S2Accompanist: A Semantic-Aware and Structure-Guided Diffusion Model for Music Accompaniment Generation
Pith reviewed 2026-05-19 22:46 UTC · model grok-4.3
The pith
A 402-million-parameter diffusion model generates coherent music accompaniments with localized semantic control by creating segment-level metadata and embedding musical structures in its latent space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
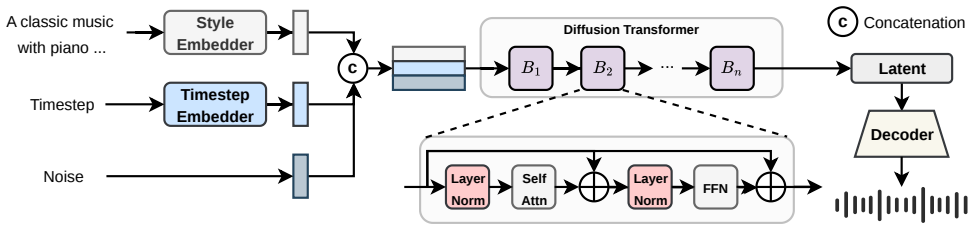
S2Accompanist is a semantic-aware and structure-guided diffusion model that overcomes coarse track-level annotations by running an automated pipeline of structural segmentation, large audio-language model captioning, and quality grading to obtain localized metadata, then fine-tunes a variational autoencoder to distill LeadSheet structures into the acoustic latent space, enabling high-fidelity accompaniment generation that reaches state-of-the-art objective performance on the ATTM Grand Challenge benchmark with only 402M parameters and first place in the Efficiency Track.
What carries the argument
semantic-aware Variational Autoencoder fine-tuning strategy that distills LeadSheet structures into the acoustic latent space, paired with the automated structural segmentation and captioning pipeline that supplies localized metadata
If this is right
- The generated accompaniments maintain structural coherence across segments while responding to localized semantic descriptions.
- Competitive or superior performance is possible against larger unconstrained models when parameter count is limited to 402M.
- Localized control over musical content becomes feasible without access to proprietary massive datasets.
- Audio fidelity improves measurably once foundational musical structures are explicitly injected into the latent space.
Where Pith is reading between the lines
- The same automated metadata pipeline could be applied to other music or audio generation tasks that currently suffer from only coarse annotations.
- Extending the structure-distillation step to full-song generation might improve long-range coherence without increasing model size.
- Prioritizing data quality and localization over sheer data volume offers a practical route to efficient models in resource-constrained settings.
Load-bearing premise
The automated pipeline of audio segmentation, large audio-language model captioning, and dual-metric quality grading produces localized metadata that is accurate enough to meaningfully improve model training over coarse track-level labels.
What would settle it
Independent re-evaluation on the ATTM Grand Challenge benchmark where the model fails to achieve the highest objective scores in the Efficiency Track or where ablating the VAE fine-tuning step produces no measurable drop in fidelity or coherence.
Figures

read the original abstract
High-fidelity text-to-music generation typically relies on massive proprietary datasets and immense computational resources. Existing models often struggle to generate coherent pure musical accompaniments and lack precise, localized semantic control due to their reliance on coarse, track-level annotations. To address these limitations under constrained data and computing resources, we propose S2Accompanist, a Semantic-Aware and Structure-Guided Diffusion Model developed for the ICME2026 ATTM Grand Challenge. Specifically, we design an automated data pipeline comprising structural segmentation, Large Audio-Language Model driven segment-level captioning, and dual-metric quality grading to overcome the absence of localized metadata in raw datasets. Furthermore, we propose a semantic-aware Variational Autoencoder fine-tuning strategy that explicitly distills foundational LeadSheet structures into the acoustic latent space, effectively improving the overall audio fidelity. Extensive experiments demonstrate that S2Accompanist achieves state-of-the-art objective performance on the ATTM Grand Challenge benchmark across both the Efficiency and Performance Tracks. With only 402M parameters, our model remains competitive compared to larger-scale unconstrained models and secured first place in the Efficiency Track.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents S2Accompanist, a semantic-aware and structure-guided diffusion model for music accompaniment generation. It introduces an automated data pipeline using structural segmentation, Large Audio-Language Model-driven segment-level captioning, and dual-metric quality grading to create localized metadata, combined with a semantic-aware Variational Autoencoder fine-tuning strategy to distill LeadSheet structures into the acoustic latent space. The work reports achieving state-of-the-art objective performance on the ATTM Grand Challenge benchmark across both Efficiency and Performance Tracks with a 402M-parameter model.
Significance. If the central performance claims hold under proper validation, the approach could demonstrate that localized semantic supervision and structure guidance enable competitive results in text-to-music tasks with modest model sizes and resources, addressing limitations of coarse track-level annotations in existing datasets.
major comments (2)
- [Experiments] Experiments section: the abstract and method description assert SOTA results from extensive experiments on the ATTM benchmark, yet no specific objective metrics, baseline comparisons, ablation tables, or error analysis are supplied to substantiate the claim or isolate the contribution of the proposed components.
- [Method] Method (automated data pipeline subsection): the central claim that the structural-segmentation + LALM-captioning + dual-metric grading pipeline supplies high-fidelity localized semantic supervision (enabling the semantic-aware VAE and diffusion conditioning) is load-bearing, but no quantitative validation such as caption-audio alignment scores, inter-annotator agreement, or an ablation removing segment captions is reported.
minor comments (1)
- [Abstract] Abstract: the phrase 'secured first place in the Efficiency Track' would benefit from an explicit reference to the corresponding table or figure in the results section.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address each major comment below, indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the abstract and method description assert SOTA results from extensive experiments on the ATTM benchmark, yet no specific objective metrics, baseline comparisons, ablation tables, or error analysis are supplied to substantiate the claim or isolate the contribution of the proposed components.
Authors: We acknowledge that the current presentation of results could be strengthened for clarity. While the manuscript reports state-of-the-art performance on the ATTM Grand Challenge benchmark in both tracks, we agree that explicit tables with objective metrics, baseline comparisons, ablation studies on the data pipeline and semantic-aware VAE components, and error analysis would better substantiate the claims and isolate contributions. We will add these elements in the revised manuscript. revision: yes
-
Referee: [Method] Method (automated data pipeline subsection): the central claim that the structural-segmentation + LALM-captioning + dual-metric grading pipeline supplies high-fidelity localized semantic supervision (enabling the semantic-aware VAE and diffusion conditioning) is load-bearing, but no quantitative validation such as caption-audio alignment scores, inter-annotator agreement, or an ablation removing segment captions is reported.
Authors: The referee is correct that the automated data pipeline is central to enabling localized supervision. We did not include caption-audio alignment scores or inter-annotator agreement because the pipeline is fully automated and our evaluation prioritized end-to-end benchmark performance over intermediate annotation quality metrics. However, we will add an ablation study removing segment captions to quantify their contribution to the final results. Additional metrics such as alignment scores would require new analysis and will be included on a partial basis if feasible within the revision timeline. revision: partial
Circularity Check
No significant circularity; claims rest on empirical benchmark results
full rationale
The paper introduces a proposed diffusion model architecture together with an automated data pipeline (structural segmentation, LALM captioning, dual-metric grading) and a semantic-aware VAE fine-tuning step. These are presented as methodological contributions whose effectiveness is assessed via objective metrics on the external ATTM Grand Challenge benchmark. No equations, derivations, or fitted-parameter predictions are described that reduce to their own inputs by construction. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work appear in the provided text. The SOTA claim is therefore an empirical outcome rather than a tautological restatement of the pipeline definition, rendering the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large Audio-Language Models can generate accurate segment-level captions for music audio that improve training data quality over track-level annotations.
- domain assumption Embedding foundational LeadSheet structures into the acoustic latent space via VAE fine-tuning improves overall audio fidelity in diffusion-based generation.
invented entities (1)
-
semantic-aware Variational Autoencoder
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
semantic-aware Variational Autoencoder fine-tuning strategy that explicitly distills foundational LeadSheet structures into the acoustic latent space
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
dual-metric quality grading ... top 20% of the highest-quality data
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Diffrhythm+: Controllable and flexible full-length song generation with preference optimization,
Huakang Chen, Yuepeng Jiang, Guobin Ma, Chunbo Hao, Shuai Wang, Jixun Yao, Ziqian Ning, Meng Meng, Jian Luan, and Lei Xie, “Diffrhythm+: Controllable and flexible full-length song generation with preference optimization,” inIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2025, Honolulu, HI, USA, December 6-10, 2025. 2025, pp. 1–8, IEEE
work page 2025
-
[2]
Ziqian Ning, Huakang Chen, Yuepeng Jiang, Chunbo Hao, Guobin Ma, Shuai Wang, Jixun Yao, and Lei Xie, “Diffrhythm: Blazingly fast and embarrassingly simple end-to-end full-length song generation with latent diffusion,”arXiv preprint arXiv:2503.01183, 2025
-
[3]
Junmin Gong, Sean Zhao, Sen Wang, Shengyuan Xu, and Joe Guo
Junmin Gong, Sean Zhao, Sen Wang, Shengyuan Xu, and Joe Guo, “Ace-step: A step towards music generation foundation model,”arXiv preprint arXiv:2506.00045, 2025
-
[4]
ACE-Step 1.5: Pushing the boundaries of open-source music generation,
Junmin Gong, Yulin Song, Wenxiao Zhao, Sen Wang, Shengyuan Xu, Jing Guo, and Xuerui Yang, “Ace-step 1.5: Pushing the boundaries of open-source music generation,”arXiv preprint arXiv:2602.00744, 2026
-
[5]
Noise2music: Text-conditioned music generation with diffusion models,
Qingqing Huang, Daniel S. Park, Tao Wang, Timo I. Denk, Andy Ly, Nanxin Chen, Zhengdong Zhang, Zhishuai Zhang, Jiahui Yu, Chris- tian Havnø Frank, Jesse H. Engel, Quoc V . Le, William Chan, and Wei Han, “Noise2music: Text-conditioned music generation with diffusion models,”CoRR, vol. abs/2302.03917, 2023
-
[6]
Moˆusai: Efficient text-to-music diffusion models,
Flavio Schneider, Ojasv Kamal, Zhijing Jin, and Bernhard Sch ¨olkopf, “Moˆusai: Efficient text-to-music diffusion models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, Andre Martins, and Vivek Srikumar, Eds. 2024, pp. 8050–806...
work page 2024
-
[7]
Musicflow: Cascaded flow matching for text guided music generation,
K. R. Prajwal, Bowen Shi, Matthew Le, Apoorv Vyas, Andros Tjandra, Mahi Luthra, Baishan Guo, Huiyu Wang, Triantafyllos Afouras, David Kant, and Wei-Ning Hsu, “Musicflow: Cascaded flow matching for text guided music generation,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Ruslan Salakhutdinov, Z...
work page 2024
-
[8]
Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies,
Ke Chen, Yusong Wu, Haohe Liu, Marianna Nezhurina, Taylor Berg- Kirkpatrick, and Shlomo Dubnov, “Musicldm: Enhancing novelty in text-to-music generation using beat-synchronous mixup strategies,” inIEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2024, Seoul, Republic of Korea, April 14-19, 2024. 2024, pp. 1206–1210, IEEE
work page 2024
-
[9]
Simple and controllable music generation,
Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi, and Alexandre D´efossez, “Simple and controllable music generation,” inAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023, Alice Oh, Tristan Na...
work page 2023
-
[10]
MusicLM: Generating Music From Text
Andrea Agostinelli, Timo I. Denk, Zal ´an Borsos, Jesse H. Engel, Mauro Verzetti, Antoine Caillon, Qingqing Huang, Aren Jansen, Adam Roberts, Marco Tagliasacchi, Matthew Sharifi, Neil Zeghidour, and Christian Havnø Frank, “Musiclm: Generating music from text,”CoRR, vol. abs/2301.11325, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Yue: Scaling open foundation models for long-form music generation.arXiv:2503.08638,
Ruibin Yuan, Hanfeng Lin, Shuyue Guo, Ge Zhang, Jiahao Pan, Yongyi Zang, Haohe Liu, Yiming Liang, Wenye Ma, Xingjian Du, Xinrun Du, Zhen Ye, Tianyu Zheng, Yinghao Ma, Minghao Liu, Zeyue Tian, Ziya Zhou, Liumeng Xue, Xingwei Qu, Yizhi Li, Shangda Wu, Tianhao Shen, Ziyang Ma, Jun Zhan, Chunhui Wang, Yatian Wang, Xiaowei Chi, Xinyue Zhang, Zhenzhu Yang, Xian...
-
[12]
Chong Zhang, Yukun Ma, Qian Chen, Wen Wang, Shengkui Zhao, Zexu Pan, Hao Wang, Chongjia Ni, Trung Hieu Nguyen, Kun Zhou, Yidi Jiang, Chaohong Tan, Zhifu Gao, Zhihao Du, and Bin Ma, “Inspiremusic: Integrating super resolution and large language model for high-fidelity long-form music generation,”CoRR, vol. abs/2503.00084, 2025
-
[13]
Academic text-to-music grand chal- lenge: Datasets, baselines, and evaluation methods,
Fang-Chih Hsieh, Wei-Jaw Lee, Chun-Ping Wang, Hung-yi Lee, Hao- Wen Dong, and Yi-Hsuan Yang, “Academic text-to-music grand chal- lenge: Datasets, baselines, and evaluation methods,” inInternational Conference on Multimedia and Expo, Grand Challenge Paper, 2026
work page 2026
-
[14]
The mtg-jamendo dataset for automatic music tagging,
Dmitry Bogdanov, Minz Won, Philip Tovstogan, Alastair Porter, and Xavier Serra, “The mtg-jamendo dataset for automatic music tagging,” inMachine learning for music discovery workshop, international con- ference on machine learning (ICML 2019). Long Beach, CA, United States, 2019, pp. 1–3
work page 2019
-
[15]
Alexandre D ´efossez, Nicolas Usunier, L´eon Bottou, and Francis R. Bach, “Demucs: Deep extractor for music sources with extra unlabeled data remixed,”CoRR, vol. abs/1909.01174, 2019
-
[16]
SongFormer: Scaling Music Structure Analysis with Heterogeneous Supervision
Chunbo Hao, Ruibin Yuan, Jixun Yao, Qixin Deng, Xinyi Bai, Wei Xue, and Lei Xie, “Songformer: Scaling music structure analysis with heterogeneous supervision,”arXiv preprint arXiv:2510.02797, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, “Gemini: A family of highly capable multimodal models,” CoRR, vol. abs/2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
Meta audiobox aes- thetics: Unified automatic assessment for speech, music and sound,
Andros Tjandra, Yi-Chiao Wu, Baishan Guo, John Hoffman, Brian Ellis, Apoorv Vyas, Bowen Shi, Sanyuan Chen, Matt Le, Nick Zacharov, Carleigh Wood, Ann Lee, and Wei-Ning Hsu, “Meta audiobox aes- thetics: Unified automatic assessment for speech, music and sound,” inIEEE Automatic Speech Recognition and Understanding Workshop, ASRU 2025, Honolulu, HI, USA, De...
work page 2025
-
[19]
Haina Zhu, Yizhi Zhou, Hangting Chen, Jianwei Yu, Ziyang Ma, Rongzhi Gu, Yi Luo, Wei Tan, and Xie Chen, “Muq: Self-supervised music representation learning with mel residual vector quantization,” CoRR, vol. abs/2501.01108, 2025
-
[20]
Fast timing-conditioned latent audio diffusion,
Zach Evans, CJ Carr, Josiah Taylor, Scott H. Hawley, and Jordi Pons, “Fast timing-conditioned latent audio diffusion,” inForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, Ruslan Salakhutdinov, Zico Kolter, Kather- ine A. Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, Eds....
work page 2024
-
[21]
Diffrhythm 2: Efficient and high fidelity song generation via block flow matching,
Yuepeng Jiang, Huakang Chen, Ziqian Ning, Jixun Yao, Zerui Han, Di Wu, Meng Meng, Jian Luan, Zhonghua Fu, and Lei Xie, “Diffrhythm 2: Efficient and high fidelity song generation via block flow matching,” arXiv preprint arXiv:2510.22950, 2025
-
[22]
Semantic-vae: Semantic-alignment latent representation for better speech synthesis,
Zhikang Niu, Shujie Hu, Jeongsoo Choi, Yushen Chen, Peining Chen, Pengcheng Zhu, Yunting Yang, Bowen Zhang, Jian Zhao, Chunhui Wang, et al., “Semantic-vae: Semantic-alignment latent representation for better speech synthesis,”arXiv preprint arXiv:2509.22167, 2025
-
[23]
Melody transcription via generative pre-training,
Chris Donahue, John Thickstun, and Percy Liang, “Melody transcription via generative pre-training,”arXiv preprint arXiv:2212.01884, 2022
-
[24]
Zach Evans, Julian D. Parker, CJ Carr, Zack Zukowski, Josiah Taylor, and Jordi Pons, “Stable audio open,” in2025 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2025, Hyderabad, India, April 6-11, 2025. 2025, pp. 1–5, IEEE
work page 2025
-
[25]
CLAP learning audio concepts from natural language supervision,
Benjamin Elizalde, Soham Deshmukh, Mahmoud Al Ismail, and Huam- ing Wang, “CLAP learning audio concepts from natural language supervision,” inIEEE International Conference on Acoustics, Speech and Signal Processing ICASSP 2023, Rhodes Island, Greece, June 4- 10, 2023. 2023, pp. 1–5, IEEE
work page 2023
-
[26]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al., “Qwen3-omni technical report,”arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.