREADER ($65.47$) is within $0.74$ of the strongest baseline (G^{2}-Reader, $66.21$). Overall, these results show that min-cost flow performs well on fragmented multimodal evidence, where top-$k$ retrieval fails. It also provides a unified way to control scoring, routing, selection, and adaptive compute together.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FLOWREADER, which models evidence assembly for long multimodal documents as a min-cost flow problem on a multimodal node graph. A single scoring vector h jointly controls source selection via MMR, sink selection via length-aware answerability, and all edge costs/capacities. Optimal flow is decomposed into paths, a subset selected via entropy-regularized replicator dynamics, and answers generated by parallel VLM workers with a dual-process gate for refinement. On VisDoMBench, it reports best results on PaperTab (58.40, +1.30 over G²-Reader) and SlideVQA (72.93, +0.62), competitive elsewhere, with macro-average 65.47 within 0.74 of the top baseline.
Significance. If the joint parameterization of the flow network by h is shown to be stable and the flow mechanism demonstrably responsible for gains on fragmented-evidence subsets, the work would provide a unified optimization framework for retrieval, diversity, connectivity, and adaptive computation in multimodal RAG, addressing a clear limitation of independent top-k chunking.
major comments (2)
- [Abstract] Abstract: The central claim attributes the +1.30 and +0.62 gains on PaperTab and SlideVQA specifically to min-cost flow whose source (MMR), sink (length-aware answerability), and all edge costs/capacities are controlled by one vector h. No equations, loss, or optimization procedure are supplied showing that a single h can satisfy these constraints simultaneously without unacceptable trade-offs (e.g., MMR-driven diversity inflating cross-modal edge costs). This joint-control assumption is load-bearing for the reported improvements over top-k baselines.
- [Abstract] Abstract: The manuscript states that flow decomposition plus replicator selection yields useful evidence paths on fragmented subsets, yet supplies neither the explicit capacity/cost definitions in terms of h nor any ablation isolating the flow component from the dual-process gate or VLM workers. Without these, it is impossible to verify that the optimization, rather than other modules, drives the subset-specific gains.
minor comments (2)
- [Abstract] Abstract: Benchmark deltas are reported without error bars, number of runs, or statistical significance tests, which is standard for claiming superiority on specific subsets.
- [Abstract] Abstract: The phrase 'parameter-free' is not used, but the claim of unified control by a single h would benefit from explicit statement of whether h is learned or hand-tuned and how its dimensionality relates to the graph size.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the two major comments point by point below and will revise the manuscript accordingly to supply the requested technical details.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim attributes the +1.30 and +0.62 gains on PaperTab and SlideVQA specifically to min-cost flow whose source (MMR), sink (length-aware answerability), and all edge costs/capacities are controlled by one vector h. No equations, loss, or optimization procedure are supplied showing that a single h can satisfy these constraints simultaneously without unacceptable trade-offs (e.g., MMR-driven diversity inflating cross-modal edge costs). This joint-control assumption is load-bearing for the reported improvements over top-k baselines.
Authors: We agree that the abstract does not contain equations or the optimization procedure. The abstract is space-constrained, but the joint-control claim requires clearer support. In revision we will expand the abstract (or add a short methods summary) to state how the single vector h simultaneously parameterizes MMR source scores, length-aware sink scores, and all edge costs/capacities, and we will briefly describe the min-cost flow objective and solver used. We will also add a short paragraph discussing why the formulation avoids unacceptable trade-offs (the global cost minimization couples the terms rather than treating them independently). revision: yes
-
Referee: [Abstract] Abstract: The manuscript states that flow decomposition plus replicator selection yields useful evidence paths on fragmented subsets, yet supplies neither the explicit capacity/cost definitions in terms of h nor any ablation isolating the flow component from the dual-process gate or VLM workers. Without these, it is impossible to verify that the optimization, rather than other modules, drives the subset-specific gains.
Authors: We accept that explicit capacity/cost definitions in terms of h and an isolating ablation are not present at the level of detail needed. In the revision we will (1) state the precise functional forms mapping h to edge capacities and costs, and (2) add a targeted ablation that removes or replaces the min-cost flow module while keeping the dual-process gate and VLM workers fixed, reporting results on the fragmented-evidence subsets. This will allow direct verification of the flow component's contribution. revision: yes
Circularity Check
No circularity: empirical method with external optimization and benchmark evaluation
full rationale
The paper presents FLOWREADER as a min-cost flow formulation on a multimodal graph controlled by scoring vector h, with flow decomposition and replicator selection, evaluated empirically on VisDoMBench subsets. No equations, self-citations, or derivations are provided that reduce the method definition or performance claims to fitted inputs or self-referential quantities by construction. The central results are comparative scores against external baselines rather than tautological predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Procedures for synthesizing ratio judgements.Journal of mathematical Psychology, 27(1):93–102, 1983
Janos Aczél and Thomas L Saaty. Procedures for synthesizing ratio judgements.Journal of mathematical Psychology, 27(1):93–102, 1983
1983
-
[2]
Large language models hallucination: A comprehensive survey.Computer Science Review, 61:100970, 2026
Aisha Alansari and Hamzah Luqman. Large language models hallucination: A comprehensive survey.Computer Science Review, 61:100970, 2026
2026
-
[3]
Entropy driven transformations of statistical hypersurfaces.Reviews in Mathematical Physics, 33(02):2150001, 2021
Mario Angelelli and Boris Konopelchenko. Entropy driven transformations of statistical hypersurfaces.Reviews in Mathematical Physics, 33(02):2150001, 2021
2021
-
[4]
Self-rag: Learning to retrieve, gener- ate, and critique through self-reflection
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. Self-rag: Learning to retrieve, gener- ate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[5]
Injecting the bm25 score as text improves bert-based re-rankers
Arian Askari, Amin Abolghasemi, Gabriella Pasi, Wessel Kraaij, and Suzan Verberne. Injecting the bm25 score as text improves bert-based re-rankers. InEuropean Conference on Information Retrieval, pages 66–83. Springer, 2023. 4https://www.hpc.cineca.it 9 FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&AA PREPRINT
2023
-
[6]
Relative entropy in biological systems.Entropy, 18(2):46, 2016
John C Baez and Blake S Pollard. Relative entropy in biological systems.Entropy, 18(2):46, 2016
2016
-
[7]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
Pith/arXiv arXiv 2025
-
[8]
Approximating the maximum weight clique using replicator dynamics.IEEE Transactions on neural networks, 11(6):1228–1241, 2000
IR Bomze, Marcello Pelillo, and V olker Stix. Approximating the maximum weight clique using replicator dynamics.IEEE Transactions on neural networks, 11(6):1228–1241, 2000
2000
-
[9]
The use of mmr, diversity-based reranking for reordering documents and producing summaries
Jaime Carbonell and Jade Goldstein. The use of mmr, diversity-based reranking for reordering documents and producing summaries. InProceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval, pages 335–336, 1998
1998
-
[10]
Dualrag: A dual-process approach to integrate reasoning and retrieval for multi-hop question answering
Rong Cheng, Jinyi Liu, Yan Zheng, Fei Ni, Jiazhen Du, Hangyu Mao, Fuzheng Zhang, Bo Wang, and Jianye Hao. Dualrag: A dual-process approach to integrate reasoning and retrieval for multi-hop question answering. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 31877–31899, 2025
2025
-
[11]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production- ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413, 2025
Pith/arXiv arXiv 2025
-
[12]
M3docvqa: Multi-modal multi-page multi-document understanding
Jaemin Cho, Debanjan Mahata, Ozan Irsoy, Yujie He, and Mohit Bansal. M3docvqa: Multi-modal multi-page multi-document understanding. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 6178–6188, 2025
2025
-
[13]
Improving the similarity measure of determinantal point processes for extractive multi-document summarization
Sangwoo Cho, Logan Lebanoff, Hassan Foroosh, and Fei Liu. Improving the similarity measure of determinantal point processes for extractive multi-document summarization. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 1027–1038, 2019
2019
-
[14]
Yun-Wei Chu, Kai Zhang, Christopher Malon, and Martin Renqiang Min. Reducing hallucinations of medical multimodal large language models with visual retrieval-augmented generation.arXiv preprint arXiv:2502.15040, 2025
arXiv 2025
-
[15]
Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport.Advances in neural information processing systems, 26, 2013
2013
-
[16]
A dataset of information- seeking questions and answers anchored in research papers
Pradeep Dasigi, Kyle Lo, Iz Beltagy, Arman Cohan, Noah A Smith, and Matt Gardner. A dataset of information- seeking questions and answers anchored in research papers. InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 4599–4610, 2021
2021
-
[17]
Mc-indexing: Effective long document retrieval via multi-view content-aware indexing
Kuicai Dong, Derrick Goh Xin Deik, Yi Quan Lee, Hao Zhang, Xiangyang Li, Cong Zhang, and Yong Liu. Mc-indexing: Effective long document retrieval via multi-view content-aware indexing. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 2673–2691, 2024
2024
-
[18]
Yaxin Du, Junru Song, Yifan Zhou, Cheng Wang, Jiahao Gu, Zimeng Chen, Menglan Chen, Wen Yao, Yang Yang, Ying Wen, et al. g2-Reader: Dual Evolving Graphs for Multimodal Document Comprehension.arXiv preprint arXiv:2601.22055, 2026
arXiv 2026
-
[19]
Meaningful environmental indices: a social choice approach.Journal of Environ- mental Economics and Management, 47(2):270–283, 2004
Udo Ebert and Heinz Welsch. Meaningful environmental indices: a social choice approach.Journal of Environ- mental Economics and Management, 47(2):270–283, 2004
2004
-
[20]
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
Pith/arXiv arXiv 2024
-
[21]
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models.arXiv preprint arXiv:2407.01449, 2024
Pith/arXiv arXiv 2024
-
[22]
A scalable global model for summarization
Dan Gillick and Benoit Favre. A scalable global model for summarization. InProceedings of the workshop on integer linear programming for natural language processing, pages 10–18, 2009
2009
-
[23]
A decomposition theorem for dynamic flows.arXiv preprint arXiv:2407.04761, 2024
Lukas Graf, Tobias Harks, and Julian Schwarz. A decomposition theorem for dynamic flows.arXiv preprint arXiv:2407.04761, 2024
arXiv 2024
-
[24]
Dior: Adaptive cognitive detection and contextual retrieval optimization for dynamic retrieval-augmented generation
Hanghui Guo, Jia Zhu, Shimin Di, Weijie Shi, Zhangze Chen, and Jiajie Xu. Dior: Adaptive cognitive detection and contextual retrieval optimization for dynamic retrieval-augmented generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2953–2975, 2025
2025
-
[25]
Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024. 10 FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&AA PREPRINT
Pith/arXiv arXiv 2024
-
[26]
Rag-anything: All-in-one rag framework
Zirui Guo, Xubin Ren, Lingrui Xu, Jiahao Zhang, and Chao Huang. Rag-anything: All-in-one rag framework. arXiv preprint arXiv:2510.12323, 2025
arXiv 2025
-
[27]
Hipporag: Neurobiologically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532– 59569, 2024
Bernal J Gutiérrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models.Advances in neural information processing systems, 37:59532– 59569, 2024
2024
-
[28]
Topic-sensitive pagerank
Taher H Haveliwala. Topic-sensitive pagerank. InProceedings of the 11th international conference on World Wide Web, pages 517–526, 2002
2002
-
[29]
Soft quality-diversity optimization.arXiv preprint arXiv:2512.00810, 2025
Saeed Hedayatian and Stefanos Nikolaidis. Soft quality-diversity optimization.arXiv preprint arXiv:2512.00810, 2025
arXiv 2025
-
[30]
Enhancing the precision and interpretability of retrieval-augmented generation (rag) in legal technology: A survey.IEEE Access, 2025
Mahd Hindi, Linda Mohammed, Ommama Maaz, and Abdulmalik Alwarafy. Enhancing the precision and interpretability of retrieval-augmented generation (rag) in legal technology: A survey.IEEE Access, 2025
2025
-
[31]
Cog-rag: Cognitive-inspired dual-hypergraph with theme alignment retrieval-augmented generation
Hao Hu, Yifan Feng, Ruoxue Li, Rundong Xue, Xingliang Hou, Zhiqiang Tian, Yue Gao, and Shaoyi Du. Cog-rag: Cognitive-inspired dual-hypergraph with theme alignment retrieval-augmented generation. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 31032–31040, 2026
2026
-
[32]
Uda: A benchmark suite for retrieval augmented generation in real-world document analysis.Advances in Neural Information Processing Systems, 37:67200–67217, 2024
Yulong Hui, Yao Lu, and Huanchen Zhang. Uda: A benchmark suite for retrieval augmented generation in real-world document analysis.Advances in Neural Information Processing Systems, 37:67200–67217, 2024
2024
-
[33]
Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity
Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Ju Hwang, and Jong C Park. Adaptive-rag: Learning to adapt retrieval-augmented large language models through question complexity. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 7036–...
2024
-
[34]
Active retrieval augmented generation
Zhengbao Jiang, Frank F Xu, Luyu Gao, Zhiqing Sun, Qian Liu, Jane Dwivedi-Yu, Yiming Yang, Jamie Callan, and Graham Neubig. Active retrieval augmented generation. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 7969–7992, 2023
2023
-
[35]
Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, 2012
Alex Kulesza and Ben Taskar. Determinantal point processes for machine learning.Foundations and Trends® in Machine Learning, 5(2-3):123–286, 2012
2012
-
[36]
From word embeddings to document distances
Matt Kusner, Yu Sun, Nicholas Kolkin, and Kilian Weinberger. From word embeddings to document distances. In International conference on machine learning, pages 957–966. PMLR, 2015
2015
-
[37]
Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
2020
-
[38]
Smart-rag: Selection using determinantal matrices for augmented retrieval
Jiatao Li, Xinyu Hu, and Xiaojun Wan. Smart-rag: Selection using determinantal matrices for augmented retrieval. arXiv preprint arXiv:2409.13992, 2024
arXiv 2024
-
[39]
Graphreader: Building graph-based agent to enhance long-context abilities of large language models
Shilong Li, Yancheng He, Hangyu Guo, Xingyuan Bu, Ge Bai, Jie Liu, Jiaheng Liu, Xingwei Qu, Yangguang Li, Wanli Ouyang, et al. Graphreader: Building graph-based agent to enhance long-context abilities of large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 12758–12786, 2024
2024
-
[40]
Reasoning rag via system 1 or system 2: A survey on reasoning agentic retrieval-augmented generation for industry challenges
Jintao Liang, Huifeng Lin, You Wu, Rui Zhao, Ziyue Li, et al. Reasoning rag via system 1 or system 2: A survey on reasoning agentic retrieval-augmented generation for industry challenges. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computa...
1954
-
[41]
Multi-document summarization via budgeted maximization of submodular functions
Hui Lin and Jeff Bilmes. Multi-document summarization via budgeted maximization of submodular functions. In Human Language Technologies: The 2010 Annual conference of the North American chapter of the association for computational linguistics, pages 912–920, 2010
2010
-
[42]
A class of submodular functions for document summarization
Hui Lin and Jeff Bilmes. A class of submodular functions for document summarization. InProceedings of the 49th annual meeting of the association for computational linguistics: human language technologies, pages 510–520, 2011
2011
-
[43]
A study of global inference algorithms in multi-document summarization
Ryan McDonald. A study of global inference algorithms in multi-document summarization. InEuropean conference on information retrieval, pages 557–564. Springer, 2007
2007
-
[44]
Siyuan Meng, Junming Liu, Yirong Chen, Song Mao, Pinlong Cai, Guohang Yan, Botian Shi, and Ding Wang. From ranking to selection: A simple but efficient dynamic passage selector for retrieval augmented generation. arXiv preprint arXiv:2508.09497, 2025
arXiv 2025
-
[45]
Fetaqa: Free-form table question answering.Transactions of the Association for Computational Linguistics, 10:35–49, 2022
Linyong Nan, Chiachun Hsieh, Ziming Mao, Xi Victoria Lin, Neha Verma, Rui Zhang, Wojciech Kry ´sci´nski, Hailey Schoelkopf, Riley Kong, Xiangru Tang, et al. Fetaqa: Free-form table question answering.Transactions of the Association for Computational Linguistics, 10:35–49, 2022. 11 FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&AA PREPRINT
2022
-
[46]
Thang Nguyen, Peter Chin, and Yu-Wing Tai. Ma-rag: Multi-agent retrieval-augmented generation via collabora- tive chain-of-thought reasoning.arXiv preprint arXiv:2505.20096, 2025
arXiv 2025
-
[47]
Morris, Brandon Duderstadt, and Andriy Mulyar
Zach Nussbaum, John X. Morris, Brandon Duderstadt, and Andriy Mulyar. Nomic embed: Training a reproducible long context text embedder, 2024
2024
-
[48]
Massimiliano Pavan and Marcello Pelillo. Dominant sets and pairwise clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(1):167–172, 2007. doi: 10.1109/TPAMI.2007.250608
-
[49]
Replicator equations, maximal cliques, and graph isomorphism.Advances in Neural Information Processing Systems, 11, 1998
Marcello Pelillo. Replicator equations, maximal cliques, and graph isomorphism.Advances in Neural Information Processing Systems, 11, 1998
1998
-
[50]
Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
Shraman Pramanick, Rama Chellappa, and Subhashini Venugopalan. Spiqa: A dataset for multimodal question answering on scientific papers.Advances in Neural Information Processing Systems, 37:118807–118833, 2024
2024
-
[51]
Measuring and narrowing the compositionality gap in language models
Ofir Press, Muru Zhang, Sewon Min, Ludwig Schmidt, Noah A Smith, and Mike Lewis. Measuring and narrowing the compositionality gap in language models. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5687–5711, 2023
2023
-
[52]
Pairwise interactions origin of entropy functions.arXiv preprint arXiv:1506.05731, 2015
Yuri Pykh. Pairwise interactions origin of entropy functions.arXiv preprint arXiv:1506.05731, 2015
Pith/arXiv arXiv 2015
-
[53]
Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Preston Rasmussen, Pavlo Paliychuk, Travis Beauvais, Jack Ryan, and Daniel Chalef. Zep: a temporal knowledge graph architecture for agent memory.arXiv preprint arXiv:2501.13956, 2025
Pith/arXiv arXiv 2025
-
[54]
Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval
Stephen E Robertson and Steve Walker. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. InSIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University, pages 232–241. Springer, 1994
1994
-
[55]
Motor: Multimodal optimal transport via grounded retrieval in medical visual question answering
Mai A Shaaban, Tausifa Jan Saleem, Vijay Ram Kumar Papineni, and Mohammad Yaqub. Motor: Multimodal optimal transport via grounded retrieval in medical visual question answering. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 459–469. Springer, 2025
2025
-
[56]
Enhancing retrieval- augmented large language models with iterative retrieval-generation synergy
Zhihong Shao, Yeyun Gong, Yelong Shen, Minlie Huang, Nan Duan, and Weizhu Chen. Enhancing retrieval- augmented large language models with iterative retrieval-generation synergy. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 9248–9274, 2023
2023
-
[57]
Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
-
[58]
Large language model reasoning failures.Transactions on Machine Learning Research
Peiyang Song, Pengrui Han, and Noah Goodman. Large language model reasoning failures.Transactions on Machine Learning Research
-
[59]
A robust optimization approach to flow decomposi- tion.arXiv preprint arXiv:2410.21140, 2024
Moritz Stinzendörfer, Philine Schiewe, and Fabricio Oliveira. A robust optimization approach to flow decomposi- tion.arXiv preprint arXiv:2410.21140, 2024
Pith/arXiv arXiv 2024
-
[60]
Penglei Sun, Yixiang Chen, Xiang Li, and Xiaowen Chu. The multi-round diagnostic rag framework for emulating clinical reasoning.arXiv preprint arXiv:2504.07724, 2025
arXiv 2025
-
[61]
Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation
Manan Suri, Puneet Mathur, Franck Dernoncourt, Kanika Goswami, Ryan A Rossi, and Dinesh Manocha. Visdom: Multi-document qa with visually rich elements using multimodal retrieval-augmented generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Vo...
2025
-
[62]
Slidevqa: A dataset for document visual question answering on multiple images
Ryota Tanaka, Kyosuke Nishida, Kosuke Nishida, Taku Hasegawa, Itsumi Saito, and Kuniko Saito. Slidevqa: A dataset for document visual question answering on multiple images. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 13636–13645, 2023
2023
-
[63]
Otextsum: Extractive text summarisa- tion with optimal transport
Peggy Tang, Kun Hu, Rui Yan, Lei Zhang, Junbin Gao, and Zhiyong Wang. Otextsum: Extractive text summarisa- tion with optimal transport. InFindings of the Association for Computational Linguistics: NAACL 2022, pages 1128–1141, 2022
2022
-
[64]
Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions
Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Interleaving retrieval with chain-of-thought reasoning for knowledge-intensive multi-step questions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 10014–10037, 2023
2023
-
[65]
Xueyao Wan and Hang Yu. Mmgraphrag: Bridging vision and language with interpretable multimodal knowledge graphs.arXiv preprint arXiv:2507.20804, 2025
arXiv 2025
-
[66]
Bin Wang, Chao Xu, Xiaomeng Zhao, Linke Ouyang, Fan Wu, Zhiyuan Zhao, Rui Xu, Kaiwen Liu, Yuan Qu, Fukai Shang, et al. Mineru: An open-source solution for precise document content extraction.arXiv preprint arXiv:2409.18839, 2024. 12 FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&AA PREPRINT
Pith/arXiv arXiv 2024
-
[67]
Vidorag: Visual document retrieval-augmented generation via dynamic iterative reasoning agents
Qiuchen Wang, Ruixue Ding, Zehui Chen, Weiqi Wu, Shihang Wang, Pengjun Xie, and Feng Zhao. Vidorag: Visual document retrieval-augmented generation via dynamic iterative reasoning agents. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 9124–9145, 2025
2025
-
[68]
Document segmentation matters for retrieval-augmented generation
Zhitong Wang, Cheng Gao, Chaojun Xiao, Yufei Huang, Shuzheng Si, Kangyang Luo, Yuzhuo Bai, Wenhao Li, Tangjian Duan, Chuancheng Lv, et al. Document segmentation matters for retrieval-augmented generation. In Findings of the Association for Computational Linguistics: ACL 2025, pages 8063–8075, 2025
2025
-
[69]
Zilong Wang, Zifeng Wang, Long Le, Huaixiu Steven Zheng, Swaroop Mishra, Vincent Perot, Yuwei Zhang, Anush Mattapalli, Ankur Taly, Jingbo Shang, et al. Speculative rag: Enhancing retrieval augmented generation through drafting.arXiv preprint arXiv:2407.08223, 2024
arXiv 2024
-
[70]
Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
Haoran Wei, Yaofeng Sun, and Yukun Li. Deepseek-ocr: Contexts optical compression.arXiv preprint arXiv:2510.18234, 2025
Pith/arXiv arXiv 2025
-
[71]
Weibull.Evolutionary Game Theory
Jörgen W. Weibull.Evolutionary Game Theory. MIT Press, Cambridge, MA, 1995
1995
-
[72]
Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, and Huaxiu Yao. Mmed-rag: Versatile multimodal rag system for medical vision language models.arXiv preprint arXiv:2410.13085, 2024
arXiv 2024
-
[73]
Knowledge conflicts for llms: A survey
Rongwu Xu, Zehan Qi, Zhijiang Guo, Cunxiang Wang, Hongru Wang, Yue Zhang, and Wei Xu. Knowledge conflicts for llms: A survey. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8541–8565, 2024
2024
-
[74]
A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents.arXiv preprint arXiv:2502.12110, 2025
Pith/arXiv arXiv 2025
-
[75]
Efficient algorithms for personalized pagerank computation: A survey.IEEE Transactions on Knowledge and Data Engineering, 36(9):4582–4602, 2024
Mingji Yang, Hanzhi Wang, Zhewei Wei, Sibo Wang, and Ji-Rong Wen. Efficient algorithms for personalized pagerank computation: A survey.IEEE Transactions on Knowledge and Data Engineering, 36(9):4582–4602, 2024
2024
-
[76]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
-
[77]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented generation on multi-modality documents. InThe Thirteenth International Conference on Learning Representations
-
[78]
Tian Yu, Shaolei Zhang, and Yang Feng. Auto-rag: Autonomous retrieval-augmented generation for large language models.arXiv preprint arXiv:2411.19443, 2024
arXiv 2024
-
[79]
keywords:
Hamed Zamani and Michael Bendersky. Stochastic rag: End-to-end retrieval-augmented generation through expected utility maximization. InProceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2641–2646, 2024. 13 FLOWREADER: Min-Cost Flow Optimization for Multi-Modal Long Document Q&AA PREPRINT ...
2024
-
[80]
Extract EVERY entity present -- coverage must be exhaustive
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.