Silent Data Corruption Protection through Efficient Task Replication
Pith reviewed 2026-06-29 05:55 UTC · model grok-4.3
The pith
Replicating tasks and recording the task tree lets AMT systems isolate and correct only the SDCs that affect the final result.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that recording the dynamic task tree during replicated execution turns an otherwise intractable identification problem into a simple top-down traversal: any mismatch at a parent immediately implicates its children, and correct child results can be kept while only the corrupted subtree is recomputed.
What carries the argument
The recorded task tree together with top-down traversal that marks corrupted ancestors and reuses verified child results.
If this is right
- Recovery cost stays low because only a small fraction of tasks need recomputation.
- The scheme works for the common case of nested fork-join without requiring static task graphs.
- The same tree can be reused to discuss protection for future-based task cooperation.
- The approach fits inside existing AMT runtimes with modest changes to task scheduling and result handling.
Where Pith is reading between the lines
- If the tree-recording overhead proves small, the method could be applied to other dynamic schedulers beyond the tested runtime.
- The same traversal idea might extend to partial replication where only high-risk tasks are duplicated.
- In very large clusters the tree itself could become a new source of memory pressure that future implementations would need to bound.
Load-bearing premise
Recording the full task tree remains possible and accurate even when work stealing rearranges execution order at runtime.
What would settle it
Run the method on a program that injects a single silent corruption into one leaf task and check whether the traversal marks exactly that task and its ancestors while leaving unrelated subtrees untouched.
Figures

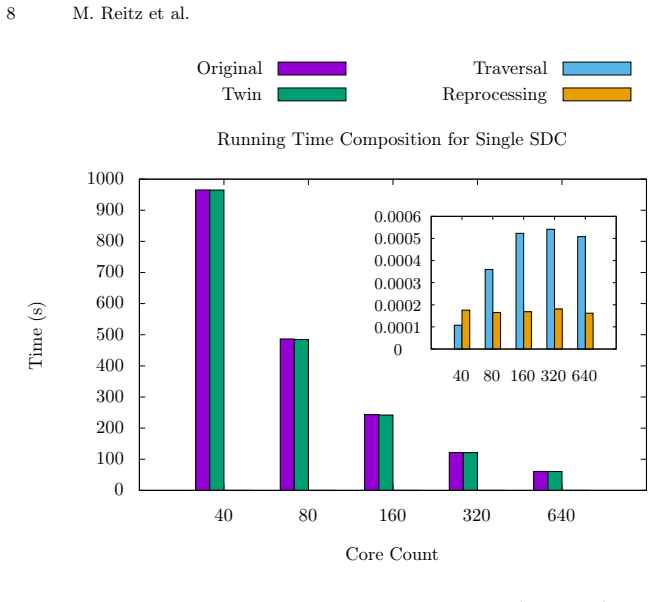
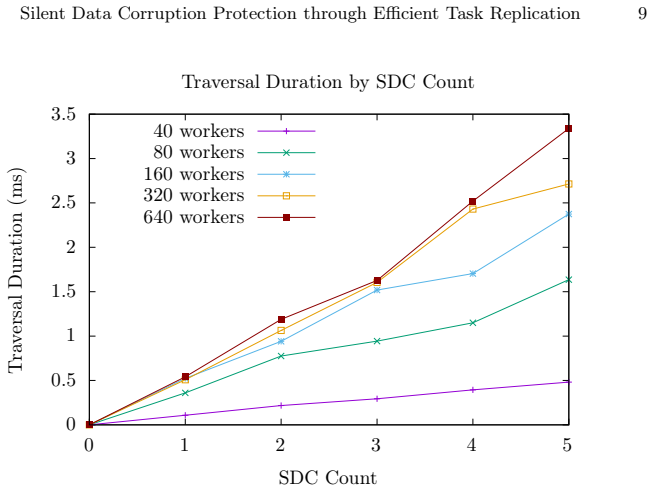
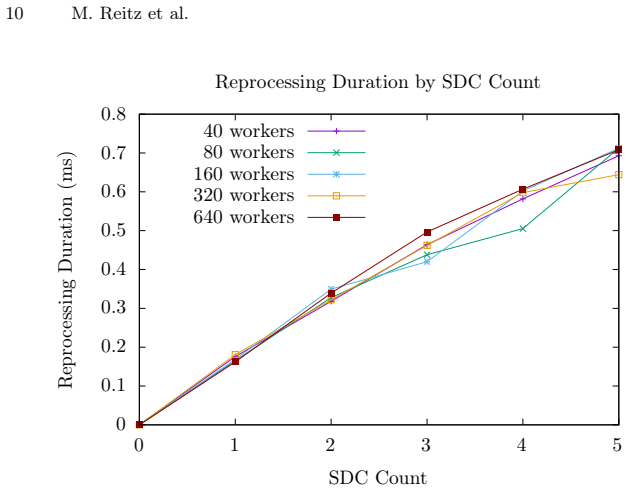

read the original abstract
The trend of increasing cluster sizes of supercomputers leads to a growing susceptibility to Silent Data Corruption (SDC) that can invalidate program results. A common strategy for SDC protection is replication, where the computation is repeated, and the correct result is determined as the one that is the same in at least two different computations. Applying replication to Asynchronous Many-Task (AMT) runtimes on clusters is challenging due to dynamic task spawning and work stealing, which complicate the identification of replicated tasks. To address the challenge, this paper introduces a novel replication scheme that detects and corrects SDCs for nested fork-join programs. Briefly stated, our approach replicates the computation and records the task tree. Upon a mismatch in the final result, it traverses the tree top-down to identify all corrupted tasks that could have impacted the final result. Recovery is then performed by recomputing these tasks, while the results of correct child tasks are reused. We demonstrate our implementation within a variant of the Itoyori cluster AMT runtime. Our experimental results suggest that the time to identify and reprocess the affected tasks is negligible. The paper concludes by discussing the adaptability of our scheme to tasks that cooperate through futures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that replicating computations in nested fork-join programs on AMT runtimes, while recording the task tree, enables efficient SDC detection and correction: upon final-result mismatch, a top-down tree traversal identifies all corrupted tasks that could affect the output, allowing selective recomputation with reuse of correct child results. The scheme is implemented in a variant of the Itoyori runtime; experiments reportedly show negligible identification/reprocessing time, and the paper discusses extension to futures-based task cooperation.
Significance. If the identification logic is shown to be correct, the approach would provide a targeted, low-overhead SDC protection mechanism for dynamic AMT systems that avoids full re-execution, addressing a practical reliability challenge in large-scale HPC. The selective recovery strategy leveraging the task tree is a direct response to the difficulties posed by work stealing and dynamic spawning.
major comments (2)
- [Abstract / experimental results] Abstract and experimental results section: the central claim that top-down traversal 'accurately isolate[s] corrupted tasks' and enables correct recovery is load-bearing, yet the manuscript provides no fault-injection experiments, no ground-truth comparison of identified vs. actually corrupted tasks, and no verification that recovered output matches a fault-free run. Only overhead is addressed.
- [Approach description] Approach description: the assumption that recording the full task tree remains feasible and correct under work stealing in dynamic AMT environments is stated but not accompanied by any analysis or measurements of tree-recording overhead or correctness under stealing.
minor comments (1)
- [Abstract] The abstract states that results 'suggest' negligible time but supplies no quantitative figures, tables, or error bars; adding these would improve clarity even if the validation experiments are added elsewhere.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where the manuscript's claims require stronger empirical support. We address each major comment below and commit to revisions that directly strengthen the validation of the proposed scheme.
read point-by-point responses
-
Referee: [Abstract / experimental results] Abstract and experimental results section: the central claim that top-down traversal 'accurately isolate[s] corrupted tasks' and enables correct recovery is load-bearing, yet the manuscript provides no fault-injection experiments, no ground-truth comparison of identified vs. actually corrupted tasks, and no verification that recovered output matches a fault-free run. Only overhead is addressed.
Authors: We agree that the current experimental evaluation focuses exclusively on overhead and does not include fault-injection studies to validate the isolation logic. In the revised manuscript we will add a dedicated fault-injection subsection that (1) injects SDCs at known task locations, (2) compares the tasks identified by top-down traversal against ground-truth corrupted tasks, and (3) confirms that the recovered final result matches a fault-free reference execution. These experiments will be performed on the same benchmarks used for the overhead measurements. revision: yes
-
Referee: [Approach description] Approach description: the assumption that recording the full task tree remains feasible and correct under work stealing in dynamic AMT environments is stated but not accompanied by any analysis or measurements of tree-recording overhead or correctness under stealing.
Authors: The manuscript states that the task tree can be recorded under work stealing but supplies neither quantitative overhead data nor a formal argument for correctness. We will augment the approach section with (a) a description of how the tree is maintained across steals, (b) measurements of the additional memory and time cost of tree recording on representative workloads, and (c) an argument (with supporting invariants) that the recorded tree remains a faithful representation of the computation even when tasks are stolen. revision: yes
Circularity Check
No circularity; algorithmic description without derivations or fitted predictions
full rationale
The paper describes a procedural replication scheme for SDC protection: replicate computation, record task tree, traverse top-down on final-result mismatch to identify corrupted tasks, then recompute selectively while reusing correct children. No equations, parameters, or predictions appear in the provided text. No self-citations are invoked to justify uniqueness, ansatz, or load-bearing premises. The central claim is the method itself, presented as a direct description rather than derived from inputs by construction. Experiments address only identification/reprocessing time (negligible), not correctness via any reduction. This matches the default expectation of no circularity for a systems/algorithm paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
(eds.): Fault-Tolerance Techniq ues for High-Performance Computing
Herault, T., Robert, Y. (eds.): Fault-Tolerance Techniq ues for High-Performance Computing. Springer (2015)
2015
-
[2]
In: Workshop on Asyn- chronous Many-Task Systems for Exascale (AMTE)
Reitz, M., Gerhards, B., Hundhausen, J., Fohry, C.: Inves tigating the performance difference of task communication via futures or side effects. In: Workshop on Asyn- chronous Many-Task Systems for Exascale (AMTE). Springer ( 2024)
2024
-
[3]
Future Generation Computing System s (FGCS) 105, 119– 134 (2019)
Posner, J., Reitz, M., Fohry, C.: A comparison of applicat ion-level fault tolerance schemes for task pools. Future Generation Computing System s (FGCS) 105, 119– 134 (2019)
2019
-
[4]
In: Workshop on Asynchronous Many-Task Syst ems for Exascale (AMTE)
Reitz, M., Fohry, C.: Task-level checkpointing for neste d fork-join programs using work stealing. In: Workshop on Asynchronous Many-Task Syst ems for Exascale (AMTE). Springer (2023)
2023
-
[5]
In : Workshop on Asyn- chronous Many-Task Systems and Applications (W AMTA) (2025 )
Reitz, M., Hundhausen, J., Fohry, C.: Fail-stop failure p rotection for coordinated work stealing of tasks that communicate through futures. In : Workshop on Asyn- chronous Many-Task Systems and Applications (W AMTA) (2025 )
2025
-
[6]
supervision
Posner, J., Reitz, M., Fohry, C.: Task-level resilience: Checkpointing vs. supervision. Special Issue International Journal of Networking and Comp uting (IJNC) 12(1), 47–72 (2022)
2022
-
[7]
In: Proceedings International Symposium on Parallel and Dis- tributed Processing (IPDPS)
Kestor, G., Krishnamoorthy, S., Ma, W.: Localized fault r ecovery for nested fork- join programs. In: Proceedings International Symposium on Parallel and Dis- tributed Processing (IPDPS). pp. 397–408. IEEE (2017)
2017
-
[8]
In: Pro ceedings of the 48th International Conference on Parallel Processing
Yasugi, M., Muraoka, D., Hiraishi, T., Umatani, S., Emoto , K.: HOPE: A paral- lel execution model based on hierarchical omission. In: Pro ceedings of the 48th International Conference on Parallel Processing. ICPP (20 19)
-
[9]
ACM Comput
Schneider, F.B.: Implementing fault-tolerant services using the state machine ap- proach: a tutorial. ACM Comput. Surv. 22(4), 299–319 (1990)
1990
-
[10]
In: Proceedings Workshop on Fault Tolerance for HPC at eXtre me Scale (FTXS)
Kolla, H., Mayo, J.R., Teranishi, K., Armstrong, R.C.: I mproving scalability of silent-error resilience for message-passing solvers via l ocal recovery and asynchrony. In: Proceedings Workshop on Fault Tolerance for HPC at eXtre me Scale (FTXS). pp. 1–10 (2020)
2020
-
[11]
Journal of Para llel and Distributed Computing (JPDC) 69(4), 410–416 (2009)
Bosilca, G., Delmas, R., Dongarra, J., Langou, J.: Algor ithm-based fault toler- ance applied to high performance computing. Journal of Para llel and Distributed Computing (JPDC) 69(4), 410–416 (2009)
2009
-
[12]
International Journal o f Parallel Programming (JPDC) 41(3), 469–493 (2012)
Ali, N., Krishnamoorthy, S., Halappanavar, M., Daily, J .: Multi-fault tolerance for cartesian data distributions. International Journal o f Parallel Programming (JPDC) 41(3), 469–493 (2012)
2012
-
[13]
Transaction on Computers 33(6), 518–528 (1984)
Huang, K.H., Abraham, J.A.: Algorithm-based fault tole rance for matrix opera- tions. Transaction on Computers 33(6), 518–528 (1984)
1984
-
[14]
In: Proceedings International Conf erence for High Perfor- mance Computing, Networking, Storage and Analysis (SC)
Kurt, M.C., Krishnamoorthy, S., Agrawal, K., Agrawal, G .: Fault-tolerant dynamic task graph scheduling. In: Proceedings International Conf erence for High Perfor- mance Computing, Networking, Storage and Analysis (SC). pp . 719–730. ACM (2014)
2014
-
[15]
In: Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS)
Samfass, P., Weinzierl, T., Reinarz, A., Bader, M.: Doub t and redundancy kill soft errors—towards detection and correction of silent data cor ruption in task-based numerical software. In: Workshop on Fault Tolerance for HPC at eXtreme Scale (FTXS). pp. 1–10 (2021)
2021
-
[16]
In: Proceedings of the Internationa l Conference for High Performance Computing, Networking, Storage and Analytics (2023)
Shiina, S., Taura, K.: Itoyori: Reconciling global addr ess space and global fork- join task parallelism. In: Proceedings of the Internationa l Conference for High Performance Computing, Networking, Storage and Analytics (2023)
2023
-
[17]
TOP500.org: Goethe-NHR, https://www.top500.org/system/179588
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.