Anchor: Mitigating Artifact Drift in Agent Benchmark Generation
Pith reviewed 2026-06-29 21:27 UTC · model grok-4.3
The pith
A single parametric specification generates consistent natural-language instructions, environments, optimal solutions, and verifiers for agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
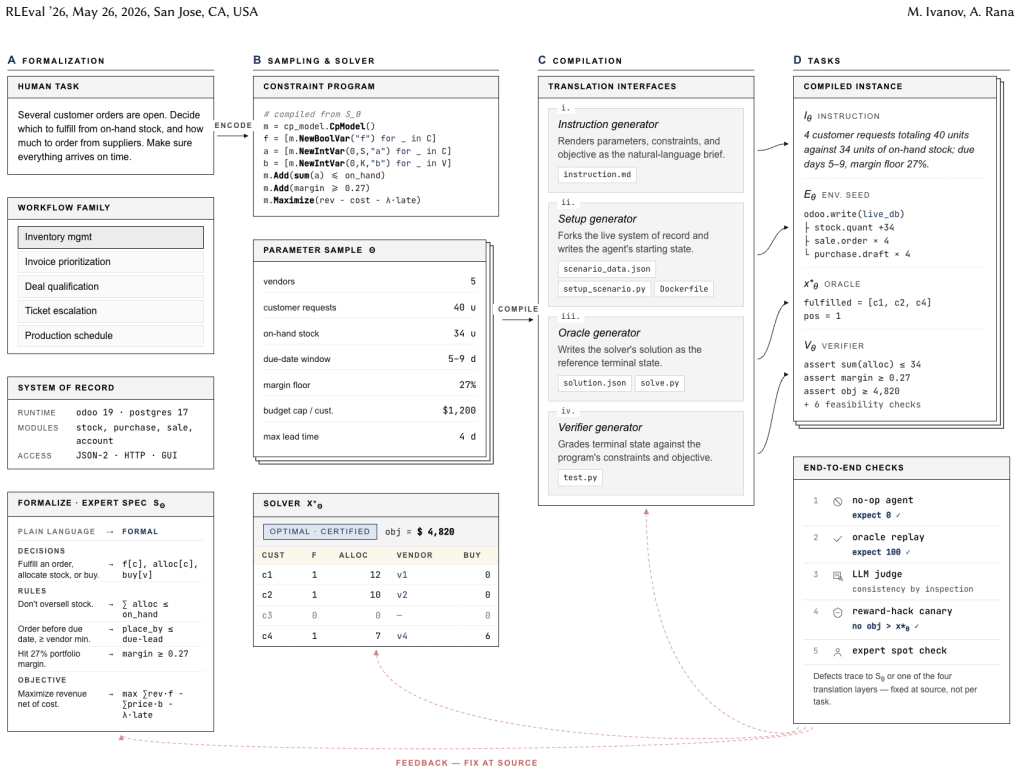
Anchor formalizes domain experts' specifications of business workflows into constraint optimization programs. From a single parametric specification, the pipeline jointly produces a natural-language instruction, environment configuration, solver-certified ground-truth solution, and state-based verifier. This produces harness-agnostic environments whose rewards depend solely on end-state business correctness, with generation parameters controlling difficulty and yielding known optimal solutions.
What carries the argument
The Anchor pipeline that encodes business workflows into constraint optimization programs to jointly generate all benchmark elements.
If this is right
- Altering parameters produces new tasks with controlled difficulty and known optimal solutions.
- Rewards in the environments depend only on end-state business correctness, independent of the harness.
- Generation parameters predict the realized difficulty of tasks.
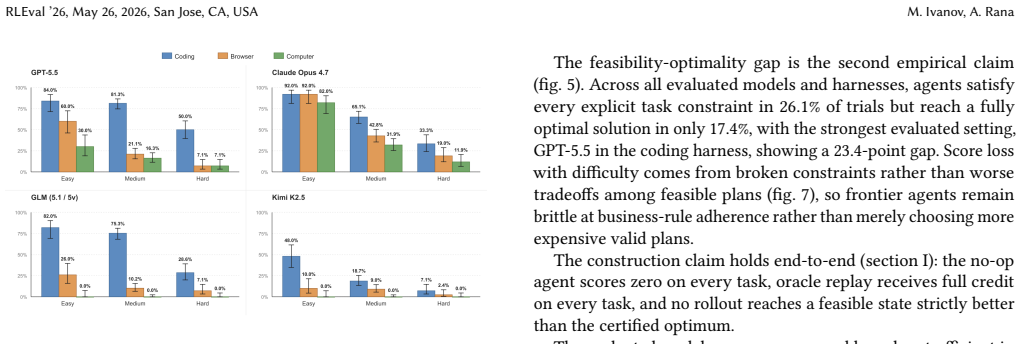
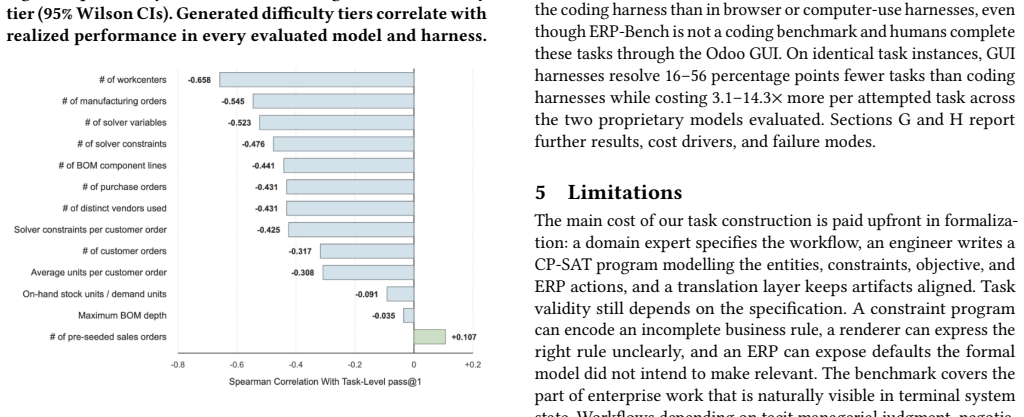
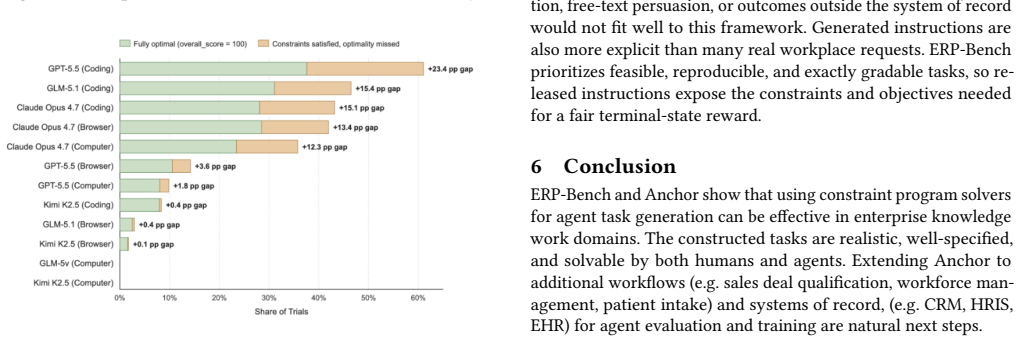
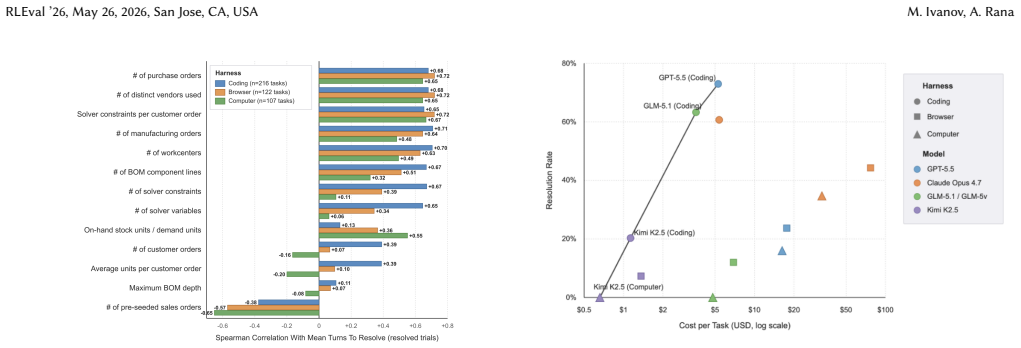
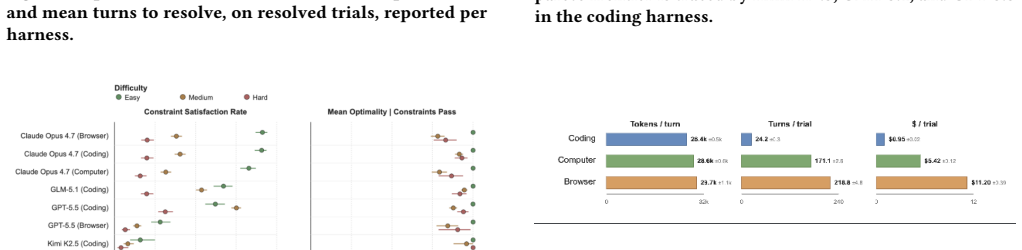
- Frontier models satisfy explicit task constraints in 26.1% of trials but reach fully optimal solutions in only 17.4% of trials.
Where Pith is reading between the lines
- This method could be applied to other enterprise domains if their workflows can be expressed as constraint programs.
- Providing verified optimal solutions may enable more effective training of agents beyond evaluation.
- State-based verifiers allow checking correctness without simulating full execution paths.
Load-bearing premise
Domain experts can accurately encode real business workflows as constraint optimization programs that stay consistent with the natural language instructions and generated environment states.
What would settle it
Finding cases where the solver-certified solution violates the natural-language instruction or where the state-based verifier accepts an incorrect end state.
Figures

read the original abstract
AI agents are beginning to complete valuable, long-horizon business operations tasks, but training and evaluation environments for enterprise work still struggle to balance realism, verifiability, and scale. Environment and task creation frequently suffers from a failure mode we call artifact drift: when instructions, environments, oracles, and verifiers are created by loosely coupled processes, they frequently disagree on what a task requires, producing environments that are unsolvable, reward-hackable, or inconsistent. We introduce Anchor, a task-generation pipeline that formalizes domain experts' specifications of business workflows into constraint optimization programs. From a single parametric specification, the pipeline jointly produces a natural-language instruction, environment configuration, solver-certified ground-truth solution, and state-based verifier. With Anchor, altering parameters yields new tasks with controlled difficulty and known optimal solutions, producing harness-agnostic environments whose rewards depend solely on end-state business correctness. We apply Anchor to produce ERP-Bench: a benchmark of 300 long-horizon tasks spanning procurement and manufacturing workflows in a production-grade ERP system. We find that generation parameters predict realized difficulty, and that frontier models satisfy explicit task constraints in 26.1% of trials but reach a fully optimal solution in only 17.4% of trials. Overall, we show that Anchor and ERP-Bench offer a concrete recipe for building auditable evaluation environments for economically valuable agent work. We release the task generator and ERP-Bench dataset at erpbench.ai
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Anchor pipeline for generating benchmarks for AI agents performing business operations tasks. It formalizes domain experts' workflow specifications as constraint optimization programs (COPs), from which it jointly generates natural-language instructions, environment configurations, solver-certified ground-truth solutions, and state-based verifiers. The approach is applied to create ERP-Bench, consisting of 300 long-horizon tasks in procurement and manufacturing within a production-grade ERP system. The paper reports that generation parameters predict task difficulty, with frontier models satisfying explicit constraints in 26.1% of trials and reaching fully optimal solutions in 17.4% of trials.
Significance. If the consistency between the generated components holds, Anchor provides a scalable method for creating verifiable, auditable evaluation environments for agentic AI in economically valuable domains, addressing the artifact drift problem that plagues current benchmarks. The release of the task generator and dataset enhances reproducibility and allows for controlled difficulty variation.
major comments (2)
- [Abstract] The reported performance figures (26.1% constraint satisfaction, 17.4% optimal solutions) lack accompanying details on the number of models evaluated, experimental protocol, error bars, or baseline comparisons, making it difficult to assess the reliability of these claims about model capabilities.
- The central claim that the pipeline mitigates artifact drift rests on the assumption that natural-language instructions generated from the COP specification will be consistent with the formal constraints and solver solutions. The manuscript does not provide a concrete mechanism or validation for ensuring that the NL generation step preserves exact alignment, particularly for complex workflows involving sequential or conditional elements.
minor comments (1)
- The abstract could benefit from a brief mention of how the state-based verifier is constructed to depend solely on end-state correctness.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each major comment below, indicating where we will revise the paper to improve clarity and strengthen the presentation of our claims.
read point-by-point responses
-
Referee: [Abstract] The reported performance figures (26.1% constraint satisfaction, 17.4% optimal solutions) lack accompanying details on the number of models evaluated, experimental protocol, error bars, or baseline comparisons, making it difficult to assess the reliability of these claims about model capabilities.
Authors: We agree that the abstract would benefit from greater specificity to allow readers to better evaluate the reported figures. In the revised version, we will expand the abstract to note the number of frontier models evaluated, briefly describe the evaluation protocol (including trial counts and task sampling), and indicate that error bars along with baseline comparisons appear in the experimental results section. Given abstract length constraints, we will prioritize the most essential details while ensuring the claims are better contextualized. revision: yes
-
Referee: [—] The central claim that the pipeline mitigates artifact drift rests on the assumption that natural-language instructions generated from the COP specification will be consistent with the formal constraints and solver solutions. The manuscript does not provide a concrete mechanism or validation for ensuring that the NL generation step preserves exact alignment, particularly for complex workflows involving sequential or conditional elements.
Authors: The manuscript grounds the consistency claim in the joint generation process: all outputs (NL instruction, environment, solver solution, and verifier) are derived directly from a single parametric COP specification, with the NL component produced via a deterministic translation of the COP's constraints, objectives, and workflow structure into templated language. This design ensures that the NL instruction encodes the same constraints as the formal program by construction. However, we acknowledge that the current text provides limited explicit description of the translation rules and any post-generation validation (e.g., automated checks for constraint coverage in sequential or conditional cases). We will add a dedicated subsection detailing the NL generation mechanism, including examples of how sequential and conditional elements are rendered, and report results from an alignment validation procedure that compares extracted constraints from the NL text against the original COP. revision: yes
Circularity Check
No significant circularity; pipeline is an independent generation recipe
full rationale
The paper describes a task-generation pipeline that converts parametric specifications into COPs and then jointly emits NL instructions, configs, solver solutions, and verifiers. No equations, fitted parameters, or self-citations are presented that would make reported success rates (26.1% constraint satisfaction, 17.4% optimal) or difficulty predictions reduce to the input parameters by construction. The empirical findings on ERP-Bench are external observations rather than tautological outputs. The central claim rests on the engineering consistency of the pipeline, which is not shown to be self-definitional or imported via author prior work.
Axiom & Free-Parameter Ledger
free parameters (1)
- generation parameters
axioms (1)
- domain assumption Domain experts can encode business workflows as constraint optimization programs that remain consistent with generated natural-language instructions and environments.
Reference graph
Works this paper leans on
- [1]
-
[2]
AlphaProof and AlphaGeometry Teams. 2024. AI Achieves Silver-Medal Standard Solving International Mathematical Olympiad Problems. https://deepmind. google/discover/blog/ai-solves-imo-problems-at-silver-medal-level/
2024
-
[3]
Victor Barres et al . 2025. 𝜏 2-Bench: Evaluating Conversational Agents in a Dual-Control Environment. arXiv:2506.07982 https://arxiv.org/abs/2506.07982 Anchor: Mitigating Artifact Drift in Agent Benchmark Generation RLEval ’26, May 26, 2026, San Jose, CA, USA
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Harbor Framework Team. 2026. Task Structure. https://www.harborframework. com/docs/tasks
2026
-
[5]
Thomas Hubert et al. 2026. Olympiad-Level Formal Mathematical Reasoning with Reinforcement Learning.Nature651 (2026), 607–613. doi:10.1038/s41586- 025-09833-y
-
[6]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues?. InInternational Conference on Learning Representations. arXiv:2310.06770 https://openreview.net/forum?id=8y2YPzvJaG
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [7]
-
[8]
National Association of Manufacturers. 2025. Facts About Manufacturing. https: //nam.org/mfgdata/facts-about-manufacturing-expanded/
2025
-
[9]
Odoo S.A. 2026. Odoo 19.0 Documentation. https://www.odoo.com/ documentation/19.0/
2026
-
[10]
Alexander Pan et al. 2025. Measuring Agents in Production. arXiv:2512.04123 https://arxiv.org/abs/2512.04123
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Laurent Perron and Frederic Didier. 2025. OR-Tools CP-SAT v9.12. https: //developers.google.com/optimization/cp/cp_solver
2025
- [12]
-
[13]
Bureau of Economic Analysis
U.S. Bureau of Economic Analysis. 2025. Gross Domestic Product, 4th Quar- ter and Year 2024, Third Estimate, GDP by Industry, and Corporate Prof- its. https://www.bea.gov/news/2025/gross-domestic-product-4th-quarter-and- year-2024-third-estimate-gdp-industry-and
2025
-
[14]
Bureau of Labor Statistics
U.S. Bureau of Labor Statistics. 2025. Purchasing Managers, Buyers, and Pur- chasing Agents. https://www.bls.gov/ooh/business-and-financial/purchasing- managers-buyers-and-purchasing-agents.htm
2025
- [15]
-
[16]
TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks
Frank F. Xu et al . 2025. TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks. arXiv:2412.14161 https://arxiv.org/abs/2412. 14161
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. 2025. 𝜏- bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. InInternational Conference on Learning Representations. arXiv:2406.12045 https: //openreview.net/forum?id=roNSXZpUDN
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Asaf Yehudai et al . 2025. Survey on Evaluation of LLM-Based Agents. arXiv:2503.16416 https://arxiv.org/abs/2503.16416
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [19]
-
[20]
Mario Zechner. 2026. Pi Monorepo. https://github.com/badlogic/pi-mono
2026
-
[21]
Mingchen Zhu et al . 2025. Establishing Best Practices for Building Rigorous Agentic Benchmarks. arXiv:2507.02825 https://arxiv.org/abs/2507.02825 RLEval ’26, May 26, 2026, San Jose, CA, USA M. Ivanov, A. Rana Table 1: Domain terms used throughout the paper. Defini- tions point at the meaning the term carries in Odoo and in ERP-Bench rather than the broad...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.