Modeling Nonlinear Feature Interactions with Product-Unit Residual Networks
Pith reviewed 2026-06-27 22:35 UTC · model grok-4.3
The pith
Product-unit residual networks explicitly model nonlinear feature interactions with multiplicative units and residuals, outperforming MLPs in robustness and interaction interpretability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
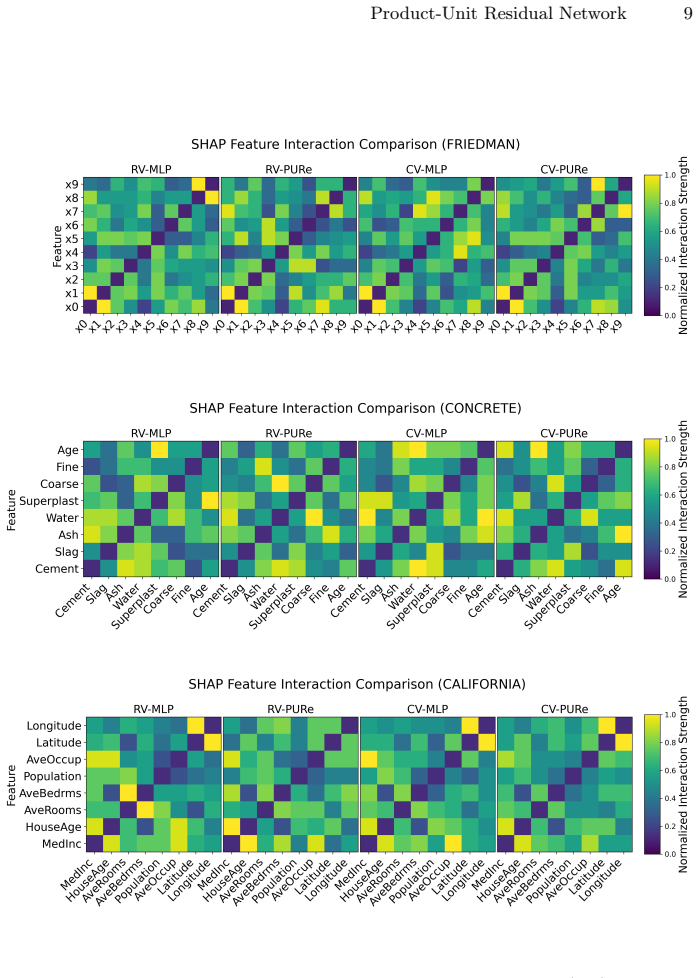
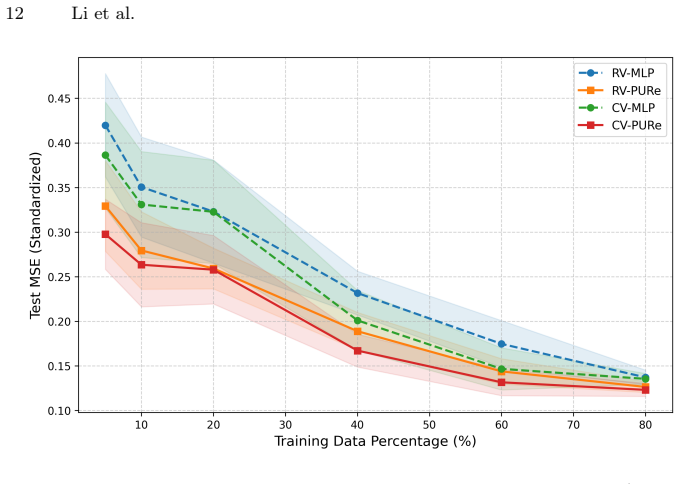
PURe integrates multiplicative product units with residual connections to explicitly model nonlinear feature interactions while stabilizing optimization. On an interaction-driven synthetic benchmark and two real-world datasets, real- and complex-valued PURe variants under a matched parameter budget achieve competitive or improved predictive accuracy, greater robustness to Gaussian feature noise, and better sample efficiency in low-data regimes than MLP baselines; SHAP analyses further show that the learned interaction patterns are more concentrated and structurally coherent.
What carries the argument
The product-unit residual block, which inserts multiplicative product units for explicit cross-feature multiplication inside residual connections to capture couplings directly.
If this is right
- PURe reaches competitive or higher predictive accuracy on tasks driven by nonlinear feature interactions.
- The networks maintain accuracy better than MLPs when input features receive Gaussian noise.
- Sample efficiency improves relative to MLPs when training data is limited.
- SHAP explanations display interaction patterns that are more concentrated and structurally coherent than those from MLPs.
Where Pith is reading between the lines
- The same multiplicative-residual pattern could be tested on problems outside the paper's datasets, such as physical simulation tasks that rely on known interaction laws.
- Higher-order product units might be added to capture interactions among more than two features without changing the residual backbone.
- Direct comparison against polynomial networks or other explicit-interaction baselines on the same benchmarks would isolate the contribution of the residual-plus-product combination.
Load-bearing premise
The synthetic interaction benchmark and the two real-world datasets are representative of the broader class of interaction-driven problems so that performance differences will generalize.
What would settle it
Finding a new dataset with nonlinear interactions where PURe shows no advantage over MLPs in robustness to noise or in the concentration and coherence of SHAP interaction patterns would falsify the central performance claim.
Figures

read the original abstract
Understanding nonlinear feature interactions is crucial in science and engineering, yet standard multilayer perceptrons (MLPs) often capture such interactions only implicitly, leading to entangled representations that can impair robustness and interpretability. We investigate product-unit residual networks (PURe) that integrate multiplicative product units with residual connections to explicitly model cross-feature couplings while stabilizing optimization. We conduct a systematic evaluation on an interaction-driven synthetic benchmark and two real-world datasets, assessing predictive accuracy, robustness to Gaussian feature noise, and performance under limited training data, and we compare real- and complex-valued variants under a matched parameter budget. Beyond accuracy, SHapley Additive exPlanations (SHAP)-based interaction analyses show that PURe learns more concentrated and structurally coherent interaction patterns than MLP baselines. Overall, PURe achieves competitive or improved performance, better robustness and sample efficiency in low-data regimes, and enhanced interaction-level interpretability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes product-unit residual networks (PURe) that combine multiplicative product units with residual connections to explicitly model nonlinear cross-feature interactions. It reports a systematic comparison against MLPs on an interaction-driven synthetic benchmark and two real-world datasets (under matched parameter budgets), claiming competitive or superior accuracy, improved robustness to Gaussian feature noise, better sample efficiency in low-data regimes, and more concentrated/structured interaction patterns as measured by SHAP. Both real- and complex-valued variants are evaluated.
Significance. If the claimed gains in accuracy, robustness, sample efficiency, and SHAP coherence are shown to arise from the architecture rather than from properties of the chosen benchmarks, the work would provide a concrete architectural alternative for tasks where explicit interaction modeling matters. The emphasis on SHAP-based interaction analysis is a constructive step toward interpretability.
major comments (1)
- [Experiments] Experiments section (synthetic benchmark construction): the manuscript provides no description of how interactions are injected into the synthetic data, the distribution of interaction orders or sparsity, or the criteria used to select the two real-world datasets. Because the central claim is that PURe improves modeling of nonlinear feature interactions in general, the absence of these details leaves open the possibility that observed differences reflect alignment with the evaluation suite rather than a general architectural advantage.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The point regarding insufficient experimental details is well-taken, and we will revise the paper accordingly to strengthen the presentation of our evaluation.
read point-by-point responses
-
Referee: [Experiments] Experiments section (synthetic benchmark construction): the manuscript provides no description of how interactions are injected into the synthetic data, the distribution of interaction orders or sparsity, or the criteria used to select the two real-world datasets. Because the central claim is that PURe improves modeling of nonlinear feature interactions in general, the absence of these details leaves open the possibility that observed differences reflect alignment with the evaluation suite rather than a general architectural advantage.
Authors: We agree that the current manuscript lacks sufficient detail on these aspects of the experimental design. In the revised version, we will expand the Experiments section with: (i) a precise description of the synthetic data generation process, including the functional forms used to inject nonlinear interactions, the distribution over interaction orders, and sparsity patterns; and (ii) explicit criteria for selecting the two real-world datasets (domain relevance, presence of known feature couplings, size, and preprocessing). These additions will make it clearer that the reported advantages are not an artifact of benchmark alignment. revision: yes
Circularity Check
No circularity in derivation chain; claims rest on empirical evaluation
full rationale
The paper introduces product-unit residual networks (PURe) as an architectural proposal and evaluates them empirically on a synthetic benchmark and two real-world datasets for accuracy, robustness, sample efficiency, and SHAP interpretability. No equations, fitted parameters renamed as predictions, self-citations as load-bearing premises, or uniqueness theorems are referenced in the abstract or described in the provided text. The central claims derive from comparative experiments under matched parameter budgets rather than any self-referential mathematical reduction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems32(2019)
Allen-Zhu, Z., Li, Y., Song, Z.: On the convergence rate of training recurrent neural networks. Advances in neural information processing systems32(2019)
2019
-
[2]
Springer (2006)
Bishop, C.M., Nasrabadi, N.M.: Pattern recognition and machine learning. Springer (2006)
2006
-
[3]
Mathe- matics of control, signals and systems2(4), 303–314 (1989)
Cybenko, G.: Approximation by superpositions of a sigmoidal function. Mathe- matics of control, signals and systems2(4), 303–314 (1989)
1989
-
[4]
Physics Letters B852, 138608 (2024)
Dellen, B., Jaekel, U., Freitas, P.S., Clark, J.W.: Predicting nuclear masses with product-unit networks. Physics Letters B852, 138608 (2024)
2024
-
[5]
In: Computational Science–ICCS 2019: 19th International Conference,Faro,Portugal,June12–14,2019,Proceedings,PartII19.pp.174–188
Dellen, B., Jaekel, U., Wolnitza, M.: Function and pattern extrapolation with product-unit networks. In: Computational Science–ICCS 2019: 19th International Conference,Faro,Portugal,June12–14,2019,Proceedings,PartII19.pp.174–188. Springer (2019) Product-Unit Residual Network 15
2019
-
[6]
Neural computation 1(1), 133–142 (1989)
Durbin, R., Rumelhart, D.E.: Product units: A computationally powerful and bi- ologically plausible extension to backpropagation networks. Neural computation 1(1), 133–142 (1989)
1989
-
[7]
The annals of statistics 19(1), 1–67 (1991)
Friedman, J.H.: Multivariate adaptive regression splines. The annals of statistics 19(1), 1–67 (1991)
1991
-
[8]
In: Proceedings of the IEEE interna- tional conference on computer vision
He, K., Zhang, X., Ren, S., Sun, J.: Delving deep into rectifiers: Surpassing human- level performance on imagenet classification. In: Proceedings of the IEEE interna- tional conference on computer vision. pp. 1026–1034 (2015)
2015
-
[9]
He,K.,Zhang,X.,Ren,S.,Sun,J.:Deepresiduallearningforimagerecognition.In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 770–778 (2016)
2016
-
[10]
Advances in Neural Information Processing Systems7, 537 (1995)
Leerink, L.R., Giles, C.L., Horne, B.G., Jabri, M.A.: Learning with product units. Advances in Neural Information Processing Systems7, 537 (1995)
1995
-
[11]
In: International Conference on Computational Science
Li, Z., Jaekel, U., Dellen, B.: Data-driven 3d shape completion with product units. In: International Conference on Computational Science. pp. 302–315. Springer (2024)
2024
-
[12]
In: International Conference on Neural In- formation Processing
Li, Z., Jaekel, U., Dellen, B.: Advancing complex-valued neural networks with product units for mri reconstruction. In: International Conference on Neural In- formation Processing. pp. 540–554. Springer (2025)
2025
-
[13]
arXiv preprint arXiv:2505.04397 (2025)
Li, Z., Jaekel, U., Dellen, B.: Deep residual learning with product units. arXiv preprint arXiv:2505.04397 (2025)
arXiv 2025
-
[14]
Advances in neural information processing systems30(2017)
Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. Advances in neural information processing systems30(2017)
2017
-
[15]
In: Joint European conference on machine learning and knowledge discovery in databases
Molnar, C., Casalicchio, G., Bischl, B.: Interpretable machine learning–a brief his- tory, state-of-the-art and challenges. In: Joint European conference on machine learning and knowledge discovery in databases. pp. 417–431. Springer (2020)
2020
-
[16]
Statistics & Probability Let- ters33(3), 291–297 (1997)
Pace, R.K., Barry, R.: Sparse spatial autoregressions. Statistics & Probability Let- ters33(3), 291–297 (1997)
1997
-
[17]
arXiv preprint arXiv:1801.00173 (2017)
Poggio, T., Kawaguchi, K., Liao, Q., Miranda, B., Rosasco, L., Boix, X., Hidary, J., Mhaskar, H.: Theory of deep learning iii: explaining the non-overfitting puzzle. arXiv preprint arXiv:1801.00173 (2017)
Pith/arXiv arXiv 2017
-
[18]
nature323(6088), 533–536 (1986)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back- propagating errors. nature323(6088), 533–536 (1986)
1986
-
[19]
arXiv preprint arXiv:1705.04977 (2017)
Tsang, M., Cheng, D., Liu, Y.: Detecting statistical interactions from neural net- work weights. arXiv preprint arXiv:1705.04977 (2017)
Pith/arXiv arXiv 2017
-
[20]
Advances in neural information processing systems29 (2016)
Veit, A., Wilber, M.J., Belongie, S.: Residual networks behave like ensembles of relatively shallow networks. Advances in neural information processing systems29 (2016)
2016
-
[21]
Cement and Concrete research28(12), 1797–1808 (1998)
Yeh, I.C.: Modeling of strength of high-performance concrete using artificial neural networks. Cement and Concrete research28(12), 1797–1808 (1998)
1998
-
[22]
arXiv preprint arXiv:1611.03530 (2017)
Zhang, C., Bengio, S., Hardt, M., Recht, B., Vinyals, O.: Understanding deep learning requires rethinking generalization (2016). arXiv preprint arXiv:1611.03530 (2017)
Pith/arXiv arXiv 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.