DPM++: Dynamic Masked Metric Learning for Occluded Person Re-identification
Pith reviewed 2026-05-08 12:21 UTC · model grok-4.3
The pith
DPM++ learns an input-adaptive masked metric to select reliable identity subspaces for matching occluded persons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
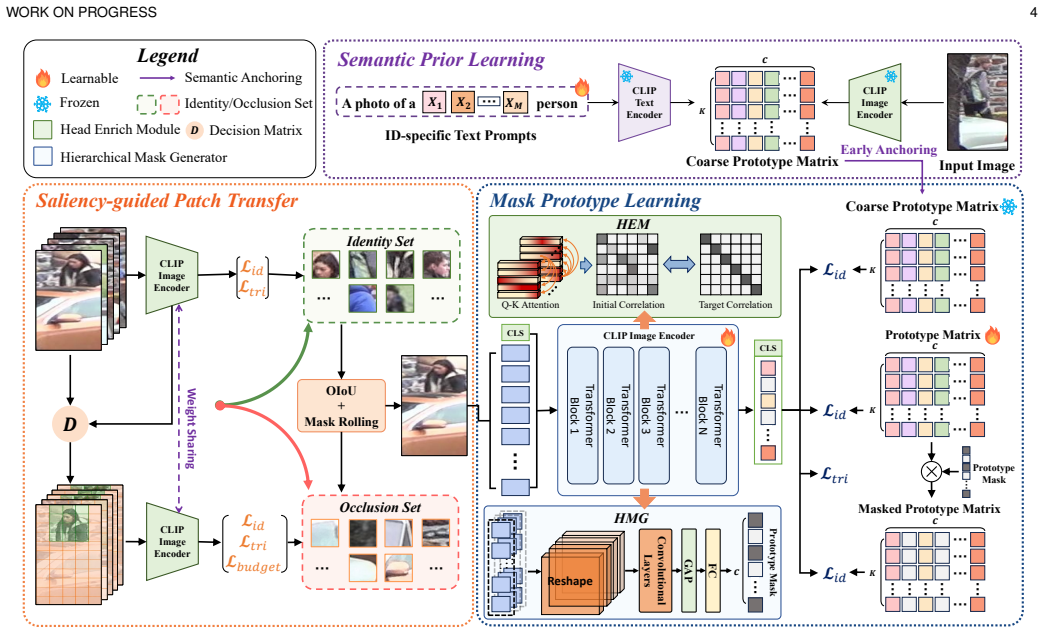
DPM++ builds a dynamic masked metric learning framework on the classifier-prototype space. It transfers ID-level semantic priors from a CLIP text branch to enable input-adaptive masked matching that emphasizes visible evidence. Saliency-guided patch transfer synthesizes photo-realistic occlusions, and occlusion-aware pairing with mask-guided optimization stabilizes training, leading to better performance on both occluded and holistic benchmarks.
What carries the argument
The input-adaptive masked metric, which dynamically selects reliable identity subspaces for each occluded instance to focus on visibility-consistent components.
If this is right
- Outperforms state-of-the-art on occluded person re-identification benchmarks.
- Maintains strong performance on standard holistic re-identification tasks.
- Reduces interference from background and occluders by suppressing unreliable metric components.
- Provides richer supervision through controllable synthetic occlusions compared to random erasing.
Where Pith is reading between the lines
- This method could be extended to other re-identification tasks involving partial views, such as vehicle re-ID with occlusions.
- The reliance on CLIP priors suggests potential benefits from other vision-language models in similar metric learning setups.
- If the synthetic samples deviate from real distributions, the gains might not hold for novel occlusion patterns like specific object types.
Load-bearing premise
That the semantic priors learned from CLIP text descriptions transfer effectively into the visual classifier-prototype space and that the saliency-guided synthetic occlusions closely match real-world patterns to improve generalization.
What would settle it
Comparing performance on a test set of occluded images where the occluders are not similar to the saliency patches used in training, such as transparent or unusual objects, and seeing if the improvement over baselines disappears.
Figures

read the original abstract
Although person re-identification has made impressive progress, occlusion caused by obstacles remains an unsettled issue in real applications. The difficulty lies in the mismatch between incomplete occluded samples and holistic identity representations. Severe occlusion removes discriminative body cues and introduces interference from background clutter and occluders, making global metric learning unreliable. Existing methods mainly rely on extra pre-trained models to estimate visible parts for alignment or construct occluded samples via data augmentation, but still lack a unified framework that learns robust visibility-consistent matching under realistic occlusion patterns. In this paper, we propose DPM++, a Dynamic Masked Metric Learning framework for occluded person re-identification. DPM++ learns an input-adaptive masked metric that dynamically selects reliable identity subspaces for each occluded instance, enabling matching to emphasize visibility-consistent evidence while suppressing unreliable components. Built upon the classifier-prototype space, DPM++ introduces a CLIP-based two-stage supervision scheme, where ID-level semantic priors are learned from the text branch and transferred into the classifier-prototype space for dynamic masked matching. To strengthen the masked metric, we introduce a saliency-guided patch transfer strategy to synthesize controllable and photo-realistic occluded samples during training. Exploiting real scene priors, this strategy exposes the model to realistic partial observations and provides richer supervision than random erasing. In addition, occlusion-aware sample pairing and mask-guided optimization improve the stability and effectiveness of the framework. Experiments on occluded and holistic person re-identification benchmarks show that DPM++ consistently outperforms previous state-of-the-art methods in both holistic and occlusion scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DPM++, a Dynamic Masked Metric Learning framework for occluded person re-identification. It learns an input-adaptive masked metric in the classifier-prototype space that dynamically selects reliable identity subspaces for each occluded instance by transferring ID-level semantic priors from a CLIP text branch. The framework augments training with a saliency-guided patch transfer strategy to synthesize controllable, photo-realistic occluded samples that exploit real scene priors, supplemented by occlusion-aware sample pairing and mask-guided optimization. Experiments on occluded and holistic person re-identification benchmarks are reported to show consistent outperformance over prior state-of-the-art methods.
Significance. If the central claims hold after addressing validation gaps, the work could advance occluded ReID by offering a unified approach that emphasizes visibility-consistent evidence through adaptive masking and realistic augmentation, potentially improving robustness in real-world applications with frequent occlusions. The integration of CLIP priors for dynamic subspace selection and scene-prior-based synthesis represents a promising direction, provided the transfer avoids hidden fitting and the synthesized data generalizes.
major comments (2)
- [Abstract] Abstract: The claim that saliency-guided patch transfer 'exploits real scene priors' to provide 'richer supervision than random erasing' is load-bearing for the generalization argument, yet no quantitative evidence (e.g., statistics on occluder size, location, texture, or distribution-matching metrics such as KL divergence between synthesized and real occluded samples) is referenced. Without this, it is unclear whether the dynamic masked metric learns to suppress unreliable components on genuine test inputs or merely on augmentation-specific artifacts.
- [Method] Method (CLIP-based two-stage supervision and dynamic masked matching): The transfer of semantic priors into the classifier-prototype space for input-adaptive masking requires explicit verification that this does not introduce hidden fitting or distribution shift, as the soundness assessment flags potential issues with clean transfer. Ablations isolating the dynamic selection mechanism from the augmentation effects are needed to confirm the central claim that it enables visibility-consistent matching.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that saliency-guided patch transfer 'exploits real scene priors' to provide 'richer supervision than random erasing' is load-bearing for the generalization argument, yet no quantitative evidence (e.g., statistics on occluder size, location, texture, or distribution-matching metrics such as KL divergence between synthesized and real occluded samples) is referenced. Without this, it is unclear whether the dynamic masked metric learns to suppress unreliable components on genuine test inputs or merely on augmentation-specific artifacts.
Authors: We agree that quantitative support for the saliency-guided patch transfer claim would strengthen the generalization argument. In the revised manuscript we will add an analysis (in the experiments section or appendix) reporting statistics on synthesized occluder size, location, and texture distributions, together with distribution-matching metrics such as FID or KL divergence between the synthesized occluded samples and real occluded images drawn from the evaluation benchmarks. These additions will demonstrate that the augmentation captures realistic scene priors more faithfully than random erasing and that performance gains arise from visibility-consistent learning on genuine patterns rather than augmentation artifacts. revision: yes
-
Referee: [Method] Method (CLIP-based two-stage supervision and dynamic masked matching): The transfer of semantic priors into the classifier-prototype space for input-adaptive masking requires explicit verification that this does not introduce hidden fitting or distribution shift, as the soundness assessment flags potential issues with clean transfer. Ablations isolating the dynamic selection mechanism from the augmentation effects are needed to confirm the central claim that it enables visibility-consistent matching.
Authors: We acknowledge the need for explicit verification that CLIP prior transfer does not introduce hidden fitting or distribution shift. In the revision we will add a targeted analysis (e.g., feature-space similarity measurements or t-SNE visualizations on clean samples) confirming that the transferred priors align with visual features without inducing measurable shift. We will also include new ablations that isolate the dynamic masked selection: performance of the full model versus a static-masking variant, with the saliency-guided augmentation held fixed. These controlled experiments will isolate the contribution of input-adaptive masking to visibility-consistent matching. revision: yes
Circularity Check
No circularity: framework components are independently trained and benchmark-validated
full rationale
The paper presents DPM++ as a composite framework whose core elements—an input-adaptive masked metric in classifier-prototype space, CLIP-derived semantic priors transferred for dynamic selection, and saliency-guided patch transfer for synthetic occlusion—are introduced as learned modules optimized end-to-end. No equation or claim reduces a 'prediction' to a fitted parameter by construction, nor invokes self-citation chains or uniqueness theorems to force the architecture. Experimental results on occluded and holistic benchmarks serve as external validation rather than definitional equivalence. The derivation chain therefore remains self-contained.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption CLIP text embeddings supply reliable semantic priors that transfer into visual classifier-prototype space for occluded matching
- domain assumption Saliency-guided patch transfer produces occluded samples whose statistics match real-world occlusion distributions
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.