GKDT: General Keypoint Detection Transformer
Pith reviewed 2026-07-02 14:18 UTC · model grok-4.3
The pith
A single transformer model trained on a merged keypoint dataset detects keypoints across dozens of categories with over 90 percent accuracy on most test sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
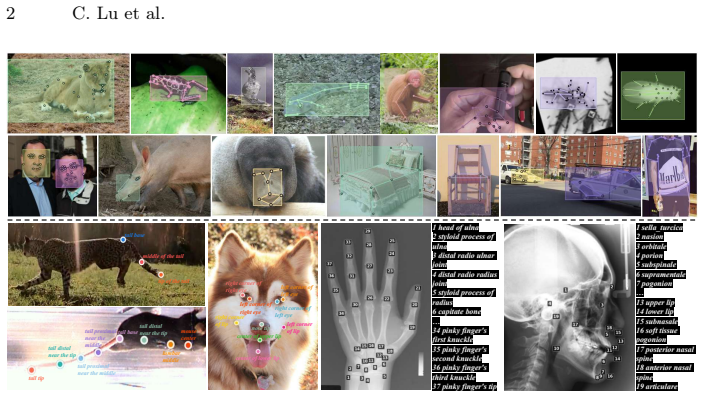
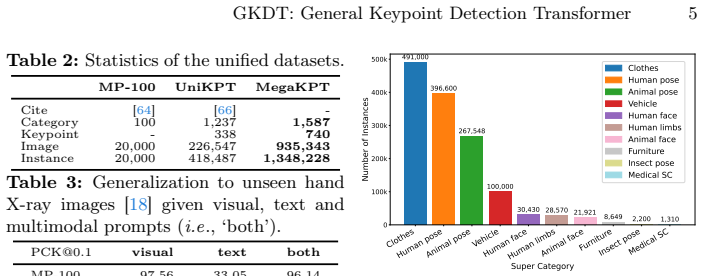
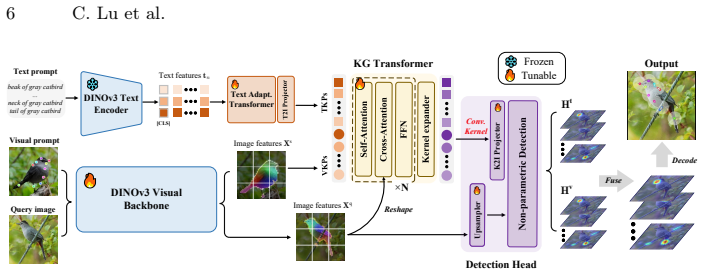
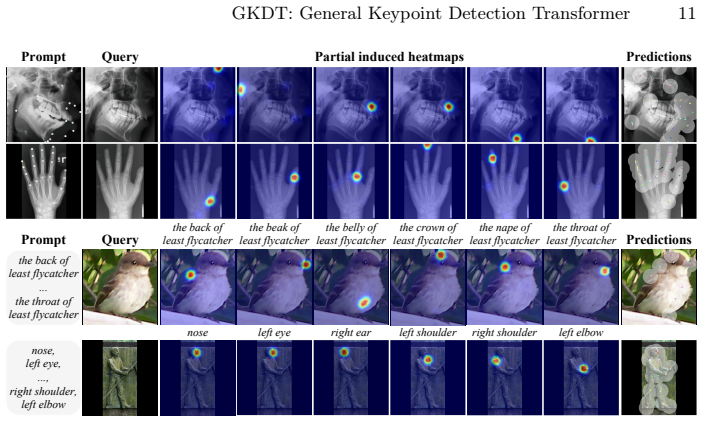
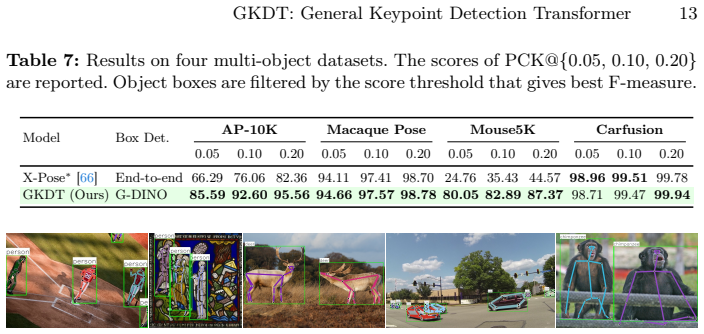
The paper constructs MegaKPT, a large-scale unified keypoint dataset drawn from twenty-nine sources with high-quality annotations and keypoint text descriptions, and introduces GKDT, a simple flexible Transformer built on DINOv3 that supports visual prompts, text prompts, or both. Using mix-modal prompted training and dynamic importance sampling, the single GKDT model achieves strong performance and generality when tested on twenty-two sets with seen or unseen objects, exceeding 90 percent PCK@0.1 accuracy on most categories.
What carries the argument
GKDT, a DINOv3-based Transformer that accepts visual prompts, text prompts, or both to locate keypoints on objects.
If this is right
- One model replaces many specialized keypoint detectors across different object types.
- The same weights handle both objects seen during training and entirely new categories.
- Prompt inputs let users specify which keypoints to detect without changing the model.
- High accuracy on broad categories supports direct use in real-world pipelines.
Where Pith is reading between the lines
- Merging strategies like MegaKPT could be repeated for related tasks such as instance segmentation if annotation consistency can be maintained.
- Text prompt support opens the possibility of describing new keypoint sets in natural language and detecting them without additional labeled examples.
- A deployed version might reduce the need for separate networks in multi-object environments like robotics or scene understanding.
Load-bearing premise
The annotations from the twenty-nine source datasets can be unified with consistent keypoint text descriptions in a way that supplies enough training signal for the model to generalize to unseen objects and categories.
What would settle it
Running the released GKDT model on a fresh collection of object categories absent from the original twenty-nine datasets and measuring PCK@0.1 well below 90 percent on most of them would show the claimed generality does not hold.
Figures


read the original abstract
With the emergence of various pre-trained vision and language models, computer vision is shifting from narrow-domain to open-domain recognition. The construction of a more powerful yet general keypoint detection (GKD) model to support diverse tasks has become increasingly important in the field. To this end, we firstly present a large-scale unified keypoint dataset called MegaKPT. The dataset is composed of over 1.3 million diverse object instances from twenty-nine existing datasets, and enjoys high-quality unified annotations with keypoint text descriptions. Based on MegaKPT, we develop GKDT, a simple, flexible and powerful DINOv3 based Transformer model for General Keypoint Detection. Our GKDT supports visual prompts, text prompts, or both. To enhance model training, we also propose a suite of useful strategies such as mix-modal prompted training and dynamic importance sampling. By testing over 22 test sets with seen or unseen objects, our single GKDT model shows strong performance and generality in detecting keypoints on broad categories, with most categories over 90\% PCK@0.1 accuracy, offering high practical applicability to real-world problems. The dataset, models, and codes will be released at https://github.com/AlanLuSun/General-Keypoint-Detection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MegaKPT, a unified keypoint dataset aggregating over 1.3 million instances from 29 existing datasets with high-quality annotations and keypoint text descriptions, and proposes GKDT, a DINOv3-based Transformer model for general keypoint detection that accepts visual prompts, text prompts, or both. It further describes training strategies including mix-modal prompted training and dynamic importance sampling. The central claim is that a single GKDT model achieves strong generality, with most categories exceeding 90% PCK@0.1 accuracy across 22 test sets containing both seen and unseen objects.
Significance. If the unification process and empirical results are shown to be robust, the work would advance open-domain keypoint detection by supplying a large-scale training resource and a flexible promptable model with broad category coverage and real-world applicability. The planned public release of the dataset, models, and code would further strengthen reproducibility.
major comments (2)
- Abstract: the central claim that a single model generalizes to unseen objects and categories with >90% PCK@0.1 on 22 test sets rests on the assumption that the 'high-quality unified annotations' in MegaKPT form a semantically coherent training distribution, yet the abstract supplies no description of the mapping rules, conflict-resolution procedure, or consistency audit used to reconcile incompatible keypoint taxonomies and coordinate conventions across the 29 source datasets.
- Abstract: performance numbers are reported without any baselines, ablation studies, error analysis, or details on dataset construction and split construction, leaving the contribution of the proposed mix-modal training and dynamic importance sampling unsupported and preventing assessment of whether the reported generality exceeds what could be obtained from simpler fine-tuning.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments on the abstract. We agree that the abstract would benefit from additional context on dataset unification and experimental support. We will revise the abstract accordingly while preserving its conciseness.
read point-by-point responses
-
Referee: Abstract: the central claim that a single model generalizes to unseen objects and categories with >90% PCK@0.1 on 22 test sets rests on the assumption that the 'high-quality unified annotations' in MegaKPT form a semantically coherent training distribution, yet the abstract supplies no description of the mapping rules, conflict-resolution procedure, or consistency audit used to reconcile incompatible keypoint taxonomies and coordinate conventions across the 29 source datasets.
Authors: We acknowledge that the abstract does not describe the unification process. Section 3 of the manuscript details the aggregation of the 29 source datasets, including taxonomy mapping rules, conflict resolution for incompatible keypoints, coordinate normalization, and consistency audits performed to ensure semantic coherence. In the revision we will add one or two sentences to the abstract summarizing these steps so that the claim of high-quality unified annotations is better supported at first reading. revision: yes
-
Referee: Abstract: performance numbers are reported without any baselines, ablation studies, error analysis, or details on dataset construction and split construction, leaving the contribution of the proposed mix-modal training and dynamic importance sampling unsupported and preventing assessment of whether the reported generality exceeds what could be obtained from simpler fine-tuning.
Authors: The abstract is intentionally brief. The full manuscript contains extensive experiments (Section 4) that include baselines against prior keypoint detectors, ablations isolating mix-modal prompted training and dynamic importance sampling, error analysis, and explicit descriptions of the train/test splits across the 22 evaluation sets. We will revise the abstract to include a short clause noting that these controlled experiments demonstrate the added value of the proposed training strategies over simpler fine-tuning baselines. revision: yes
Circularity Check
No circularity: empirical dataset unification and model evaluation are self-contained.
full rationale
The paper constructs MegaKPT by aggregating and annotating instances from 29 prior datasets, then trains and evaluates GKDT directly on held-out test sets across 22 benchmarks. No equations, predictions, or central claims reduce by construction to fitted inputs, self-citations, or renamed prior results. Performance metrics (PCK@0.1) are reported from explicit testing rather than derived from the unification step itself. The derivation chain is therefore independent of the patterns that would trigger circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023) 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
arXiv preprint arXiv:2108.13958 (2021) 4, 9, 22 16 C
Banik, P., Li, L., Dong, X.: A novel dataset for keypoint detection of quadruped animals from images. arXiv preprint arXiv:2108.13958 (2021) 4, 9, 22 16 C. Lu et al
-
[3]
IEEE transactions on pattern analysis and machine intelligence 35(12), 2930–2940 (2013) 4
Belhumeur, P.N., Jacobs, D.W., Kriegman, D.J., Kumar, N.: Localizing parts of faces using a consensus of exemplars. IEEE transactions on pattern analysis and machine intelligence 35(12), 2930–2940 (2013) 4
2013
-
[4]
Advances in neural information processing systems33, 1877–1901 (2020) 13
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J.D., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., et al.: Language models are few-shot learners. Advances in neural information processing systems33, 1877–1901 (2020) 13
1901
-
[5]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Cao, J., Tang, H., Fang, H.S., Shen, X., Lu, C., Tai, Y.W.: Cross-domain adapta- tion for animal pose estimation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 9498–9507 (2019) 4, 10, 22
2019
-
[6]
IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 1, 2, 3
Cao, Z., Hidalgo, G., Simon, T., Wei, S.E., Sheikh, Y.: Openpose: Realtime multi- person 2d pose estimation using part affinity fields. IEEE transactions on pattern analysis and machine intelligence43(1), 172–186 (2019) 1, 2, 3
2019
-
[7]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Carreira, J., Agrawal, P., Fragkiadaki, K., Malik, J.: Human pose estimation with iterative error feedback. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 4733–4742 (2016) 3
2016
-
[8]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 3
Chen, J., Luo, Z., Liu, Z., Jiang, W., Niu, L., Fang, Y.: Weak-shot keypoint es- timation via keyness and correspondence transfer. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025) 3
2025
-
[9]
In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition
Cheng, B., Xiao, B., Wang, J., Shi, H., Huang, T.S., Zhang, L.: Higherhrnet: Scale- aware representation learning for bottom-up human pose estimation. In: Proceed- ings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5386–5395 (2020) 1, 3
2020
-
[10]
In: Proceedings of the IEEE international conference on computer vision
Fang, H.S., Xie, S., Tai, Y.W., Lu, C.: Rmpe: Regional multi-person pose estima- tion. In: Proceedings of the IEEE international conference on computer vision. pp. 2334–2343 (2017) 3
2017
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ge, Y., Zhang, R., Wang, X., Tang, X., Luo, P.: Deepfashion2: A versatile bench- mark for detection, pose estimation, segmentation and re-identification of clothing images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5337–5345 (2019) 4, 24
2019
-
[12]
elife8, e47994 (2019) 4, 23
Graving, J.M., Chae, D., Naik, H., Li, L., Koger, B., Costelloe, B.R., Couzin, I.D.: Deepposekit, a software toolkit for fast and robust animal pose estimation using deep learning. elife8, e47994 (2019) 4, 23
2019
-
[13]
In: Alvey vision conference
Harris, C., Stephens, M., et al.: A combined corner and edge detector. In: Alvey vision conference. vol. 15, pp. 10–5244. Manchester, UK (1988) 1, 3
1988
-
[14]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., Girshick, R.: Masked autoencoders are scalable vision learners. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16000–16009 (2022) 7, 13
2022
-
[15]
In: European Conference on Computer Vision
Hirschorn, O., Avidan, S.: A graph-based approach for category-agnostic pose es- timation. In: European Conference on Computer Vision. pp. 469–485. Springer (2024) 2
2024
-
[16]
In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Honari, S., Molchanov, P., Tyree, S., Vincent, P., Pal, C., Kautz, J.: Improving landmark localization with semi-supervised learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 1546–1555 (2018) 3
2018
-
[17]
Advances in Neural Information Processing Systems36 (2024) 5
Jiao, B., Liu, L., Gao, L., Wu, R., Lin, G., Wang, P., Zhang, Y.: Toward re- identifying any animal. Advances in Neural Information Processing Systems36 (2024) 5
2024
-
[18]
Bioengineering11(9), 932 (2024) 3, 4, 5, 6, 10, 24 GKDT: General Keypoint Detection Transformer 17
Joham, S.J., Hadzic, A., Urschler, M.: Implicit is not enough: Explicitly enforcing anatomical priors inside landmark localization models. Bioengineering11(9), 932 (2024) 3, 4, 5, 6, 10, 24 GKDT: General Keypoint Detection Transformer 17
2024
-
[19]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Jose, C., Moutakanni, T., Kang, D., Baldassarre, F., Darcet, T., Xu, H., Li, D., Szafraniec, M., Ramamonjisoa, M., Oquab, M., et al.: Dinov2 meets text: A unified framework for image-and pixel-level vision-language alignment. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 24905–24916 (2025) 7
2025
-
[20]
In: 2021 IEEE international conference on robotics and au- tomation (ICRA)
Joska, D., Clark, L., Muramatsu, N., Jericevich, R., Nicolls, F., Mathis, A., Mathis, M.W., Patel, A.: Acinoset: a 3d pose estimation dataset and baseline models for cheetahs in the wild. In: 2021 IEEE international conference on robotics and au- tomation (ICRA). pp. 13901–13908. IEEE (2021) 4, 24
2021
-
[21]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ju, X., Zeng, A., Wang, J., Xu, Q., Zhang, L.: Human-art: A versatile human- centric dataset bridging natural and artificial scenes. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 618–629 (2023) 4, 9, 12, 22
2023
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Khan, M.H., McDonagh, J., Khan, S., Shahabuddin, M., Arora, A., Khan, F.S., Shao, L., Tzimiropoulos, G.: Animalweb: A large-scale hierarchical dataset of an- notated animal faces. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6939–6948 (2020) 4, 10, 23
2020
-
[23]
In: 2011 IEEE international conference on computer vision workshops (ICCV work- shops)
Koestinger, M., Wohlhart, P., Roth, P.M., Bischof, H.: Annotated facial landmarks in the wild: A large-scale, real-world database for facial landmark localization. In: 2011 IEEE international conference on computer vision workshops (ICCV work- shops). pp. 2144–2151. IEEE (2011) 4, 24
2011
-
[24]
in the wild
Labuguen, R., Matsumoto, J., Negrete, S.B., Nishimaru, H., Nishijo, H., Takada, M., Go, Y., Inoue, K.i., Shibata, T.: Macaquepose: a novel “in the wild” macaque monkey pose dataset for markerless motion capture. Frontiers in behavioral neu- roscience 14, 581154 (2021) 4, 23
2021
-
[25]
In: European conference on computer vision
Le, V., Brandt, J., Lin, Z., Bourdev, L., Huang, T.S.: Interactive facial feature localization. In: European conference on computer vision. pp. 679–692. Springer (2012) 4
2012
-
[26]
arXiv preprint arXiv:1906.05586 (2019) 4, 23
Li, S., Li, J., Tang, H., Qian, R., Lin, W.: Atrw: a benchmark for amur tiger re-identification in the wild. arXiv preprint arXiv:1906.05586 (2019) 4, 23
-
[27]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014) 4, 5, 7, 9, 10, 11, 12, 22
2014
-
[28]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., et al.: Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499 (2023) 5, 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Interna- tional journal of computer vision60(2), 91–110 (2004) 1, 3
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Interna- tional journal of computer vision60(2), 91–110 (2004) 1, 3
2004
-
[30]
Lu, C.: General Keypoint Detection: Few-Shot and Zero-Shot. Ph.D. thesis, The Australian National University (Australia) (2024) 2
2024
-
[31]
Neurocomputing409, 60–73 (2020) 4
Lu, C., Gu, C., Wu, K., Xia, S., Wang, H., Guan, X.: Deep transfer neural network using hybrid representations of domain discrepancy. Neurocomputing409, 60–73 (2020) 4
2020
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lu, C., Koniusz, P.: Few-shot keypoint detection with uncertainty learning for unseen species. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19416–19426 (2022) 2, 3, 10
2022
-
[33]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Lu, C., Koniusz, P.: Detect any keypoints: An efficient light-weight few-shot key- point detector. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 3882–3890 (2024) 2, 3 18 C. Lu et al
2024
-
[34]
In: European Conference on Computer Vision
Lu, C., Liu, Z., Koniusz, P.: Openkd: Opening prompt diversity for zero-and few- shot keypoint detection. In: European Conference on Computer Vision. pp. 148–
-
[35]
Springer (2024) 2, 4, 6, 9, 10, 11, 22, 23
2024
-
[36]
Lu, C., Wang, H., Gu, C., Wu, K., Guan, X.: Viewpoint estimation for workpieces withdeeptransferlearningfromcoldtohot.In:InternationalConferenceonNeural Information Processing. pp. 21–32. Springer (2018) 4
2018
-
[37]
International Journal of Computer Vision134(2), 63 (2026) 2, 3
Lu, C., Zhu, H., Koniusz, P.: Exploiting class-agnostic visual prior for few-shot keypoint detection. International Journal of Computer Vision134(2), 63 (2026) 2, 3
2026
-
[38]
Stanford University (1980) 1
Moravec, H.P.: Obstacle avoidance and navigation in the real world by a seeing robot rover. Stanford University (1980) 1
1980
-
[39]
arXiv preprint arXiv:2101.07988 (2021) 3
Moskvyak, O., Maire, F., Dayoub, F., Baktashmotlagh, M.: Semi-supervised key- point localization. arXiv preprint arXiv:2101.07988 (2021) 3
-
[40]
In: European conference on computer vision
Newell, A., Yang, K., Deng, J.: Stacked hourglass networks for human pose esti- mation. In: European conference on computer vision. pp. 483–499. Springer (2016) 1, 3
2016
-
[41]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ng, X.L., Ong, K.E., Zheng, Q., Ni, Y., Yeo, S.Y., Liu, J.: Animal kingdom: A large and diverse dataset for animal behavior understanding. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 19023– 19034 (2022) 4, 23
2022
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Pavlakos, G., Shan, D., Radosavovic, I., Kanazawa, A., Fouhey, D., Malik, J.: Reconstructing hands in 3d with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9826–9836 (2024) 4, 22
2024
-
[43]
Na- ture methods 16(1), 117–125 (2019) 4, 23
Pereira, T.D., Aldarondo, D.E., Willmore, L., Kislin, M., Wang, S.S.H., Murthy, M., Shaevitz, J.W.: Fast animal pose estimation using deep neural networks. Na- ture methods 16(1), 117–125 (2019) 4, 23
2019
-
[44]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021) 4
2021
-
[45]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Reddy, N.D., Vo, M., Narasimhan, S.G.: Carfusion: Combining point tracking and part detection for dynamic 3d reconstruction of vehicles. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1906–1915 (2018) 4, 23
1906
-
[46]
Image and vision computing47, 3–18 (2016) 4, 22
Sagonas, C., Antonakos, E., Tzimiropoulos, G., Zafeiriou, S., Pantic, M.: 300 faces in-the-wild challenge: Database and results. Image and vision computing47, 3–18 (2016) 4, 22
2016
-
[47]
In: Proceedings of the IEEE international conference on computer vision workshops
Sagonas, C., Tzimiropoulos, G., Zafeiriou, S., Pantic, M.: 300 faces in-the-wild challenge: The first facial landmark localization challenge. In: Proceedings of the IEEE international conference on computer vision workshops. pp. 397–403 (2013) 4
2013
-
[48]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Shi, M., Huang, Z., Ma, X., Hu, X., Cao, Z.: Matching is not enough: A two- stage framework for category-agnostic pose estimation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7308– 7317 (2023) 10, 11
2023
-
[49]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Shi, W., Lu, C., Shao, M., Zhang, Y., Xia, S., Koniusz, P.: Few-shot shape recog- nition by learning deep shape-aware features. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 1848–1859 (2024) 3 GKDT: General Keypoint Detection Transformer 19
2024
-
[50]
Siméoni, O., Vo, H.V., Seitzer, M., Baldassarre, F., Oquab, M., Jose, C., Khali- dov, V., Szafraniec, M., Yi, S., Ramamonjisoa, M., et al.: Dinov3. arXiv preprint arXiv:2508.10104 (2025) 3, 4, 7, 10, 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[51]
Prototypical Networks for Few-shot Learning
Snell, J., Swersky, K., Zemel, R.S.: Prototypical networks for few-shot learning. arXiv preprint arXiv:1703.05175 (2017) 3
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[52]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, K., Xiao, B., Liu, D., Wang, J.: Deep high-resolution representation learn- ing for human pose estimation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5693–5703 (2019) 1, 2, 3
2019
-
[53]
Sung, F., Yang, Y., Zhang, L., Xiang, T., Torr, P.H., Hospedales, T.M.: Learning to compare:Relationnetworkforfew-shotlearning.In:ProceedingsoftheIEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1199–1208 (2018) 3
2018
-
[54]
Advances in neural information processing systems27 (2014) 3
Tompson, J.J., Jain, A., LeCun, Y., Bregler, C.: Joint training of a convolutional network and a graphical model for human pose estimation. Advances in neural information processing systems27 (2014) 3
2014
-
[55]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Toshev, A., Szegedy, C.: Deeppose: Human pose estimation via deep neural net- works. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1653–1660 (2014) 3
2014
-
[56]
In: Proceedings of the IEEEConferenceonComputerVisionandPatternRecognition.pp.595–604(2015) 4, 10, 23
Van Horn, G., Branson, S., Farrell, R., Haber, S., Barry, J., Ipeirotis, P., Perona, P., Belongie, S.: Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. In: Proceedings of the IEEEConferenceonComputerVisionandPatternRecognition.pp.595–604(2015) 4, 10, 23
2015
-
[57]
Advances in neural information pro- cessing systems 30 (2017) 2
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems 30 (2017) 2
2017
-
[58]
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The Caltech-UCSD Birds-200-2011 Dataset. Tech. Rep. CNS-TR-2011-001, California Institute of Technology (2011) 4, 10, 22
2011
-
[59]
arXiv preprint arXiv:2201.08613 (2022) 3
Wang, C., Jin, S., Guan, Y., Liu, W., Qian, C., Luo, P., Ouyang, W.: Pseudo- labeled auto-curriculum learning for semi-supervised keypoint localization. arXiv preprint arXiv:2201.08613 (2022) 3
-
[60]
Medical image analysis31, 63–76 (2016) 3, 4, 6, 24
Wang, C.W., Huang, C.T., Lee, J.H., Li, C.H., Chang, S.W., Siao, M.J., Lai, T.M., Ibragimov, B., Vrtovec, T., Ronneberger, O., et al.: A benchmark for comparison of dental radiography analysis algorithms. Medical image analysis31, 63–76 (2016) 3, 4, 6, 24
2016
-
[61]
IEEE Transactions on Circuits and Systems for Video Technology 29(11), 3258–3268 (2018) 4, 22
Wang, Y., Peng, C., Liu, Y.: Mask-pose cascaded cnn for 2d hand pose estimation from single color image. IEEE Transactions on Circuits and Systems for Video Technology 29(11), 3258–3268 (2018) 4, 22
2018
-
[62]
In: European Conference on Computer Vision
Wu, J., Xue, T., Lim, J.J., Tian, Y., Tenenbaum, J.B., Torralba, A., Freeman, W.T.: Single image 3d interpreter network. In: European Conference on Computer Vision. pp. 365–382. Springer (2016) 4, 23
2016
-
[63]
In: 2021 International Conference on control, au- tomation and information sciences (ICCAIS)
Wu, X., Lu, C., Gu, C., Wu, K., Zhu, S.: Domain adaptation for viewpoint esti- mation with image generation. In: 2021 International Conference on control, au- tomation and information sciences (ICCAIS). pp. 341–346. IEEE (2021) 4
2021
-
[64]
In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition
Xian, Y., Schiele, B., Akata, Z.: Zero-shot learning-the good, the bad and the ugly. In:ProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition. pp. 4582–4591 (2017) 10
2017
-
[65]
In: European confer- ence on computer vision
Xu, L., Jin, S., Zeng, W., Liu, W., Qian, C., Ouyang, W., Luo, P., Wang, X.: Pose for everything: Towards category-agnostic pose estimation. In: European confer- ence on computer vision. pp. 398–416. Springer (2022) 2, 5 20 C. Lu et al
2022
-
[66]
IEEE Transactions on Pattern Analysis and Machine Intel- ligence 46(2), 1212–1230 (2023) 1, 2, 3, 7, 11, 12
Xu, Y., Zhang, J., Zhang, Q., Tao, D.: Vitpose++: Vision transformer for generic body pose estimation. IEEE Transactions on Pattern Analysis and Machine Intel- ligence 46(2), 1212–1230 (2023) 1, 2, 3, 7, 11, 12
2023
-
[67]
In: European Conference on Computer Vision
Yang, J., Zeng, A., Zhang, R., Zhang, L.: X-pose: Detecting any keypoints. In: European Conference on Computer Vision. pp. 249–268. Springer (2024) 2, 4, 5, 6, 10, 11, 12, 13, 24
2024
-
[68]
Advances in Neural Informa- tion Processing Systems35, 17301–17313 (2022) 4, 24
Yang, Y., Yang, J., Xu, Y., Zhang, J., Lan, L., Tao, D.: Apt-36k: A large-scale benchmark for animal pose estimation and tracking. Advances in Neural Informa- tion Processing Systems35, 17301–17313 (2022) 4, 24
2022
-
[69]
arXiv preprint arXiv:2203.074364(5) (2022) 4, 23
Ye, S., Filippova, A., Lauer, J., Vidal, M., Schneider, S., Qiu, T., Mathis, A., Mathis, M.W.: Superanimal models pretrained for plug-and-play analysis of animal behavior. arXiv preprint arXiv:2203.074364(5) (2022) 4, 23
-
[70]
arXiv preprint arXiv:2108.12617 (2021)
Yu, H., Xu, Y., Zhang, J., Zhao, W., Guan, Z., Tao, D.: Ap-10k: A benchmark for animal pose estimation in the wild. arXiv preprint arXiv:2108.12617 (2021) 2, 4, 10, 23
-
[71]
In- ternational Journal of Computer Vision132(12), 5741–5758 (2024) 2, 4, 5
Zhang, H., Xu, L., Lai, S., Shao, W., Zheng, N., Luo, P., Qiao, Y., Zhang, K.: Open-vocabulary animal keypoint detection with semantic-feature matching. In- ternational Journal of Computer Vision132(12), 5741–5758 (2024) 2, 4, 5
2024
-
[72]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhang, X., Wang, W., Chen, Z., Xu, Y., Zhang, J., Tao, D.: Clamp: Prompt-based contrastive learning for connecting language and animal pose. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 23272– 23281 (2023) 2, 4, 5
2023
-
[73]
International Jour- nal of Computer Vision pp
Zhao, S., Gong, M., Zhao, H., Zhang, J., Tao, D.: Deep corner. International Jour- nal of Computer Vision pp. 1–25 (2023) 3
2023
-
[74]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhou, B., Zhou, H., Liang, T., Yu, Q., Zhao, S., Zeng, Y., Lv, J., Luo, S., Wang, Q., Yu, X., et al.: Clothesnet: An information-rich 3d garment model repository with simulated clothes environment. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20428–20438 (2023) 1
2023
-
[75]
In: 2012 IEEE conference on computer vision and pattern recognition
Zhu, X., Ramanan, D.: Face detection, pose estimation, and landmark localization in the wild. In: 2012 IEEE conference on computer vision and pattern recognition. pp. 2879–2886. IEEE (2012) 4 GKDT: General Keypoint Detection Transformer (Supplementary Material) Changsheng Lu1, Yuxin Chen1, Haokun Gui1, Rong Wang2, Jie Yang3, Harry Yang1, Anton van den Hen...
2012
-
[76]
To ease the usage of this dataset, we release above splits at https://github.com/AlanLuSun/General-Keypoint-Detection
are only used for training. To ease the usage of this dataset, we release above splits at https://github.com/AlanLuSun/General-Keypoint-Detection. C Additional Implementation Details In our detection head, the upsamplerU can be either bilinear upsampler or two deconv blocks, which are for upscaling the resolution of query image feature maps. We find that ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.