Perceptual 3D Simulation With Physical World Modeling
Pith reviewed 2026-06-29 01:38 UTC · model grok-4.3
The pith
P3Sim simulates future scene states from partial images and incomplete 3D transformation signals by combining probabilistic inference with geometric conditioning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
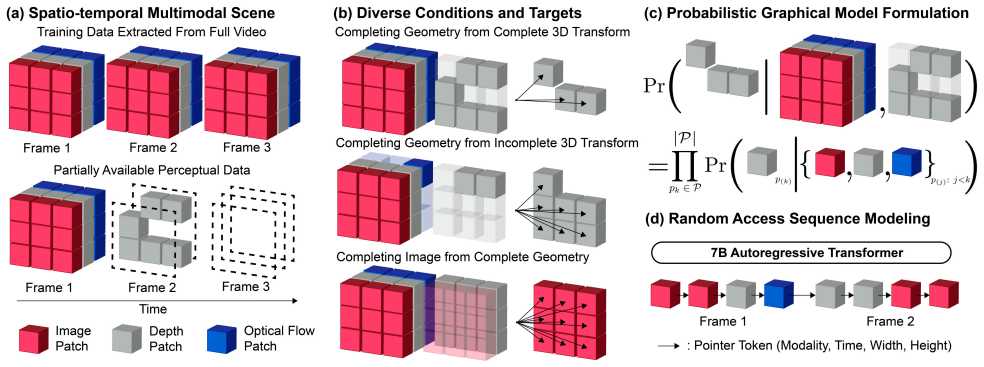
P3Sim is composed of three interacting components: a learned physical world model that interprets perception as probabilistic inference over multimodal scene variables and provides predictions of the distributions of any scene variable conditioned on any combination of others, a geometric conditioning module that supplies a partial 3D transform signal at inference time, and a persistent scene memory that integrates predictions over time. By combining learned inference with explicit geometric structure, P3Sim balances data-driven flexibility with built-in inductive bias and yields a flexible perceptual simulator that generalizes across diverse 3D transformation tasks.
What carries the argument
The learned physical world model, which performs probabilistic inference to predict distributions over any scene variable conditioned on partial observations and incomplete 3D signals.
If this is right
- The same system can be applied to novel view synthesis without retraining.
- Object manipulation predictions follow directly from conditioning the world model on the desired transformation.
- Dynamic scene prediction emerges from repeated application of the model with the persistent memory.
- Online updates remain consistent under uncertainty because the memory integrates successive inferences.
Where Pith is reading between the lines
- Hybrid learned-geometric simulators of this form may reduce the need for task-specific retraining in robotics settings with incomplete sensor data.
- The approach points toward simulators that can be queried in any direction, treating any subset of observations as conditioning input.
- Extending the geometric conditioning module to handle uncertainty in the transform signal itself could further improve robustness.
Load-bearing premise
The learned physical world model can accurately interpret perception as probabilistic inference over multimodal scene variables and provide correct conditional predictions from any combination of partial observations.
What would settle it
A demonstration that P3Sim produces inaccurate or inconsistent predictions on a held-out 3D transformation task, such as object manipulation under novel camera trajectories or dynamic scene changes not seen during training, would falsify the generalization claim.
Figures







read the original abstract
Predicting how a scene will evolve after a desired 3D transformation from images is a central goal in vision, graphics, and robotics. Yet unlike ideal simulators with full access to 3D geometry and dynamics, real world systems must rely on perceptual inputs and local actions that are inherently partial and incomplete. In this work, we present P3Sim, a physical world modeling system that simulates future scene states under both partial observations and incomplete 3D transformation signals. P3Sim is composed of three interacting components: a learned physical world model, a geometric conditioning module, and a persistent scene memory. The world model interprets perception as probabilistic inference over multimodal scene variables, providing predictions of the distributions of any scene variable conditioned on any combination of others. The geometric conditioning module provides a partial 3D transform signal for conditioning the world model at inference time. The persistent scene memory integrates predictions over time, enabling online updates and consistency under uncertainty. By combining learned inference with explicit geometric structure, P3Sim balances data-driven flexibility with built-in inductive bias. This design yields a flexible perceptual simulator that generalizes across diverse 3D transformation tasks, such as novel view synthesis, object manipulation, and dynamic scene prediction, advancing toward general purpose 3D scene understanding and transformation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces P3Sim, a physical world modeling system for simulating 3D scene evolutions under partial observations and incomplete transformation signals. It consists of a learned physical world model that performs probabilistic inference over multimodal scene variables, a geometric conditioning module, and a persistent scene memory. The paper claims that this architecture balances learned inference with geometric structure to generalize across tasks including novel view synthesis, object manipulation, and dynamic scene prediction.
Significance. Should the described components function as intended, the work could contribute to perceptual simulation in computer vision by integrating probabilistic modeling with explicit geometry, potentially enabling more robust handling of uncertainty in 3D transformations for applications in robotics and graphics.
major comments (1)
- [Abstract] Abstract: The central claims that the system 'generalizes across diverse 3D transformation tasks' and that the world model 'provide[s] accurate predictions of distributions conditioned on any combination of partial observations' rest entirely on descriptive assertions. No experiments, quantitative results, derivations, or evaluations are supplied to support these assertions, which are load-bearing for the paper's contribution.
minor comments (1)
- The high-level component descriptions would benefit from additional implementation details or pseudocode to clarify interactions between the world model, geometric conditioning, and scene memory.
Simulated Author's Rebuttal
We thank the referee for their review and the opportunity to respond. We address the major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claims that the system 'generalizes across diverse 3D transformation tasks' and that the world model 'provide[s] accurate predictions of distributions conditioned on any combination of partial observations' rest entirely on descriptive assertions. No experiments, quantitative results, derivations, or evaluations are supplied to support these assertions, which are load-bearing for the paper's contribution.
Authors: We agree that the abstract makes load-bearing claims about generalization across tasks and accurate conditional predictions that are not supported by any experiments, quantitative results, or evaluations in the manuscript. The provided text consists of an architectural description without empirical backing for these assertions. We will revise the abstract to remove or qualify these claims so that they accurately reflect the descriptive content of the work. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes P3Sim as an architectural system composed of a learned physical world model (probabilistic inference over multimodal variables), a geometric conditioning module, and persistent scene memory. All central claims—arbitrary conditioning, generalization across novel view synthesis/object manipulation/dynamic prediction, and the balance of flexibility with inductive bias—are presented as direct consequences of these design choices rather than as outputs of any derivation, equation, or fitted parameter. No equations appear in the provided text, no self-citations of uniqueness theorems are invoked to force the architecture, and no 'predictions' are shown to reduce by construction to inputs. The argument is therefore self-contained as a system description; the generalization claim follows from the stated components without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Lumiere: A space-time diffu- sion model for video generation
Omer Bar-Tal, Hila Chefer, Omer Tov, Charles Her- rmann, Roni Paiss, Shiran Zada, Ariel Ephrat, Junhwa Hur, Guanghui Liu, Amit Raj, et al. Lumiere: A space-time diffu- sion model for video generation. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 2
2024
-
[2]
Ge- nie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Ge- nie: Generative interactive environments. InForty-first Inter- national Conference on Machine Learning, 2024. 2
2024
-
[3]
pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction
David Charatan, Sizhe Lester Li, Andrea Tagliasacchi, and Vincent Sitzmann. pixelsplat: 3d gaussian splats from image pairs for scalable generalizable 3d reconstruction. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19457–19467, 2024. 2
2024
-
[4]
Video depth any- thing: Consistent depth estimation for super-long videos
Sili Chen, Hengkai Guo, Shengnan Zhu, Feihu Zhang, Zi- long Huang, Jiashi Feng, and Bingyi Kang. Video depth any- thing: Consistent depth estimation for super-long videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22831–22840, 2025. A1
2025
-
[5]
I2vcontrol: Disentangled and uni- fied video motion synthesis control
Wanquan Feng, Tianhao Qi, Jiawei Liu, Mingzhen Sun, Pengqi Tu, Tianxiang Ma, Fei Dai, Songtao Zhao, Siyu Zhou, and Qian He. I2vcontrol: Disentangled and uni- fied video motion synthesis control. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14051–14060, 2025. 2
2025
-
[6]
Brendan J Frey and Nebojsa Jojic. Learning graphical mod- els of images, videos and their spatial transformations.arXiv preprint arXiv:1301.3854, 2013. 3
Pith/arXiv arXiv 2013
-
[7]
Motion prompting: Controlling video generation with motion trajec- tories
Daniel Geng, Charles Herrmann, Junhwa Hur, Forrester Cole, Serena Zhang, Tobias Pfaff, Tatiana Lopez-Guevara, Yusuf Aytar, Michael Rubinstein, Chen Sun, et al. Motion prompting: Controlling video generation with motion trajec- tories. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1–12, 2025. 2
2025
-
[8]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
2024
-
[9]
Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control
Zekai Gu, Rui Yan, Jiahao Lu, Peng Li, Zhiyang Dou, Chenyang Si, Zhen Dong, Qifeng Liu, Cheng Lin, Ziwei Liu, et al. Diffusion as shader: 3d-aware video diffusion for ver- satile video generation control. InProceedings of the Special Interest Group on Computer Graphics and Interactive Tech- niques Conference Conference Papers, pages 1–12, 2025. 2
2025
-
[10]
Dream to control: Learning behaviors by la- tent imagination.arXiv preprint arXiv:1912.01603, 2019
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Moham- mad Norouzi. Dream to control: Learning behaviors by la- tent imagination.arXiv preprint arXiv:1912.01603, 2019. 2
Pith/arXiv arXiv 1912
-
[11]
Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023. 2
Pith/arXiv arXiv 2023
-
[12]
Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis
Wonjoon Jin, Qi Dai, Chong Luo, Seung-Hwan Baek, and Sunghyun Cho. Flovd: Optical flow meets video diffusion model for enhanced camera-controlled video synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 2040–2049, 2025. 2
2040
-
[13]
MIT press, 2009
Daphne Koller and Nir Friedman.Probabilistic graphical models: principles and techniques. MIT press, 2009. 3
2009
-
[14]
Videohandles: Editing 3d object compo- sitions in videos using video generative priors
Juil Koo, Paul Guerrero, Chun-Hao P Huang, Duygu Ceylan, and Minhyuk Sung. Videohandles: Editing 3d object compo- sitions in videos using video generative priors. InProceed- ings of the Computer Vision and Pattern Recognition Con- ference, pages 17692–17701, 2025. 2
2025
-
[15]
Onlyflow: Optical flow based mo- tion conditioning for video diffusion models
Mathis Koroglu, Hugo Caselles-Dupr ´e, Guillaume Jean- neret, and Matthieu Cord. Onlyflow: Optical flow based mo- tion conditioning for video diffusion models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6226–6236, 2025. 2
2025
-
[16]
World mod- eling with probabilistic structure integration.arXiv preprint arXiv:2509.09737, 2025
Klemen Kotar, Wanhee Lee, Rahul Venkatesh, Honglin Chen, Daniel Bear, Jared Watrous, Simon Kim, Khai Loong Aw, Lilian Naing Chen, Stefan Stojanov, et al. World mod- eling with probabilistic structure integration.arXiv preprint arXiv:2509.09737, 2025. 2
arXiv 2025
-
[17]
Unified 3d scene understanding through physical world modeling.arXiv preprint arXiv:2605.24321, 2026
Wanhee Lee, Klemen Kotar, Rahul Mysore Venkatesh, Jared Watrous, Honglin Chen, Khai Loong Aw, and Daniel LK Yamins. Unified 3d scene understanding through physical world modeling.arXiv preprint arXiv:2605.24321, 2026. 2, 8
Pith/arXiv arXiv 2026
-
[18]
Depth anything 3: Recovering the visual space from any views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views. arXiv preprint arXiv:2511.10647, 2025. A2
Pith/arXiv arXiv 2025
-
[19]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi Tu, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Yawen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22160–22169, 2024. A2
2024
-
[20]
Zero-1-to- 3: Zero-shot one image to 3d object
Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tok- makov, Sergey Zakharov, and Carl V ondrick. Zero-1-to- 3: Zero-shot one image to 3d object. InProceedings of the IEEE/CVF international conference on computer vision, pages 9298–9309, 2023. 2
2023
-
[21]
Finite scalar quantization: Vq-vae made 9 simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made 9 simple. InInternational Conference on Learning Represen- tations, pages 51772–51783, 2024. A1
2024
-
[22]
Null-text inversion for editing real im- ages using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real im- ages using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023. 2
2023
-
[23]
Dpflow: Adaptive optical flow estimation with a dual-pyramid framework
Henrique Morimitsu, Xiaobin Zhu, Roberto M Cesar, Xi- angyang Ji, and Xu-Cheng Yin. Dpflow: Adaptive optical flow estimation with a dual-pyramid framework. InProceed- ings of the Computer Vision and Pattern Recognition Confer- ence, pages 17810–17820, 2025. A1
2025
-
[24]
Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d
Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, and Niloy J Mitra. Diffusion handles enabling 3d edits for diffusion models by lifting ac- tivations to 3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7695– 7704, 2024. 2, 8
2024
-
[25]
Sam 2: Seg- ment anything in images and videos
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman R¨adle, Chloe Rolland, Laura Gustafson, et al. Sam 2: Seg- ment anything in images and videos. InInternational Con- ference on Learning Representations, pages 28085–28128,
-
[26]
Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction
Jeremy Reizenstein, Roman Shapovalov, Philipp Henzler, Luca Sbordone, Patrick Labatut, and David Novotny. Com- mon objects in 3d: Large-scale learning and evaluation of real-life 3d category reconstruction. InProceedings of the IEEE/CVF international conference on computer vision, pages 10901–10911, 2021. A2
2021
-
[27]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 2
2022
-
[28]
Zeronvs: Zero-shot 360- degree view synthesis from a single image
Kyle Sargent, Zizhang Li, Tanmay Shah, Charles Herrmann, Hong-Xing Yu, Yunzhi Zhang, Eric Ryan Chan, Dmitry La- gun, Li Fei-Fei, Deqing Sun, et al. Zeronvs: Zero-shot 360- degree view synthesis from a single image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9420–9429, 2024. 2
2024
-
[29]
Yujun Shi, Jun Hao Liew, Hanshu Yan, Vincent YF Tan, and Jiashi Feng. Lightningdrag: Lightning fast and accu- rate drag-based image editing emerging from videos.arXiv preprint arXiv:2405.13722, 2024. 2, 8
arXiv 2024
-
[30]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063,
-
[31]
ObjCtrl-2.5D: Training-free object con- trol with camera poses
Zhouxia Wang, Yushi Lan, Shangchen Zhou, and Chen Change Loy. ObjCtrl-2.5D: Training-free object con- trol with camera poses. InarXiv preprint arXiv:2412.07721,
-
[32]
Motionctrl: A unified and flexible motion controller for video generation
Zhouxia Wang, Ziyang Yuan, Xintao Wang, Yaowei Li, Tianshui Chen, Menghan Xia, Ping Luo, and Ying Shan. Motionctrl: A unified and flexible motion controller for video generation. InACM SIGGRAPH 2024 Conference Pa- pers, pages 1–11, 2024. 2
2024
-
[33]
Draganything: Motion control for any- thing using entity representation
Weijia Wu, Zhuang Li, Yuchao Gu, Rui Zhao, Yefei He, David Junhao Zhang, Mike Zheng Shou, Yan Li, Tingting Gao, and Di Zhang. Draganything: Motion control for any- thing using entity representation. InEuropean Conference on Computer Vision, pages 331–348. Springer, 2024. 2, 8
2024
-
[34]
Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024
Lihe Yang, Bingyi Kang, Zilong Huang, Zhen Zhao, Xiao- gang Xu, Jiashi Feng, and Hengshuang Zhao. Depth any- thing v2.Advances in Neural Information Processing Sys- tems, 37:21875–21911, 2024. A2
2024
-
[35]
Scannet++: A high-fidelity dataset of 3d in- door scenes
Chandan Yeshwanth, Yueh-Cheng Liu, Matthias Nießner, and Angela Dai. Scannet++: A high-fidelity dataset of 3d in- door scenes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12–22, 2023. A2
2023
-
[36]
Shengming Yin, Chenfei Wu, Jian Liang, Jie Shi, Houqiang Li, Gong Ming, and Nan Duan. Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory.arXiv preprint arXiv:2308.08089, 2023. 2
Pith/arXiv arXiv 2023
-
[37]
pixelnerf: Neural radiance fields from one or few images
Alex Yu, Vickie Ye, Matthew Tancik, and Angjoo Kanazawa. pixelnerf: Neural radiance fields from one or few images. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 4578–4587, 2021. 2
2021
-
[38]
Wangbo Yu, Jinbo Xing, Li Yuan, Wenbo Hu, Xiaoyu Li, Zhipeng Huang, Xiangjun Gao, Tien-Tsin Wong, Ying Shan, and Yonghong Tian. Viewcrafter: Taming video diffusion models for high-fidelity novel view synthesis.arXiv preprint arXiv:2409.02048, 2024. 2, 8
Pith/arXiv arXiv 2024
-
[39]
Mvimgnet: A large-scale dataset of multi-view images
Xianggang Yu, Mutian Xu, Yidan Zhang, Haolin Liu, Chongjie Ye, Yushuang Wu, Zizheng Yan, Chenming Zhu, Zhangyang Xiong, Tianyou Liang, et al. Mvimgnet: A large-scale dataset of multi-view images. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9150–9161, 2023. A2
2023
-
[40]
World-consistent video diffusion with explicit 3d modeling
Qihang Zhang, Shuangfei Zhai, Miguel Angel Bautista Mar- tin, Kevin Miao, Alexander Toshev, Joshua Susskind, and Jiatao Gu. World-consistent video diffusion with explicit 3d modeling. InProceedings of the Computer Vision and Pat- tern Recognition Conference, pages 21685–21695, 2025. 2
2025
-
[41]
Yuchen Zhang, Nikhil Keetha, Chenwei Lyu, Bhuvan Jhamb, Yutian Chen, Yuheng Qiu, Jay Karhade, Shreyas Jha, Yaoyu Hu, Deva Ramanan, et al. Ufm: A simple path towards unified dense correspondence with flow.arXiv preprint arXiv:2506.09278, 2025. A1
arXiv 2025
-
[42]
Stable virtual camera: Generative view synthesis with diffusion models
Jensen Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12405–12414, 2025. 2, 8
2025
-
[43]
Tinghui Zhou, Richard Tucker, John Flynn, Graham Fyffe, and Noah Snavely. Stereo magnification: Learning view synthesis using multiplane images.arXiv preprint arXiv:1805.09817, 2018. A2 10 Perceptual 3D Simulation With Physical World Modeling Supplementary Material Overview of the Supplementary Material This supplementary material provides additional tech...
Pith/arXiv arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.