Explainable Forensics of Manipulated Segments in Untrimmed Long Videos
Pith reviewed 2026-06-28 14:46 UTC · model grok-4.3
The pith
The paper formulates a new task for localizing and explaining AI-manipulated segments in long untrimmed videos and introduces a benchmark and baseline method to address it.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
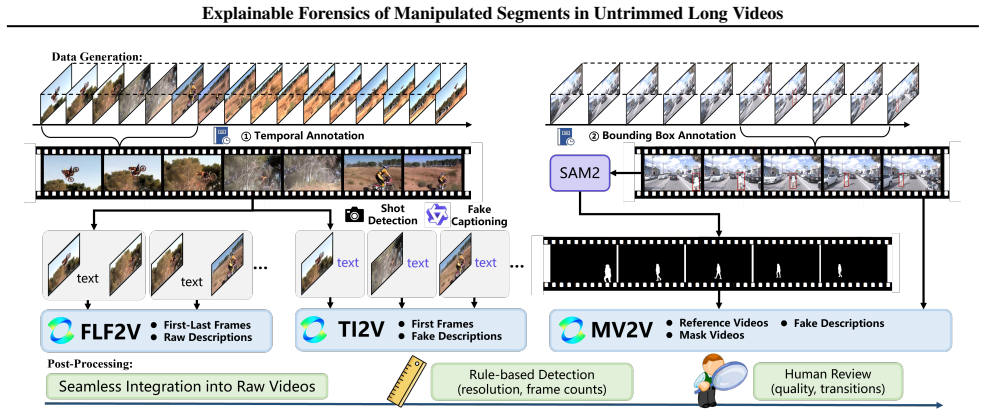
Existing video forensic methods fail on long videos because they operate on short independent clips, while realistic AI manipulations appear as sparse segments within authentic footage. This paper formulates the Temporal AI-Generated Segment Localization and Explanation task, introduces the TASLE benchmark of 12,472 untrimmed videos annotated with temporal boundaries, authenticity labels and segment-level rationales, and proposes the MSLoc baseline that combines boundary-sensitive proposal generation for efficient scanning with MLLM-based refinement for precise localization and interpretable reasoning. Experiments validate the baseline's effectiveness.
What carries the argument
The MSLoc baseline, a coarse-to-fine forensic method that first uses boundary-sensitive proposal generation for efficient long-video scanning and then applies an MLLM-based refinement module for precise boundary localization and interpretable reasoning.
If this is right
- Segment-level explainable forensics becomes feasible for untrimmed long videos with sparse manipulations.
- The TASLE benchmark enables standardized evaluation across diverse manipulation patterns and rich annotation signals.
- Coarse-to-fine processing allows efficient scanning of long videos without full fine-grained analysis from the outset.
- MLLM refinement supplies segment-level rationales that support interpretable analysis beyond binary authenticity labels.
Where Pith is reading between the lines
- The task formulation could support extension to streaming or live video where manipulations must be flagged in real time.
- Emphasis on sparse segments may reduce false positives relative to methods that classify entire videos.
- Segment-level rationales in the benchmark could aid development of detection systems that output human-readable justifications.
- The approach points toward future benchmarks that prioritize realistic video durations over curated short clips.
Load-bearing premise
That existing short-clip forensic methods necessarily fail on realistic long videos containing only sparse manipulated segments.
What would settle it
An experiment in which an unmodified short-clip forensic method achieves comparable or higher accuracy on the TASLE benchmark than the proposed MSLoc baseline.
Figures

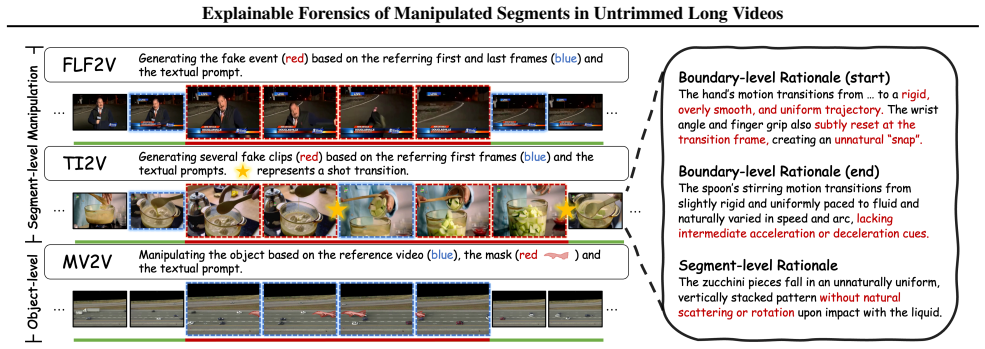
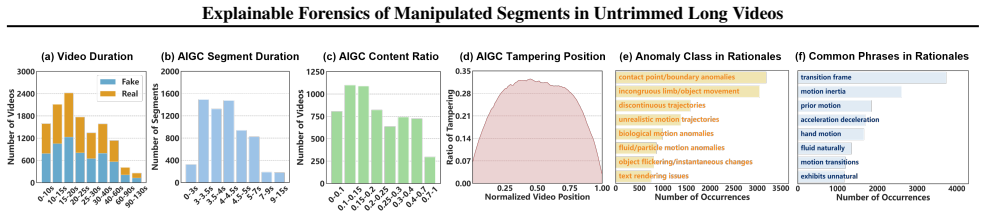
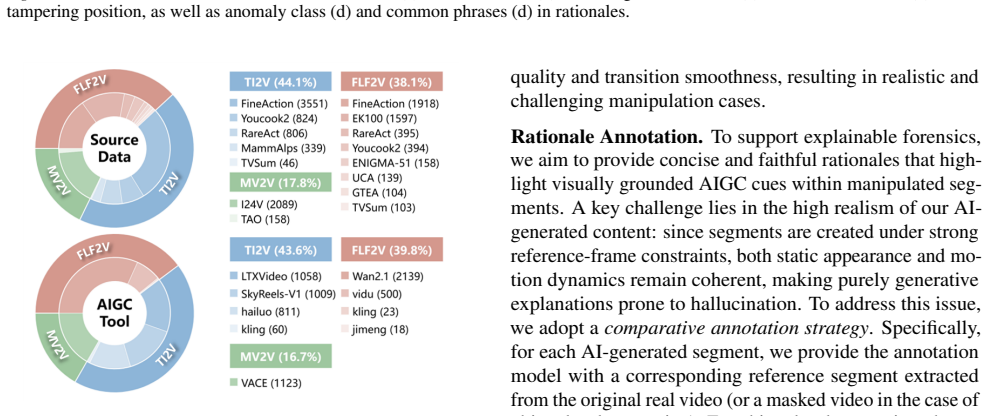
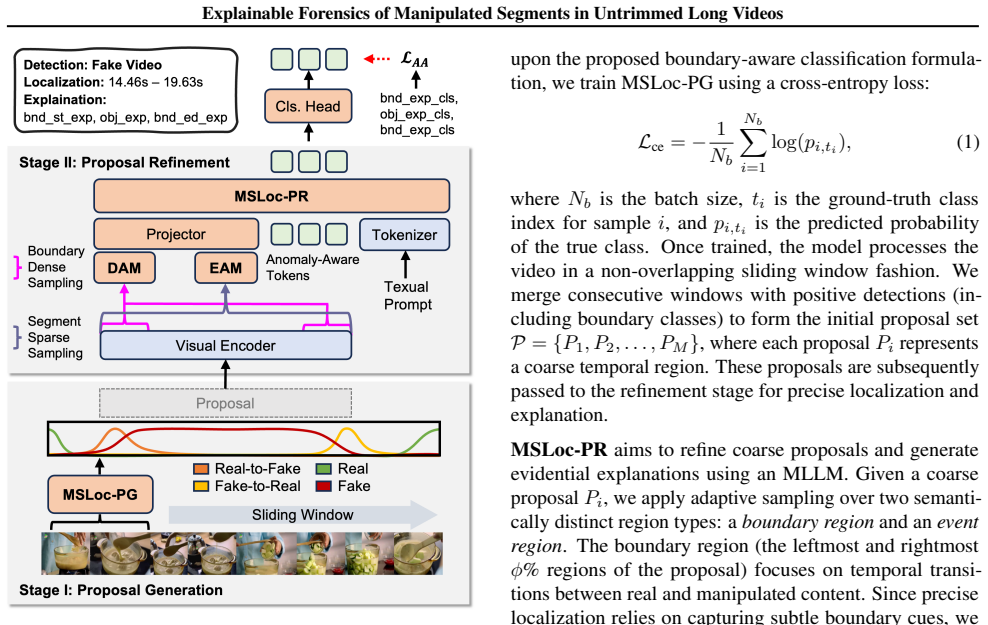



read the original abstract
The rapid advancement of AI-driven video generation has transformed content creation, while simultaneously increasing the risk of misinformation through localized manipulations in long-form videos. Existing video forensic methods predominantly operate on short, independent clips, and thus fail to capture realistic scenarios where AI-generated content is sparsely embedded within otherwise authentic footage. To bridge this gap, we formulate the task of Temporal AI-Generated Segment Localization and Explanation, which targets authenticity detection, temporal localization, and interpretable analysis of manipulated segments in untrimmed long videos. We further introduce TASLE, a large-scale benchmark comprising 12,472 untrimmed videos with diverse manipulation patterns and rich annotation signals, including temporal boundaries, authenticity labels, and segment-level rationales. In addition, we propose MSLoc, a coarse-to-fine forensic baseline that combines a boundary-sensitive proposal generation module for efficient long-video scanning with an MLLM-based refinement module for precise boundary localization and interpretable reasoning. Experiments validate the effectiveness of the proposed baseline, highlighting the importance of segment-level explainable forensics for long-form AI-generated video analysis. Our dataset and code are publicly available at https://debby-0527.github.io/TASLE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates the new task of Temporal AI-Generated Segment Localization and Explanation targeting authenticity detection, temporal localization, and interpretable analysis of manipulated segments in untrimmed long videos. It releases the TASLE benchmark of 12,472 videos annotated with temporal boundaries, authenticity labels, and segment-level rationales. It introduces the MSLoc coarse-to-fine baseline that uses boundary-sensitive proposal generation for long-video scanning followed by MLLM-based refinement for precise localization and reasoning. The manuscript states that experiments validate the effectiveness of this baseline.
Significance. If the reported experiments hold, the work is significant as the first large-scale benchmark and baseline explicitly designed for sparse manipulations in realistic long-form videos rather than short independent clips. The public release of TASLE and code is a concrete community resource. The coarse-to-fine design with MLLM refinement supplies both efficiency and segment-level explanations, directly addressing a practical gap in forensic analysis of AI-generated content.
major comments (1)
- [Abstract] Abstract: the claim that 'Experiments validate the effectiveness of the proposed baseline' supplies no quantitative metrics, baselines, ablation results, or error analysis, which is load-bearing for the central empirical contribution of the paper.
Simulated Author's Rebuttal
We thank the referee for the careful review and the recommendation for major revision. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'Experiments validate the effectiveness of the proposed baseline' supplies no quantitative metrics, baselines, ablation results, or error analysis, which is load-bearing for the central empirical contribution of the paper.
Authors: We agree that the abstract claim is currently unsupported by numbers. The full manuscript contains quantitative results (mAP, precision/recall for localization, explanation accuracy), baseline comparisons, ablations on the coarse-to-fine design, and error analysis in Sections 4–5. To address the concern directly, we will revise the abstract to include specific metrics and comparisons that substantiate the effectiveness claim. revision: yes
Circularity Check
No significant circularity; self-contained task+dataset contribution
full rationale
The paper formulates a new task (Temporal AI-Generated Segment Localization and Explanation), releases the TASLE benchmark with annotations, and introduces a coarse-to-fine MSLoc baseline. No equations, fitted parameters, or derivations are described in the provided text. The central claims rest on the new task definition and experimental validation of the baseline rather than any reduction to prior inputs by construction. No self-citation chains or ansatzes are invoked as load-bearing premises. This matches the default expectation of a non-circular contribution.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
- [2]
-
[3]
Jimeng AI official plat- form for image and video generation
URL https: //jimeng.jianying.com/. Jimeng AI official plat- form for image and video generation. Chen, H., Hong, Y ., Huang, Z., Xu, Z., Gu, Z., Li, Y ., Lan, J., Zhu, H., Zhang, J., Wang, W., et al. Demamba: Ai-generated video detection on million-scale genvideo benchmark.arXiv preprint arXiv:2405.19707,
-
[4]
9 Explainable Forensics of Manipulated Segments in Untrimmed Long Videos Chen, W., Zheng, W., Zheng, Y ., Chen, L., Zhou, J., Lu, J., and Duan, Y . Genworld: Towards detecting ai- generated real-world simulation videos.arXiv preprint arXiv:2506.10975,
-
[5]
Fathi, A., Ren, X., and Rehg, J
URL https://arxiv.org/abs/ 2005.10356. Fathi, A., Ren, X., and Rehg, J. M. Learning to recognize objects in egocentric activities. InCVPR 2011, pp. 3281–
arXiv 2005
-
[6]
URL https://doi.org/ 10.1007/s11633-025-1585-x
1007/s11633-025-1585-x. URL https://doi.org/ 10.1007/s11633-025-1585-x. Gabeff, V ., Qi, H., Flaherty, B., Sumb ¨ul, G., Mathis, A., and Tuia, D. Mammalps: A multi-view video behavior monitoring dataset of wild mammals in the swiss alps. arXiv,
-
[7]
doi: 10.48550/arXiv.2503.18223. Gao, Y ., Ding, Y ., Su, H., Li, J., Zhao, Y ., Luo, L., Chen, Z., Wang, L., Wang, X., Wang, Y ., Ma, X., and Jiang, Y .-G. David-xr1: Detecting ai-generated videos with explainable reasoning,
-
[8]
URL https://arxiv. org/abs/2506.14827. Gloudemans, D., Zach ´ar, G., Wang, Y ., Ji, J., Nice, M., Bunting, M., Barbour, W. W., Sprinkle, J., Piccoli, B., Monache, M. L. D., et al. So you think you can track? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pp. 4528–4538,
-
[9]
URL https://arxiv.org/abs/ 2410.05643. HaCohen, Y ., Chiprut, N., Brazowski, B., Shalem, D., Moshe, D., Richardson, E., Levin, E., Shiran, G., Zabari, N., Gordon, O., Panet, P., Weissbuch, S., Kulikov, V ., Bitterman, Y ., Melumian, Z., and Bibi, O. Ltx- video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
-
[10]
He, X., Lin, K., Zhou, Y ., Zhong, J., Ye, W., Yi, W., Fan, B., Ding, F., Li, H., Cao, B., et al. Mpf-net: Exposing high-fidelity ai-generated video forgeries via hierarchi- cal manifold deviation and micro-temporal fluctuations. arXiv preprint arXiv:2601.21408,
-
[11]
Ivy- fake: A unified explainable framework and benchmark for image and video aigc detection, 2025a
Jiang, C., Dong, W., Zhang, Z., Si, C., Yu, F., Peng, W., Yuan, X., Bi, Y ., Zhao, M., Zhou, Z., and Shan, C. Ivy- fake: A unified explainable framework and benchmark for image and video aigc detection, 2025a. URL https: //arxiv.org/abs/2506.00979. Jiang, Z., Han, Z., Mao, C., Zhang, J., Pan, Y ., and Liu, Y . Vace: All-in-one video creation and editing. ...
-
[12]
Sam3-i: Segment anything with instructions.arXiv preprint arXiv:2512.04585, 2025a
Li, J., Feng, Y ., Guo, Y ., Huang, J., Ji, W., Bi, Q., Piao, Y ., Zhang, M., Zhao, X., Chen, Q., et al. Sam3-i: Segment anything with instructions.arXiv preprint arXiv:2512.04585, 2025a. Li, Y ., Yang, C., Zeng, H., Dong, Z., An, Z., Xu, Y ., Tian, Y ., and Wu, H. Frequency-aligned knowledge distillation for lightweight spatiotemporal forecasting. InProc...
-
[13]
Rareact: A video dataset of unusual interactions
Miech, A., Alayrac, J.-B., Laptev, I., Sivic, J., and Zisser- man, A. Rareact: A video dataset of unusual interactions. arxiv:2008.01018,
arXiv 2008
-
[15]
Ren, S., Yao, L., Li, S., Sun, X., and Hou, L
URL https:// arxiv.org/abs/2408.00714. Ren, S., Yao, L., Li, S., Sun, X., and Hou, L. Timechat: A time-sensitive multimodal large language model for long video understanding.ArXiv, abs/2312.02051,
-
[16]
doi: 10.1109/CVPR.2015. 7299154. Team, K., Chen, J., Ci, Y ., Du, X., Feng, Z., Gai, K., Guo, S., Han, F., He, J., He, K., Hu, X., Hu, X., Jiang, B., Kong, F., Li, H., Li, J., Li, Q., Li, S., Li, X., Li, Y ., Liang, J., Liao, B., Liao, Y ., Lin, W., Liu, Q., Liu, X., Liu, Y ., Liu, Y ., Lu, S., Mao, H., Mao, Y ., Ouyang, H., Qin, W., Shi, W., Shi, X., Su,...
-
[17]
URL https://arxiv.org/abs/2512.16776. 11 Explainable Forensics of Manipulated Segments in Untrimmed Long Videos Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.-W., Chen, D., Yu, F., Zhao, H., Yang, J., Zeng, J., Wang, J., Zhang, J., Zhou, J., Wang, J., Chen, J., Zhu, K., Zhao, K., Yan, K., Huang, L., Feng, M., Zhang, N., Li, P., Wu, P., Chu, R., Feng...
-
[18]
Wen, H., He, Y ., Huang, Z., Li, T., Yu, Z., Huang, X., Qi, L., Wu, B., Li, X., and Cheng, G. Busterx: Mllm-powered ai- generated video forgery detection and explanation.arXiv preprint arXiv:2505.12620,
-
[19]
Wu, J., Wang, Z., Hong, M., Ji, W., Fu, H., Xu, Y ., Xu, M., and Jin, Y
URL https: //arxiv.org/abs/2507.14632. Wu, J., Wang, Z., Hong, M., Ji, W., Fu, H., Xu, Y ., Xu, M., and Jin, Y . Medical sam adapter: Adapting segment anything model for medical image segmentation.Medical Image Analysis, 102:103547,
-
[20]
Xu, Z., Zhang, X., Li, R., Tang, Z., Huang, Q., and Zhang, J. Fakeshield: Explainable image forgery detection and localization via multi-modal large language models. In International Conference on Learning Representations, 2025c. Xu, Z., Zhang, X., Zhou, X., and Zhang, J. Avatarshield: Visual reinforcement learning for human-centric video forgery detectio...
-
[21]
D3: Training-free ai- generated video detection using second-order features
Zheng, C., Lin, C., Zhao, Z., Yang, L., Liu, S., Yang, M., Wang, C., Shen, C., et al. D3: Training-free ai- generated video detection using second-order features. arXiv preprint arXiv:2508.00701,
-
[22]
12 Explainable Forensics of Manipulated Segments in Untrimmed Long Videos A
URLhttps://arxiv.org/abs/1703.09788. 12 Explainable Forensics of Manipulated Segments in Untrimmed Long Videos A. TASLE Dataset This section provides detailed information on the compo- sition and characteristics of the TASLE dataset. As men- tioned in the main text, TASLE is specifically designed for the task of localizing and explaining sparse AI-generat...
-
[23]
The video durations range from 2 seconds to 124 seconds, encompassing various real-world scenarios such as first-person, third-person perspectives, and indoor/outdoor settings
These video sources include cooking tutorials (Youcook2 (Zhou et al., 2017)), fine-grained human actions (FineAction (Liu et al., 2022)), desktop activities (GTEA (Fathi et al., 2011)), kitchen oper- ations (EK100 (Damen et al., 2022)), industrial scenarios (ENIGMA-51 (Ragusa et al., 2024)), animal behavior (Mam- mAlps (Gabeff et al., 2025)), rare actions...
2017
-
[24]
hand motion
to obtain object masks (Li et al., 2025a; Ji et al., 2023; 2024a;b; Zhao et al., 2024; Wu et al., 2025), filtering out objects that are too small or persist for excessively long durations. The selected targets are then replaced or removed using a mask-conditioned video-to-video generation tool (e.g., V ACE), producing fine-grained object-level manipula- t...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.