Exploring Pre-training Benefits on Phoneme Addition through Fine-tuning in Speech Synthesis
Pith reviewed 2026-06-26 16:18 UTC · model grok-4.3
The pith
Pre-training improves naturalness in TTS fine-tuning but offers limited benefit for learning new phonemes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
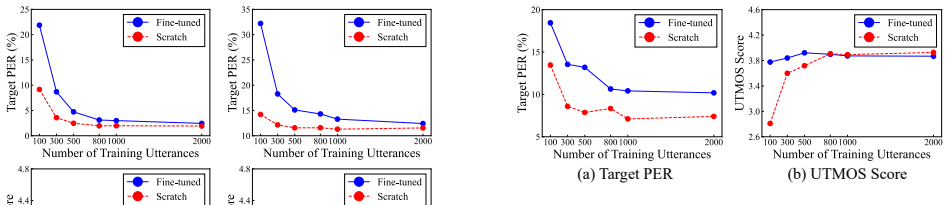
In both the simulation and real-speech settings, fine-tuning a pre-trained model achieved higher naturalness scores than training from scratch, but required as much or more data to achieve comparable phoneme error rates for the new phonemes. These findings indicate that pre-training contributes primarily to improvements in naturalness while providing limited assistance for the process of phoneme addition.
What carries the argument
The direct comparison of data efficiency for phoneme error rate on unseen phonemes between fine-tuned pre-trained models and models trained from scratch, using phoneme-controlled corpora in simulation and cross-lingual real data.
If this is right
- Fine-tuning always yields higher naturalness than scratch training even when adding phonemes.
- Comparable phoneme accuracy on new sounds takes the same or greater amount of fine-tuning data whether starting from a pre-trained model or not.
- Pre-training benefits are concentrated in aspects that affect perceived naturalness rather than in acquiring new phoneme production.
- The process of expanding the phoneme inventory during fine-tuning does not leverage prior knowledge of other phonemes effectively.
Where Pith is reading between the lines
- If the goal is only to add new phonemes with minimal data, training from scratch may be equally efficient.
- Models might benefit from targeted adaptation methods focused on the new phoneme embeddings rather than full fine-tuning.
- These results could inform choices in multilingual TTS systems where phoneme overlap varies across languages.
Load-bearing premise
The LLM-generated phoneme-controlled corpora in the simulation setup produce phoneme addition behavior that matches what occurs with actual human speech recordings.
What would settle it
An experiment showing that pre-trained models reach the target phoneme error rate on new phonemes with substantially less fine-tuning data than scratch-trained models in the real-speech setting.
Figures

read the original abstract
Transfer learning is widely used for low-resource text-to-speech. When the target corpus contains phonemes unseen in pre-training, the model must expand its phoneme inventory during fine-tuning; we call the process "phoneme addition." However, it remains unclear whether the pre-trained ability to generate seen phonemes contributes to this process. This study investigates phoneme addition in two settings: (1) a simulation setup using LLM-generated phoneme-controlled corpora that enables investigation without considering confounding factors, and (2) a real-speech cross-lingual transfer setup (English to Japanese) to validate whether the findings hold in practice. Experiments in both settings showed that while fine-tuning achieved higher naturalness than training from scratch, it required as much or more data to achieve comparable PER for new phonemes. These results indicate that pre-training mainly contributes to naturalness improvement, but offers limited benefit for phoneme addition.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that pre-training in TTS mainly improves naturalness during fine-tuning but offers limited benefit for phoneme addition: in both an LLM-generated phoneme-controlled simulation and an English-to-Japanese real-speech transfer, fine-tuning requires as much or more data than training from scratch to reach comparable phoneme error rates (PER) on unseen phonemes.
Significance. If the results hold, the work indicates that pre-training contributes primarily to prosodic and acoustic naturalness rather than efficient expansion of the phoneme inventory, which could inform the design of future pre-training objectives or targeted data collection for low-resource phoneme-addition scenarios. The use of complementary simulation and real-speech setups is a methodological strength.
major comments (1)
- [Simulation setup (abstract and methods)] Simulation setup: the central claim that pre-training offers limited benefit for phoneme addition rests on the LLM-generated corpora producing representative phoneme-learning dynamics. The abstract states the simulation “enables investigation without considering confounding factors,” but provides no evidence (e.g., statistical comparison of phoneme-context distributions, coarticulation patterns, or duration variability) that the generated data match real speech; if the simulation distorts acquisition behavior, the data-efficiency result does not generalize to the English-to-Japanese case.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the single major comment below and will revise the manuscript to incorporate additional validation where appropriate.
read point-by-point responses
-
Referee: Simulation setup: the central claim that pre-training offers limited benefit for phoneme addition rests on the LLM-generated corpora producing representative phoneme-learning dynamics. The abstract states the simulation “enables investigation without considering confounding factors,” but provides no evidence (e.g., statistical comparison of phoneme-context distributions, coarticulation patterns, or duration variability) that the generated data match real speech; if the simulation distorts acquisition behavior, the data-efficiency result does not generalize to the English-to-Japanese case.
Authors: We acknowledge that the original manuscript does not include direct statistical comparisons demonstrating that the LLM-generated corpora match real-speech distributions in phoneme contexts, coarticulation, or duration. The simulation was intentionally constructed to isolate phoneme-addition dynamics by removing real-speech confounders (e.g., speaker variability, recording conditions), which is its stated purpose. Nevertheless, to strengthen the claim of representativeness and to address generalizability, the revised version will add quantitative comparisons of phoneme-context distributions, coarticulation statistics, and duration variability between the simulated data and the real English-to-Japanese corpora. These additions will clarify the degree to which the simulation reproduces acquisition behavior and will explicitly link the simulation results to the real-speech transfer findings. revision: yes
Circularity Check
Purely empirical study; no derivations or fitted predictions
full rationale
The paper reports experimental comparisons of fine-tuning vs. scratch training on phoneme addition in two setups (LLM-simulated corpora and English-to-Japanese real speech). No equations, parameter fits, uniqueness theorems, or ansatzes are presented as predictions. Conclusions are direct measurements of naturalness and PER; no step reduces by construction to its own inputs or self-citations. This is the expected non-finding for an empirical measurement study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Exploring Pre-training Benefits on Phoneme Addition through Fine-tuning in Speech Synthesis
Introduction Recent text-to-speech (TTS) systems have achieved human- level naturalness in high-resource scenarios. However, develop- ing low-resource language TTS remains challenging. To solve this data limitation issue, transfer learning is a standard ap- proach, where a model is pre-trained on a high-resource lan- guage and subsequently fine-tuned on t...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
corpora,
Phoneme-Controlled Corpus Generation Using LLM To investigate how pre-trained phoneme knowledge contributes to unseen phoneme addition through fine-tuning, we design a phoneme-controlled experimental setup that simulates the phoneme addition process. These simulation settings enable us to investigate the phoneme addition process without consider- ing conf...
-
[3]
Scratch
Experiments This study focuses on two questions: whether a model can acquire target phonemes unseen in pre-training through fine- tuning, and how pre-trained knowledge benefits this process. We conducted two experiments under simulated phoneme- controlled settings and real-speech cross-lingual transfer set- tings. In the simulated phoneme-controlled setti...
-
[4]
Experimental Results 4.1. Results in Simulated Phoneme-Controlled Setting Figure 2 shows Target PER and UTMOS score comparisons be- tween fine-tuning and training from scratch for plosive conso- nants and front vowels across various dataset sizes (100, 300, 500, 800, 1,000, and 2,000). Across both target phoneme types, training from scratch achieved compa...
-
[5]
Conclusions This study investigated how pre-trained phoneme knowledge contributes to the phoneme addition process through fine- tuning. We conducted experiments under two settings: (1) a phoneme-controlled simulation using LLM-generated corpora to enable the comprehensive evaluation without considering confounding factors, and (2) a real-speech cross-ling...
-
[6]
Acknowledgments This work was supported in part by JSPS KAKENHI Grant Number 26H02530, and in part by the BRIDGE Program (R7-H05), implemented by the Cabinet Office, Government of Japan
-
[7]
Generative AI Use Disclosure We used ChatGPT 5.2 Pro and Claude Opus 4.6 for polishing manuscripts
-
[8]
End-to-end text-to- speech for low-resource languages by cross-lingual transfer learn- ing,
Y .-J. Chen, T. Tu, C.-c. Yeh, and H.-Y . Lee, “End-to-end text-to- speech for low-resource languages by cross-lingual transfer learn- ing,” inProc. Interspeech, 2019, pp. 2075–2079
2019
-
[9]
Text-to-speech for under-resourced languages: Phoneme mapping and source lan- guage selection in transfer learning,
P. Do, M. Coler, J. Dijkstra, and E. Klabbers, “Text-to-speech for under-resourced languages: Phoneme mapping and source lan- guage selection in transfer learning,” inProc. LREC, 2022, pp. 16–22
2022
-
[10]
Few shot cross-lingual tts using transferable phoneme embedding,
W.-P. Huang, P.-C. Chen, S.-F. Huang, and H.-y. Lee, “Few shot cross-lingual tts using transferable phoneme embedding,” inProc. Interspeech 2022, 2022, pp. 4566–4570
2022
-
[11]
Strategies in trans- fer learning for low-resource speech synthesis: Phone mapping, features input, and source language selection,
P. Do, M. Coler, J. Dijkstra, and E. Klabbers, “Strategies in trans- fer learning for low-resource speech synthesis: Phone mapping, features input, and source language selection,” inProc. SSW, 2023, pp. 26–28
2023
-
[12]
Text-to-speech system for low-resource language using cross-lingual transfer learning and data augmentation,
Z. Byambadorj, R. Nishimura, A. Ayush, K. Ohta, and N. Ki- taoka, “Text-to-speech system for low-resource language using cross-lingual transfer learning and data augmentation,”Eurasip J. Adv. Signal Process., vol. 42, pp. 1–20, 2021
2021
-
[13]
A multilingual training strategy for low resource text to speech,
A. Amalas, M. Ghogho, M. Chetouani, and R. O. H. Thami, “A multilingual training strategy for low resource text to speech,” arXiv preprint arXiv:2409.01217, 2024
-
[14]
Claude opus 4.6 system card,
Anthropic, “Claude opus 4.6 system card,” 2026, accessed 22 February 2026. [Online]. Available: https://www-cdn.anthropic. com/0dd865075ad3132672ee0ab40b05a53f14cf5288.pdf
2026
-
[15]
CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit,
J. Yamagishi, C. Veaux, and K. MacDonald, “CSTR VCTK Corpus: English multi-speaker corpus for CSTR voice cloning toolkit,”University of Edinburgh. The Centre for Speech Technol- ogy Research (CSTR), 2016
2016
-
[16]
The cmu pronouncing dic- tionary
Carnegie Mellon University, “The cmu pronouncing dic- tionary.” [Online]. Available: http://www.speech.cs.cmu.edu/ cgi-bin/cmudict
-
[17]
Recent develop- ments on espnet toolkit boosted by conformer,
P. Guo, F. Boyer, X. Chang, T. Hayashi, Y . Higuchi, H. Inaguma, N. Kamo, C. Li, D. Garcia-Romero, J. Shiet al., “Recent develop- ments on espnet toolkit boosted by conformer,” inProc. ICASSP, 2021, pp. 5874–5878
2021
-
[18]
Conformer: Convolution-augmented transformer for speech recognition,
A. Gulati, C.-C. Chiu, J. Qin, J. Yu, N. Parmar, R. Pang, S. Wang, W. Han, Y . Wu, Y . Zhang, and Z. Zhang, “Conformer: Convolution-augmented transformer for speech recognition,” in Proc. Interspeech, 2020, pp. 5036–5040
2020
-
[19]
Fastspeech 2: Fast and high-quality end-to-end text to speech,
Y . Ren, C. Hu, X. Tan, T. Qin, S. Zhao, Z. Zhao, and T.-Y . Liu, “Fastspeech 2: Fast and high-quality end-to-end text to speech,” inProc. ICLR, 2021
2021
-
[20]
ESPnet: End-to-end speech processing toolkit,
S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishitoba, Y . Unno, N. Enrique Yalta Soplin, J. Heymann, M. Wiesner, N. Chen, A. Renduchintala, and T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” inProc. Interspeech, 2018, pp. 2207–2211
2018
-
[21]
HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,
J. Kong, J. Kim, and J. Bae, “HiFi-GAN: Generative adversarial networks for efficient and high fidelity speech synthesis,” inProc. NeurIPS, vol. 33, 2020, pp. 17 022–17 033
2020
-
[22]
Simple and effective zero-shot cross-lingual phoneme recognition,
Q. Xu, A. Baevski, and M. Auli, “Simple and effective zero-shot cross-lingual phoneme recognition,” inProc. Interspeech, 2022, pp. 2113–2117
2022
-
[23]
Contextualized streaming end-to-end speech recognition with trie-based deep biasing and shallow fusion,
D. Le, M. Jain, G. Keren, S. Kim, Y . Shi, J. Mahadeokar, J. Chan, Y . Shangguan, C. Fuegen, O. Kalinli, Y . Saraf, and M. L. Seltzer, “Contextualized streaming end-to-end speech recognition with trie-based deep biasing and shallow fusion,” inProc. Interspeech, 2021, pp. 1772–1776
2021
-
[24]
Contextualized end-to-end speech recognition with contextual phrase prediction network,
K. Huang, A. Zhang, Z. Yang, P. Guo, B. Mu, T. Xu, and L. Xie, “Contextualized end-to-end speech recognition with contextual phrase prediction network,” inProc. Interspeech, 2023, pp. 4933– 4937
2023
-
[25]
Improving asr contextual biasing with guided attention,
J. Tang, K. Kim, S. Shon, F. Wu, and P. Sridhar, “Improving asr contextual biasing with guided attention,” inProc. ICASSP, 2024, pp. 12 096–12 100
2024
-
[26]
UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “UTMOS: UTokyo-SaruLab System for V oice- MOS Challenge 2022,” inProc. Interspeech, 2022, pp. 4521– 4525
2022
-
[27]
JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis
R. Sonobe, S. Takamichi, and H. Saruwatari, “Jsut corpus: free large-scale japanese speech corpus for end-to-end speech synthe- sis,”arXiv preprint arXiv:1711.00354, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[28]
Jvs corpus: free japanese multi-speaker voice cor- pus,
S. Takamichi, K. Mitsui, Y . Saito, T. Koriyama, N. Tanji, and H. Saruwatari, “Jvs corpus: free japanese multi-speaker voice cor- pus,”arXiv preprint arXiv:1908.06248, 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.