A Unifying View of Variational Generative Wasserstein Flows
Pith reviewed 2026-06-28 22:52 UTC · model grok-4.3
The pith
Many generative modeling methods arise as parametric instances of the JKO discretization of Wasserstein gradient flows for f-divergences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
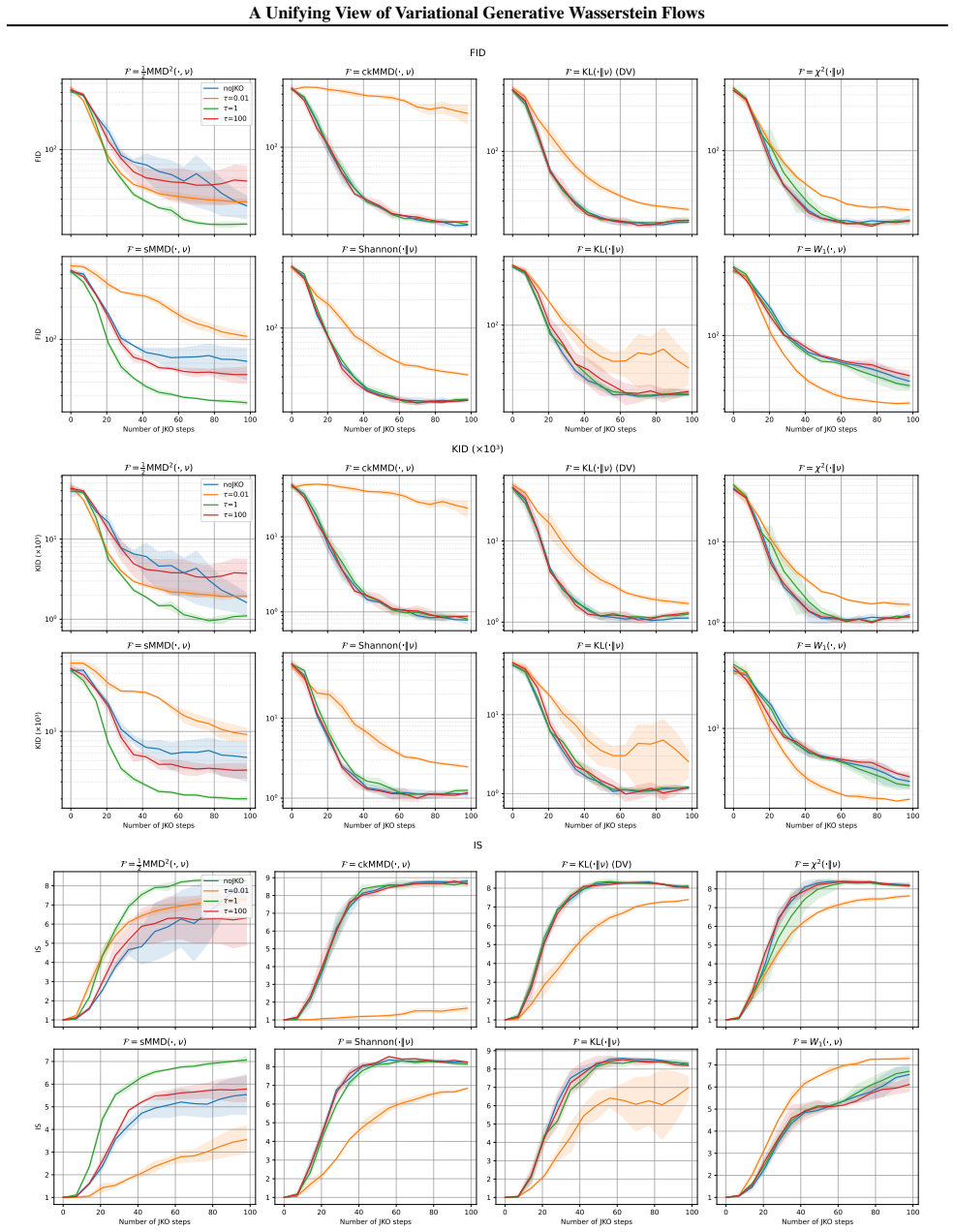
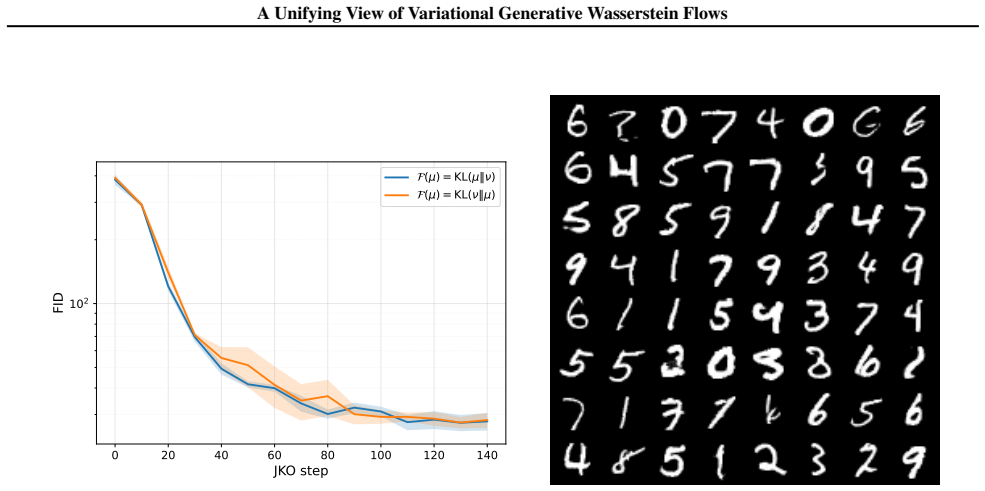
Generative Wasserstein Flows recast generative modeling as the discretization of Wasserstein gradient flows via the Jordan-Kinderlehrer-Otto scheme. A broad class of existing methods follows directly as parametric JKO schemes for f-divergence objectives, and explicit equivalences are established between several recently proposed algorithms. The framework is extended beyond f-divergences to integral probability metrics and squared maximum mean discrepancy, producing new JKO-based algorithms whose connections to GANs are clarified. The paper further studies the effect of JKO regularization on a range of objectives and analyzes the parametric case in which dynamics are confined to distributions
What carries the argument
Parametric JKO schemes for f-divergence objectives, which act as implicit discretizations of Wasserstein gradient flows when the particle dynamics are restricted to parametrized maps.
If this is right
- Several existing generative algorithms become interchangeable once rewritten in the parametric JKO form for the same f-divergence.
- New generative procedures follow by applying the JKO step to integral probability metrics or squared maximum mean discrepancy.
- The implicit regularization introduced by the JKO discretization measurably alters training dynamics across objectives.
- Restricting the flow to parametrized maps yields practical algorithms while preserving the continuous-time Wasserstein interpretation.
Where Pith is reading between the lines
- The unification may allow optimization heuristics developed for one generative family to be ported to another by translating them into the shared JKO language.
- Hybrid models could be constructed by mixing different discrepancy objectives inside the same parametric JKO iteration.
- If the parametric restriction preserves the gradient-flow structure, then convergence rates derived for the continuous flow might transfer to the discrete parametric setting with only minor adjustments.
Load-bearing premise
The JKO scheme continues to serve as a faithful implicit discretization of the underlying Wasserstein gradient flow once the dynamics are restricted to distributions induced by parametrized maps.
What would settle it
An explicit calculation showing that a standard generative algorithm cannot be recovered as a parametric JKO step for the f-divergence it is commonly associated with, or an experiment in which the claimed equivalences between algorithms produce measurably different trajectories.
Figures






read the original abstract
Many modern generative models can be viewed as minimizing divergences between probability distributions, yet they rely on different algorithmic and geometric principles. Wasserstein gradient flows provide a continuous-time formulation for optimizing over distributions, and can be approximated through their implicit discretization via the Jordan-Kinderlehrer-Otto (JKO) scheme. In this work, we present a unified theoretical framework for generative modeling based on Wasserstein gradient flows, which we refer to as Generative Wasserstein Flows (GWF). We show that a broad class of existing methods can be derived as instances of parametric JKO schemes for $f$-divergence objectives, and we establish equivalences between several recently proposed algorithms. We extend this framework beyond f-divergence to Integral Probability Metrics and squared Maximum Mean Discrepancy, deriving new JKO-based generative algorithms, and clarifying their connections with GANs. We study empirically the impact of the JKO regularization for a wide set of objectives. Finally, we analyze parametric Wasserstein flows, where the dynamics are restricted to distributions induced by parametrized maps.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Generative Wasserstein Flows (GWF) as a unifying framework viewing many generative models as parametric instances of the Jordan-Kinderlehrer-Otto (JKO) scheme applied to Wasserstein gradient flows of f-divergence objectives. It derives equivalences between existing algorithms (including GAN variants), extends the framework to Integral Probability Metrics and squared MMD to obtain new JKO-based algorithms, presents empirical results on the effect of JKO regularization across objectives, and analyzes the restriction of the dynamics to distributions induced by parametrized maps.
Significance. If the claimed derivations and equivalences hold, the work would supply a coherent geometric and variational lens on a wide range of generative modeling techniques, potentially clarifying algorithmic relationships and enabling systematic derivation of new methods. The empirical component on regularization effects and the parametric-flow analysis would add practical value, though the strength depends on the rigor of the central equivalences.
major comments (2)
- [parametric Wasserstein flows] Section on parametric Wasserstein flows: the central claim that a broad class of methods arise exactly as parametric JKO steps for f-divergence (and IPM/MMD) objectives requires that the JKO optimality condition and proximal map remain valid after confining the flow to the image of a parametric map family. No proof or explicit verification is supplied that the Euler-Lagrange equation or the implicit discretization property is preserved under this restriction; any mismatch between the unrestricted Wasserstein gradient and its projected parametric counterpart would invalidate the stated equivalences.
- [Introduction / Abstract] Abstract and introduction: the statement that 'a broad class of existing methods can be derived as instances of parametric JKO schemes' is load-bearing for the unification claim, yet the manuscript provides no explicit mapping or derivation table that lists each cited method, its objective, and the precise parametric JKO step that recovers it. Without such a concrete ledger, the scope of the unification cannot be assessed.
minor comments (2)
- Notation for the parametric map family and the induced push-forward measures should be introduced once with consistent symbols rather than redefined across sections.
- The empirical section would benefit from an explicit statement of the baseline implementations and hyper-parameter ranges used for the compared methods to allow reproduction of the reported regularization effects.
Simulated Author's Rebuttal
Thank you for the thorough review of our manuscript. We address each major comment below with clarifications on the framework and commit to revisions that enhance rigor and clarity without altering the core claims.
read point-by-point responses
-
Referee: [parametric Wasserstein flows] Section on parametric Wasserstein flows: the central claim that a broad class of methods arise exactly as parametric JKO steps for f-divergence (and IPM/MMD) objectives requires that the JKO optimality condition and proximal map remain valid after confining the flow to the image of a parametric map family. No proof or explicit verification is supplied that the Euler-Lagrange equation or the implicit discretization property is preserved under this restriction; any mismatch between the unrestricted Wasserstein gradient and its projected parametric counterpart would invalidate the stated equivalences.
Authors: We thank the referee for this observation. The parametric JKO scheme is defined directly (Section 5) as the minimization of the proximal functional over the image of the parametric map family; the optimality condition is therefore the first-order stationarity condition within that family by construction, rather than a projection of the unrestricted flow. Equivalences to existing algorithms are verified by matching their explicit update rules to this restricted argmin. We agree an explicit derivation of the restricted Euler-Lagrange equation would improve transparency and will insert a short subsection deriving it from the definition of the parametric proximal map. revision: yes
-
Referee: [Introduction / Abstract] Abstract and introduction: the statement that 'a broad class of existing methods can be derived as instances of parametric JKO schemes' is load-bearing for the unification claim, yet the manuscript provides no explicit mapping or derivation table that lists each cited method, its objective, and the precise parametric JKO step that recovers it. Without such a concrete ledger, the scope of the unification cannot be assessed.
Authors: We agree that a consolidated ledger would make the scope immediately verifiable. While the paper already derives the precise JKO steps for the cited methods in Sections 3 and 4, we will add a summary table to the revised introduction that enumerates each method, the associated objective (f-divergence, IPM, or MMD), and the corresponding parametric JKO update. This addition clarifies the unification without changing any technical content. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe a theoretical unification deriving existing generative methods as parametric JKO instances for f-divergences and extensions to IPMs. No equations or fitting procedures are shown that would make any claimed equivalence or prediction reduce to its inputs by construction. The parametric restriction is stated without evidence of self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that collapse the central claim. The derivation chain relies on independent mathematical arguments and is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Wasserstein gradient flows exist for the chosen objectives and admit JKO-scheme discretizations that remain well-defined under parametric restrictions.
Reference graph
Works this paper leans on
-
[1]
16) Alvarez-Melis, D., Schiff, Y ., and Mroueh, Y
(Cited on p. 16) Alvarez-Melis, D., Schiff, Y ., and Mroueh, Y . Optimizing Functionals on the Space of Probabilities with Input Con- vex Neural Networks.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. (Cited on p. 3, 16) Ambrosio, L., Gigli, N., and Savar´e, G.Gradient Flows: in Metric Spaces and in the Space of Probability Measures. Spr...
arXiv 2022
-
[2]
(Cited on p. 50) Donsker, M. and Varadhan, S. Asymptotic Evaluation of Certain Markov Process Expectations for Large Time .IV. InProbabilistic Methods in Differential Equations: Proceedings of the Conference Held at the University of Victoria, August 19–20, 1974, pp. 82–88. Springer, 1983. (Cited on p. 4) Dumont, T., Lacombe, T., and Vialard, F.-X. Learni...
Pith/arXiv arXiv 1974
-
[3]
4) Krizhevsky, A
(Cited on p. 4) Krizhevsky, A. and Hinton, G. Learning Multiple Layers of Features from Tiny Images. Technical report, University of Toronto, 2009. (Cited on p. 6) Lambert, M., Chewi, S., Bach, F., Bonnabel, S., and Rigol- let, P. Variational inference via Wasserstein gradient flows. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K. (eds.),Advances in ...
2009
-
[4]
19, 33) Lee, W., Wang, L., and Li, W
(Cited on p. 19, 33) Lee, W., Wang, L., and Li, W. Deep JKO: Time-implicit particle methods for general nonlinear gradient flows. Journal of Computational Physics, 514:113187, 2024. (Cited on p. 16) Li, C.-L., Chang, W.-C., Cheng, Y ., Yang, Y ., and P´oczos, B. MMD GAN: Towards Deeper Understanding of Mo- ment Matching Network.Advances in neural informat...
2024
-
[5]
ISBN 978-3- 030-26980-7
Springer International Publishing. ISBN 978-3- 030-26980-7. (Cited on p. 17, 38, 39) Li, Y ., Swersky, K., and Zemel, R. Generative Moment Matching Networks. In Bach, F. and Blei, D. (eds.), Proceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pp. 1718–1727, Lille, France, 07–09 Jul 20...
2015
-
[6]
1, 2, 5, 6, 7, 16, 17, 28, 29, 33, 53) Lipman, Y ., Chen, R
(Cited on p. 1, 2, 5, 6, 7, 16, 17, 28, 29, 33, 53) Lipman, Y ., Chen, R. T. Q., Ben-Hamu, H., Nickel, M., and Le, M. Flow Matching for Generative Modeling. InThe Eleventh International Conference on Learning Representations, 2023. (Cited on p. 1) Mahey, G.Unbalanced and Linear Optimal Transport for Reliable Estimation of the Wasserstein Distance. PhD the...
2023
-
[7]
(Cited on p
PMLR, 2020. (Cited on p. 1, 4) Manupriya, P., Jagarlapudi, S., and Jawanpuria, P. MMD- Regularized Unbalanced Optimal Transport.Transactions on Machine Learning Research, 2024. ISSN 2835-8856. (Cited on p. 5, 18, 23) Mokrov, P., Korotin, A., Li, L., Genevay, A., Solomon, J., and Burnaev, E. Large-scale wasserstein gradient flows. In Beygelzimer, A., Dauph...
2020
-
[8]
4) M¨uller, A
(Cited on p. 4) M¨uller, A. Integral Probability Metrics and their Generating Classes of Functions.Advances in applied probability, 29(2):429–443, 1997. (Cited on p. 5) Nasirzadeh, R., Mohammadi, Z., and Shishebor, Z. A New Modification of Taylor Theorem for Multivariate Vector Valued Functions.World Applied Sciences Journal, 15, 01 2011. (Cited on p. 34)...
1997
-
[9]
16) Papamakarios, G., Nalisnick, E., Rezende, D
(Cited on p. 16) Papamakarios, G., Nalisnick, E., Rezende, D. J., Mohamed, S., and Lakshminarayanan, B. Normalizing Flows for Probabilistic Modeling and Inference.Journal of Ma- chine Learning Research, 22(57):1–64, 2021. (Cited on p. 1, 3) Park, M. S., Kim, C., Son, H., and Hwang, H. J. The Deep Minimizing Movement Scheme.Journal of Computa- tional Physi...
Pith/arXiv arXiv 2021
-
[10]
(Cited on p
Springer, 2009. (Cited on p. 2, 17) Wibisono, A. Sampling as optimization in the space of measures: The Langevin dynamics as a composite opti- mization problem. InConference on learning theory, pp. 2093–3027. PMLR, 2018. (Cited on p. 3) Xu, C., Cheng, X., and Xie, Y . Normalizing flow neural networks by JKO scheme. InThirty-seventh Conference on Neural In...
2009
-
[11]
48) Yi, M., Zhu, Z., and Liu, S
(Cited on p. 48) Yi, M., Zhu, Z., and Liu, S. MonoFlow: Rethinking Diver- gence GANs via the Perspective of Wasserstein Gradient Flows. InInternational Conference on Machine Learning, pp. 39984–40000. PMLR, 2023. (Cited on p. 16) Zhai, S., Zhang, R., Nakkiran, P., Berthelot, D., Gu, J., Zheng, H., Chen, T., Bautista, M. ´A., Jaitly, N., and Susskind, J. M...
arXiv 2023
-
[12]
strong Fr ´echet differential
In this case, by (34), the optimal potentials y7→ 1 2 ∥y∥2 2 −g(y) andx7→ 1 2 ∥x∥2 2 −g c(x)are both convex, and we have gc(x) = min y 1 2 ∥x−y∥ 2 2 −g(y) = 1 2 ∥x∥2 2 −max y ⟨x, y⟩ − 1 2 ∥y∥2 2 −g(y) . (38) Moreover, on one hand, x7→ ⟨x, y⟩ is convex. On the other hand, y7→ 1 2 ∥y∥2 2 −g(y) is convex, thus y7→ ⟨x, y⟩ − 1 2 ∥y∥2 2 −g(y) is concave. Hence,...
2024
-
[13]
Lemma C.2.For all measurable functionsϕ:R d →R, we have: Z ϕdµ− Z f ∗ ◦ϕdν≤D f(µ∥ν),(51) wheref ∗(y) = supt{yt−f(t)}is the convex conjugate off
for other examples.f-divergences admit the following lower bound. Lemma C.2.For all measurable functionsϕ:R d →R, we have: Z ϕdµ− Z f ∗ ◦ϕdν≤D f(µ∥ν),(51) wheref ∗(y) = supt{yt−f(t)}is the convex conjugate off. Proof.Using the definition off ∗, for allx∈R d, f ∗ ϕ(x) = sup t {ϕ(x)t−f(t)} ≥ϕ(x)· dµ dν (x)−f dµ dν (x) ,(52) so integrating both sides w.r.t.ν...
2025
-
[14]
If π1 #γ̸=µ , then there exists f∈C b(Rd) such that R fdµ− R fd(π 1 #γ)̸= 0 , and scaling f shows that the supremum is+∞. Using this identity, we obtain sUOTc(µ, ν) = inf γ∈M+(Rd×Rd),π1 #γ=µ Z c(x, y) dγ(x, y) + λ2 2 MMD2 k(ν, π2 #γ) = inf γ∈M+(Rd×Rd) Z c(x, y) dγ(x, y) +ι {π1 #γ=µ}(γ) + λ2 2 ∥mν −m π2 #γ∥2 H. (88) Fenchel–Rockafellar formulation.We now c...
1967
-
[15]
T is parametrized as a neural network, while the optimal u is known in closed-form
Plugging this into (98), we obtain the problem sup g∈H inf T Z ∥x−T(x)∥ 2 2 −g T(x) dµ(x) + Z gdν− 1 2λ2 ∥g∥2 H.(99) Doing the change of variableg=λ 2u, we obtain sup u∈H inf T Z ∥x−T(x)∥ 2 2 −λ 2u T(x) dµ(x) + Z λ2udν− λ2 2 ∥u∥2 H.(100) 26 A Unifying View of Variational Generative Wasserstein Flows Then factorizing byλ 2, this is equivalent to sup u∈H in...
2017
-
[16]
Indeed, the left-hand side is of the form inf γ∈P2(Rd×Rd), π 1 #γ=µ sup h ˜L(γ, h) = inf γ∈P2(Rd×Rd), π 1 #γ=µ Z 1 2τ ∥x−y∥ 2 2 dγ(x, y) + Df(π2 #γ||ν),(112) and µ∈ P ac,2(Rd), thus by (Eyring et al., 2024, Proposition 3.1), the optimal plan γ is given by an OT map between µ and π2 #γ. Hence, we have inf T sup h L(T, h) = inf γ∈P2(Rd×Rd),π1 #γ=µ sup h ˜L(...
2024
-
[17]
strong gradients
Since: h(z) = 1 2τ ∥z∥2 ⇒ ∇h(z) = 1 τ z⇒(∇h) −1(u) =τ u,(124) we obtain: Tℓ+1(x) =x−(∇h) −1 ∇ϕcτ µℓ,µℓ+1(x) =x−τ∇ϕ cτ µℓ,µℓ+1(x),(125) whereϕ cτ µℓ,µℓ+1 is the Kantorovich potential betweenµ ℓ andµ ℓ+1 forc τ . Therefore, the JKO update becomes: µℓ+1 = Tℓ+1 #µℓ = (Id−τ∇ϕ cτ µℓ,µℓ+1)#µℓ.(126) We now show that the Wasserstein Gradient Descent scheme of (119...
2018
-
[18]
LargeNet
Local regularity of the objective:The map θ7→ F(µ θ) is differentiable in a neighborhood of θℓ, and its gradient is continuous. 2.Non-degeneracy of the parametrization:There existsc >0such that for allθ∈R p, ∥Fθ −F θℓ ∥2 L2(µ) ≥c∥θ−θ ℓ∥2 2, then Assumption 3 in Theorem G.4 is satisfied. Proof.Sinceθ ℓ+1 minimizesΦ ℓ, we haveΦ ℓ(θℓ+1)≤Φ ℓ(θℓ), this yields ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.