Ablation-Reversible Heads Don't Transfer: A Stress Test for Mechanistic Role Claims in Transformers
Pith reviewed 2026-06-27 19:31 UTC · model grok-4.3
The pith
Attention heads passing necessity, linear encoding, and ablation-reversibility checks routinely fail to transfer computations when patched into new prompts under matched controls.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across three 7-8B instruction-tuned models and five computation families, heads passing necessity, linear encoding, and ablation-reversibility checks routinely fail to transfer the computation when their activations are patched into a different prompt under matched controls.
What carries the argument
The KID (Knowing/Intent/Doing) role-assignment lens paired with a three-stage pipeline of capability-selective screening, singular value decomposition, and activation transduction under matched controls.
If this is right
- Existing role claims based only on necessity, linear encoding, and ablation-reversibility require additional transfer validation.
- The same-answer control should be used more widely to separate specific computation from broad state transfer.
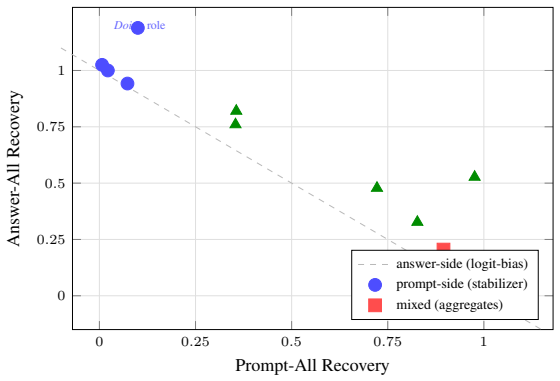
- Analysis yields a preliminary taxonomy of head roles including prompt-trajectory stabilizers, answer-side logit-bias heads, and soft computation-pattern carriers.
Where Pith is reading between the lines
- The results suggest that many existing mechanistic claims may be identifying prompt-dependent patterns rather than general computations.
- Broader use of the same-answer control could revise or strengthen findings from earlier interpretability studies.
- The pipeline could be applied to test role claims for other model components such as MLPs.
Load-bearing premise
That the activation transduction under matched controls including the same-answer control isolates semantic specificity rather than other factors such as prompt trajectory or general state transfer.
What would settle it
Observing reliable transfer of the claimed computation when patching activations from heads that pass the three checks into new prompts under the same matched controls would show the checks are sufficient.
Figures

read the original abstract
In mechanistic interpretability, attention heads are commonly elevated to role claims (e.g., "this head represents addition") when they are necessary for a behavior, encode it linearly, and recover that behavior when restored after ablation. We show this evidence is insufficient: across three 7-8B instruction-tuned models and five computation families, heads passing all three checks routinely fail to transfer the computation when their activations are patched into a different prompt under matched controls. We introduce KID (Knowing / Intent / Doing), a role-assignment lens for attention heads, and pair it with a three-stage pipeline: capability-selective screening (CSS), singular value decomposition (SVD), and activation transduction under matched controls. Our results document a preliminary role taxonomy (including prompt-trajectory stabilizers, answer-side logit-bias heads, and soft computation-pattern carriers) and show that the same-answer control (a transduction target sharing the answer string but not the requested computation) is an underused check that exposes broad state transfer masquerading as semantic specificity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that standard mechanistic interpretability checks for attention-head roles (necessity for a behavior, linear encoding of it, and ablation-reversibility) are insufficient to establish semantic specificity. Across three 7-8B instruction-tuned models and five computation families, heads passing all three checks routinely fail to transfer the target computation when patched into different prompts under matched controls; the authors introduce the KID (Knowing/Intent/Doing) lens together with a CSS-SVD-transduction pipeline and document a preliminary role taxonomy that includes prompt-trajectory stabilizers, answer-side logit-bias heads, and soft computation-pattern carriers, while highlighting the same-answer control as an underused safeguard against state-transfer confounds.
Significance. If the empirical results hold, the work would be significant for mechanistic interpretability: it supplies a concrete stress test showing that three widely used criteria do not isolate semantic roles, introduces matched-control transduction as a stronger diagnostic, and offers an initial taxonomy that could guide more precise role assignments. The multi-model, multi-task design and explicit emphasis on reproducible pipelines are strengths that would make the negative result broadly relevant.
major comments (2)
- [Abstract] Abstract: the central negative result is stated clearly but provides no quantitative details on effect sizes, number of heads tested, or exact matching criteria for controls; the claim that the three checks are routinely insufficient therefore rests on an unshown experimental pipeline.
- [Abstract] Abstract / pipeline description: the same-answer control is presented as exposing broad state transfer, yet the manuscript does not report how trajectory matching (token length, preceding tokens, attention patterns) is enforced or supply quantitative similarity metrics between source and target contexts; without these, the transduction failures could reflect non-semantic mismatches rather than absence of semantic role.
minor comments (1)
- [Abstract] The acronym KID is introduced without spelling it out on first use.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on the abstract. We agree that additional quantitative and methodological details would strengthen it and will revise accordingly while preserving the paper's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central negative result is stated clearly but provides no quantitative details on effect sizes, number of heads tested, or exact matching criteria for controls; the claim that the three checks are routinely insufficient therefore rests on an unshown experimental pipeline.
Authors: The experimental pipeline, including all quantitative results on heads tested, effect sizes, and failure rates, is fully detailed in Sections 3 and 4 of the manuscript. We acknowledge that the abstract is concise and will revise it to include summary statistics (number of heads, models, tasks, and aggregate transfer failure rates) along with a brief reference to the matching criteria defined in the methods. revision: yes
-
Referee: [Abstract] Abstract / pipeline description: the same-answer control is presented as exposing broad state transfer, yet the manuscript does not report how trajectory matching (token length, preceding tokens, attention patterns) is enforced or supply quantitative similarity metrics between source and target contexts; without these, the transduction failures could reflect non-semantic mismatches rather than absence of semantic role.
Authors: The methods section (and appendices) describe the trajectory matching procedure, including token-length equalization, preceding-token selection, and attention-pattern similarity thresholds, with quantitative metrics reported in supplementary tables. We agree the abstract is too terse on this point and will expand it with a concise description of the controls and a reference to the similarity metrics. revision: yes
Circularity Check
No circularity: empirical patching experiments contain no derivation chain reducing to inputs
full rationale
The manuscript advances its central claim—that necessity, linear encoding, and ablation-reversibility are insufficient for role assignment—solely through direct experimental measurements of activation transduction under matched controls. No equations, fitted parameters, or self-citations are invoked as load-bearing premises; the KID taxonomy and three-stage pipeline (CSS, SVD, transduction) are presented as post-hoc interpretive lenses derived from the observed transfer failures rather than from any prior fitted quantities or uniqueness theorems. The argument is therefore self-contained against external benchmarks of the patching methodology and does not reduce any prediction to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation patching under matched controls isolates the contribution of a head to a specific computation rather than general prompt state.
Reference graph
Works this paper leans on
-
[1]
B. Ahmad et al. Beyond components: Singular vector-based interpretability of transformer circuits. arXiv preprint arXiv:2511.20273,
-
[2]
S. Bair et al. Compressed sensing for capability localization in LLMs.arXiv preprint arXiv:2603.03335,
-
[3]
A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Yang, A. Fan, et al. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
-
[4]
URLhttps://arxiv.org/abs/2006.00995. N. Elhage, T. Hume, C. Olsson, N. Schiefer, T. Henighan, S. Kravec, Z. Hatfield-Dodds, R. Lasenby, D. Drain, C. Chen, et al. Toy models of superposition. Transformer Circuits Thread,
arXiv 2006
-
[5]
URL https://transformer-circuits.pub/2022/toy_model/index.html. D. Friedman, A. K. Lampinen, L. Dixon, D. Chen, and A. Ghandeharioun. Interpretability illusions in the generalization of simplified models. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 14035– 14059,
2022
-
[6]
URLhttps://arxiv.org/abs/2312.03656. E. Hernandez, A. Variengien, D. Bau, and J. Andreas. Linearity of relation decoding in transformer language models.arXiv preprint arXiv:2308.09124,
-
[7]
URLhttps://arxiv.org/abs/ 2308.09124. J. Hewitt and P. Liang. Designing and interpreting probes with control tasks. InProceedings of the 2019 Conference on Empirical Methods in Natural Language Processing,
arXiv 2019
-
[9]
URLhttps://arxiv.org/abs/2310.06825. S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnson, S. Johnston, S. El-Showk, A. Jones, N. Elhage, T. Hume, A. Chen, Y . Bai, S. Bowman, S. Fort, D. Ganguli, D. Hernandez, J. Jacobson, J. Kernion, S. Kravec, L. Lovitt, K. Ndousse, C. Olsson,...
-
[10]
URLhttps://zenodo.org/records/19671185
doi: 10.5281/zenodo.19671185. URLhttps://zenodo.org/records/19671185. Preprint, accepted to ICML
-
[11]
Makelov, G
A. Makelov, G. Lange, and N. Nanda. Is this the subspace you are looking for? an interpretabil- ity illusion for subspace activation patching. InNeurIPS 2023 Workshop on Attributing Model Behavior at Scale,
2023
-
[12]
URLhttps://arxiv.org/abs/2311.17030. 10 C. McDougall, A. Conmy, C. Rushing, T. McGrath, and N. Nanda. Copy suppression: Com- prehensively understanding an attention head.arXiv preprint arXiv:2310.04625,
-
[13]
URL https://arxiv.org/abs/2310.04625. M. Méloux, F. Portet, and M. Peyrard. Mechanistic interpretability as statistical estimation: A variance analysis.arXiv preprint arXiv:2510.00845,
-
[14]
URLhttps://arxiv.org/abs/ 2510.00845. K. Meng, D. Bau, A. Andonian, and Y . Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, volume 35,
-
[15]
URLhttps://transformer-circuits.pub/2022/ in-context-learning-and-induction-heads/index.html. Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115,
Pith/arXiv arXiv 2022
-
[16]
URL https://arxiv.org/abs/2501.16496. E. Todd, M. Li, A. S. Sharma, A. Mueller, B. C. Wallace, and D. Bau. Function vectors in large language models. InInternational Conference on Learning Representations,
-
[17]
URLhttps://arxiv.org/abs/2211.00593. M. Yu, M. Chaudhary, et al. The super weight in large language models.arXiv preprint arXiv:2411.07191,
-
[18]
URLhttps://arxiv.org/abs/2411.07191. F. Zhang and N. Nanda. Towards best practices of activation patching in language models: Metrics and methods. InInternational Conference on Learning Representations,
-
[19]
URLhttps: //arxiv.org/abs/2309.16042. A Broader Impacts This work is foundational interpretability research. Its positive impact is to make mechanistic ev- idence standards more precise: behaviorally important, decodable, and ablation-reversible compo- nents should not be promoted to semantic role claims without matched interventional tests. Better eviden...
Pith/arXiv arXiv 2026
-
[20]
What isa⊕b?
Model + prompt-family cell.The primary unit of analysis: the intersection of one model and one prompt family, writtenqwen maths,llama digits, etc. Rk.Rankkwithin the cumulative top-5 CSS set for a cell. R1 is the head with highest individual selectivity; R2–R5 are added greedily. 13 C Case Studies This appendix gives full numerical detail for the case-stu...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.