FrequencyBooster: Full-Frequency Modeling for High-Fidelity Pixel Diffusion
Pith reviewed 2026-05-20 12:40 UTC · model grok-4.3
The pith
FrequencyBooster adds a high-capacity decoder to a DiT backbone so pixel diffusion models can recover full-frequency details and reach new FID lows.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FrequencyBooster is a framework that equips pixel diffusion with full-frequency modeling through a high-capacity decoder. The decoder extracts exhaustive high-frequency details and low-frequency semantics from high-dimensional feature representations provided by a Diffusion Transformer backbone. This design preserves global structural integrity while delivering superior pixel-level precision, evidenced by an FID of 1.60 at 256×256 resolution in 320 epochs and an FID of 1.69 at 512×512 resolution.
What carries the argument
High-capacity decoder that extracts exhaustive high-frequency details from high-dimensional features while receiving low-frequency semantics from the DiT backbone to keep global context intact.
If this is right
- Pixel diffusion reaches an FID of 1.60 at 256×256 resolution after only 320 epochs.
- At 512×512 resolution the model records an FID of 1.69 and outperforms both existing pixel-space and latent-space generative models.
- The method sidesteps the spectral compromise that previously forced a trade-off between efficiency and fine detail.
- High-dimensional features allow global structure and local pixel precision to be maintained simultaneously.
Where Pith is reading between the lines
- The same decoder pattern could be attached to other diffusion backbones to test whether full-frequency gains are architecture-specific.
- If the overhead remains low, the approach might support direct pixel modeling at resolutions beyond 512 without first moving to a latent space.
- Downstream tasks that rely on sharp textures, such as texture synthesis or detail-preserving editing, may see direct quality lifts from the recovered frequency content.
Load-bearing premise
The high-capacity decoder can extract exhaustive high-frequency details from high-dimensional features while maintaining global structural integrity supplied by the DiT backbone, without introducing prohibitive computational overhead or optimization misalignment.
What would settle it
Training FrequencyBooster for 320 epochs on ImageNet and finding that the generated images exhibit the same high-frequency suppression visible in earlier pixel diffusion baselines, or that the reported FID scores are not reached.
Figures



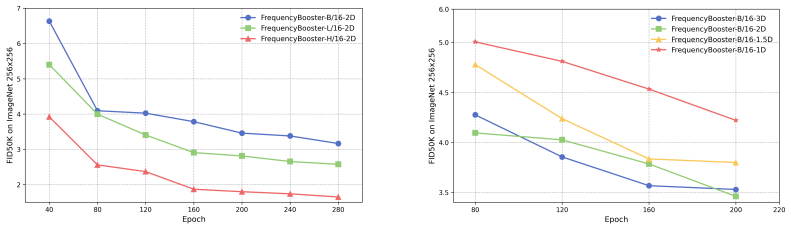





read the original abstract
To circumvent the inherent fidelity bottlenecks and optimization misalignment of VAE-based latent diffusion, pixel-space diffusion models have emerged as a compelling end-to-end paradigm. However, existing pixel diffusion models often struggle to balance computational efficiency with the preservation of high-frequency details. They frequently resort to patch-based compression or restricted local decoding, leading to a "spectral compromise" where high-frequency and fine-grained pixel information are suppressed. To address these challenges, we propose \textbf{FrequencyBooster}, a novel framework designed to empower pixel diffusion with full-frequency modeling capabilities without prohibitive overhead. The core of our method is a high-capacity decoder that specializes in extracting exhaustive high-frequency details and low-frequency semantics, the latter of which is derived from a Diffusion Transformer (DiT) backbone. Unlike prior works that sacrifice global context for local refinement, FrequencyBooster leverages high-dimensional feature representations to maintain global structural integrity while achieving superior pixel-level precision. Extensive experiments on ImageNet demonstrate the effectiveness of our approach: our model achieves a state-of-the-art FID of \textbf{1.60} at $256 \times 256$ resolution within only 320 epochs. Furthermore, at $512 \times 512$ resolution, FrequencyBooster attains an FID of \textbf{1.69}, significantly outperforming existing pixel-space and latent-space generative models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces FrequencyBooster, a pixel-space diffusion framework that pairs a Diffusion Transformer (DiT) backbone with a high-capacity decoder to enable full-frequency modeling. The approach seeks to resolve the 'spectral compromise' of prior pixel diffusion models by extracting exhaustive high-frequency details and low-frequency semantics from high-dimensional DiT features while preserving global structure. On ImageNet, the authors report state-of-the-art FID scores of 1.60 at 256×256 resolution after only 320 epochs and 1.69 at 512×512 resolution, outperforming existing pixel-space and latent-space generative models.
Significance. If the performance gains can be rigorously attributed to the full-frequency mechanism rather than increased capacity or training schedule, the work would meaningfully advance end-to-end pixel diffusion by demonstrating that high-dimensional DiT features can be decoded to recover fine-grained details without prohibitive overhead or loss of global coherence. The reported FID numbers, if reproducible under controlled conditions, would set a new empirical bar for high-resolution image synthesis.
major comments (2)
- [Abstract] Abstract: The central claim that the high-capacity decoder extracts exhaustive high-frequency details from DiT features is presented without any spectral diagnostics (radial power spectra, high-frequency energy ratios) or targeted ablations that isolate the decoder's frequency-specific pathways from overall model scale.
- [Experiments] Experiments section: The reported FID of 1.60 at 256×256 after 320 epochs and 1.69 at 512×512 lacks direct comparisons against baselines trained for identical epochs and parameter budgets, as well as error bars or multiple-run statistics, making it impossible to confirm that gains arise from the claimed full-frequency modeling rather than capacity or optimization differences.
minor comments (2)
- The phrase 'spectral compromise' is used without a precise definition or citation to prior literature employing equivalent terminology.
- Figure captions and method diagrams would benefit from explicit labeling of the frequency pathways within the decoder to improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and describe the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the high-capacity decoder extracts exhaustive high-frequency details from DiT features is presented without any spectral diagnostics (radial power spectra, high-frequency energy ratios) or targeted ablations that isolate the decoder's frequency-specific pathways from overall model scale.
Authors: We agree that the abstract would benefit from stronger support for the frequency-modeling claim. The main text already contains frequency analysis in Section 4, but we will add radial power spectra, high-frequency energy ratios, and a dedicated ablation that compares the specialized decoder against a capacity-matched baseline decoder. These additions will be referenced concisely in the revised abstract. revision: yes
-
Referee: [Experiments] Experiments section: The reported FID of 1.60 at 256×256 after 320 epochs and 1.69 at 512×512 lacks direct comparisons against baselines trained for identical epochs and parameter budgets, as well as error bars or multiple-run statistics, making it impossible to confirm that gains arise from the claimed full-frequency modeling rather than capacity or optimization differences.
Authors: We acknowledge that matched training budgets and statistical reporting would make the attribution clearer. In the revision we will add side-by-side comparisons to published baselines that share similar epoch counts and parameter scales. We will also report standard deviation across multiple inference seeds and explicitly note that full retraining of all baselines under identical schedules was not feasible due to compute limits. revision: partial
Circularity Check
No circularity: empirical architecture and FID results are independent of inputs
full rationale
The paper describes an empirical architecture (high-capacity decoder on DiT backbone for full-frequency pixel diffusion) and reports training outcomes (FID 1.60 at 256×256 after 320 epochs; FID 1.69 at 512×512). No equations, fitted parameters, predictions, or first-principles derivations appear in the provided text. The central claims rest on experimental results rather than any self-definitional reduction, fitted-input-as-prediction, or self-citation chain that would make the reported metrics equivalent to the model description by construction. The work is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
high-capacity decoder that specializes in extracting exhaustive high-frequency details and low-frequency semantics... FB-Decoder (L×nD) ... simply increasing the feature dimension of FB-Decoder
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
spectral compromise where high-frequency and fine-grained pixel information are suppressed
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2504.07963 (2025)
Shoufa Chen, Chongjian Ge, Shilong Zhang, Peize Sun, and Ping Luo. PixelFlow: Pixel-space generative models with flow.arXiv preprint arXiv:2504.07963, 2025
-
[2]
arXiv preprint arXiv:2511.18822 (2025)
Zhennan Chen, Junwei Zhu, Xu Chen, Jiangning Zhang, Xiaobin Hu, Hanzhen Zhao, Chengjie Wang, Jian Yang, and Ying Tai. DiP: Taming diffusion models in pixel space.arXiv preprint arXiv:2511.18822, 2025
-
[3]
Diffusion models beat gans on image synthesis
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. In Advances in Neural Information Processing Systems (NeurIPS), volume 34, pages 8780–8794, 2021
work page 2021
-
[4]
Classifier-Free Diffusion Guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance.arXiv preprint arXiv:2207.12598, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[5]
Fleet, Mohammad Norouzi, and Tim Salimans
Jonathan Ho, Chitwan Saharia, William Chan, David J. Fleet, Mohammad Norouzi, and Tim Salimans. Cascaded diffusion models for high fidelity image generation.JMLR, 2022
work page 2022
-
[6]
Simple diffusion: End-to-end diffusion for high resolution images
Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. Simple diffusion: End-to-end diffusion for high resolution images. InInternational Conference on Machine Learning (ICML), pages 13213–13232, 2023
work page 2023
-
[7]
Simpler diffusion: 1.5 fid on imagenet-512 with pixel-space diffusion
Emiel Hoogeboom, Thomas Mensink, Jonathan Heek, Kay Lamerigts, Ruiqi Gao, and Tim Salimans. Simpler diffusion: 1.5 fid on imagenet-512 with pixel-space diffusion. InCVPR, 2025
work page 2025
-
[8]
Scalable adaptive computation for iterative generation
Allan Jabri, David Fleet, and Ting Chen. Scalable adaptive computation for iterative generation. arXiv preprint arXiv:2212.11972, 2022
-
[9]
Understanding diffusion objectives as the elbo with simple data augmentation
Diederik Kingma and Ruiqi Gao. Understanding diffusion objectives as the elbo with simple data augmentation. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 65484–65516, 2023
work page 2023
-
[10]
Jiachen Lei, Keli Liu, Julius Berner, Steven C. H. Hoi, Hongkai Zheng, Jiahong Wu, and Xiangxiang Chu. Advancing end-to-end pixel-space generative modeling via self-supervised pre-training. InICLR, 2025
work page 2025
-
[11]
REPA-E: Unlocking vae for end-to-end tuning of latent diffusion transformers
Xingjian Leng, Jaskirat Singh, Yunzhong Hou, Zhenchang Xing, Saining Xie, and Liang Zheng. REPA-E: Unlocking vae for end-to-end tuning of latent diffusion transformers. InICCV, 2025
work page 2025
-
[12]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise.arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Tianhong Li, Qinyi Sun, Lijie Fan, and Kaiming He. Fractal generative models.arXiv preprint arXiv:2502.17437, 2025
-
[14]
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers.arXiv preprint arXiv:2401.08740, 2024
-
[15]
DeCo: Frequency-Decoupled Pixel Diffusion for End-to-End Image Generation
Zehong Ma, Longhui Wei, Shuai Wang, Shiliang Zhang, and Qi Tian. DeCo: Frequency- decoupled pixel diffusion for end-to-end image generation.arXiv preprint arXiv:2511.19365, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
PixelGen: Improving Pixel Diffusion with Perceptual Supervision
Zehong Ma, Ruihan Xu, and Shiliang Zhang. PixelGen: Pixel diffusion beats latent diffusion with perceptual loss.arXiv preprint arXiv:2602.02493, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195–4205, 2023. 10
work page 2023
-
[19]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022
work page 2022
-
[20]
Imagenet large scale visual recognition challenge.IJCV, 2015
Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Li Fei-Fei, et al. Imagenet large scale visual recognition challenge.IJCV, 2015
work page 2015
-
[21]
StyleGAN-XL: Scaling stylegan to large diverse datasets
Axel Sauer, Katja Schwarz, and Andreas Geiger. StyleGAN-XL: Scaling stylegan to large diverse datasets. InACM SIGGRAPH, 2022
work page 2022
-
[22]
Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan, Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and Jiwen Lu. Latent diffusion model without variational autoencoder.arXiv preprint arXiv:2510.15301, 2025
-
[23]
Chenyang Si, Weihao Yu, Pan Zhou, Yichen Zhou, Xinchao Wang, and Shuicheng Yan. Incep- tion transformer. InNeurIPS, 2022
work page 2022
-
[24]
Relay diffusion: Unifying diffusion process across resolutions for image syn- thesis
Jiayan Teng, Wendi Zheng, Ming Ding, Wenyi Hong, Jianqiao Wangni, Zhuoyi Yang, and Jie Tang. Relay diffusion: Unifying diffusion process across resolutions for image synthesis.arXiv preprint arXiv:2309.03350, 2023
-
[25]
Yuchuan Tian, Zhijun Tu, Hanting Chen, Jie Hu, Chao Xu, and Yunhe Wang. U-DiTs: Down- sample tokens in u-shaped diffusion transformers.Advances in Neural Information Processing Systems, 37:51994–52013, 2024
work page 2024
-
[26]
Michael Tschannen, André Susano Pinto, and Alexander Kolesnikov. JetFormer: An autore- gressive generative model of raw images and text.arXiv preprint arXiv:2411.19722, 2024
-
[27]
Pixnerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268, 2025
Shuai Wang, Ziteng Gao, Chenhui Zhu, Weilin Huang, and Limin Wang. PixNerd: Pixel neural field diffusion.arXiv preprint arXiv:2507.23268, 2025
-
[28]
Ddt: Decoupled diffusion transformer.arXiv preprint arXiv:2504.05741, 2025
Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang. DDT: Decoupled diffusion transformer. arXiv preprint arXiv:2504.05741, 2025
-
[29]
Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstruction vs. generation: Taming optimiza- tion dilemma in latent diffusion models. InCVPR, 2025
work page 2025
-
[30]
Representation alignment for generation: Training diffusion transformers is easier than you think
Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think. InICLR, 2025
work page 2025
-
[31]
PixelDiT: Pixel Diffusion Transformers for Image Generation
Yongsheng Yu, Wei Xiong, Weili Nie, Yichen Sheng, Shiqiu Liu, and Jiebo Luo. PixelDiT: Pixel diffusion transformers for image generation.arXiv preprint arXiv:2511.20645, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Diffusion Transformers with Representation Autoencoders
Boyang Zheng, Nanye Ma, Shengbang Tong, and Saining Xie. Diffusion transformers with representation autoencoders.arXiv preprint arXiv:2510.11690, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
FARMER: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588, 2025
Guangting Zheng, Qinyu Zhao, Tao Yang, Fei Xiao, Zhijie Lin, Jie Wu, Jiajun Deng, Yanyong Zhang, and Rui Zhu. FARMER: Flow autoregressive transformer over pixels.arXiv preprint arXiv:2510.23588, 2025
-
[34]
Hongkai Zheng, Weili Nie, Arash Vahdat, and Anima Anandkumar. Fast training of diffusion models with masked transformers.arXiv preprint arXiv:2306.09305, 2023. 11 A More Implementary Details We follow the official implementations of DiT and JiT[ 12]. Our settings are outlined in Table 5. Further details are provided as follows: A.0.1 Detailed Architecture...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.