CHOIR: Contact-aware 4D Hand-Object Interaction Reconstruction
Pith reviewed 2026-05-22 09:51 UTC · model grok-4.3
The pith
Contact as an explicit coupling signal enables accurate 4D hand-object interaction reconstruction from monocular videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
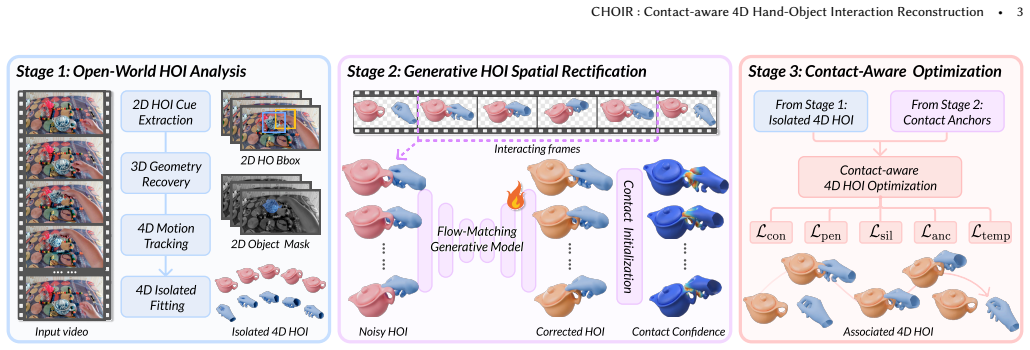
CHOIR reconstructs articulated hand motion, object shape with 6D pose over time, and contact information from monocular videos by first producing a coarse 4D HOI sequence, then using a generative spatial rectification module to predict ray-depth corrections that rectify hand-object placement and derive per-frame contact correspondences, and finally running contact-aware joint optimization with dynamically updated constraints to enforce geometric, temporal, and contact consistency.
What carries the argument
Generative HOI spatial rectification module followed by contact-aware joint optimization that treats derived contact correspondences as the explicit coupling signal between hands and objects.
If this is right
- Object reconstruction improves in both controlled and challenging videos compared with prior separate-estimation methods.
- Physical plausibility of the reconstructed interactions increases through enforced contact constraints.
- Temporal consistency across frames rises because the optimization updates contact constraints dynamically.
- The output yields reusable 4D interaction primitives that can be mined from real open-world footage.
Where Pith is reading between the lines
- The same contact-coupling pattern could be tested on multi-hand or hand-tool sequences to check whether the rectification-plus-optimization pipeline generalizes without major redesign.
- Reconstructed contact maps might serve as training signals for physics-based simulators that predict future interactions from partial observations.
- If the rectification step proves robust, the framework could be adapted to produce training data for robot grasping policies that require realistic contact timing.
Load-bearing premise
Contact correspondences obtained after the generative rectification step remain accurate and stable enough to guide the subsequent joint optimization without adding new errors in cluttered or heavily occluded scenes.
What would settle it
A monocular video sequence with heavy occlusion where the final output shows persistent hand-object interpenetration or temporally inconsistent contact locations that violate physical plausibility.
Figures










read the original abstract
We ask whether everyday open-world monocular videos can be turned into reusable 4D interaction primitives: articulated hand motion, object shape with 6D pose over time, and the when/where of contact. Such a capability would enable scalable mining of real interactions and, beyond reconstruction, support scene-aware synthesis and planning. However, reconstructing hand-object interaction (HOI) from challenging monocular videos remains difficult: methods often assume known objects or curated scenes, and separately estimated hands and objects easily become misaligned under clutter, occlusion, and unseen object geometries. Targeting this setting, we present CHOIR, a Contact-aware HOI Reconstruction framework for a monocular camera, using contact as an explicit coupling signal between hands and objects. CHOIR first initializes a coarse, contact-agnostic 4D HOI sequence from open-world visual priors. It then introduces a generative HOI spatial rectification module to predict ray-depth corrections and rectify hand-object relative placement, then derive initial per-frame contact correspondences on the rectified geometry. Last, a contact-aware joint optimization with dynamically updated contact constraints enforces geometric, temporal, and contact consistency. Experiments on controlled and challenging videos show that CHOIR improves object reconstruction, physical plausibility, and temporal consistency over state-of-the-art methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents CHOIR, a Contact-aware 4D Hand-Object Interaction Reconstruction framework for monocular videos. It initializes a coarse, contact-agnostic 4D HOI sequence from open-world visual priors, applies a generative HOI spatial rectification module to predict ray-depth corrections and derive per-frame contact correspondences on the rectified geometry, and performs contact-aware joint optimization with dynamically updated contact constraints to enforce geometric, temporal, and contact consistency. Experiments on controlled and challenging videos claim improvements in object reconstruction, physical plausibility, and temporal consistency over state-of-the-art methods.
Significance. If the central claims hold, the work would be significant for computer vision by enabling reconstruction of reusable 4D interaction primitives from everyday open-world monocular videos without assuming known objects or curated scenes. The explicit use of contact as a coupling signal between hands and objects addresses misalignment under clutter and occlusion, with potential downstream value for scalable interaction mining, scene-aware synthesis, and planning.
major comments (2)
- [Pipeline description (generative rectification step)] The generative rectification module (described in the pipeline overview) predicts ray-depth corrections from visual priors without explicit contact supervision on occluded or unseen geometry. This directly affects the derived contact correspondences used as dynamic constraints in the subsequent joint optimization; if the contacts are noisy or unstable, the optimization risks overfitting to incorrect couplings or failing to resolve misalignment, which is the core failure mode the method targets.
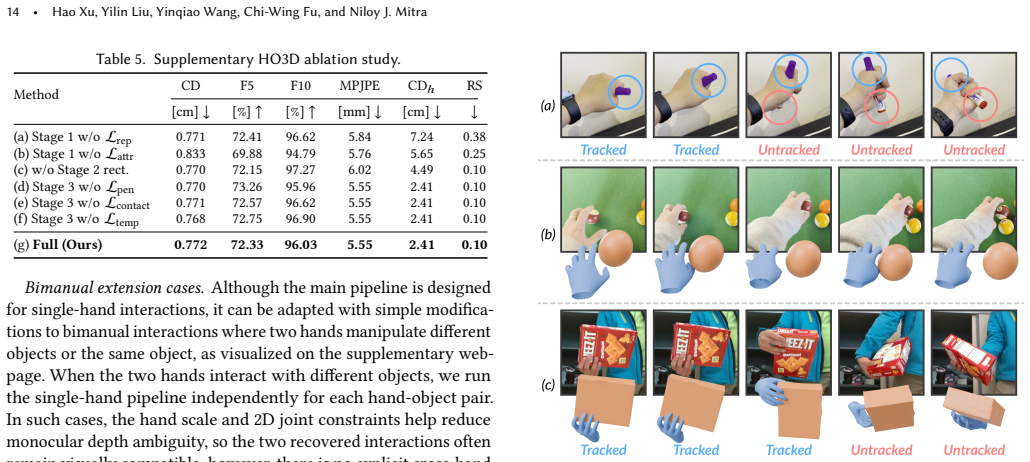
- [Experiments section] The quantitative claims of improved object reconstruction and physical plausibility rest on the assumption that post-rectification contacts provide a sufficiently accurate and stable coupling signal. However, the manuscript provides no ablation or error analysis isolating the effect of contact noise in occluded regions on the final optimization outcomes.
minor comments (2)
- [Abstract] The abstract refers to 'open-world visual priors' for initialization without naming the specific models or datasets used; adding this detail would improve reproducibility.
- [Methods] Notation for contact correspondences and ray-depth corrections could be formalized with equations in the methods to clarify how they are derived and updated across frames.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment point by point below, providing clarifications from the paper and indicating where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Pipeline description (generative rectification step)] The generative rectification module (described in the pipeline overview) predicts ray-depth corrections from visual priors without explicit contact supervision on occluded or unseen geometry. This directly affects the derived contact correspondences used as dynamic constraints in the subsequent joint optimization; if the contacts are noisy or unstable, the optimization risks overfitting to incorrect couplings or failing to resolve misalignment, which is the core failure mode the method targets.
Authors: The generative rectification module does operate from visual priors without per-pixel contact labels on occluded geometry, as the module is trained to predict plausible ray-depth corrections for relative hand-object placement. These initial contacts are not treated as fixed; Section 3.3 describes how the contact-aware joint optimization treats them as dynamic constraints that are re-evaluated and updated at each iteration to enforce geometric, temporal, and contact consistency. This iterative refinement is intended to reduce sensitivity to initial noise. We will expand the pipeline overview in Section 3.2 to explicitly note the role of dynamic updating in mitigating unstable correspondences. revision: yes
-
Referee: [Experiments section] The quantitative claims of improved object reconstruction and physical plausibility rest on the assumption that post-rectification contacts provide a sufficiently accurate and stable coupling signal. However, the manuscript provides no ablation or error analysis isolating the effect of contact noise in occluded regions on the final optimization outcomes.
Authors: We agree that an explicit ablation isolating contact noise in occluded regions would better substantiate the robustness claims. We have run additional controlled experiments that inject increasing levels of synthetic noise into the post-rectification contact maps and report the resulting changes in object reconstruction error, penetration depth, and temporal consistency metrics. These results and a short error analysis will be added to the Experiments section. revision: yes
Circularity Check
No significant circularity in CHOIR derivation chain
full rationale
The paper presents a sequential pipeline that begins with external open-world visual priors to produce a coarse contact-agnostic 4D HOI initialization, proceeds to a generative rectification module that predicts ray-depth corrections from those priors to derive per-frame contacts, and ends with a contact-aware joint optimization that enforces consistency using the derived constraints. No step equates a claimed prediction or result to its own fitted inputs by construction, nor does any load-bearing premise reduce to a self-citation chain or ansatz smuggled from prior author work. The approach remains self-contained against external benchmarks and priors, with the final outputs determined by the optimization objective rather than by re-labeling of intermediate fits.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Open-world visual priors can produce a usable coarse 4D HOI initialization even under clutter and occlusion
- domain assumption Ray-depth corrections from the generative module yield geometry accurate enough for initial contact correspondence estimation
Reference graph
Works this paper leans on
-
[1]
InProceedings of the European Conference on Computer Vision (ECCV)
Are Synthetic Data Useful for Egocentric Hand-Object Interaction Detection?. InProceedings of the European Conference on Computer Vision (ECCV). Springer, 36–54. Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. 2023. Flow Matching for Generative Modeling. InInternational Conference on Learning Representations (ICLR). Shaowei ...
work page 2023
-
[2]
EXIM: A Hybrid Explicit-Implicit Representation for Text-Guided 3D Shape Generation.ACM Transactions on Graphics (TOG)42, 6 (2023), 1–12. Yumeng Liu, Xiaoxiao Long, Zemin Yang, Yuan Liu, Marc Habermann, Christian Theobalt, Yuexin Ma, and Wenping Wang. 2025. EasyHOI: Unleashing the Power of Large Models for Reconstructing Hand-Object Interactions in the Wi...
-
[3]
MediaPipe: A Framework for Building Perception Pipelines.arXiv preprint arXiv:1906.08172(2019). Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Des- maison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Beno...
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[4]
In Advances in Neural Information Processing Systems (NeurIPS)
PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems (NeurIPS). Curran Associates, Inc., 8024–8035. Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. 2024. Reconstructing Hands in 3D with Transformers. InPro- ceedings of the IEEE/CVF C...
work page 2024
-
[5]
SAM 2: Segment Anything in Images and Videos
WiLoR: End-to-End 3D Hand Localization and Reconstruction in the Wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12242–12254. Charles R. Qi, Li Yi, Hao Su, and Leonidas J. Guibas. 2017. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. InAdvances in Neural Information Process...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
MagicHOI: Leveraging 3D Priors for Accurate Hand-Object Reconstruction from Short Monocular Video Clips. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 5957–5968. Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. 2022. ViTPose: Simple Vi- sion Transformer Baselines for Human Pose Estimation. InAdvances in Neural Infor...
-
[7]
InInternational Conference on 3D Vision (3DV)
Predicting 4D Hand Trajectory from Monocular Videos. InInternational Conference on 3D Vision (3DV). Yufei Ye, Abhinav Gupta, Kris Kitani, and Shubham Tulsiani. 2024. G-HOP: Generative Hand-Object Prior for Interaction Reconstruction and Grasp Synthesis. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1911–1920...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.