Reformulate LLM Reinforcement Learning for Efficient Training under Black-box Discrepancy
Pith reviewed 2026-06-27 18:41 UTC · model grok-4.3
The pith
Reformulating LLM reinforcement learning as a discrepancy-constrained process stabilizes training by allowing exploration within a tolerance region while aligning train-inference behavior.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
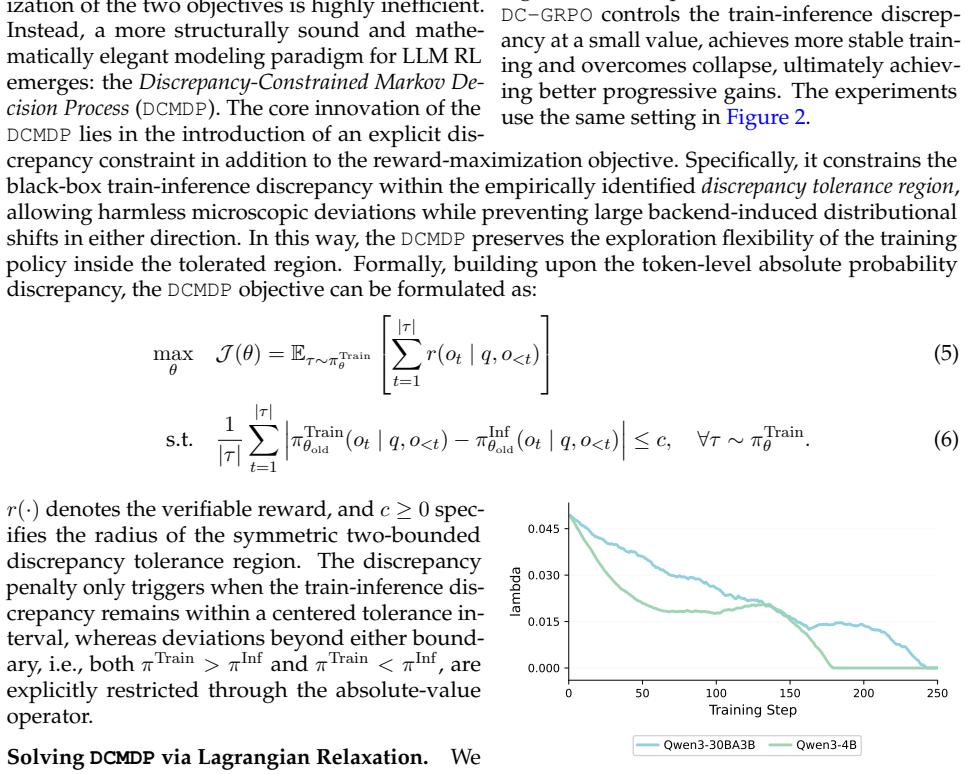
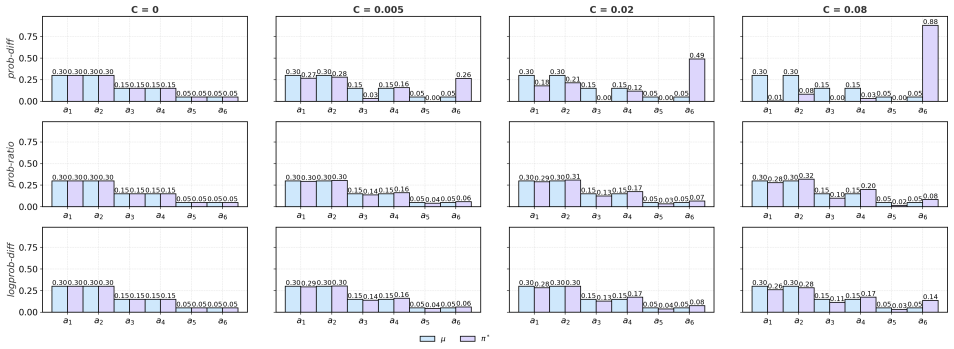
We formulate this problem as a Discrepancy-Constrained Markov Decision Process (DCMDP), where reward maximization is coupled with a constraint that aligns training-Inference behavior, achieving stable dual-objective optimization. To adaptively balance performance improvement and discrepancy control, we introduce a Lagrangian relaxation mechanism that dynamically adjusts the relative weight of the two objectives according to the current degree of discrepancy violation. This enables stable dual-objective optimization: the policy is allowed to explore freely within the tolerance region, while being guided back when the discrepancy exceeds the safe boundary. Empirically, DCMDP significantly impr
What carries the argument
Discrepancy-Constrained Markov Decision Process (DCMDP) paired with Lagrangian relaxation that dynamically reweights the discrepancy constraint according to the current violation level.
If this is right
- The policy explores freely inside the tolerance region while being pulled back only when discrepancy exceeds the boundary.
- Dual-objective optimization remains stable because the Lagrangian weight adapts automatically to the current violation degree.
- Performance improves on both 8B dense and 30B MoE models under the constrained formulation.
- Training can occur in high-fidelity setups while the learned policy is explicitly aligned for low-cost inference deployment.
Where Pith is reading between the lines
- The same constrained formulation could be tested on other post-training objectives that suffer from engine or architecture mismatch.
- If the tolerance region proves robust across model families, it would justify deliberately training on more expensive hardware while targeting cheaper inference hardware.
- Explicit identification of the tolerance region might itself become a diagnostic tool for diagnosing training instability before full runs complete.
Load-bearing premise
There exists an empirically identifiable discrepancy tolerance region inside which the policy can explore freely without aggressive discrepancy reduction suppressing learning efficiency.
What would settle it
A controlled experiment in which applying the DCMDP formulation and Lagrangian mechanism produces no performance gain, or a performance loss, relative to standard RL on the same models and tasks, or in which no consistent tolerance region can be located across runs.
Figures


read the original abstract
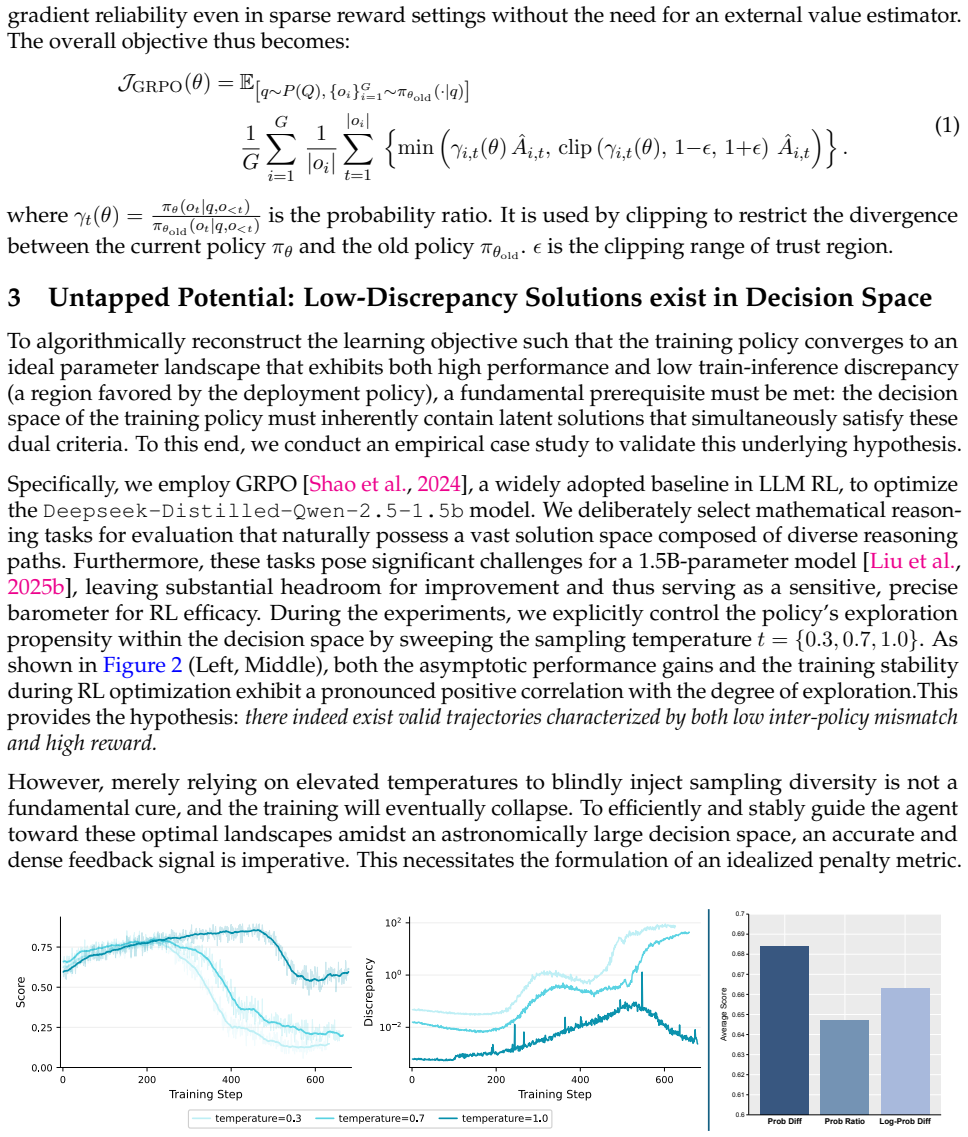
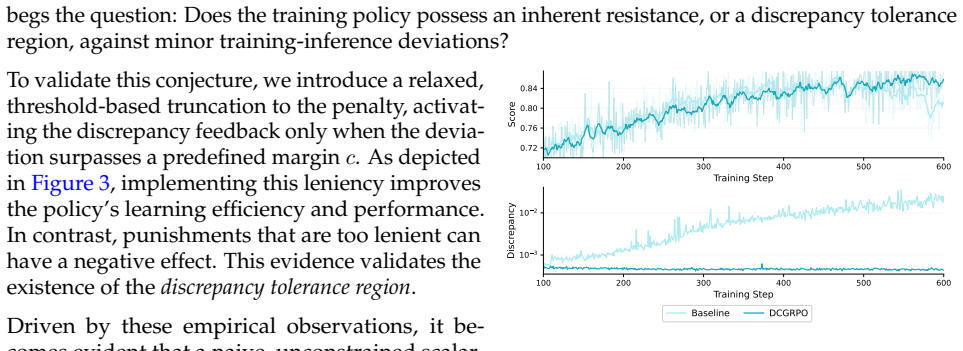
Reinforcement Learning (RL) has emerged as a pivotal post-training paradigm, yet it frequently suffers from unpredictable sub-optimum performance or even training collapses. Recent findings attribute these failures to a hidden train-inference discrepancy (or mismatch), stemming from the disparate underlying engines and architecture. We find that the training policy can actively self-correct such a discrepancy when provided with an appropriate learning signal. Then, we further empirically identify a discrepancy tolerance region: within this region, aggressively narrowing the discrepancy can suppress policy exploration and reduce learning efficiency, whereas outside this region, reducing excessive discrepancy improves optimization consistency and raises the achievable local performance ceiling. According to such findings, we formulate this problem as a Discrepancy-Constrained Markov Decision Process (DCMDP), where reward maximization is coupled with a constraint that aligns training-Inference behavior, achieving stable dual-objective optimization. To adaptively balance performance improvement and discrepancy control, we introduce a Lagrangian relaxation mechanism that dynamically adjusts the relative weight of the two objectives according to the current degree of discrepancy violation. This enables stable dual-objective optimization: the policy is allowed to explore freely within the tolerance region, while being guided back when the discrepancy exceeds the safe boundary. Empirically, DCMDP significantly improves the performance of 8B dense model (Qwen-3-8b) and 30B Mixture-of-Expert model (Qwen-3-30bA3b), and enables a heterogeneous training paradigm, where LLMs can be optimized in high-fidelity training setup while being explicitly aligned for low-cost, resource-constrained inference deployment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that train-inference discrepancy in LLM RL causes instability, that a discrepancy tolerance region exists where aggressive correction harms exploration, and that reformulating the problem as a Discrepancy-Constrained Markov Decision Process (DCMDP) with Lagrangian relaxation enables stable dual-objective optimization. This is said to yield performance gains on Qwen-3-8B and Qwen-3-30B models while supporting heterogeneous training-inference setups.
Significance. If the tolerance region is rigorously identified and the DCMDP mechanism demonstrably drives the reported gains rather than unstated factors, the work could meaningfully advance stable RL post-training for large models by allowing controlled exploration without collapse. The heterogeneous paradigm is a potentially useful practical contribution.
major comments (2)
- [Abstract, §3] Abstract and §3 (DCMDP formulation): the justification for the constrained formulation rests on an 'empirically identified' discrepancy tolerance region inside which aggressive reduction suppresses exploration. No identification procedure, metric definition, threshold values, or supporting ablation curves are provided, so the claim that the policy 'explores freely within the tolerance region' while being 'guided back' cannot be evaluated or attributed to the Lagrangian mechanism.
- [§4] §4 (Experiments): performance improvements on Qwen-3-8B and Qwen-3-30B are asserted without reported baselines, error bars, statistical tests, or ablations that isolate the effect of the discrepancy constraint versus standard RL or other regularization. This makes it impossible to confirm that the dual-objective optimization is responsible for the gains.
minor comments (2)
- [§3] Notation for the discrepancy measure and the tolerance bounds should be defined explicitly with equations rather than prose descriptions.
- [§3.2] The Lagrangian relaxation update rule and the adaptive weighting schedule need a clear algorithmic pseudocode or derivation to allow reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments correctly identify areas where additional details are required to substantiate the empirical claims and experimental results. We address each point below and commit to revisions that strengthen the paper without altering its core contributions.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (DCMDP formulation): the justification for the constrained formulation rests on an 'empirically identified' discrepancy tolerance region inside which aggressive reduction suppresses exploration. No identification procedure, metric definition, threshold values, or supporting ablation curves are provided, so the claim that the policy 'explores freely within the tolerance region' while being 'guided back' cannot be evaluated or attributed to the Lagrangian mechanism.
Authors: We agree that the manuscript does not provide sufficient detail on the empirical identification of the discrepancy tolerance region. In the revised version, we will expand §3 with a new subsection that defines the discrepancy metric (token-level KL divergence between training and inference distributions), describes the identification procedure via systematic ablations across discrepancy levels, reports the specific threshold values used, and includes the corresponding ablation curves demonstrating the exploration-performance trade-off inside versus outside the region. This will make the justification for the DCMDP formulation and the Lagrangian mechanism fully evaluable. revision: yes
-
Referee: [§4] §4 (Experiments): performance improvements on Qwen-3-8B and Qwen-3-30B are asserted without reported baselines, error bars, statistical tests, or ablations that isolate the effect of the discrepancy constraint versus standard RL or other regularization. This makes it impossible to confirm that the dual-objective optimization is responsible for the gains.
Authors: The referee is correct that the current experimental section is missing essential elements for rigorous validation. We will revise §4 to include: (i) direct comparisons against standard RL baselines such as PPO without the discrepancy constraint, (ii) results reported as means with standard deviations over at least three random seeds with error bars, (iii) statistical significance tests (e.g., paired t-tests), and (iv) targeted ablations that vary the Lagrangian multiplier and constraint strength to isolate the contribution of the dual-objective optimization. These additions will allow attribution of gains specifically to the DCMDP mechanism. revision: yes
Circularity Check
No significant circularity; formulation presented as response to empirical observations without reduction to inputs by construction.
full rationale
The abstract states empirical findings on train-inference discrepancy and a tolerance region, then formulates DCMDP and Lagrangian relaxation accordingly. No equations, fitted parameters, or self-citations are shown that would make the DCMDP constraint or dual-objective optimization equivalent to the inputs by definition. The tolerance region is described as empirically identified rather than self-defined, and the derivation chain does not reduce the claimed performance gains to a tautology or unverified self-reference. The paper's central claims remain independent of the listed circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existence of a discrepancy tolerance region where moderate mismatch aids exploration but excess harms consistency
invented entities (1)
-
Discrepancy-Constrained Markov Decision Process (DCMDP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Probing RLVR training instability through the lens of objective-level hacking
Yiming Dong, Kun Fu, Haoyu Li, Xinyuan Zhu, Yurou Liu, Lijing Shao, Jieping Ye, and Zheng Wang. Probing rlvr training instability through the lens of objective-level hacking.arXiv preprint arXiv:2602.01103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.211. URL https://aclanthology.org/2024.acl-long.211/. Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model. InThe Thirty-ninth Annual Conference on Neu...
-
[3]
Qwen2.5-Coder Technical Report
URL https://openreview.net/forum?id=NFM8F5cV0V. Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Keming Lu, et al. Qwen2.5-coder technical report.arXiv preprint arXiv:2409.12186,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
Association for Computing Machinery. ISBN 9798400702297. doi: 10.1145/3600006.3613165. URL https://doi.org/10.1145/3600006. 3613165. Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, Yuhuai Wu, Behnam Neyshabur, Guy Gur-Ari, and Vedant Misra. Solving q...
-
[5]
Trust Region Masking for Long-Horizon LLM Reinforcement Learning
URL https://proceedings.neurips.cc/paper_files/paper/2022/file /18abbeef8cfe9203fdf9053c9c4fe191-Paper-Conference.pdf. Yingru Li, Jiacai Liu, Jiawei Xu, Yuxuan Tong, Ziniu Li, Qian Liu, and Baoxiang Wang. Trust region masking for long-horizon llm reinforcement learning.arXiv preprint arXiv:2512.23075,
work page internal anchor Pith review arXiv 2022
-
[6]
Qurl: Efficient reinforcement learning with quantized rollout.arXiv preprint arXiv:2602.13953,
Yuhang Li, Reena Elangovan, Xin Dong, Priyadarshini Panda, and Brucek Khailany. Qurl: Efficient reinforcement learning with quantized rollout.arXiv preprint arXiv:2602.13953,
-
[7]
URL https://openreview.net/for um?id=v8L0pN6EOi. Hanbing Liu, Lang Cao, Yuanyi Ren, Mengyu Zhou, Haoyu Dong, Xiaojun Ma, Shi Han, and Dongmei Zhang. Bingo: Boosting efficient reasoning of llms via dynamic and significance-based reinforcement learning.arXiv preprint arXiv:2506.08125, 2025a. Jiashun Liu, Johan S. Obando-Ceron, Han Lu, Yancheng He, Weixun Wa...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Accessed: 2026-04-30
URL https://artofpro blemsolving.com/wiki/index.php/AMC_12_Problems_and_Solutions . Accessed: 2026-04-30. MAA. American invitational mathematics examination (aime), February
2026
-
[9]
Accessed: 2026-04-30
URL https: //artofproblemsolving.com/wiki/index.php/2024_AIME_I. Accessed: 2026-04-30. MAA. American invitational mathematics examination (aime), February
2026
-
[10]
Defeating the training-inference mismatch via fp16.arXiv preprint arXiv:2510.26788,
URL https: //artofproblemsolving.com/wiki/index.php/2025_AIME_I. Accessed: 2026-04-30. Penghui Qi, Zi-Yan Liu, Xiangxin Zhou, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Defeating the training-inference mismatch via fp16.ArXiv, abs/2510.26788,
-
[11]
Proximal Policy Optimization Algorithms
URL https://api.se manticscholar.org/CorpusID:282591916. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catan- zaro. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[14]
Ling Team, Anqi Shen, Baihui Li, Bin Hu, Bin Jing, Cai Chen, Chao Huang, Chao Zhang, Chaokun Yang, Cheng Lin, et al. Every step evolves: Scaling reinforcement learning for trillion-scale thinking model.arXiv preprint arXiv:2510.18855,
-
[15]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Yaxiang Zhang, Yingru Li, Jiacai Liu, Jiawei Xu, Ziniu Li, Qian Liu, and Haoyuan Li
URL https://openreview.net/forum?id=2a 36EMSSTp. Yaxiang Zhang, Yingru Li, Jiacai Liu, Jiawei Xu, Ziniu Li, Qian Liu, and Haoyuan Li. Beyond precision: Training-inference mismatch is an optimization problem and simple lr scheduling fixes it.arXiv preprint arXiv:2602.01826,
-
[17]
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.