PermDoRA -- Understanding Adapter Interference in Language Models: Limits of Parameter-Space Geometry
Pith reviewed 2026-06-27 14:20 UTC · model grok-4.3
The pith
Adapter interference in language models arises from shared nonlinear representations rather than overlaps in parameter-space geometry.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
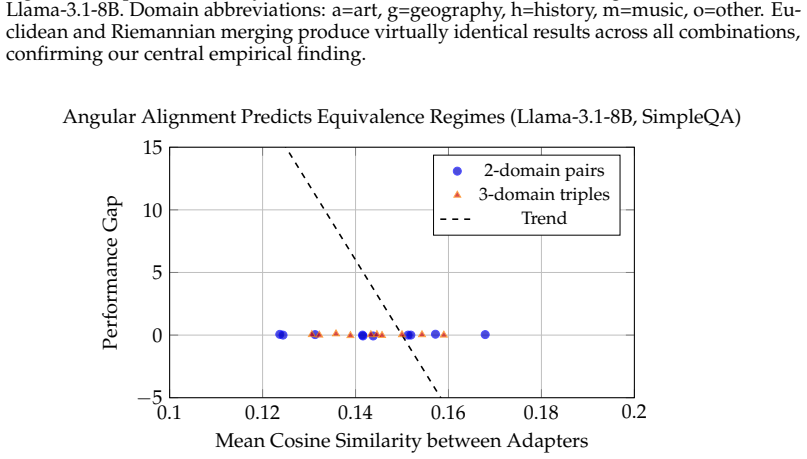
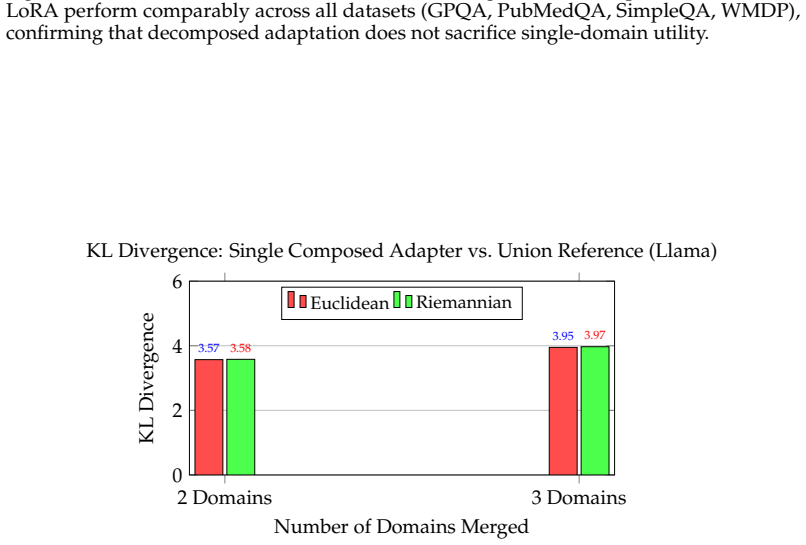
While single-domain performance matches LoRA, geometry-aware merging provides no consistent advantage over standard averaging in multi-domain settings. Angular alignment and orthogonality of adapter updates are weak predictors of composition performance. These findings suggest that adapter interference is not governed primarily by parameter-space geometry, but is instead consistent with interactions in shared nonlinear representations.
What carries the argument
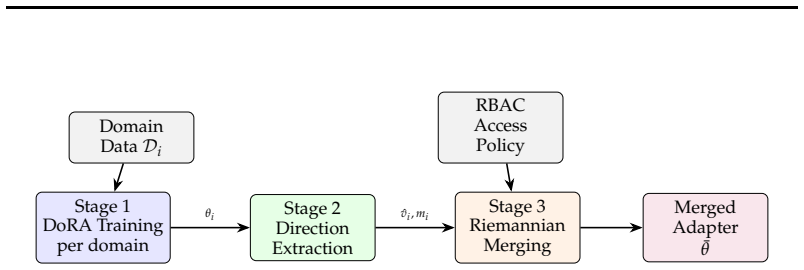
DoRA-RBAC, a hierarchical adapter composition framework based on weight-decomposed low-rank adaptation, used to compare Euclidean merging with normalized directional averaging that approximates the Frechet mean.
If this is right
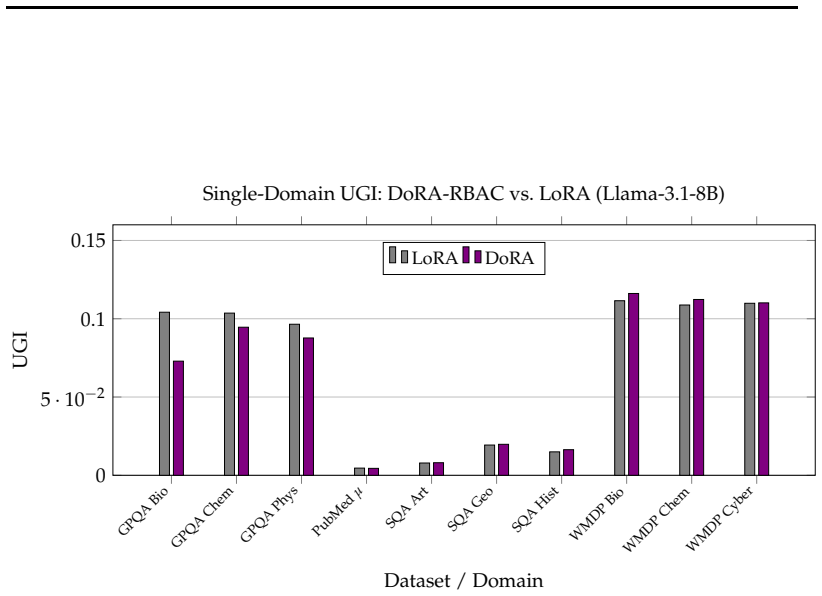
- Single-domain adapter performance matches that of standard LoRA.
- Geometry-aware merging provides no consistent advantage over standard averaging in multi-domain settings.
- Angular alignment and orthogonality of adapter updates are weak predictors of composition performance.
- Adapter interference is consistent with interactions in shared nonlinear representations rather than parameter-space overlaps.
Where Pith is reading between the lines
- Future adapter work may need to target representation-level interactions rather than parameter geometry to reduce interference.
- The same pattern could appear in other task types or larger models not tested here.
- Alternative merging strategies that act directly on activations might be worth testing next.
Load-bearing premise
The tested geometry-aware merging strategy and the chosen QA benchmarks are sufficient to detect whether parameter-space geometry controls interference in general multi-domain settings.
What would settle it
A geometry-aware merging method that consistently outperforms standard averaging on the same or similar multi-domain QA benchmarks would falsify the claim.
Figures

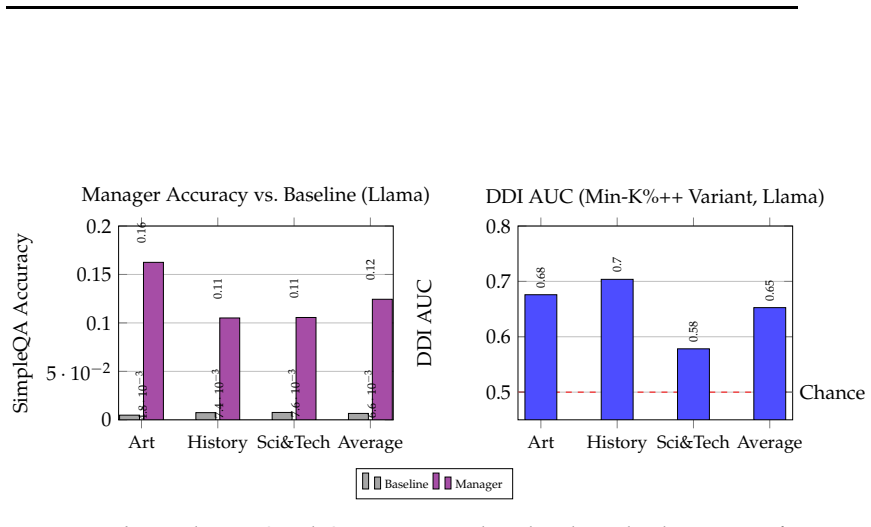
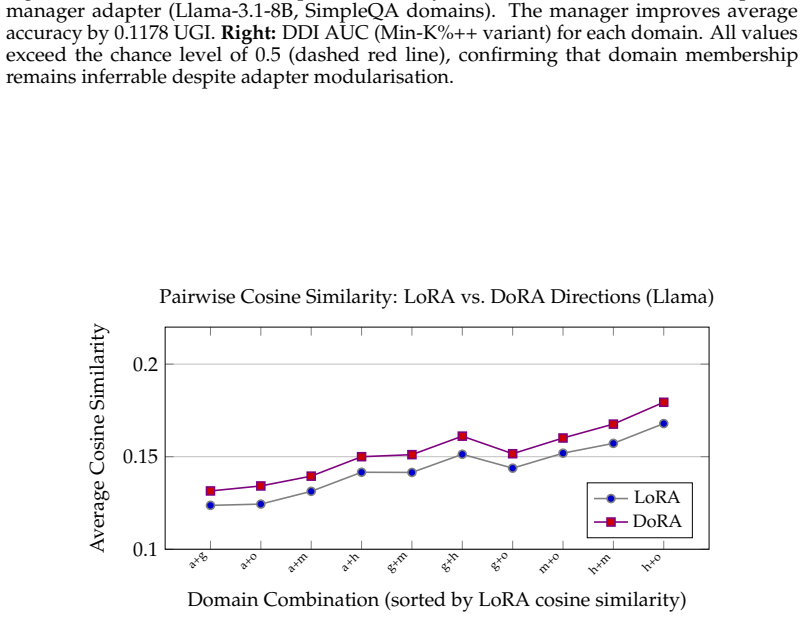

read the original abstract
Access control in large language models (LLMs) requires modular mechanisms to enable domain-specific behavior without retraining or cross-domain interference. A common hypothesis is that interference during adapter composition arises from overlap in linear parameter updates, suggesting that enforcing orthogonality or directional independence should improve multi-domain performance. We test this hypothesis using DoRA-RBAC, a hierarchical adapter composition framework based on weight-decomposed low-rank adaptation. We compare conventional Euclidean merging with a geometry-aware Riemannian-inspired merging strategy that approximates the Frechet mean via normalized directional averaging across multiple QA benchmarks (GPQA, PubMedQA, SimpleQA, WMDP) on LLaMA-3.1-8B and Mistral-7B. Our results show that while single-domain performance matches LoRA, geometry-aware merging provides no consistent advantage over standard averaging in multi-domain settings.Diagnostic analysis further reveals that angular alignment and orthogonality of adapter updates are weak predictors of composition performance. These findings suggest that adapter interference is not governed primarily by parameter-space geometry, but is instead consistent with interactions in shared nonlinear representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that adapter interference during composition in LLMs is not governed primarily by overlaps in parameter-space geometry. Using the DoRA-RBAC framework on LLaMA-3.1-8B and Mistral-7B, it compares standard Euclidean merging against a geometry-aware strategy (normalized directional averaging as a proxy for the Fréchet mean) across QA benchmarks (GPQA, PubMedQA, SimpleQA, WMDP). Single-domain performance matches LoRA, but the geometry-aware method shows no consistent multi-domain gains, and angular/orthogonality metrics are weak predictors of performance; the authors conclude that interference instead arises from interactions in shared nonlinear representations.
Significance. If the central empirical result holds after addressing the noted gaps, the work would be significant for the modular-adapter literature by providing evidence against a geometry-centric view of interference and motivating investigation of nonlinear representation interactions. The study receives credit for its direct comparison of merging strategies on two model families and a multi-benchmark QA suite, which supplies a concrete falsification attempt of the parameter-space hypothesis.
major comments (3)
- [Abstract] Abstract: the inference that 'adapter interference is not governed primarily by parameter-space geometry' is drawn from a null result on one specific merging approximation (normalized directional averaging). The manuscript does not establish that this operation is a faithful test of the geometry hypothesis (e.g., by comparing it to other Riemannian operations or proving it would detect geometry-driven interference if present), rendering the leap to the nonlinear-representation alternative under-supported.
- [Abstract] Abstract: the benchmarks are limited to four QA tasks (GPQA, PubMedQA, SimpleQA, WMDP). Without evidence or additional experiments showing these tasks are representative of general multi-domain composition, the null result cannot be taken to imply that geometry effects are absent across broader task distributions.
- [Abstract] Abstract: the comparative results are reported without details on statistical tests, run-to-run variance, or the precise implementation of the Riemannian approximation. These omissions make it impossible to assess whether the observed lack of advantage is robust or merely under-powered.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, proposing targeted revisions to strengthen the manuscript while maintaining the integrity of our empirical findings.
read point-by-point responses
-
Referee: [Abstract] Abstract: the inference that 'adapter interference is not governed primarily by parameter-space geometry' is drawn from a null result on one specific merging approximation (normalized directional averaging). The manuscript does not establish that this operation is a faithful test of the geometry hypothesis (e.g., by comparing it to other Riemannian operations or proving it would detect geometry-driven interference if present), rendering the leap to the nonlinear-representation alternative under-supported.
Authors: We acknowledge that normalized directional averaging is one specific proxy for the Fréchet mean and that the manuscript does not compare it against alternative Riemannian operations. In revision we will temper the abstract and discussion to state that the results show no advantage from this geometry-aware strategy, thereby providing evidence against a purely parameter-space view without claiming to have exhaustively tested all possible geometry-based merging methods. A new limitations paragraph will discuss the choice of approximation. revision: partial
-
Referee: [Abstract] Abstract: the benchmarks are limited to four QA tasks (GPQA, PubMedQA, SimpleQA, WMDP). Without evidence or additional experiments showing these tasks are representative of general multi-domain composition, the null result cannot be taken to imply that geometry effects are absent across broader task distributions.
Authors: The four QA benchmarks were selected to span distinct domains (general knowledge, biomedical, safety). We will add explicit justification for this selection in the methods and a limitations statement noting that generalization to other task families (e.g., long-form generation or multi-step reasoning) remains untested. revision: partial
-
Referee: [Abstract] Abstract: the comparative results are reported without details on statistical tests, run-to-run variance, or the precise implementation of the Riemannian approximation. These omissions make it impossible to assess whether the observed lack of advantage is robust or merely under-powered.
Authors: We will expand the methods and results sections to report: the exact formula for normalized directional averaging, standard deviations across multiple random seeds, and statistical comparisons (paired t-tests) between merging strategies. These additions will allow readers to evaluate the robustness of the null result. revision: yes
Circularity Check
No circularity: purely empirical null-result study with no derivations or self-referential steps
full rationale
The paper reports direct experimental comparisons of Euclidean vs. Riemannian-inspired merging on fixed QA benchmarks using LLaMA-3.1-8B and Mistral-7B. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or ansatzes appear in the provided text. The central claim follows from measured performance differences and correlation diagnostics rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AdapterSwap : Continuous training of LLMs with data removal and access-control guarantees
William Fleshman, Aleem Khan, Marc Marone, and Benjamin Van Durme . AdapterSwap : Continuous training of LLMs with data removal and access-control guarantees. arXiv preprint arXiv:2404.08417, 2025. URL https://arxiv.org/abs/2404.08417
arXiv 2025
-
[2]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024. URL https://arxiv.org/abs/2407.21783
Pith/arXiv arXiv 2024
-
[3]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA : Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[4]
Marathe, Hamid Mozaffari, William F
Bargav Jayaraman, Virendra J. Marathe, Hamid Mozaffari, William F. Shen, and Krishnaram Kenthapadi. Permissioned LLMs : Enforcing access control in large language models. arXiv preprint arXiv:2505.22860, 2025. URL https://arxiv.org/abs/2505.22860
arXiv 2025
-
[5]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, L\' e lio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timoth\' e e Lacroix, and William El Sayed. Mistral 7b. arXiv preprint...
Pith/arXiv arXiv 2023
-
[6]
URLhttps://doi.org/10.18653/v1/D19-1259
Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. PubMedQA : A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pp.\ 2567--2577. Association for Computa...
-
[7]
Communications on Pure and Applied Mathematics , volume =
Hermann Karcher. Riemannian center of mass and mollifier smoothing. Communications on Pure and Applied Mathematics, 30 0 (5): 0 509--541, 1977. doi:10.1002/cpa.3160300502
-
[8]
Nathaniel Li, Alexander Pan, Anjali Gopal, Summer Yue, Daniel Berrios, Alice Gatti, Justin D. Li, Ann-Kathrin Dombrowski, Shashwat Goel, Gabriel Mukobi, Nathan Helm-Burger, Rassin Lababidi, Lennart Justen, Andrew Bo Liu, Michael Chen, Isabelle Barrass, Oliver Zhang, Xiaoyuan Zhu, Rishub Tamirisa, Bhrugu Bharathi, Ariel Herbert-Voss, Cort B. Breuer, Andy Z...
2024
-
[9]
Prefix-Tuning: Optimizing Continuous Prompts for Generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pp.\ 4582--4597. Association for Computational Linguistics, 2021. doi:10.1...
-
[10]
DoRA : Weight-decomposed low-rank adaptation
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA : Weight-decomposed low-rank adaptation. In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pp.\ 32100--32121. PMLR, 2024. URL https://proceedings.mlr.press...
2024
-
[11]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level google-proof Q&A benchmark. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=Ti67584b98
2024
-
[12]
Ken Shoemake. Animating rotation with quaternion curves. In Proceedings of the 12th Annual Conference on Computer Graphics and Interactive Techniques ( SIGGRAPH '85) , pp.\ 245--254. ACM, 1985. doi:10.1145/325334.325242
-
[13]
Measuring short-form factuality in large language models
Jason Wei, Karina Nguyen, Hyung Won Chung, Yunxin Joy Jiao, Spencer Papay, Amelia Glaese, John Schulman, and William Fedus. Measuring short-form factuality in large language models. arXiv preprint arXiv:2411.04368, 2024. URL https://arxiv.org/abs/2411.04368
Pith/arXiv arXiv 2024
-
[14]
Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt
Mitchell Wortsman, Gabriel Ilharco, Samir Yitzhak Gadre, Rebecca Roelofs, Raphael Gontijo-Lopes, Ari S. Morcos, Hongseok Namkoong, Ali Farhadi, Yair Carmon, Simon Kornblith, and Ludwig Schmidt. Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. In Proceedings of the 39th International Conferen...
2022
-
[15]
TIES -merging: Resolving interference when merging models
Prateek Yadav, Derek Tam, Leshem Choshen, Colin Raffel, and Mohit Bansal. TIES -merging: Resolving interference when merging models. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=xtaX3WyCj1
2023
-
[16]
Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, Sergey Yekhanin, and Huishuai Zhang
Da Yu, Saurabh Naik, Arturs Backurs, Sivakanth Gopi, Huseyin A. Inan, Gautam Kamath, Janardhan Kulkarni, Yin Tat Lee, Andre Manoel, Lukas Wutschitz, Sergey Yekhanin, and Huishuai Zhang. Differentially private fine-tuning of language models. In International Conference on Learning Representations, 2022. URL https://openreview.net/forum?id=Q42f0dfjECO
2022
-
[17]
Min- K \ In The Thirteenth International Conference on Learning Representations, 2025
Jingyang Zhang, Jingwei Sun, Eric Yeats, Yang Ouyang, Martin Kuo, Jianyi Zhang, Hao Frank Yang, and Hai Li. Min- K \ In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=ZGkfoufDaU
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.