TabSODA: Tabular Diffusion based Imputation with Skip Pattern Detection and Ordinal Awareness
Pith reviewed 2026-06-28 03:52 UTC · model grok-4.3
The pith
TabSODA improves ordinal survey imputation by propagating structural skips and modeling ordinals with cumulative-probit latents in a diffusion framework.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
TabSODA is an Expectation-Maximization-based diffusion imputer built on the Elucidated Diffusion Model framework. It propagates structural skips through the denoising loss and reverse-time sampler, represents ordinal variables with cumulative-probit scalar latents while retaining analog-bit encodings for nominal variables, and when no codebook is available uses a CART-based skip-pattern miner to estimate the mask. On the PATH and NSDUH surveys, TabSODA reduces ordinal MACE by up to 23.7 percent and improves categorical accuracy by up to 9 percent over the strongest baseline across MCAR, MAR, and MNAR masking, with the skip miner achieving near-perfect precision.
What carries the argument
TabSODA, an EM-based diffusion imputer on the EDM framework that propagates structural skips through the loss and sampler while using cumulative-probit scalar latents for ordinal variables.
If this is right
- Imputed survey data better preserves questionnaire structure by avoiding imputation of structurally skipped cells.
- Ordinal responses receive more appropriate modeling than one-hot or analog-bit encodings alone.
- The method works with or without an available codebook skip mask through the integrated miner.
- Gains hold across MCAR, MAR, and MNAR missingness mechanisms on nationally representative surveys.
- Skip pattern detection reaches near-perfect precision on the tested datasets.
Where Pith is reading between the lines
- The approach may extend to other structured datasets with logical dependencies between variables, such as electronic health records.
- Downstream statistical analyses on imputed surveys could show reduced bias in estimates of associations.
- Testing the skip miner on non-U.S. surveys might reveal whether questionnaire order alone suffices across different designs.
- Combining cumulative-probit latents with other diffusion model variants could produce further accuracy gains.
Load-bearing premise
The claim rests on the premise that structural skips can be accurately identified and propagated without imputation either via codebook or the CART-based miner, and that cumulative-probit latents meaningfully improve the diffusion process for ordinal data.
What would settle it
If TabSODA applied to the PATH or NSDUH datasets under the reported MCAR, MAR, and MNAR masking shows no reduction in ordinal MACE or no gain in categorical accuracy compared to the strongest baseline, the performance claims would not hold.
Figures

read the original abstract
Missing data imputation in large-scale surveys faces two challenges that are not well handled by current tabular diffusion methods. First, \emph{structural skips}, cells made inapplicable by questionnaire design, should not be imputed but are often conflated with item nonresponse. Second, \emph{ordinal} responses encode ordered categories, yet most pipelines treat them as nominal levels through one-hot or analog-bit encodings. We introduce \textbf{TabSODA} (\textbf{Tab}ular diffusion with \textbf{S}kip pattern detection and \textbf{O}r\textbf{d}inal \textbf{A}wareness), an Expectation-Maximization (EM)-based diffusion imputer built on the Elucidated Diffusion Model (EDM) framework. TabSODA propagates structural skips through the denoising loss and reverse-time sampler, and represents ordinal variables with cumulative-probit scalar latents while retaining analog-bit encodings for nominal variables. When a codebook skip mask is available, TabSODA uses it directly; otherwise, the TabSODA+SKIP variant estimates the mask from raw responses and questionnaire order using a CART-based skip-pattern miner. On Population Assessment of Tobacco and Health (PATH) study and the National Survey on Drug Use and Health (NSDUH), two nationally representative U.S.\ surveys, TabSODA reduces ordinal MACE by up to $23.7\%$ and improves categorical accuracy by up to $9\%$ over the strongest baseline across MCAR, MAR, and MNAR masking. The skip miner achieves near-perfect precision on both datasets, allowing TabSODA+SKIP to closely track the codebook-mask variant.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TabSODA, an EM-based diffusion imputer extending the EDM framework for tabular survey data. It propagates structural skips (via codebook or CART miner) through the denoising loss and reverse sampler, represents ordinals via cumulative-probit scalar latents (while using analog-bit for nominals), and reports up to 23.7% reduction in ordinal MACE and 9% gain in categorical accuracy versus strongest baselines on PATH and NSDUH under MCAR/MAR/MNAR, with the miner achieving near-perfect precision.
Significance. If the empirical results hold under the stated modeling choices, the work offers a targeted improvement for a practically important setting—large-scale survey imputation—by explicitly separating structural skips from item nonresponse and respecting ordinal structure. Concrete gains on two nationally representative datasets across three missingness regimes, plus the reported miner precision, constitute a falsifiable empirical contribution that builds directly on the external EDM framework.
major comments (2)
- [§4.2, Eq. (8)–(10)] §4.2, Eq. (8)–(10): the integration of cumulative-probit latents into the EDM score-matching objective is described at a high level; the precise form of the modified loss (including how the probit CDF enters the denoising target) is not derived, making it impossible to verify that the ordinal modeling is parameter-free or that it does not introduce additional fitting degrees of freedom.
- [Table 3] Table 3 (PATH, MNAR column): the reported 23.7% MACE reduction for TabSODA versus the strongest baseline is given as a point estimate without standard errors or number of runs; because the central performance claim rests on these numbers, the absence of variability measures leaves open whether the gain is statistically distinguishable from zero under the experimental protocol.
minor comments (3)
- [§5] The skip-miner precision is stated as “near-perfect” in the abstract and §5; reporting the exact precision/recall values per dataset and per missingness mechanism would allow readers to assess whether the CART component is truly robust or dataset-specific.
- [§3.3] Notation for the skip mask propagation (e.g., how the binary skip indicator modifies the reverse-time sampler) is introduced in §3.3 but never given an explicit equation; adding one would improve reproducibility.
- [Figure 2] Figure 2 caption does not state the number of Monte-Carlo samples used to generate the diffusion trajectories shown; this detail is needed to interpret the visual comparison.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and constructive comments. We address each major point below and will incorporate clarifications and additional reporting in the revised manuscript.
read point-by-point responses
-
Referee: [§4.2, Eq. (8)–(10)] §4.2, Eq. (8)–(10): the integration of cumulative-probit latents into the EDM score-matching objective is described at a high level; the precise form of the modified loss (including how the probit CDF enters the denoising target) is not derived, making it impossible to verify that the ordinal modeling is parameter-free or that it does not introduce additional fitting degrees of freedom.
Authors: We agree the current description is high-level. In the revision we will add an explicit derivation of the modified EDM score-matching loss, showing the precise manner in which the cumulative-probit CDF maps ordinal categories to a scalar latent that enters the denoising target. The construction uses only the fixed probit link and the existing diffusion network; no extra trainable parameters are introduced for the ordinal component. revision: yes
-
Referee: [Table 3] Table 3 (PATH, MNAR column): the reported 23.7% MACE reduction for TabSODA versus the strongest baseline is given as a point estimate without standard errors or number of runs; because the central performance claim rests on these numbers, the absence of variability measures leaves open whether the gain is statistically distinguishable from zero under the experimental protocol.
Authors: The observation is correct. We will revise Table 3 (and the corresponding NSDUH table) to report the number of independent runs together with standard errors on all MACE and accuracy figures, allowing readers to evaluate the statistical distinguishability of the reported gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces TabSODA as an algorithmic extension of the external EDM diffusion framework, adding skip-pattern handling (via codebook or CART miner) and cumulative-probit ordinal latents. All load-bearing claims are empirical performance numbers on PATH and NSDUH under MCAR/MAR/MNAR regimes; no derivation, uniqueness theorem, or prediction is shown to reduce by construction to fitted parameters, self-citations, or renamed inputs. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Albert and Siddhartha Chib
James H. Albert and Siddhartha Chib. Bayesian Analysis of Binary and Polychotomous Response Data.Journal of the American Statistical Association, 88(422):669–679, 1993
1993
-
[2]
Skip pattern analysis for detection of undetermined and inconsistent data
Suzan Arslanturk, Mohammad-Reza Siadat, Theophilus Ogunyemi, Kerima Demirovic, and Ananias Diokno. Skip pattern analysis for detection of undetermined and inconsistent data. In2012 5th International Conference on BioMedical Engineering and Informatics, pages 1122–1126, October 2012
2012
-
[3]
Analysis of incomplete and inconsistent clinical survey data.Knowledge and Information Systems, 46(3):731–750, March 2016
Suzan Arslanturk, Mohammad-Reza Siadat, Theophilus Ogunyemi, Kim Killinger, and Ana- nias Diokno. Analysis of incomplete and inconsistent clinical survey data.Knowledge and Information Systems, 46(3):731–750, March 2016. ISSN 0219-3116
2016
-
[4]
Evaluation measures for ordi- nal regression
Stefano Baccianella, Andrea Esuli, and Fabrizio Sebastiani. Evaluation measures for ordi- nal regression. In2009 Ninth International Conference on Intelligent Systems Design and Applications (ISDA), pages 283–287. IEEE, 2009
2009
-
[5]
Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289–300, 1995
Yoav Benjamini and Yosef Hochberg. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing.Journal of the Royal Statistical Society: Series B (Methodological), 57(1):289–300, 1995. ISSN 2517-6161
1995
-
[6]
Leo Breiman, Jerome Friedman, R. A. Olshen, and Charles J. Stone.Classification and Regression Trees. Chapman and Hall/CRC, New York, October 2017. ISBN 978-1-315-13947- 0
2017
-
[7]
ISSN 1548-7660
Stef Van Buuren and Karin Groothuis-Oudshoorn.Mice: Multivariate Imputation by Chained Equations inR.Journal of Statistical Software, 45(3), 2011. ISSN 1548-7660
2011
-
[8]
Rank Consistent Ordinal Regression for Neural Networks with Application to Age Estimation.Pattern Recognition Letters, 140: 325–331, 2020
Wenzhi Cao, Vahid Mirjalili, and Sebastian Raschka. Rank Consistent Ordinal Regression for Neural Networks with Application to Age Estimation.Pattern Recognition Letters, 140: 325–331, 2020
2020
-
[9]
Carpenter and Melanie Smuk
James R. Carpenter and Melanie Smuk. Missing Data: A Statistical Framework for Practice. Biometrical Journal, 63(5):915–947, 2021
2021
-
[10]
Ting Chen, Ruixiang Zhang, and Geoffrey E. Hinton. Analog Bits: Generating Discrete Data using Diffusion Models with Self-Conditioning. InInternational Conference on Learning Representations, 2023
2023
-
[11]
Rune H. B. Christensen.Ordinal—Regression Models for Ordinal Data. 2025
2025
-
[12]
ReMasker: Imputing Tabular Data with Masked Autoencoding
Tianyu Du, Luca Melis, and Ting Wang. ReMasker: Imputing Tabular Data with Masked Autoencoding. InInternational Conference on Learning Representations, 2024
2024
-
[13]
Edward S. Epstein. A Scoring System for Probability Forecasts of Ranked Categories.Journal of Applied Meteorology, 8(6):985–987, 1969
1969
-
[14]
Greenberg
Jim Fagan and Brian V . Greenberg. Using Graph Theory to Analyze Skip Patterns in Question- naires. SRD Research Report Census/SRD/RR-88/06, U.S. Bureau of the Census, Statistical Research Division, 1988
1988
-
[15]
Fisher.Statistical Methods for Research Workers
Ronald A. Fisher.Statistical Methods for Research Workers. Oliver & Boyd, Edinburgh, 5 edition, 1934
1934
-
[16]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On Calibration of Modern Neural Networks. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 2017. 9
2017
-
[17]
Cebere, Tennison Liu, Alicia Curth, and Mihaela van der Schaar
Daniel Jarrett, Bogdan C. Cebere, Tennison Liu, Alicia Curth, and Mihaela van der Schaar. HyperImpute: Generalized Iterative Imputation with Automatic Model Selection. InProceed- ings of the 39th International Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 9916–9937. PMLR, 2022
2022
-
[18]
David Judkins, Tom Krenzke, Andrea Piesse, Zizhong Fan, and W.-C. Haung. Preservation of Skip Patterns and Covariance Structure through Semi-Parametric Whole-Questionnaire Imputation. InProceedings of the American Statistical Association, Section on Survey Research Methods, pages 3211–3218, 2007
2007
-
[19]
Elucidating the Design Space of Diffusion-Based Generative Models
Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the Design Space of Diffusion-Based Generative Models. InAdvances in Neural Information Processing Systems, volume 35, pages 26565–26577, 2022
2022
-
[20]
Roderick J. A. Little and Donald B. Rubin.Statistical Analysis with Missing Data. Wiley, New York, 2 edition, 2002
2002
-
[21]
MIW AE: Deep Generative Modelling and Imputation of Incomplete Data Sets
Pierre-Alexandre Mattei and Jes Frellsen. MIW AE: Deep Generative Modelling and Imputation of Incomplete Data Sets. InProceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 4413–4423. PMLR, 2019
2019
-
[22]
Regression Models for Ordinal Data.Journal of the Royal Statistical Society
Peter McCullagh. Regression Models for Ordinal Data.Journal of the Royal Statistical Society. Series B (Methodological), 42(2):109–142, 1980. ISSN 0035-9246
1980
-
[23]
Olmos, Zoubin Ghahramani, and Isabel Valera
Alfredo Nazábal, Pablo M. Olmos, Zoubin Ghahramani, and Isabel Valera. Handling Incomplete Heterogeneous Data using V AEs.Pattern Recognition, 107:107501, 2020
2020
-
[24]
A Deep Learning Ordinal Classifier.International Journal of Advanced Computer Science and Applica- tions, 16(3), 2025
Tiphelele Lwazi Nxumalo, Richard Maina Rimiru, and Vusi Mpendulo Magagula. A Deep Learning Ordinal Classifier.International Journal of Advanced Computer Science and Applica- tions, 16(3), 2025
2025
-
[25]
MissDiff: Training Diffusion Models on Tabular Data with Missing Values, 2025
Yidong Ouyang, Liyan Xie, Chongxuan Li, and Guang Cheng. MissDiff: Training Diffusion Models on Tabular Data with Missing Values, 2025
2025
-
[26]
Richardson, Wencheng Wu, Lei Lin, Beilei Xu, and Edgar A
Trevor W. Richardson, Wencheng Wu, Lei Lin, Beilei Xu, and Edgar A. Bernal. McFlow: Monte Carlo Flow Models for Data Imputation. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14193–14202, Seattle, WA, USA, June 2020. IEEE. ISBN 978-1-7281-7168-5
2020
-
[27]
Donald B. Rubin. Inference and Missing Data.Biometrika, 63(3):581–592, 1976
1976
-
[28]
Tab- Diff: A Mixed-Type Diffusion Model for Tabular Data Generation
Juntong Shi, Minkai Xu, Harper Hua, Hengrui Zhang, Stefano Ermon, and Jure Leskovec. Tab- Diff: A Mixed-Type Diffusion Model for Tabular Data Generation. InInternational Conference on Learning Representations, 2025
2025
-
[29]
Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole
Yang Song, Jascha Sohl-Dickstein, Diederik P. Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-Based Generative Modeling through Stochastic Differential Equations. In International Conference on Learning Representations, 2021
2021
-
[30]
Stekhoven and Peter Bühlmann
Daniel J. Stekhoven and Peter Bühlmann. MissForest—non-parametric missing value imputation for mixed-type data.Bioinformatics, 28(1):112–118, January 2012. ISSN 1367-4803
2012
-
[31]
National Survey on Drug Use and Health (NSDUH): Public-use Data, 2021, 2021
Substance Abuse and Mental Health Services Administration. National Survey on Drug Use and Health (NSDUH): Public-use Data, 2021, 2021
2021
-
[32]
CSDI: Conditional Score-Based Diffusion Models for Probabilistic Time Series Imputation
Yusuke Tashiro, Jiaming Song, Yang Song, and Stefano Ermon. CSDI: Conditional Score-Based Diffusion Models for Probabilistic Time Series Imputation. InAdvances in Neural Information Processing Systems, volume 34, 2021
2021
-
[33]
Population Assessment of Tobacco and Health (PATH) Study [United States] Public-Use Files, 2024
United States Department of Health and Human Services, National Institutes of Health, National Institute on Drug Abuse and United States Department of Health and Human Services, Food and Drug Administration, Center for Tobacco Products. Population Assessment of Tobacco and Health (PATH) Study [United States] Public-Use Files, 2024. 10
2024
-
[34]
Cumulative link models for deep ordinal classification.Neurocomputing, 401:48–58, August 2020
Víctor Manuel Vargas, Pedro Antonio Gutiérrez, and César Hervás-Martínez. Cumulative link models for deep ordinal classification.Neurocomputing, 401:48–58, August 2020. ISSN 0925-2312
2020
-
[35]
A Connection Between Score Matching and Denoising Autoencoders.Neural Computation, 23(7):1661–1674, 2011
Pascal Vincent. A Connection Between Score Matching and Denoising Autoencoders.Neural Computation, 23(7):1661–1674, 2011
2011
-
[36]
Mining incomplete survey data through classification.Knowl- edge and Information Systems, 24(2):221–233, August 2010
Hai Wang and Shouhong Wang. Mining incomplete survey data through classification.Knowl- edge and Information Systems, 24(2):221–233, August 2010. ISSN 0219-3116
2010
-
[37]
Paul F. V . Wiemann, Thomas Kneib, and Julien Hambuckers. Using the Softplus Function to Construct Alternative Link Functions in Generalized Linear Models and Beyond.Statistical Papers, 65(5):3155–3180, 2024
2024
-
[38]
GAIN: Missing Data Imputation using Generative Adversarial Nets
Jinsung Yoon, James Jordon, and Mihaela van der Schaar. GAIN: Missing Data Imputation using Generative Adversarial Nets. InProceedings of the 35th International Conference on Machine Learning, volume 80 ofProceedings of Machine Learning Research, pages 5689–5698. PMLR, 2018
2018
-
[39]
Kochenderfer, and Jure Leskovec
Jiaxuan You, Xiaobai Ma, Daisy Yi Ding, Mykel J. Kochenderfer, and Jure Leskovec. Han- dling Missing Data with Graph Representation Learning. InAdvances in Neural Information Processing Systems, volume 33, pages 19075–19087, 2020
2020
-
[40]
Guangyu Zhang, Yulei He, Baisheng Cai, Christopher Moriarity, Hye-Chung Shin, Vera Parsons, and Katherine E. Irimata. Multiple Imputation of Missing Data with Skip-Pattern Covariates: A Comparison of Alternative Strategies.Journal of Statistical Computation and Simulation, 94 (7):1543–1570, 2024
2024
-
[41]
Mixed-Type Tabular Data Synthesis with Score-Based Diffusion in Latent Space
Hengrui Zhang, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Xiao Qin, Christos Faloutsos, Huzefa Rangwala, and George Karypis. Mixed-Type Tabular Data Synthesis with Score-Based Diffusion in Latent Space. InInternational Conference on Learning Representa- tions, 2024
2024
-
[42]
Hengrui Zhang, Liancheng Fang, Qitian Wu, and Philip S. Yu. DiffPuter: Empowering Diffusion Models for Missing Data Imputation. InInternational Conference on Learning Representations, 2025
2025
-
[43]
Diffusion models for missing value imputation in tabular data
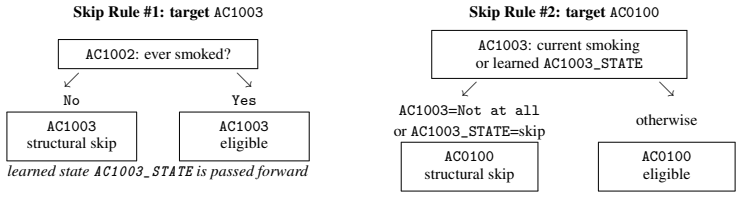
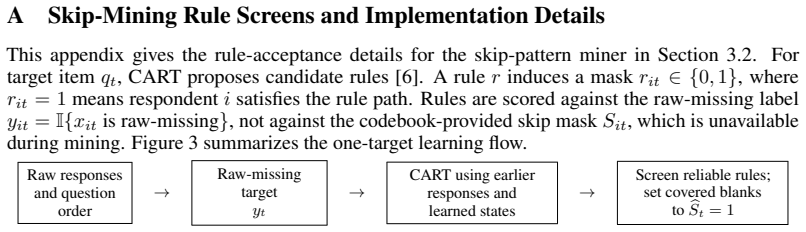
Shuhan Zheng and Nontawat Charoenphakdee. Diffusion models for missing value imputation in tabular data. InNeurIPS 2022 First Table Representation Workshop, October 2022. 11 A Skip-Mining Rule Screens and Implementation Details This appendix gives the rule-acceptance details for the skip-pattern miner in Section 3.2. For target item qt, CART proposes cand...
2022
-
[44]
MACE” (mean absolute category error) and “MAE
is a nationally representative longitudinal cohort survey of tobacco-use behaviors, attitudes, and health outcomes among U.S. adults and youth, jointly funded by the National Institute on Drug Abuse (NIDA) at the National Institutes of Health (NIH) and the U.S. Food and Drug Administration’s (FDA) Center for Tobacco Products, with public-use data distribu...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.