DyCon: Dynamic Reasoning Control via Evolving Difficulty Modeling
Pith reviewed 2026-06-27 22:14 UTC · model grok-4.3
The pith
Reasoning difficulty changes dynamically and is linearly encoded in a model's step-level embeddings, enabling a training-free method to control reasoning depth.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
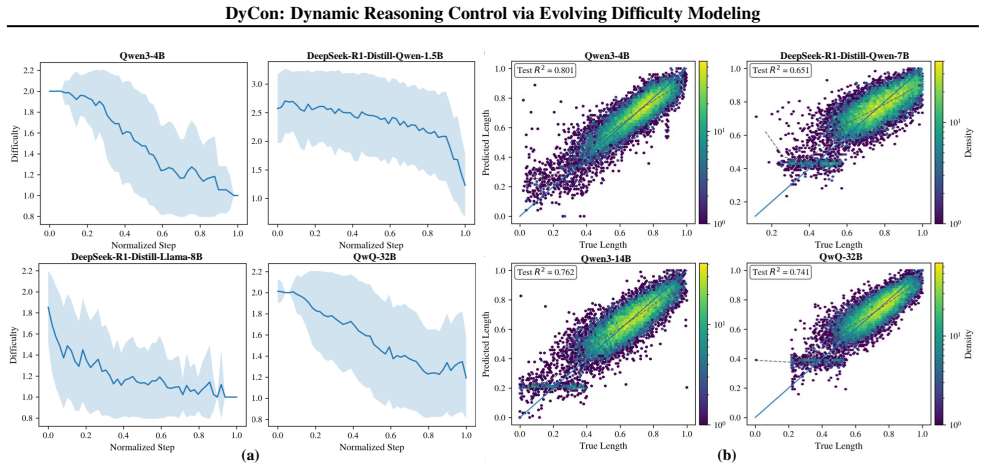
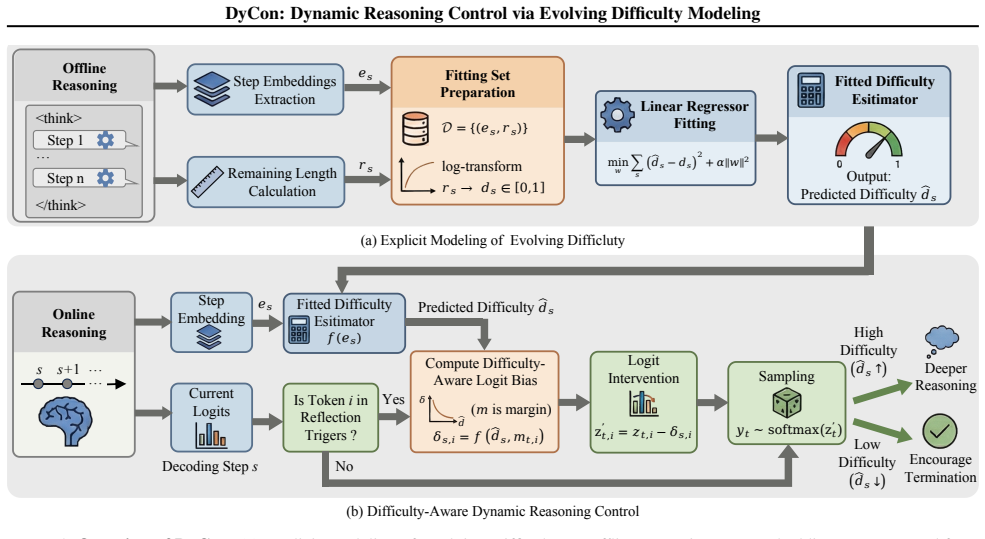
The problem difficulty evolves dynamically throughout the reasoning process and is linearly encoded in the LRM's step-level embeddings. Building on this insight, DyCon is proposed as a training-free framework that leverages latent step-level representations to explicitly model the evolving task difficulty, enabling the dynamic control of reasoning depth to mitigate the overthinking issue.
What carries the argument
The linear encoding of evolving difficulty in step-level embeddings, which DyCon reads to model difficulty and adjust reasoning depth on the fly.
If this is right
- Redundant reasoning steps are reduced while final answer correctness is preserved.
- The same control works across model scales from 4B to 32B parameters.
- No separate training or fine-tuning is required for new tasks.
- Performance gains appear on math reasoning, general question answering, and coding benchmarks.
Where Pith is reading between the lines
- The same embedding signal could be monitored to control other sequential generation behaviors such as search depth or output length.
- Future model architectures might expose difficulty estimates explicitly rather than leaving them implicit in hidden states.
- The linear relationship suggests that progress toward solution completion is represented in a simple geometric form inside the network.
Load-bearing premise
The linear encoding of evolving difficulty in step-level embeddings is reliable and general enough to support effective dynamic control without task-specific training or accuracy loss.
What would settle it
An experiment on held-out tasks where difficulty scores derived from the embeddings show no correlation with actual remaining complexity or where early stopping based on those scores produces measurably lower accuracy than the unguided baseline.
Figures












read the original abstract
Recent advances in Large Reasoning Models (LRMs) demonstrate remarkable performance improvements by iteratively reflecting, exploring, and executing complex tasks, yet suffer from inefficiencies due to redundant reasoning, known as "overthinking". Existing methods to mitigate this issue either rely on static difficulty estimates or require task-specific training, and thus fail to adapt to the dynamic complexity during reasoning. In this work, we empirically show that the problem difficulty evolves dynamically throughout the reasoning process and is linearly encoded in the LRM's step-level embeddings. Building on this insight, we propose DyCon, a training-free framework that leverages latent step-level representations to explicitly model the evolving task difficulty, enabling the dynamic control of reasoning depth to mitigate the overthinking issue. Extensive experiments conducted on four models ranging from 4B to 32B, and across twelve benchmarks in math reasoning, general question answering, and coding tasks demonstrate that DyCon significantly enhances reasoning efficiency by reducing redundant steps without sacrificing accuracy or generalization. Code is available at https://github.com/yu-lin-li/DyCon.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that problem difficulty evolves dynamically during LRM reasoning and is linearly encoded in step-level embeddings. Building on this, it introduces DyCon, a training-free framework that projects these embeddings to model evolving difficulty and dynamically controls reasoning depth (e.g., via thresholds) to reduce overthinking. Experiments on four LRMs (4B–32B) across twelve math/QA/coding benchmarks report reduced reasoning steps with no accuracy loss.
Significance. If the linear-encoding observation is robust and generalizes, DyCon offers a practical, training-free route to efficiency gains in LRMs, directly addressing overthinking without task-specific fine-tuning. The code release and multi-model/multi-domain evaluation are strengths that would make the contribution actionable for the community.
major comments (3)
- [§3.2] §3.2 (linear encoding verification): the central claim that difficulty 'is linearly encoded' requires explicit quantitative support (Pearson r or R² values, per model and per benchmark) for the step-level embedding projections; without these metrics it is unclear whether the relationship is strong enough to support reliable threshold-based control across the claimed model sizes.
- [§4.2–4.3] §4.2–4.3 (DyCon control mechanism): the description of how the evolving-difficulty signal is turned into a stopping decision (projection, threshold selection, handling of non-monotonic trajectories) is load-bearing for the 'training-free' and 'no accuracy loss' claims; the current exposition leaves open whether any per-task or per-model hyperparameter is implicitly tuned.
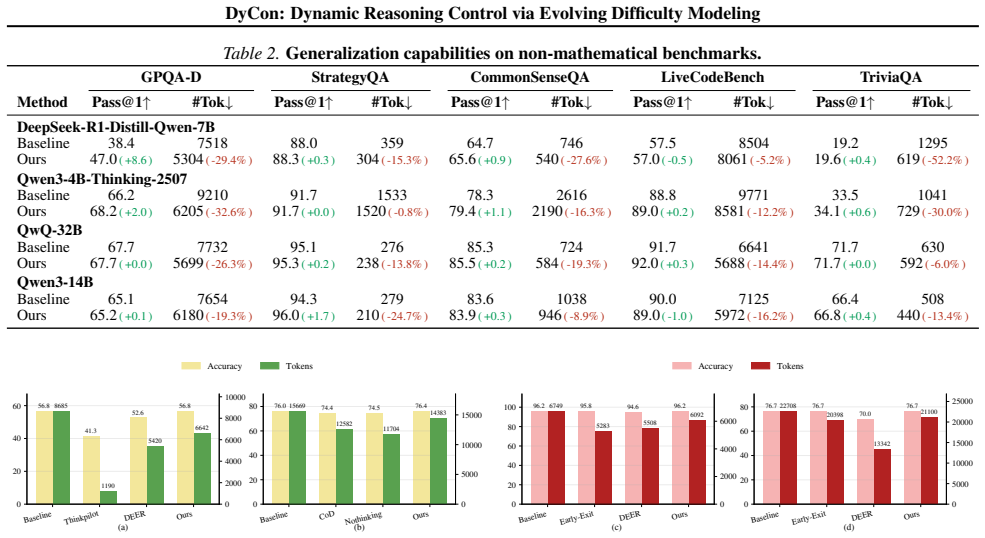
- [Table 2 / Figure 4] Table 2 / Figure 4 (cross-model results): the reported step reductions must be accompanied by per-benchmark accuracy deltas and variance across runs; if accuracy is preserved only on aggregate, the claim that DyCon 'mitigates overthinking without sacrificing accuracy' is not yet substantiated at the granularity needed for the central efficiency argument.
minor comments (2)
- [§3] Notation for the step-level embedding projection (e.g., the linear map W) should be introduced once with a clear equation number rather than redefined inline in multiple sections.
- [§2] The related-work discussion of prior difficulty-estimation methods should cite the specific papers whose static estimates are being contrasted, rather than using generic phrases.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript to incorporate the suggested improvements for greater clarity and substantiation.
read point-by-point responses
-
Referee: [§3.2] §3.2 (linear encoding verification): the central claim that difficulty 'is linearly encoded' requires explicit quantitative support (Pearson r or R² values, per model and per benchmark) for the step-level embedding projections; without these metrics it is unclear whether the relationship is strong enough to support reliable threshold-based control across the claimed model sizes.
Authors: We agree that explicit quantitative metrics would strengthen the central claim. In the revised manuscript we will add Pearson r and R² values (per model and per benchmark) for the linear projections of step-level embeddings onto difficulty, directly quantifying the strength of the observed linear encoding. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (DyCon control mechanism): the description of how the evolving-difficulty signal is turned into a stopping decision (projection, threshold selection, handling of non-monotonic trajectories) is load-bearing for the 'training-free' and 'no accuracy loss' claims; the current exposition leaves open whether any per-task or per-model hyperparameter is implicitly tuned.
Authors: We will expand §§4.2–4.3 with a precise algorithmic description: the projection is a fixed linear map, thresholds are chosen once on a small held-out validation split (no per-task or per-benchmark retuning), and non-monotonic trajectories are handled by a simple cumulative moving average. The framework uses the same fixed rule set across all models and domains, preserving the training-free property. revision: yes
-
Referee: [Table 2 / Figure 4] Table 2 / Figure 4 (cross-model results): the reported step reductions must be accompanied by per-benchmark accuracy deltas and variance across runs; if accuracy is preserved only on aggregate, the claim that DyCon 'mitigates overthinking without sacrificing accuracy' is not yet substantiated at the granularity needed for the central efficiency argument.
Authors: We acknowledge the need for finer-grained reporting. The revised Table 2 will include per-benchmark accuracy deltas (DyCon vs. baseline) together with standard deviations computed over three independent runs, confirming that accuracy is preserved at the individual benchmark level rather than only in aggregate. revision: yes
Circularity Check
No circularity; empirical observation supports independent framework
full rationale
The paper claims an empirical finding that difficulty evolves and is linearly encoded in step-level embeddings, then builds the training-free DyCon framework on that observation to control reasoning depth. No equations, fitted parameters renamed as predictions, self-citations, or ansatzes are present in the provided text that would reduce the central claim to its own inputs by construction. The derivation is self-contained because the control mechanism follows directly from the stated empirical pattern without tautological redefinition or load-bearing prior self-work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Problem difficulty evolves dynamically throughout reasoning and is linearly encoded in the LRM's step-level embeddings.
Reference graph
Works this paper leans on
-
[1]
AI-MO. Aime 2024, July 2024a. URL https: //huggingface.co/datasets/AI-MO/ aimo-validation-aime. AI-MO. Amc 2023, July 2024b. URL https: //huggingface.co/datasets/AI-MO/ aimo-validation-amc. Arora, D. and Zanette, A. Training language models to rea- son efficiently.arXiv preprint arXiv:2502.04463,
arXiv 2024
-
[2]
Chen, R., Zhang, Z., Hong, J., Kundu, S., and Wang, Z. Seal: Steerable reasoning calibration of large language models for free.arXiv preprint arXiv:2504.07986,
-
[3]
Do not think that much for 2+ 3=? on the overthinking of o1-like llms
Chen, X., Xu, J., Liang, T., He, Z., Pang, J., Yu, D., Song, L., Liu, Q., Zhou, M., Zhang, Z., et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms. arXiv preprint arXiv:2412.21187,
-
[4]
Training verifiers to solve math word problems
Cobbe, K., Kosaraju, V ., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168,
-
[5]
Break the chain: Large language models can be shortcut reasoners.arXiv preprint arXiv:2406.06580,
Ding, M., Liu, H., Fu, Z., Song, J., Xie, W., and Zhang, Y . Break the chain: Large language models can be shortcut reasoners.arXiv preprint arXiv:2406.06580,
-
[6]
Reasoning without self-doubt: More efficient chain-of- thought through certainty probing
9 DyCon: Dynamic Reasoning Control via Evolving Difficulty Modeling Fu, Y ., Chen, J., Zhuang, Y ., Fu, Z., Stoica, I., and Zhang, H. Reasoning without self-doubt: More efficient chain-of- thought through certainty probing. InICLR 2025 Work- shop on Foundation Models in the Wild,
2025
-
[7]
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
-
[8]
L., Shen, J., Hu, J., Han, X., Huang, Y ., Zhang, Y ., et al
He, C., Luo, R., Bai, Y ., Hu, S., Thai, Z. L., Shen, J., Hu, J., Han, X., Huang, Y ., Zhang, Y ., et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad- level bilingual multimodal scientific problems.arXiv preprint arXiv:2402.14008,
-
[9]
Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring mas- sive multitask language understanding.arXiv preprint arXiv:2009.03300,
Pith/arXiv arXiv 2009
-
[10]
Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., and Steinhardt, J. Measuring math- ematical problem solving with the math dataset.arXiv preprint arXiv:2103.03874,
-
[11]
Huang, J., Hu, X., Han, B., Shi, S., Tian, Z., He, T., and Jiang, L. Memory forcing: Spatio-temporal memory for consistent scene generation on minecraft.arXiv preprint arXiv:2510.03198, 2025a. Huang, J., Hu, X., Shi, S., Tian, Z., and Jiang, L. Edit360: 2d image edits to 3d assets from any angle. InICCV, 2025b. Huang, S., Wang, H., Zhong, W., Su, Z., Feng...
-
[12]
Openai o1 system card.arXiv preprint arXiv:2412.16720,
Jaech, A., Kalai, A., Lerer, A., Richardson, A., El-Kishky, A., Low, A., Helyar, A., Madry, A., Beutel, A., Car- ney, A., et al. Openai o1 system card.arXiv preprint arXiv:2412.16720,
-
[13]
Jain, N., Han, K., Gu, A., Li, W.-D., Yan, F., Zhang, T., Wang, S., Solar-Lezama, A., Sen, K., and Stoica, I. Livecodebench: Holistic and contamination free eval- uation of large language models for code.arXiv preprint arXiv:2403.07974,
-
[14]
Flashthink: An early exit method for efficient reasoning
Jiang, G., Quan, G., Ding, Z., Luo, Z., Wang, D., and Hu, Z. Flashthink: An early exit method for efficient reasoning. arXiv preprint arXiv:2505.13949,
-
[15]
Joshi, M., Choi, E., Weld, D. S., and Zettlemoyer, L. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension.arXiv preprint arXiv:1705.03551,
-
[16]
B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D
Kaplan, J., McCandlish, S., Henighan, T., Brown, T. B., Chess, B., Child, R., Gray, S., Radford, A., Wu, J., and Amodei, D. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361,
Pith/arXiv arXiv 2001
-
[17]
D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al
Kumar, A., Zhuang, V ., Agarwal, R., Su, Y ., Co-Reyes, J. D., Singh, A., Baumli, K., Iqbal, S., Bishop, C., Roelofs, R., et al. Training language models to self-correct via reinforcement learning.arXiv preprint arXiv:2409.12917,
-
[18]
Lisa: Reasoning segmentation via large language model
10 DyCon: Dynamic Reasoning Control via Evolving Difficulty Modeling Lai, X., Tian, Z., Chen, Y ., Li, Y ., Yuan, Y ., Liu, S., and Jia, J. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9579– 9589, 2024a. Lai, X., Tian, Z., Chen, Y ., Yang, S., Peng, X., and ...
-
[19]
Lin, W., Li, X., Yang, Z., Fu, X., Zhen, H.-L., Wang, Y ., Yu, X., Liu, W., Li, X., and Yuan, M. Trimr: Verifier-based training-free thinking compression for efficient test-time scaling.arXiv preprint arXiv:2505.17155, 2025a. Lin, Z., Fu, Z., Chen, Z., Chen, C., Xie, L., Wang, W., Cai, D., Wang, Z., and Ye, J. Controlling thinking speed in reasoning model...
-
[20]
Adacot: Pareto-optimal adaptive chain-of-thought triggering via reinforcement learning
Lou, C., Sun, Z., Liang, X., Qu, M., Shen, W., Wang, W., Li, Y ., Yang, Q., and Wu, S. Adacot: Pareto-optimal adaptive chain-of-thought triggering via reinforcement learning. arXiv preprint arXiv:2505.11896,
-
[21]
Reasoning models can be effective without thinking
Ma, W., He, J., Snell, C., Griggs, T., Min, S., and Zaharia, M. Reasoning models can be effective without thinking. arXiv preprint arXiv:2504.09858,
-
[22]
H., Yang, Y ., Kim, Y ., and Yun, S.-Y
Munkhbat, T., Ho, N., Kim, S. H., Yang, Y ., Kim, Y ., and Yun, S.-Y . Self-training elicits concise reasoning in large language models.arXiv preprint arXiv:2502.20122,
-
[23]
Concise thoughts: Impact of output length on llm reasoning and cost.arXiv preprint arXiv:2407.19825,
Nayab, S., Rossolini, G., Simoni, M., Saracino, A., But- tazzo, G., Manes, N., and Giacomelli, F. Concise thoughts: Impact of output length on llm reasoning and cost.arXiv preprint arXiv:2407.19825,
-
[24]
T., She, R., Fu, X., and Nguyen, V
Nguyen, B., Nguyen, H. T., She, R., Fu, X., and Nguyen, V . A. Reasoning planning for language models.arXiv preprint arXiv:2511.00521,
-
[25]
Boosting few-shot 3d point cloud segmentation via query-guided enhancement
Ning, Z., Tian, Z., Lu, G., and Pei, W. Boosting few-shot 3d point cloud segmentation via query-guided enhancement. InProceedings of the 31st ACM international conference on multimedia, pp. 1895–1904,
1904
-
[26]
Aime 2025, February
OpenCompass. Aime 2025, February
2025
-
[27]
Scalable lan- guage model with generalized continual learning.arXiv preprint arXiv:2404.07470, 2024a
Peng, B., Tian, Z., Liu, S., Yang, M., and Jia, J. Scalable lan- guage model with generalized continual learning.arXiv preprint arXiv:2404.07470, 2024a. Peng, B., Wu, X., Jiang, L., Chen, Y ., Zhao, H., Tian, Z., and Jia, J. Oa-cnns: Omni-adaptive sparse cnns for 3d semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat...
-
[28]
and Guven, E
Renze, M. and Guven, E. The benefits of a concise chain of thought on problem-solving in large language models. In 2024 2nd International Conference on Foundation and Large Language Models (FLLM), pp. 476–483. IEEE,
2024
-
[29]
Dast: Difficulty- adaptive slow-thinking for large reasoning models.arXiv preprint arXiv:2503.04472,
Shen, Y ., Zhang, J., Huang, J., Shi, S., Zhang, W., Yan, J., Wang, N., Wang, K., Liu, Z., and Lian, S. Dast: Difficulty- adaptive slow-thinking for large reasoning models.arXiv preprint arXiv:2503.04472,
-
[30]
On reasoning strength planning in large reasoning models.arXiv preprint arXiv:2506.08390,
Sheng, L., Zhang, A., Wu, Z., Zhao, W., Shen, C., Zhang, Y ., Wang, X., and Chua, T.-S. On reasoning strength planning in large reasoning models.arXiv preprint arXiv:2506.08390,
-
[31]
W., Tay, Y ., Ruder, S., Zhou, D., et al
Shi, F., Suzgun, M., Freitag, M., Wang, X., Srivats, S., V osoughi, S., Chung, H. W., Tay, Y ., Ruder, S., Zhou, D., et al. Language models are multilingual chain-of-thought reasoners.arXiv preprint arXiv:2210.03057,
-
[32]
Su, D., Zhu, H., Xu, Y ., Jiao, J., Tian, Y ., and Zheng, Q. Token assorted: Mixing latent and text tokens for improved language model reasoning.arXiv preprint arXiv:2502.03275, 2025a. Su, J., Healey, J., Nakov, P., and Cardie, C. Between un- derthinking and overthinking: An empirical study of rea- soning length and correctness in llms.arXiv preprint arXi...
-
[33]
Com- monsenseqa: A question answering challenge targeting commonsense knowledge
Talmor, A., Herzig, J., Lourie, N., and Berant, J. Com- monsenseqa: A question answering challenge targeting commonsense knowledge. InProceedings of the 2019 Conference of the North American Chapter of the Associ- ation for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pp. 4149–4158,
2019
-
[34]
Wang, C., Feng, Y ., Chen, D., Chu, Z., Krishna, R., and Zhou, T. Wait, we don’t need to” wait”! removing think- ing tokens improves reasoning efficiency.arXiv preprint arXiv:2506.08343, 2025a. Wang, J., Chen, B., Li, Y ., Kang, B., Chen, Y ., and Tian, Z. Declip: Decoupled learning for open-vocabulary dense perception. InProceedings of the Computer Visio...
-
[35]
Wolf, T., Debut, L., Sanh, V ., Chaumond, J., Delangue, C., Moi, A., Cistac, P., Rault, T., Louf, R., Funtowicz, M., et al. Huggingface’s transformers: State-of-the-art natural language processing.arXiv preprint arXiv:1910.03771,
Pith/arXiv arXiv 1910
-
[36]
Wu, Y ., Shi, J., Wu, B., Zhang, J., Lin, X., Tang, N., and Luo, Y . Concise reasoning, big gains: Pruning long reasoning trace with difficulty-aware prompting.arXiv preprint arXiv:2505.19716,
-
[37]
Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025a
Xu, S., Xie, W., Zhao, L., and He, P. Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025a. Xu, Y ., Guo, X., Zeng, Z., and Miao, C. Softcot: Soft chain-of-thought for efficient reasoning with llms.arXiv preprint arXiv:2502.12134, 2025b. Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C....
-
[38]
Zhang, S., Wu, J., Chen, J., Zhang, C., Lou, X., Zhou, W., Zhou, S., Wang, C., and Wang, J. Othink-r1: Intrinsic fast/slow thinking mode switching for over-reasoning mitigation.arXiv preprint arXiv:2506.02397, 2025a. Zhang, Y ., Wu, X., Lao, Y ., Wang, C., Tian, Z., Wang, N., and Zhao, H. Concerto: Joint 2d-3d self-supervised learning emerges spatial repr...
-
[39]
15 A.1 System 1 or System 2: Which Reasoning Mode Is Needed?
13 DyCon: Dynamic Reasoning Control via Evolving Difficulty Modeling Contents A Further Discussion on Motivation. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 A.1 System 1 or System 2: Which Reasoning Mode Is Needed? . . . . . . . . . . . . . . . . . . . . 15 A.2 Who Decides Difficulty? A Model-Centric Perspective . . . . . . . . . . ....
2011
-
[40]
Okay, I have finished thinking.</think>
We observe that both NoThinking and NoThinking Variant substantially reduce token consumption in reasoning models. Notably, NoThinking Variant achieves a markedly stronger compression effect, reducing the average token usage by 64.28% relative to the baseline. This result suggests that injecting an explicit reasoning-termination semantic during the reason...
-
[41]
95.2 4362 73.3 16556 73.3 19177 74.5 11704 95.0 1137 97.5 7738 ∆vs. Baseline (%)−1.04−35.55−12.00−22.97−4.43−15.55−1.97−25.31−0.94−23.90−2.50−30.11 NoThinking Variant 91.8197563.31081750.01350666.7601493.843192.53555 ∆vs. Baseline (%)−4.57−70.82−24.01−49.67−34.81−40.51−12.24−61.62−2.19−71.15−7.50−67.90 A.2. Who Decides Difficulty? A Model-Centric Perspect...
-
[42]
employs a contrastive learning paradigm to select appropriate reasoning strategies for a given query. Its learned mapper is able to separate hard and easy mathematical problems in the latent space, indicating that problem difficulty can be effectively encoded and distinguished at the representation level. Sheng et al. (2025) further observe that special i...
2025
-
[43]
</think>
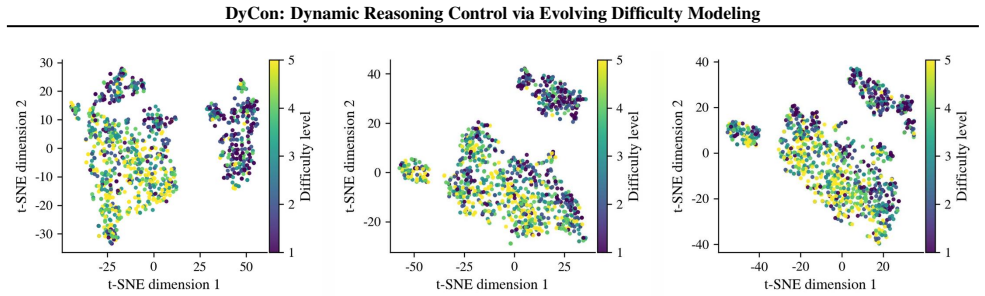
are colored by remaining generation length. (a) Math-500; (b) Math-500 + GSM8K; (c) Math-500 + GSM8K + Olympiad; (d) Math-500 + GSM8K + Olympiad + AIME2025; (e) Math-500 + GSM8K + Olympiad + AIME2025 + AMC23; (f) Math-500 + GSM8K + Olympiad + AIME2025 + AMC23 + GPQA. The overall geometric structure remains stable as additional datasets are incorporated, i...
2043
-
[44]
However, we also observe substantial accuracy degradation on relatively simple datasets
and TrimR (Lin et al., 2025a), the GRU-based method achieves superior performance. However, we also observe substantial accuracy degradation on relatively simple datasets. We attribute this to the fact that the appearance of conclusion-style phrases does not necessarily indicate that the ground-truth answer has been correctly derived. In many cases, the m...
arXiv 2019
-
[45]
leads to comparable performance across models and benchmarks. We further study whether the reflection-token vocabulary can be optimized in a model-specific manner, and find that an evolutionary refinement strategy can yield additional improvements in both accuracy and inference efficiency. The predefined reflection-token list used in our main experiments ...
2025
-
[46]
These results indicate that refinement should be understood as a controlled reshaping of the reasoning-trajectory distribution rather than simple denoising
However, this improvement is not monotonic: excessive refinement further increases the regressor’sR2 but hurts downstream performance. These results indicate that refinement should be understood as a controlled reshaping of the reasoning-trajectory distribution rather than simple denoising. The difficulty regressor in DyCon is fitted on reasoning trajecto...
2021
-
[47]
This is consistent with prior work showing that shorter but complete reasoning traces can serve as effective learning signals (Wu et al., 2025)
0.9276 96.2 / 5710 86.7 / 19051 73.3 / 19726 process. This is consistent with prior work showing that shorter but complete reasoning traces can serve as effective learning signals (Wu et al., 2025). To further understand this effect, we evaluate multiple refinement iterations. Table 32 reports the regressor R2 and downstream performance after successive r...
2025
-
[48]
However, it does not consistently provide a clearly superior efficiency–accuracy trade-off over the simple linear regressor
As shown in Table 34, the MLP achieves competitive performance and can further improve accuracy in some cases. However, it does not consistently provide a clearly superior efficiency–accuracy trade-off over the simple linear regressor. This suggests that the difficulty signal used by DyCon is already largely accessible through a simple linear readout from...
2020
-
[49]
and DeepSeek-V3 (Liu et al., 2024), have achieved remarkable success largely through massive parameter and compute scaling. This scaling momentum has also propagated beyond text-only NLP into multimodal and vision-language domains, reshaping tasks from reasoning segmentation, open-vocabulary perception, and language-driven adaptation to multimodal reasoni...
2024
-
[50]
These models generate explicit intermediate reasoning before producing final answers, enabling iterative deliberation and improved problem decomposition
and OpenAI o1 series (Jaech et al., 2024). These models generate explicit intermediate reasoning before producing final answers, enabling iterative deliberation and improved problem decomposition. As a result, they achieve substantially improved performance on complex reasoning tasks. Efficient Reasoning.Despite their strong reasoning capability, large re...
2024
-
[51]
These methods demonstrate the effectiveness of early-exit strategies for reducing reasoning cost
uses agreement across multiple sampled answers to guide early termination. These methods demonstrate the effectiveness of early-exit strategies for reducing reasoning cost. D. Details On Experimental Settings D.1. Decoding and Sampling Settings To ensure optimal model performance, we follow the original model configurations and experimental settings adopt...
2025
-
[52]
Unless otherwise stated, all experimental results reported in this paper are based on the HuggingFace Transformers implementation (Wolf et al., 2019)
and vLLM (Kwon et al., 2023). Unless otherwise stated, all experimental results reported in this paper are based on the HuggingFace Transformers implementation (Wolf et al., 2019). D.4. Details on Benchmarks Math-500(Lightman et al., 2023): A difficulty-balanced mathematical reasoning benchmark comprising 500 problems, with each instance labeled according...
2023
-
[53]
how many in a month\
and FlashThinking (Jiang et al., 2025); and (4)output-basedmethods, represented by NoWait (Wang et al., 2025a). D.6. Details on Prompts. Math-500, AIME2024, AIME2025, AMC23, GSM8K, Olympiad-Bench, and MMLU: <|System|>Please reason step by step, and place the final answer inside\boxed{}. <|User|>[question] GPQA Diamond, CommonSenseQA: <|System|>Please reas...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.