Detecting Fluent Optimization-Based Adversarial Prompts via Sequential Entropy Changes
Pith reviewed 2026-05-20 07:35 UTC · model grok-4.3
The pith
Change-point detection on next-token entropy identifies fluent optimization-based adversarial suffixes in LLM prompts online and without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
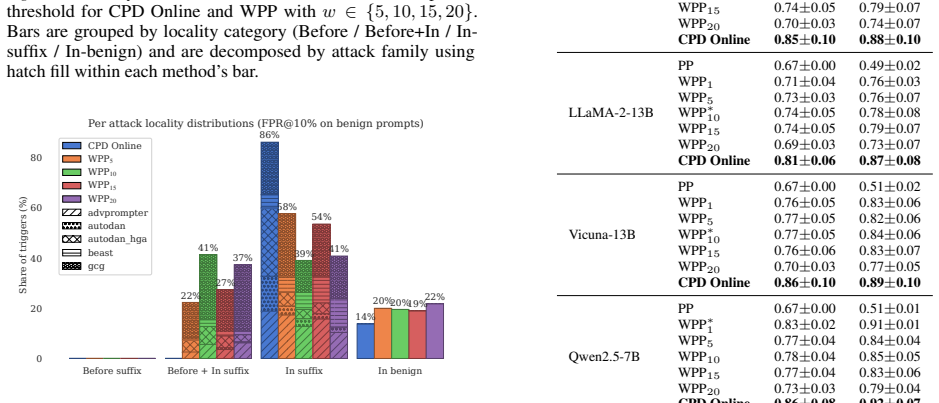
The paper claims that casting adversarial suffix detection as an online change-point detection problem over the token-level next-token entropy stream, standardized against a system-prompt baseline and tracked with a one-sided CUSUM statistic, produces a model-agnostic, training-free detector that raises F1 scores above the strongest windowed-perplexity baseline on all six tested open-weight chat models, reaches AUROC 0.88 and F1 0.82 on LLaMA-2-7B, places 79.6 percent of its triggers inside the adversarial suffix, and reduces LLaMA Guard calls by 17-22 percent in benign-dominated deployment while preserving guard-level quality.
What carries the argument
One-sided CUSUM statistic applied to next-token entropies standardized against the system prompt baseline.
If this is right
- F1 improves over the strongest windowed-perplexity baseline on LLaMA-2-7B/13B, Vicuna-7B/13B, and Qwen2.5-7B/14B.
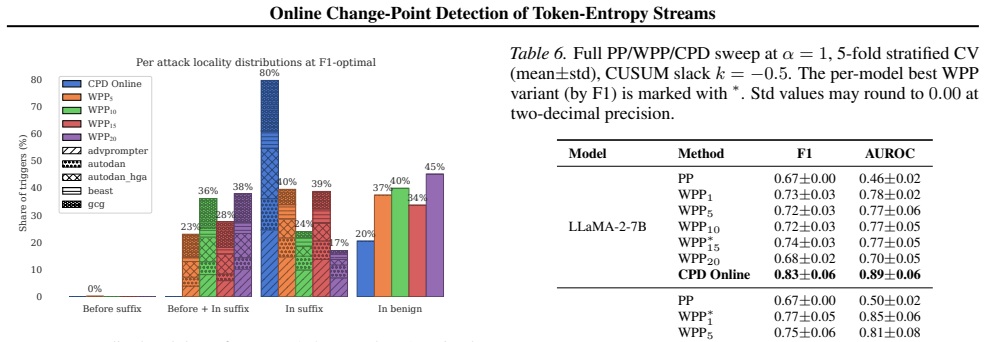
- 79.6 percent of CPD triggers fall inside the adversarial suffix, compared with 17-46 percent for the baselines.
- When used as a gate for LLaMA Guard in benign-dominated traffic, the detector cuts guard calls by 17-22 percent while keeping detection performance intact.
- The method localizes the onset of the adversarial suffix in addition to flagging the full prompt.
Where Pith is reading between the lines
- The same entropy-based change-point approach could be tested on prompt streams that mix multiple users or sessions to monitor for emerging anomalies beyond single-prompt attacks.
- Localization of the suffix onset suggests the possibility of early intervention, such as truncating or rewriting the prompt at the moment the change is flagged rather than after the full input is seen.
- The training-free and model-agnostic properties make it straightforward to combine with other lightweight signals for layered defenses that escalate only when the CUSUM fires.
Load-bearing premise
Next-token entropy shifts induced by optimization-based suffixes remain sufficiently distinct from natural entropy variation in benign prompts after standardization against the system-prompt baseline.
What would settle it
A collection of benign prompts whose standardized entropy sequences trigger the one-sided CUSUM at rates comparable to those of the optimization-based adversarial suffixes, or a set of optimization-based suffixes that produce no detectable entropy shift relative to the baseline.
Figures





read the original abstract
Optimization-based adversarial suffixes can jailbreak aligned large language models (LLMs) while remaining fluent, weakening static and windowed perplexity-based detectors. We cast adversarial suffix detection as an online change-point detection problem over the token-level next-token entropy stream. Using the LLM system prompt to estimate a robust baseline, we standardize user-token entropies and apply a one-sided CUSUM statistic. The resulting detector, CPD Online (CPD), is model-agnostic, training-free, runs online, and localizes the adversarial suffix onset. On a benchmark of 1,012 optimization-based suffix attacks (GCG, AutoDAN, AdvPrompter, BEAST, AutoDAN-HGA) and 1,012 perplexity-controlled benign prompts, CPD improves F1 over the strongest windowed-perplexity baseline on all six open-weight chat models (LLaMA-2-7B/13B, Vicuna-7B/13B, Qwen2.5-7B/14B). On LLaMA-2-7B at the canonical CUSUM setting ($k=0$), CPD reaches AUROC $0.88$ and F1 $0.82$. Beyond prompt-level detection, CPD concentrates 79.6% of its triggers inside the adversarial suffix, versus 17-46% for windowed perplexity. Finally, when used as a lightweight gate for LLaMA Guard, CPD reduces guard calls by 17-22% on a high-volume, benign-dominated deployment while preserving guard-level detection quality
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes CPD Online (CPD), a training-free, model-agnostic online detector for optimization-based adversarial suffixes. It frames detection as a change-point problem on the stream of next-token entropies: user-token entropies are standardized against mean and standard deviation computed from the system-prompt tokens, then fed to a one-sided CUSUM statistic. On a benchmark of 1,012 adversarial suffixes (GCG, AutoDAN, AdvPrompter, BEAST, AutoDAN-HGA) and 1,012 perplexity-controlled benign prompts across six models, CPD reports AUROC 0.88 and F1 0.82 on LLaMA-2-7B at k=0, 79.6% trigger localization inside the suffix, and 17-22% reduction in LLaMA Guard calls while preserving detection quality.
Significance. If the central claims hold, the work supplies a lightweight, online, training-free alternative to perplexity-based detectors that is particularly effective against fluent optimization-based attacks. The localization of the adversarial suffix and the demonstrated efficiency gain when gating a heavier guard model are practical strengths. The evaluation on held-out attack and benign sets with multiple models and attack families provides a reproducible foundation for the performance numbers.
major comments (2)
- [Section 3.2] Section 3.2 (standardization and CUSUM): The procedure subtracts the system-prompt mean and divides by its standard deviation before applying one-sided CUSUM. The reported AUROC 0.88 / F1 0.82 and 79.6% localization on LLaMA-2-7B rest on the premise that perplexity-controlled benign user prompts produce no sustained positive drift relative to the system-prompt baseline. The manuscript does not report an explicit test of this stationarity assumption on uncontrolled benign prompts that vary in length, topic, or syntactic complexity; if such prompts induce drift, CUSUM will accumulate false positives and the claimed separation from windowed-perplexity baselines (17-46% localization) would not hold.
- [Section 4.3] Section 4.3 and Table 2: The canonical setting k=0 is used and the decision threshold h appears fixed for the reported metrics, yet no sensitivity table or description of how h was selected without reference to the test-set labels is provided. Because the central performance numbers (AUROC, F1, localization percentage) are load-bearing for the claim of superiority, the absence of this detail makes it impossible to judge whether the results are robust to reasonable choices of h.
minor comments (2)
- [Abstract] The abstract states results 'at the canonical CUSUM setting (k=0)' but does not define the exact decision threshold or confirm it was chosen independently of the test set; adding one sentence would improve reproducibility.
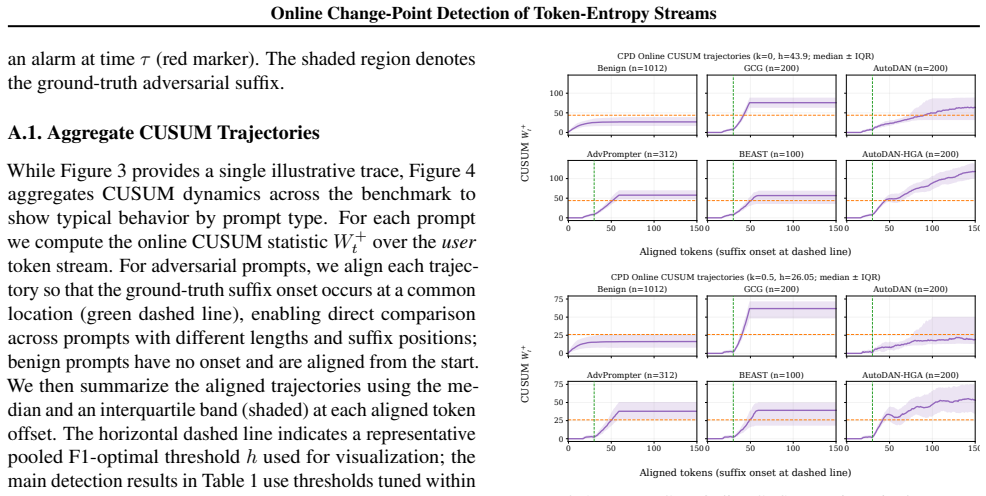
- [Figure 3] Figure 3 (localization plot): The adversarial-suffix region is not explicitly shaded or labeled on the x-axis, making it harder to verify the 79.6% concentration claim at a glance.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that strengthen the presentation without altering the core claims.
read point-by-point responses
-
Referee: [Section 3.2] Section 3.2 (standardization and CUSUM): The procedure subtracts the system-prompt mean and divides by its standard deviation before applying one-sided CUSUM. The reported AUROC 0.88 / F1 0.82 and 79.6% localization on LLaMA-2-7B rest on the premise that perplexity-controlled benign user prompts produce no sustained positive drift relative to the system-prompt baseline. The manuscript does not report an explicit test of this stationarity assumption on uncontrolled benign prompts that vary in length, topic, or syntactic complexity; if such prompts induce drift, CUSUM will accumulate false positives and the claimed separation from windowed-perplexity baselines (17-46% localization) would not hold.
Authors: We thank the referee for identifying this assumption. The perplexity-controlled benign prompts were chosen specifically to enable a fair, apples-to-apples comparison with windowed-perplexity baselines under matched fluency conditions; uncontrolled prompts would introduce length and topic confounds that affect all detectors equally. We nevertheless agree that an explicit check on uncontrolled benign prompts would better substantiate stationarity. In the revised manuscript we will add a new experiment using a held-out collection of uncontrolled benign prompts that vary in length, topic, and syntactic complexity, reporting the resulting false-positive rate, AUROC, and localization statistics to quantify any drift. revision: yes
-
Referee: [Section 4.3] Section 4.3 and Table 2: The canonical setting k=0 is used and the decision threshold h appears fixed for the reported metrics, yet no sensitivity table or description of how h was selected without reference to the test-set labels is provided. Because the central performance numbers (AUROC, F1, localization percentage) are load-bearing for the claim of superiority, the absence of this detail makes it impossible to judge whether the results are robust to reasonable choices of h.
Authors: We apologize for the omitted detail. The threshold h was selected on a validation split held completely separate from the test set by performing a grid search that maximized F1 on the validation data. To address the concern directly, the revised manuscript will include a sensitivity table in Section 4.3 that reports AUROC, F1, and localization accuracy for a range of h values (e.g., 3 to 10) around the chosen operating point, confirming that the reported gains over baselines remain stable across reasonable threshold choices. revision: yes
Circularity Check
No significant circularity; standard CUSUM on held-out entropy streams
full rationale
The paper frames detection as online change-point detection via one-sided CUSUM applied to next-token entropy, standardized against system-prompt statistics. All reported metrics (AUROC 0.88, F1 0.82, 79.6% suffix localization) are obtained from empirical evaluation on explicitly held-out sets of 1012 optimization-based attacks and 1012 perplexity-controlled benign prompts across six models. No equation reduces these performance numbers to a fit performed on the same test data, nor does any step equate a claimed result to its own inputs by definition. The approach is training-free, uses a canonical CUSUM parameter (k=0), and relies on externally computed entropy values rather than self-referential fitting or self-citation chains. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- CUSUM reference value k
axioms (1)
- domain assumption Next-token entropy computed by the target LLM is a reliable and comparable signal across tokens when standardized against the system prompt.
Reference graph
Works this paper leans on
-
[1]
Ji, Jiaming and Qiu, Tianyi and Chen, Boyuan and Zhang, Borong and Lou, Hantao and Wang, Kaile and Duan, Yawen and He, Zhonghao and Zhou, Jiayi and Zhang, Zhaowei and others , journal =
-
[2]
Jailbreak Attacks and Defenses Against Large Language Models: A Survey
Jailbreak attacks and defenses against large language models: A survey , author=. arXiv preprint arXiv:2407.04295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Universal and Transferable Adversarial Attacks on Aligned Language Models
Universal and Transferable Adversarial Attacks on Aligned Language Models , author =. arXiv preprint arXiv:2307.15043 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Baseline Defenses for Adversarial Attacks Against Aligned Language Models
Baseline Defenses for Adversarial Attacks Against Aligned Language Models , author =. arXiv preprint arXiv:2309.00614 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Zhu, Sicheng and Zhang, Ruiyi and An, Bang and Wu, Gang and Barrow, Joe and Wang, Zichao and Huang, Furong and Nenkova, Ani and Sun, Tong , booktitle =. 2024 , url =
work page 2024
-
[6]
Liu, Xiaogeng and Xu, Nan and Chen, Muhao and Xiao, Chaowei , booktitle =. 2024 , url =
work page 2024
-
[7]
Paulus, Anselm and Zharmagambetov, Arman and Guo, Chuan and Amos, Brandon and Tian, Yuandong , booktitle =. 2025 , publisher =
work page 2025
-
[8]
Detecting Language Model Attacks with Perplexity
Detecting Language Model Attacks with Perplexity , author =. arXiv preprint arXiv:2308.14132 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
arXiv preprint arXiv:2311.11509 , year=
Token-level adversarial prompt detection based on perplexity measures and contextual information , author=. arXiv preprint arXiv:2311.11509 , year=
-
[10]
Inan, Hakan and Upasani, Kartikeya and Chi, Jianfeng and Rungta, Rashi and Iyer, Krithika and Mao, Yuning and Tontchev, Michael and Hu, Qing and Fuller, Brian and Testuggine, Davide and others , journal=
-
[11]
Chiang, Wei-Lin and Li, Zhuohan and Lin, Zi and others , howpublished =
-
[12]
Touvron, Hugo and Martin, Louis and Stone, Kevin and others , journal =
-
[13]
HuggingFace repository , howpublished =
Wing Lian and Bleys Goodson and Eugene Pentland and Austin Cook and Chanvichet Vong and "Teknium" , year =. HuggingFace repository , howpublished =
-
[14]
Detection of Abrupt Changes: Theory and Application , author =
-
[15]
Sequential Analysis: Hypothesis Testing and Changepoint Detection , author =
- [16]
-
[17]
The Annals of Mathematical Statistics , volume =
Procedures for Reacting to a Change in Distribution , author =. The Annals of Mathematical Statistics , volume =
-
[18]
The Annals of Statistics , volume =
Optimal Stopping Times for Detecting Changes in Distributions , author =. The Annals of Statistics , volume =
-
[19]
Change-Point Detection in Time-Series Data by Direct Density-Ratio Estimation , author =. Proceedings of the 2009
work page 2009
-
[20]
IEEE Transactions on Signal Processing , volume =
An Online Kernel Change Detection Algorithm , author =. IEEE Transactions on Signal Processing , volume =
-
[21]
Advances in Neural Information Processing Systems 28 (NeurIPS) , pages =
M-Statistic for Kernel Change-Point Detection , author =. Advances in Neural Information Processing Systems 28 (NeurIPS) , pages =
-
[22]
Zhao, Wenting and Ren, Xiang and Hessel, Jack and Cardie, Claire and Choi, Yejin and Deng, Yuntian , booktitle =. 2024 , url =
work page 2024
-
[23]
Zico and Fredrikson, Matt , title =
Zou, Andy and Wang, Zifan and Carlini, Nicholas and Nasr, Milad and Kolter, J. Zico and Fredrikson, Matt , title =. 2023 , note =
work page 2023
-
[24]
Jonathan H. Clark and Eunsol Choi and Michael Collins and Dan Garrette and Tom Kwiatkowski and Vitaly Nikolaev and Jennimaria Palomaki , year =
-
[25]
Robey, Alexander and Wong, Eric and Hassani, Hamed and Pappas, George J. , journal =. 2025 , url =
work page 2025
-
[26]
Not What You've Signed Up For: Compromising Real-World
Abdelnabi, Sahar and Greshake, Kai and Mishra, Shailesh and Endres, Christoph and Holz, Thorsten and Fritz, Mario , booktitle =. Not What You've Signed Up For: Compromising Real-World. 2023 , publisher =
work page 2023
-
[27]
Zeng, Yi and Lin, Hongpeng and Zhang, Jingwen and Yang, Diyi and Jia, Ruoxi and Shi, Weiyan , booktitle=. How
-
[28]
Transactions on Machine Learning Research , year =
Single-Pass Detection of Jailbreaking Input in Large Language Models , author =. Transactions on Machine Learning Research , year =
-
[29]
arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Fast Adversarial Attacks on Language Models In One
Sadasivan, Vinu Sankar and Saha, Shoumik and Sriramanan, Gaurang and Kattakinda, Priyatham and Chegini, Atoosa and Feizi, Soheil , booktitle =. Fast Adversarial Attacks on Language Models In One
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.