Scalable Operator Learning via Nystr\"om Approximation With Denoising Applications
Pith reviewed 2026-06-26 03:12 UTC · model grok-4.3
The pith
Nyström subsampling for vector-valued regression in vRKHS achieves minimax-optimal rates under general index-function source conditions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A Nyström-based estimator for vector-valued regression in vRKHS attains minimax-optimal convergence rates under source conditions characterized by arbitrary index functions, and the same construction supplies a uniform operator-learning approach to function denoising across diverse signal types.
What carries the argument
Nyström subsampling of the kernel operator that reduces the effective dimension of the vector-valued RKHS while preserving the approximation needed for rate analysis under index-function source conditions.
If this is right
- Kernel methods for functional data become computationally feasible for large sample sizes without sacrificing statistical optimality.
- Denoising problems in signals, audio, and images can be solved inside a single operator-learning framework instead of custom methods per domain.
- The index-function source condition framework extends classical smoothness assumptions to cover a wider range of targets while retaining optimal rates.
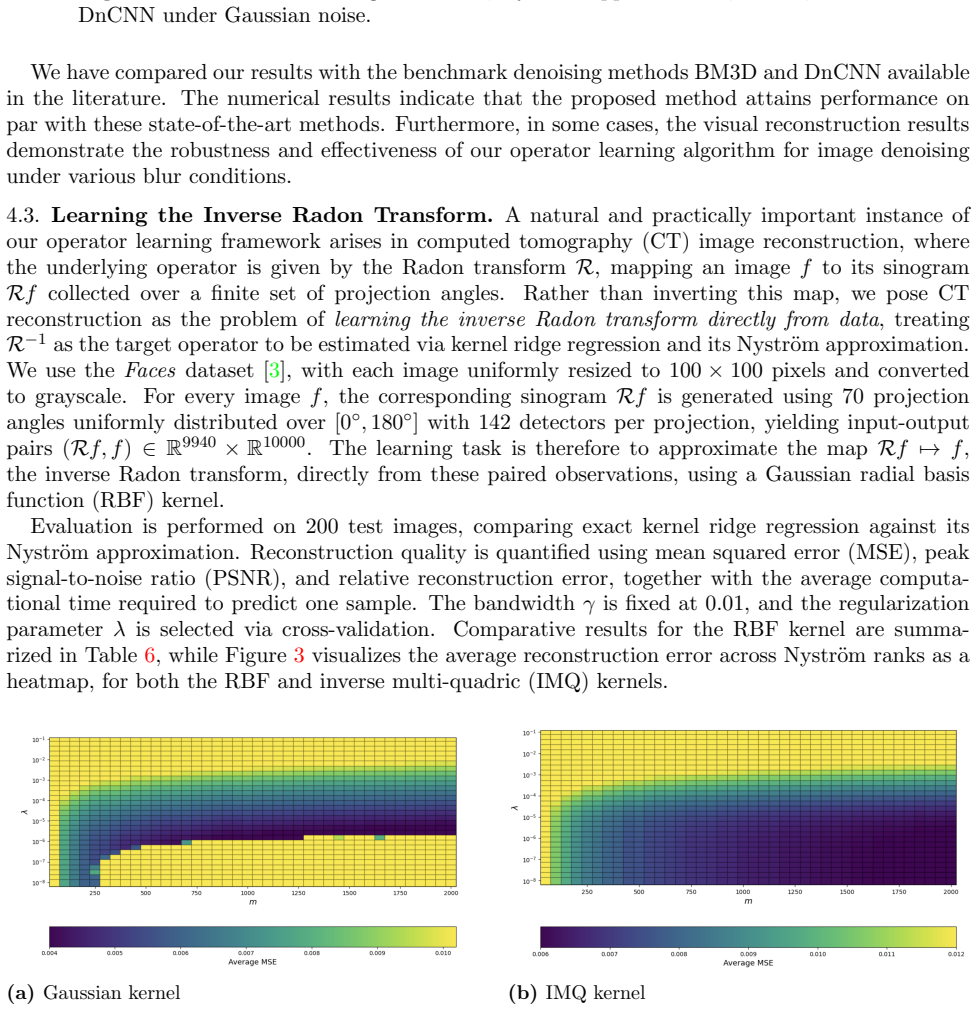
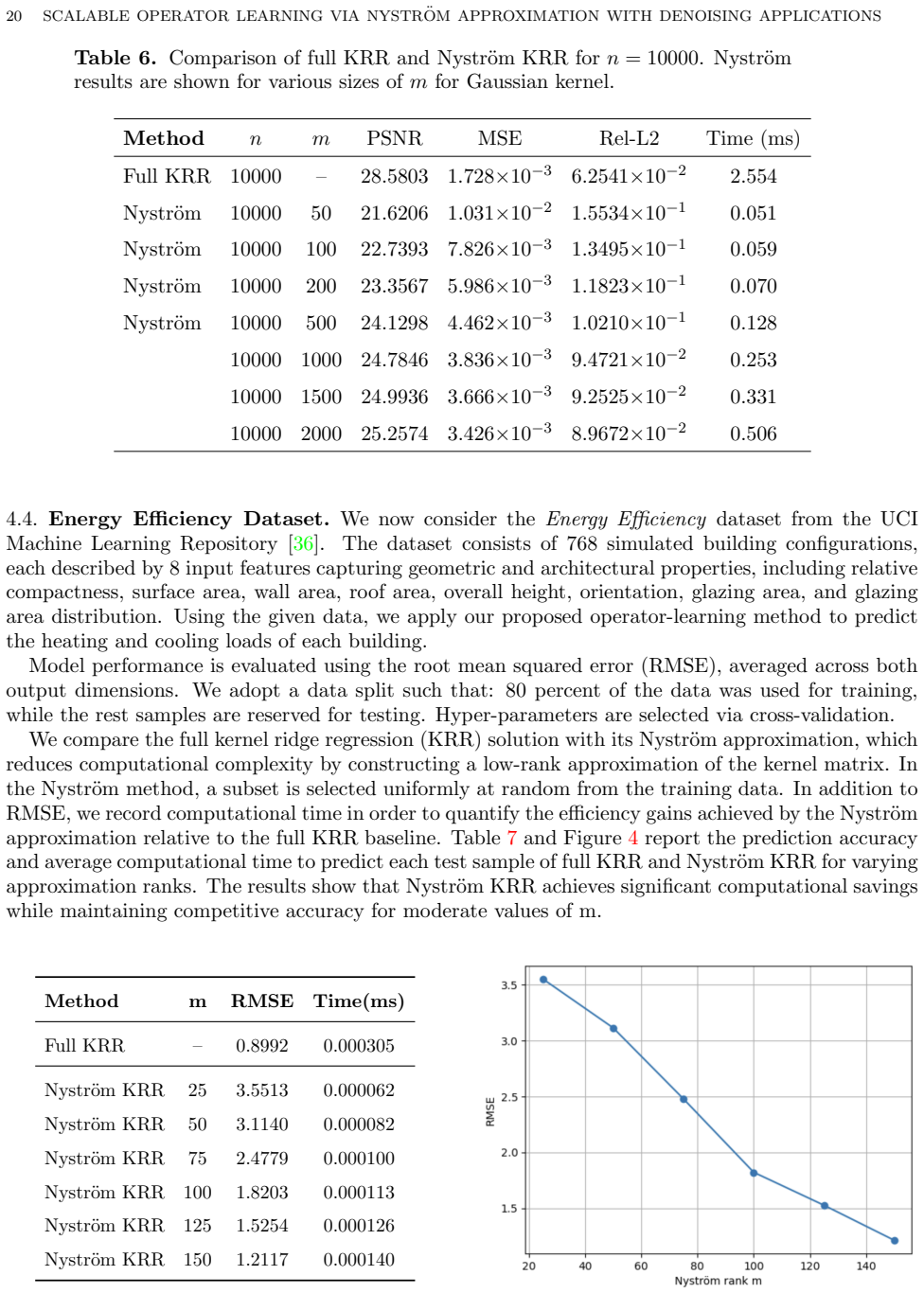
- Numerical results indicate that the reduced-cost estimator matches full-kernel performance on inverse Radon reconstruction and energy-efficiency prediction tasks.
Where Pith is reading between the lines
- If simple random or greedy landmark selection suffices in practice, the method immediately applies to streaming or very large functional datasets.
- The general source-condition analysis may transfer to other kernel-based inverse problems beyond denoising, such as deconvolution or tomography.
- The approach offers a theoretically grounded middle ground between full kernel methods and purely data-driven neural operators for functional outputs.
Load-bearing premise
The selected Nyström landmarks must preserve the approximation properties of the full kernel operator under the given index-function source conditions.
What would settle it
An explicit counterexample in which a concrete choice of landmarks causes the Nyström estimator to fall short of the claimed minimax rate for some index function would falsify the optimality result.
Figures


read the original abstract
In this paper, we study Nystr\"om subsampling for vector-valued regression in vector-valued reproducing kernel Hilbert spaces. Standard kernel methods often suffer from prohibitive computational costs due to the construction and inversion of large kernel matrices, which limits their scalability to large datasets. To overcome this bottleneck, we propose an efficient operator learning algorithm based on Nystr\"om subsampling that accommodates functional outputs. Under general source conditions characterized by index functions-extending beyond the classical H\"older-type and operator-monotone frameworks-we establish minimax-optimal convergence rates for the proposed estimator. As an application of the proposed framework, we consider function denoising problems. Unlike classical denoising methods, which are typically tailored to specific signal representations or noise models, our approach formulates denoising within a general operator learning framework. Numerical experiments on signal denoising, real-time audio denoising, image denoising, inverse Radon transform reconstruction, and energy-efficiency prediction confirm that the proposed method achieves performance comparable to full kernel methods while substantially reducing computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a Nyström subsampling algorithm for scalable vector-valued regression in vector-valued RKHS. It establishes minimax-optimal convergence rates for the resulting estimator under general source conditions given by arbitrary index functions φ (extending beyond Hölder and operator-monotone cases). The framework is applied to function denoising, with numerical experiments on signal, audio, image, Radon-transform, and energy-prediction tasks showing performance comparable to full-kernel methods at substantially lower cost.
Significance. If the rates hold, the work supplies a computationally tractable operator-learning method whose theoretical guarantees are compatible with a broad class of source conditions without extra kernel regularity. The explicit treatment of landmark selection via deterministic/uniform subsampling that preserves the necessary spectral properties, together with reproducible numerical comparisons, strengthens both the theoretical and practical contribution.
minor comments (3)
- Abstract: the phrase 'minimax-optimal convergence rates' should be qualified by the precise dependence on the index function φ and the subsampling parameter m; the current wording risks overstating uniformity across all φ.
- Notation: the distinction between the full kernel operator and its Nyström approximation is occasionally blurred in the statement of the main theorem; a short clarifying sentence after the definition of the Nyström operator would help.
- Experiments: error bars or standard deviations over the 10 random trials are not reported in the tables; adding them would make the 'comparable performance' claim easier to assess.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of the manuscript, recognition of its significance in providing scalable operator learning with broad source conditions, and recommendation for minor revision. No major comments were raised in the report.
Circularity Check
No significant circularity; theoretical rates rest on external RKHS assumptions
full rationale
The paper derives minimax-optimal convergence rates for a Nyström estimator in vector-valued RKHS under index-function source conditions. This chain relies on standard operator-theoretic bounds and general source conditions that are not defined in terms of the paper's own fitted quantities or outputs. No step reduces a claimed prediction to a parameter fitted from the same data, nor does any load-bearing premise collapse to a self-citation whose content is unverified within the manuscript. Landmark selection is handled via deterministic subsampling arguments compatible with the stated spectral assumptions. The analysis is therefore self-contained against external RKHS and approximation theory benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- standard math The kernel operator is positive definite and the vector-valued RKHS is well-defined.
- domain assumption Source conditions are characterized by index functions that extend beyond Hölder and operator-monotone classes.
Reference graph
Works this paper leans on
-
[1]
Al-Tawaha, A
A. Al-Tawaha, A. Alshorman, M. Jin, M. Al Janaideh, and K. F. Aljanaideh. An analytical approach to signal denoising based on singular value decomposition. In2025 American Control Conference (ACC), pages 3914–3919. IEEE, 2025
2025
-
[2]
Aubin.Applied Functional Analysis
J.-P. Aubin.Applied Functional Analysis. Pure and Applied Mathematics. Wiley-Interscience, second edition, 2000
2000
-
[3]
W. A. Bainbridge, P. Isola, and A. Oliva. The intrinsic memorability of face photographs.Journal of Experimental Psychology: General, 142(4):1323–1334, 2013
2013
-
[4]
Bauer, S
F. Bauer, S. Pereverzyev, and L. Rosasco. On regularization algorithms in learning theory.J. Complexity, 23:52–72, 2007
2007
-
[5]
Caponnetto and E
A. Caponnetto and E. De Vito. Optimal rates for the regularized least-squares algorithm.Found. Comput. Math., 7(3):331–368, 2007
2007
-
[6]
Carmeli, E
C. Carmeli, E. De Vito, and A. Toigo. Vector-valued reproducing kernel Hilbert spaces of integrable functions and Mercer theorem.Anal. Appl. (Singap.), 4(4):377–408, 2006
2006
-
[7]
Carmeli, E
C. Carmeli, E. De Vito, A. Toigo, and V. Umanit` a. Vector-valued reproducing kernel Hilbert spaces and universality. Anal. Appl. (Singap.), 8(1):19–61, 2010
2010
-
[8]
Dabov, A
K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian. Image denoising by sparse 3-D transform-domain collaborative filtering.IEEE Transactions on Image Processing, 16(8):2080–2095, 2007
2080
-
[9]
de Oliveira Mota, F
H. de Oliveira Mota, F. H. Vasconcelos, and R. M. da Silva. A real-time system for denoising of signals in continuous streams through the wavelet transform. InInternational Symposium on Signals, Circuits and Systems, volume 2, pages 429–432. IEEE, 2005
2005
-
[10]
Della Vecchia, A
A. Della Vecchia, A. M. Watusadisi, E. De Vito, and L. Rosasco. Computational efficiency under covariate shift in kernel ridge regression. InAdvances in Neural Information Processing Systems, volume 38, pages 141618–141648. Curran Associates, Inc., 2025
2025
-
[11]
D. L. Donoho and I. M. Johnstone. Ideal spatial adaptation by wavelet shrinkage.Biometrika, 81(3):425–455, 1994
1994
-
[12]
D. L. Donoho and I. M. Johnstone. Adapting to unknown smoothness via wavelet shrinkage.J. Amer. Statist. Assoc., 90(432):1200–1224, 1995
1995
-
[13]
Z.-C. Guo, S. Lin, and D.-X. Zhou. Learning theory of distributed spectral algorithms.Inverse Problems, 33:074009, 2017
2017
-
[14]
Gupta and S
N. Gupta and S. Sivananthan. Convergence analysis of regularised Nystr¨ om method for functional linear regression. Inverse Problems, 41(4):045005, 2025
2025
-
[15]
Gupta and S
N. Gupta and S. Sivananthan. Revisiting general source condition in learning over a Hilbert space.Inverse Problems, 41(7):075014, 2025
2025
-
[16]
M. Holzleitner, S. Pereverzyev, S. V. Pereverzyev, V. Silmana, and S. Sivananthan. Towards regularized learning from functional data with covariate shift. arXiv:2601.21019, 2026
arXiv 2026
-
[17]
J. Jin, C. Zhang, F. Feng, W. Na, J. Ma, and Q.-J. Zhang. Deep neural network technique for high-dimensional microwave modeling and applications to parameter extraction of microwave filters.IEEE Transactions on Microwave Theory and Techniques, 67(10):4140–4155, 2019
2019
-
[18]
G. S. Kimeldorf and G. Wahba. A correspondence between Bayesian estimation on stochastic processes and smooth- ing by splines.The Annals of Mathematical Statistics, 41(2):495–502, 1970
1970
-
[19]
H. Krim, D. Tucker, S. Mallat, and D. Donoho. On denoising and best signal representation.IEEE Trans. Inform. Theory, 45(7):2225–2238, 1999
1999
-
[20]
Z. Li, D. Meunier, M. Mollenhauer, and A. Gretton. Towards optimal Sobolev norm rates for the vector-valued regularized least-squares algorithm.J. Mach. Learn. Res., 25(181):1–51, 2024
2024
-
[21]
S.-B. Lin, X. Guo, and D.-X. Zhou. Distributed learning with regularized least squares.J. Mach. Learn. Res., 18(92):1–31, 2017
2017
-
[22]
G. Liu, S. Chang, and Y. Ma. Blind image deblurring using spectral properties of convolution operators.IEEE Transactions on Image Processing, 23(12):5047–5056, 2014
2014
-
[23]
S. Lu, P. Math´ e, and S. Pereverzyev. Analysis of regularized Nystr¨ om subsampling for regression functions of low smoothness.Anal. Appl. (Singap.), 17(6):931–946, 2019
2019
-
[24]
Meunier, Z
D. Meunier, Z. Shen, M. Mollenhauer, A. Gretton, and Z. Li. Optimal rates for vector-valued spectral regularization learning algorithms. InAdvances in Neural Information Processing Systems, volume 37, pages 82514–82559. Curran Associates, Inc., 2024
2024
-
[25]
C. A. Micchelli and M. Pontil. On learning vector-valued functions.Neural Comput., 17(1):177–204, 2005
2005
-
[26]
G. L. Myleiko, S. Pereverzyev, and S. G. Solodky. Regularized Nystr¨ om subsampling in regression and ranking problems under general smoothness assumptions.Anal. Appl. (Singap.), 17(3):453–475, 2019
2019
-
[27]
H. L. Myleiko and S. G. Solodky. Regularized Nystr¨ om subsampling in covariate shift domain adaptation problems. Numer. Funct. Anal. Optim., 45(3):165–188, 2024
2024
-
[28]
G. Pedrick. Theory of reproducing kernels for Hilbert spaces of vector valued functions. Technical report, Kansas University, Lawrence, KS, USA, 1957. 22 SCALABLE OPERATOR LEARNING VIA NYSTR ¨OM APPROXIMATION WITH DENOISING APPLICATIONS
1957
-
[29]
I. F. Pinelis and A. I. Sakhanenko. Remarks on inequalities for large deviation probabilities.Theory Probab. Appl., 30(1):143–148, 1986
1986
-
[30]
Rastogi and S
A. Rastogi and S. Sivananthan. Optimal rates for the regularized learning algorithms under general source condition. Frontiers in Applied Mathematics and Statistics, 3:3, 2017
2017
-
[31]
A. Rudi, R. Camoriano, and L. Rosasco. Less is more: Nystr¨ om computational regularization. InAdvances in Neural Information Processing Systems, volume 28, pages 1657–1665. MIT Press, 2015
2015
-
[32]
Sahoo, J
G. Sahoo, J. Freed, and M. Srivastava. Optimal wavelet selection for signal denoising.IEEE Access, 12:45369–45380, 2024
2024
-
[33]
Schwartz
L. Schwartz. Hilbertian subspaces of topological vector spaces and associated nuclei (reproductive nuclei).J. Anal. Math., 13(1):115–256, 1964
1964
-
[34]
A. J. Smola and B. Sch¨ olkopf. Sparse greedy matrix approximation for machine learning. InProceedings of the 17th International Conference on Machine Learning, pages 911–918, San Francisco, CA, USA, 2000. Morgan Kaufmann Publishers Inc
2000
-
[35]
Trinchero and F
R. Trinchero and F. Canavero. Machine learning regression techniques for the modeling of complex systems: An overview.IEEE Electromagnetic Compatibility Magazine, 10(4):71–79, 2021
2021
-
[36]
Tsanas and A
A. Tsanas and A. Xifara. Energy efficiency. UCI Machine Learning Repository, 2012
2012
-
[37]
Yurinsky.Sums and Gaussian Vectors, volume 1617 ofLecture Notes in Mathematics
V. Yurinsky.Sums and Gaussian Vectors, volume 1617 ofLecture Notes in Mathematics. Springer-Verlag, Berlin, 1995
1995
-
[38]
Zhang, W
K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang. Beyond a Gaussian denoiser: Residual learning of deep CNN for image denoising.IEEE Transactions on Image Processing, 26(7):3142–3155, 2017
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.