Automatic selection of hyper-parameters via the use of softened profile likelihood
Pith reviewed 2026-05-21 19:30 UTC · model grok-4.3
The pith
A softened profile likelihood allows automatic simultaneous selection of multiple hyperparameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We extend a heuristic method for automatic dimensionality selection, which maximizes a profile likelihood to identify elbows in scree plots. Our extension enables researchers to make automatic choices of multiple hyper-parameters simultaneously. To facilitate our extension to multi-dimensions, we propose a softened profile likelihood. We present two distinct parameterizations of our solution and demonstrate our approach on elastic nets, support vector machines, and neural networks.
What carries the argument
The softened profile likelihood, a modified objective that smooths the standard profile likelihood to identify elbows across multiple hyper-parameter dimensions at once.
If this is right
- Multiple hyperparameters in models such as elastic nets or neural networks can be chosen automatically instead of one at a time.
- The same softened objective applies to other tasks that previously used profile likelihood for single-parameter selection.
- Two different parameterizations give users flexibility when applying the method to new models.
- Researchers gain a heuristic alternative to exhaustive search when tuning several parameters jointly.
Where Pith is reading between the lines
- If the method scales, it could lower the computational cost of hyper-parameter search in high-dimensional tuning spaces.
- The softening idea might generalize to other elbow-detection or profile-based selection problems in statistics.
- Larger-scale tests on diverse datasets would help determine whether the simulation results hold in typical practice.
Load-bearing premise
The data and model satisfy an unspecified assumption that lets the softened profile likelihood correctly locate good hyper-parameter values, with robustness checked only in a small simulation study.
What would settle it
A real-data or larger simulation experiment in which hyperparameters chosen by the softened profile likelihood produce clearly worse out-of-sample performance than those chosen by grid search or cross-validation.
Figures
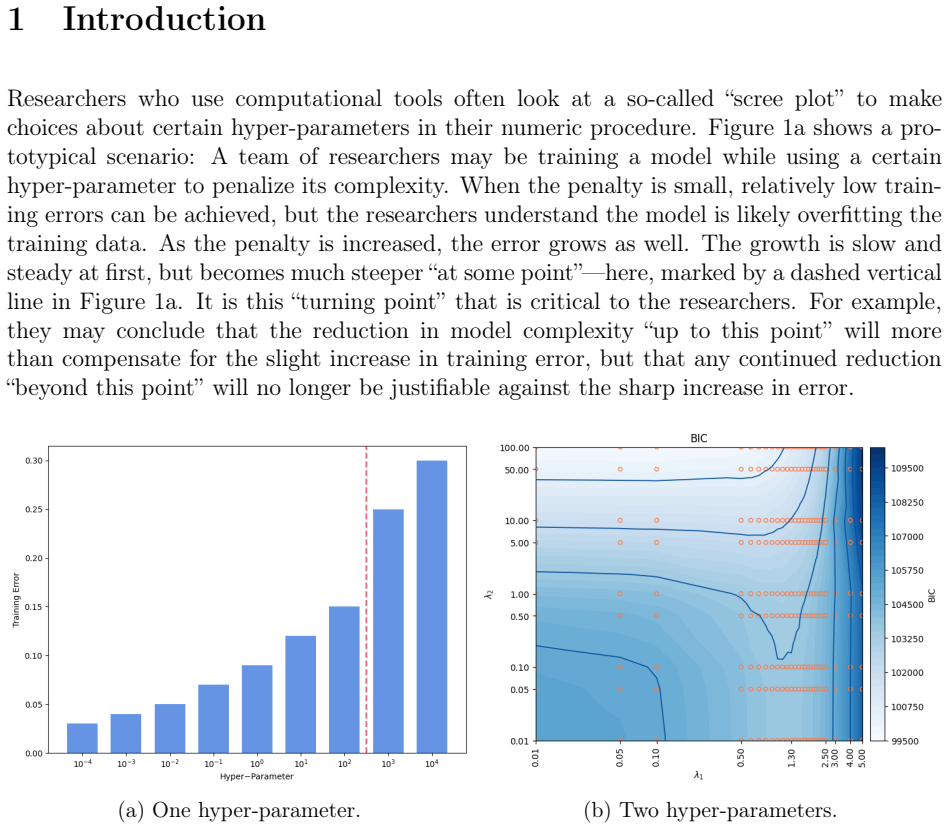
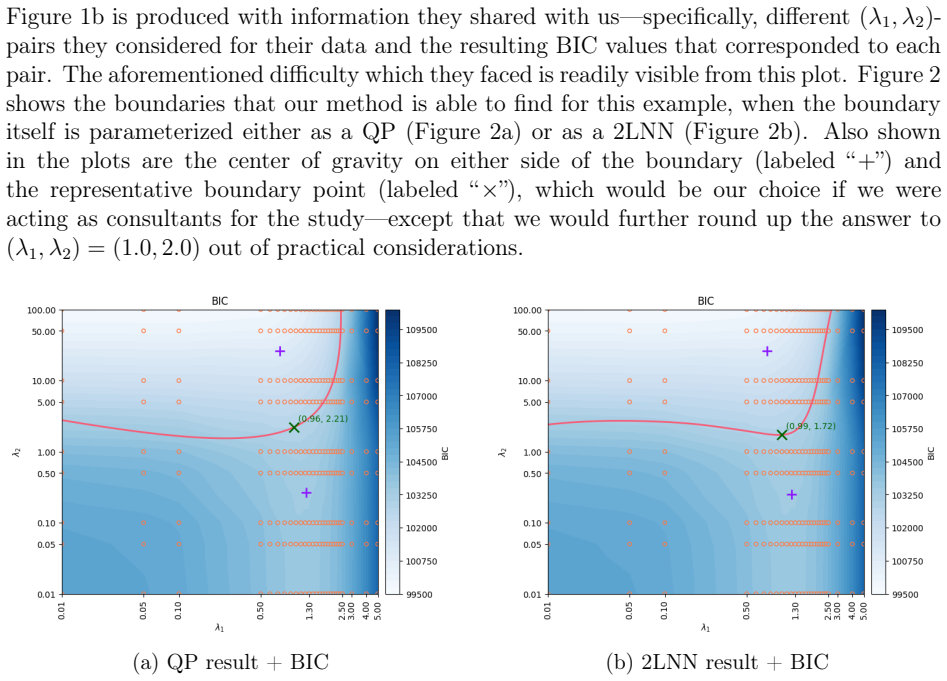
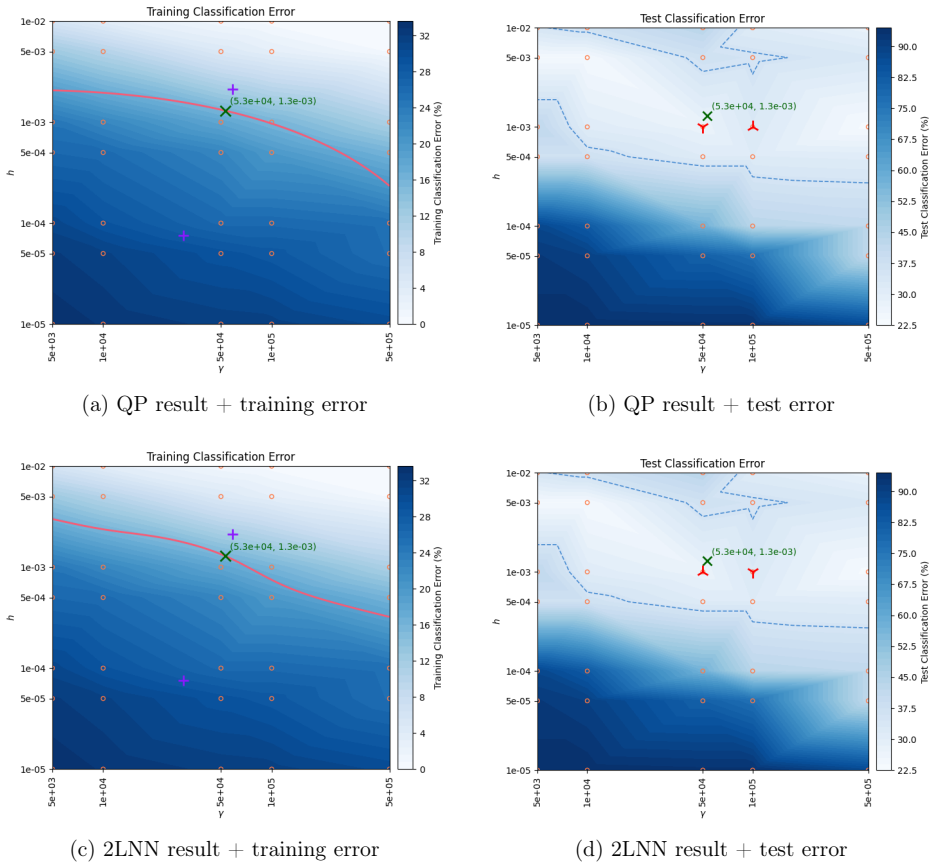
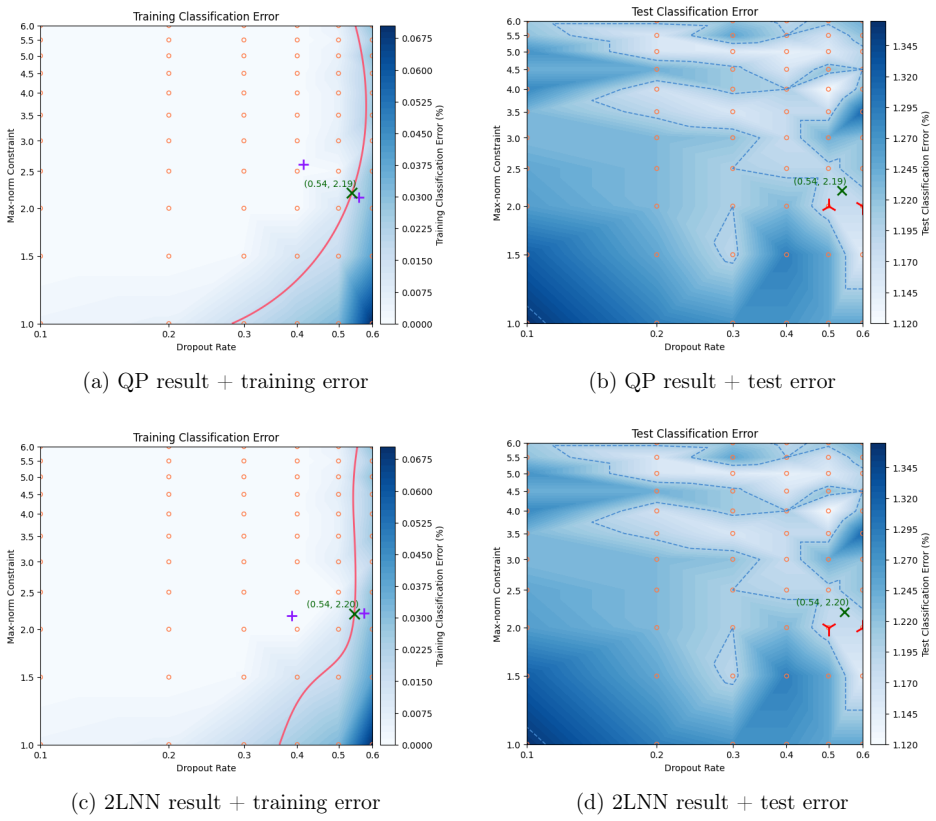
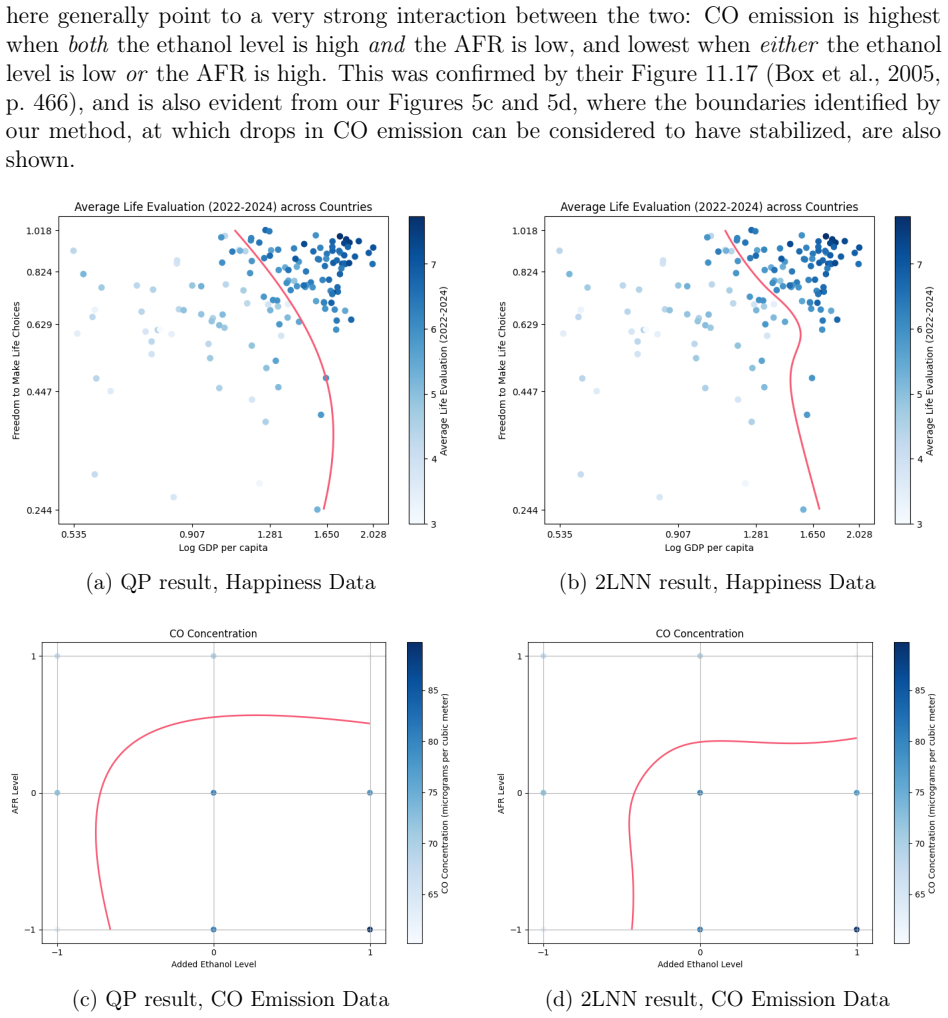
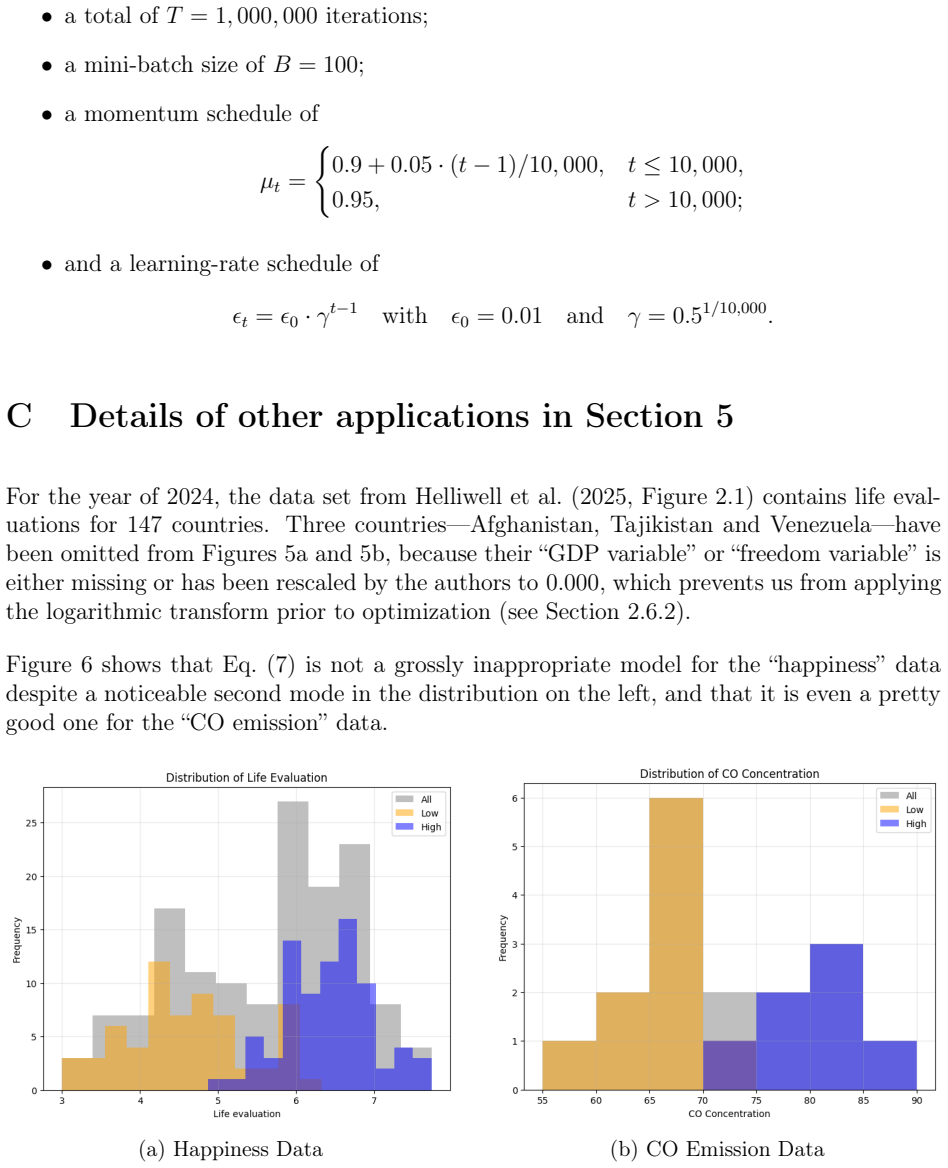
read the original abstract
We extend a heuristic method for automatic dimensionality selection, which maximizes a profile likelihood to identify "elbows" in scree plots. Our extension enables researchers to make automatic choices of multiple hyper-parameters simultaneously. To facilitate our extension to multi-dimensions, we propose a "softened" profile likelihood. We present two distinct parameterizations of our solution and demonstrate our approach on elastic nets, support vector machines, and neural networks. We also report a small simulation study to investigate violations to an assumption we make, and briefly discuss applications of our method to other data-analytic tasks than hyper-parameter selection.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends a heuristic for automatic dimensionality selection that maximizes a profile likelihood to locate elbows in scree plots. The central contribution is a softened profile likelihood that permits simultaneous automatic selection of multiple hyper-parameters. Two distinct parameterizations are introduced, the method is demonstrated on elastic-net, SVM, and neural-network models, and a small simulation study examines violations of an underlying assumption; applications beyond hyper-parameter tuning are briefly discussed.
Significance. If the softened profile likelihood reliably recovers good joint hyper-parameter values, the approach would supply a computationally attractive alternative to exhaustive search or cross-validation when tuning several parameters at once. The demonstrations across three distinct model classes and the explicit check of the key assumption are positive features that strengthen the practical claim.
major comments (2)
- [§3 and simulation study] The multi-dimensional extension rests on an assumption (required for the softening operation to preserve the relevant maxima) that is not stated explicitly in the main text. Validation is confined to a small simulation study; if the assumption fails on non-convex surfaces typical of neural-network training or on correlated penalties in elastic nets, the automatic-selection claim does not hold. This is load-bearing for the central contribution.
- [§4 and §5] No theoretical results (convergence, bounds on the location of the softened maximum, or consistency under standard regularity conditions) are supplied to support the multi-dimensional procedure. The demonstrations therefore rest entirely on empirical behavior whose generality remains uncharacterized.
minor comments (2)
- [§3] Notation for the two parameterizations of the softened profile likelihood should be introduced with a single consistent symbol set rather than ad-hoc subscripts.
- [simulation study] The simulation study would benefit from reporting the exact sample sizes, number of replications, and the precise metric used to declare a violation of the assumption.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We appreciate the positive assessment of the practical aspects and the identification of areas for improvement. We address the major comments below and have revised the manuscript to make the underlying assumption explicit while acknowledging the heuristic nature of the approach.
read point-by-point responses
-
Referee: [§3 and simulation study] The multi-dimensional extension rests on an assumption (required for the softening operation to preserve the relevant maxima) that is not stated explicitly in the main text. Validation is confined to a small simulation study; if the assumption fails on non-convex surfaces typical of neural-network training or on correlated penalties in elastic nets, the automatic-selection claim does not hold. This is load-bearing for the central contribution.
Authors: We thank the referee for highlighting this important point. We agree that the assumption should be stated more explicitly in the main text. In the revised manuscript, we have inserted a clear statement of the assumption in Section 3, specifying that the softening preserves the relevant maxima when the profile likelihood exhibits the expected elbow behavior or when the softening parameter is sufficiently small. Regarding the simulation study, while it is indeed small, it was designed to probe specific violations of the assumption in controlled settings. We have expanded the discussion to address potential issues with non-convex surfaces in neural network training and correlated penalties in elastic nets, noting that the empirical results in Sections 4 and 5 provide evidence of practical utility even in these cases. We believe this strengthens the central contribution without overclaiming generality. revision: yes
-
Referee: [§4 and §5] No theoretical results (convergence, bounds on the location of the softened maximum, or consistency under standard regularity conditions) are supplied to support the multi-dimensional procedure. The demonstrations therefore rest entirely on empirical behavior whose generality remains uncharacterized.
Authors: We acknowledge the absence of theoretical results in the manuscript. The proposed method is an extension of a heuristic for automatic hyper-parameter selection, and our primary aim is to demonstrate its applicability across different models through empirical examples. Developing rigorous theoretical guarantees, such as convergence properties or consistency under regularity conditions, would require substantial additional work, especially given the complexities of non-convex optimization in neural networks. We have added a paragraph in the discussion section noting this limitation and suggesting it as a direction for future research. The strength of the paper lies in the practical demonstrations rather than theoretical characterization. revision: partial
Circularity Check
No significant circularity; extension of external heuristic with independent simulation check
full rationale
The paper frames its contribution as an extension of a pre-existing heuristic method for dimensionality selection via profile likelihood maximization on scree plots. No equations or derivations are presented that reduce a claimed prediction or result to a fitted parameter or self-defined quantity by construction. The multi-dimensional softening and the assumption about preserving maxima are introduced as proposals, with violations investigated via a separate small simulation study rather than being presupposed in the definition of the method itself. This keeps the central claim self-contained against external benchmarks and avoids any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Profile likelihood maximization can locate optimal hyper-parameter values by detecting elbows in appropriate plots.
invented entities (1)
-
softened profile likelihood
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinctionreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
maximizing a profile log-likelihood function... boundary curve g(u; ω) = 0
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Box, G. E. P., Hunter, J. S., and Hunter, W. G. (2005).Statistics for Experimenters: Design, Innovation, and Discovery . Wiley, 2nd edition
work page 2005
-
[2]
Chang, M.-C., Tung, C.-H., Chang, S.-Y., Carrillo, J. M., Wang, Y., Sumpter, B. G., Huang, G.-R., Do, C., and Chen, W.-R. (2022). A machine learning inversion scheme for deter- mining interaction from scattering.Communications Physics, 5:46
work page 2022
-
[3]
Cortes, C. and Vapnik, V. (1995). Support-vector networks.Machine Learning, 20:273–297
work page 1995
-
[4]
Fogel, P., Young, S. S., Hawkins, D. M., and Ledirac, N. (2007). Inferential, robust non- negative matrix factorization analysis of microarray data.Bioinformatics, 23(1):44–49
work page 2007
-
[5]
Hamady, M., Lozupone, C., and Knight, R. (2010). Fast UniFrac: facilitating high- throughput phylogenetic analyses of microbial communities including analysis of pyrose- quencing and PhyloChip data.The ISME Journal: Multidisciplinary Journal of Microbial Ecology, 4(1):17–27
work page 2010
-
[6]
Helliwell, J. F., Layard, R., Sachs, J. D., De Neve, J.-E., Aknin, L. B., and Wang, S., editors (2025). World Happiness Report 2025 . University of Oxford: Wellbeing Research Centre
work page 2025
-
[7]
Honarkhah, M. and Caers, J. (2010). Stochastic simulation of patterns using distance-based pattern modeling. Mathematical Geosciences, 42(5):487–517
work page 2010
-
[8]
Jian, J., Sang, P., andZhu, M. (2024). Two Gaussianregularizationmethodsfortime-varying networks. Journal of Agricultural, Biological and Environmental Statistics , 29:853–873
work page 2024
-
[9]
Kingma, D. P. and Ba, J. (2014). ADAM: A method for stochastic optimization. arXiv preprint arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[10]
Lai, C.-Q., Tucker, K. L., Choudhry, S., Parnell, L. D., Mattei, J., García-Bailo, B., Beck- man, K., Burchard, E. G., and Ordovás, J. M. (2009). Population admixture associ- ated with disease prevalence in the Boston Puerto Rican health study.Human Genetics, 125:199–209
work page 2009
-
[11]
Lyzinski, V., Tang, M., Athreya, A., Park, Y., and Priebe, C. E. (2017). Community detection and classification in hierarchical stochastic blockmodels.IEEE Transactions on Network Science and Engineering , 4(1):13–26
work page 2017
-
[12]
Nocedal, J. and Wright, S. J. (2006).Numerical Optimization. Springer Series in Operations Research and Financial Engineering. Springer New York, NY, 2 edition
work page 2006
-
[13]
Priebe, C. E., Park, Y., Vogelstein, J. T., Conroy, J. M., Lyzinski, V., Tang, M., Athreya, A., Cape, J., and Bridgeford, E. (2019). On a two-truths phenomenon in spectral graph clustering. Proceedings of the National Academy of Sciences , 116(13):5995–6000. 23
work page 2019
-
[14]
Sakar, B. E., Isenkul, M. E., Sakar, C. O., Sertbas, A., Gurgen, F., Delil, S., Apaydin, H., and Kursun, O. (2013). Collection and analysis of a Parkinson speech dataset with multiple types of sound recordings.IEEE Journal of Biomedical and Health Informatics , 17(4):828–834
work page 2013
-
[15]
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting.Journal of Machine Learning Research, 15(56):1929–1958
work page 2014
-
[16]
L., Lyzinski, V., Park, Y., and Priebe, C
Tang, M., Athreya, A., Sussman, D. L., Lyzinski, V., Park, Y., and Priebe, C. E. (2017). A semiparametric two-sample hypothesis testing problem for random graphs.Journal of Computational and Graphical Statistics , 26(2):344–354
work page 2017
-
[17]
Zhong, F., Rosenberg, M., Agterberg, J., and Crabb, R. (2021). Social determinant–based profiles of U.S. adults with the highest and lowest health expenditures using clusters. North American Actuarial Journal , 25(1):115–133
work page 2021
-
[18]
Zhu, M. and Ghodsi, A. (2006). Automatic dimensionality selection from the scree plot via the use of profile likelihood.Computational Statistics & Data Analysis , 51(2):918–930
work page 2006
-
[19]
Zou, H. and Hastie, T. J. (2005). Regularization and variable selection via the elastic net. Journal of the Royal Statistical Society, Series B , 67(2):301–320. 24
work page 2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.