Multi-modal Video Representation Alignment for Robust Self-supervised Driver Distraction Detection
Pith reviewed 2026-06-28 14:58 UTC · model grok-4.3
The pith
A global multi-modal alignment method improves self-supervised video representations by relaxing hard negatives and weighting unreliable positives with cycle-consistency and similarity scores.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
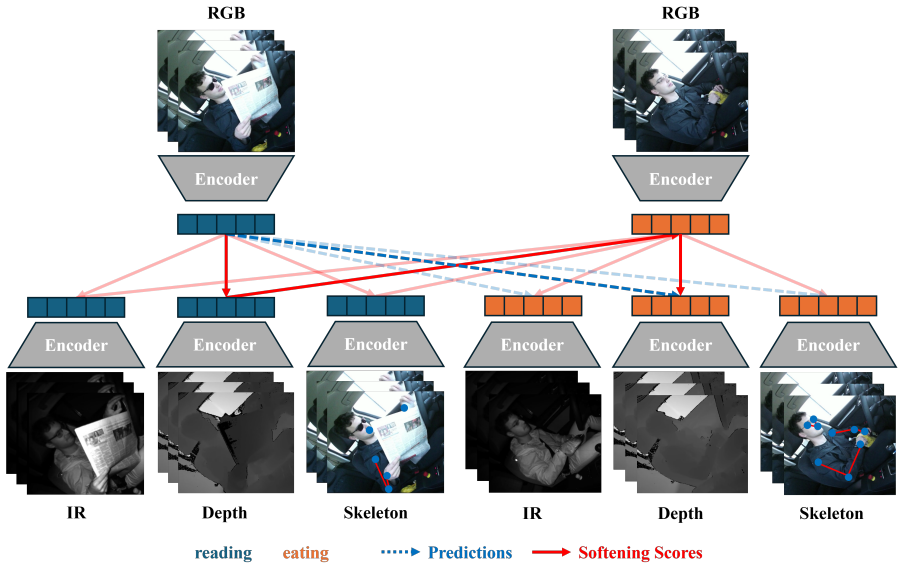
The central claim is that jointly modeling faulty negatives and unreliable positives through a global multi-modal alignment objective—aggregating alignment information across all modality pairs, deriving soft targets from cycle-consistency scores, and applying similarity-distribution weights—produces more robust video representations than pairwise or existing global methods, as shown by consistent gains across RGB, IR, Depth, and Skeleton modalities on the Drive&Act dataset together with strong cross-view generalization.
What carries the argument
The multi-modal global alignment framework that aggregates pairwise alignment information across all modality combinations while using cycle-consistency scores for soft targets and similarity distributions for positive weighting.
If this is right
- The approach outperforms pairwise alignment and existing global baselines on the Drive&Act dataset for RGB, IR, Depth, and Skeleton modalities.
- Representations learned this way generalize to camera perspectives not present during training.
- The framework scales to self-supervised global multi-modal representation learning without requiring paired labels.
- It supports reliable driver distraction detection from complementary but noisy sensor streams.
Where Pith is reading between the lines
- The same cycle-consistency and distribution-weighting steps could be tested on other multi-modal video tasks such as action recognition or activity monitoring.
- If the soft-target mechanism works, it may reduce sensitivity to label noise in any contrastive setting that mixes multiple data streams.
- Extending the global aggregation beyond four modalities would be a direct next measurement of whether the pairwise aggregation principle continues to hold.
Load-bearing premise
Cycle-consistency scores can be turned into reliable soft targets and similarity distributions can down-weight faulty positives even when multi-modal video data contains viewpoint changes, occlusions, and semantic overlap.
What would settle it
A direct comparison on the Drive&Act dataset in which the proposed global method fails to outperform both pairwise contrastive baselines and prior global alignment methods across the four modalities or shows no advantage in cross-view tests.
Figures

read the original abstract
Robust self-supervised learning of multi-modal video representations is critical for real-world applications such as driver distraction detection, where multiple sensors provide complementary but noisy signals. Conventional contrastive objectives, such as InfoNCE, assume all negatives are equally informative and all positives are reliable. However, this assumption is frequently violated in multi-modal data due to viewpoint changes, occlusions, or semantic overlap across modalities. In this work, we propose a novel framework for multi-modal global alignment that addresses these challenges by jointly modeling faulty negatives and unreliable or faulty positives. We introduce soft targets derived from cycle-consistency scores to relax the hard-negative assumption, and a weighting mechanism based on similarity distributions to mitigate the impact of noisy or faulty positives. Our approach extends traditional pairwise alignment to a principled global multi-modal setting, aggregating alignment information across all modality pairs. We evaluate our method on the Drive&Act dataset, demonstrating that it consistently outperforms both pairwise and existing global alignment baselines across RGB, IR, Depth, and Skeleton modalities. Cross-view ablation studies further show strong generalization to unseen camera perspectives, highlighting the robustness of our representations. Overall, our framework provides a scalable and effective solution for self-supervised global multi-modal representation learning, enabling reliable driver distraction detection and pioneering in real-world multi-modal video understanding. Our code will be published on GitHub.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a self-supervised multi-modal global alignment framework for video representations in driver distraction detection. It extends contrastive objectives by deriving soft targets from cycle-consistency scores to relax the hard-negative assumption and by applying similarity-distribution weighting to down-weight faulty positives. The method aggregates information across all modality pairs rather than relying on pairwise alignment and is evaluated on the Drive&Act dataset, claiming consistent gains over pairwise and existing global baselines on RGB, IR, Depth, and Skeleton modalities together with strong cross-view generalization.
Significance. If the empirical claims hold under rigorous controls, the work offers a practical extension of contrastive learning that directly targets noise sources common in real-world multi-modal video (viewpoint change, occlusion, semantic overlap). The global aggregation and explicit handling of unreliable positives/negatives address load-bearing assumptions in standard InfoNCE-style losses. The multi-modality evaluation and cross-view ablations provide falsifiable evidence; the planned code release supports reproducibility.
minor comments (2)
- [Abstract] Abstract: the statement that the method 'consistently outperforms' both pairwise and global baselines should be accompanied by at least one quantitative result (e.g., accuracy or mAP delta) to allow readers to gauge effect size without consulting the full experimental tables.
- [Method] The description of the similarity-distribution weighting mechanism would benefit from an explicit equation or pseudocode showing how the distribution is computed and normalized; the current high-level description leaves the precise functional form ambiguous.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on multi-modal global alignment for driver distraction detection and for recommending minor revision. We note that the report contains no specific major comments requiring point-by-point rebuttal.
Circularity Check
No significant circularity detected
full rationale
The provided abstract and context describe an empirical extension of contrastive learning with cycle-consistency soft targets and similarity-distribution weighting for multi-modal alignment. No derivation chain, equations, or first-principles results are shown that reduce by construction to fitted parameters, self-definitions, or self-citation load-bearing premises. The central claim is outperformance on the Drive&Act dataset across modalities, which is presented as a falsifiable experimental result rather than a mathematical identity. No patterns matching self-definitional, fitted-input-called-prediction, or ansatz-smuggled-in-via-citation are identifiable from the text. The method is self-contained against external benchmarks and does not rely on uniqueness theorems or renamed known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Road safety thematic report – distraction,
European Commission, Directorate-General for Transport, “Road safety thematic report – distraction,” Brussels, Belgium, Tech. Rep.,
-
[2]
[Online]. Available: https://road-safety.transport.ec.europa.eu/ document/download/5244113d-5209-4dd2-998c-1094f0876cd1 en? filename=ERSO-TR distraction 2026.pdf 1
arXiv 2026
-
[3]
(2023) Road traffic accidents
Statistics Austria. (2023) Road traffic accidents. Retrieved 24.02.2026. [Online]. Available: https://www.statistik.at/en/statistics/ tourism-and-transport/accidents/road-traffic-accidents 1
2023
-
[4]
Distracted driving in 2023,
National Highway Traffic Safety Administration, “Distracted driving in 2023,” Apr. 2025. 1
2023
-
[5]
Driver crash risk factors and prevalence evaluation using naturalistic driving data,
T. A. Dingus, F. Guo, S. Lee, J. F. Antin, M. Perez, M. Buchanan-King, and J. Hankey, “Driver crash risk factors and prevalence evaluation using naturalistic driving data,”Proceedings of the National Academy of Sciences, 2016. 1
2016
-
[6]
A multimodal framework for fatigue driving detection via feature fusion of vision and tactile information,
K. Li, W. Yue, D. B. Shinet al., “A multimodal framework for fatigue driving detection via feature fusion of vision and tactile information,” npj Flex Electron, 2026. 1
2026
-
[7]
Focal loss for dense object detection,
T.-Y . Lin, P. Goyal, R. Girshick, K. He, and P. Doll ´ar, “Focal loss for dense object detection,” inProceedings of the IEEE International Conference on Computer Vision (ICCV), 2017. 2
2017
-
[8]
Robust audio-visual instance discrimination,
P. Morgado, I. Misra, and N. Vasconcelos, “Robust audio-visual instance discrimination,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 2, 3, 4, 5
2021
-
[9]
Decoupling representation and classifier for long-tailed recognition,
B. Kang, S. Xie, M. Rohrbach, Z. Yan, A. Gordo, J. Feng, and Y . Kalantidis, “Decoupling representation and classifier for long-tailed recognition,” inInternational Conference on Learning Representations (ICLR), 2020. 2
2020
-
[10]
Risky driver recognition with class imbalance data and automated machine learning framework,
K. Wang, Q. Xue, and J. J. Lu, “Risky driver recognition with class imbalance data and automated machine learning framework,” International Journal of Environmental Research and Public Health,
-
[11]
3d skeleton-based driver activity recognition using self- supervised learning,
D. J. Lerch, Y . El Bachiri, M. Martin, F. Diederichs, and R. Stiefel- hagen, “3d skeleton-based driver activity recognition using self- supervised learning,” in2024 IEEE 27th International Conference on Intelligent Transportation Systems (ITSC), 2024. 2
2024
-
[12]
Emerging properties in self-supervised vision trans- formers,
M. Caron, H. Touvron, I. Misra, H. J ´egou, J. Mairal, P. Bojanowski, and A. Joulin, “Emerging properties in self-supervised vision trans- formers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9650–9660. 2
2021
-
[13]
Learning transferable visual models from natural language supervi- sion,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervi- sion,” inProceedings of the 38th International Conference on Machine Learning (ICML), 2021. 2
2021
-
[14]
Drive and act: A multi-modal dataset for fine- grained driver behavior recognition in autonomous vehicles,
M. Martin, A. Roitberg, M. Haurilet, M. Horne, S. Reiß, M. V oit, and R. Stiefelhagen, “Drive and act: A multi-modal dataset for fine- grained driver behavior recognition in autonomous vehicles,” inThe IEEE International Conference on Computer Vision (ICCV), Oct 2019. 2, 5, 6
2019
-
[15]
State farm distracted driver detection,
A. Montoya, D. Holman, S. science, T. Smith, and W. Kan, “State farm distracted driver detection,” 2016, accessed: 2024-05-13. 2
2016
-
[16]
Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,
J. D. Ortega, N. Kose, P. Ca ˜nas, M.-A. Chao, A. Unnervik, M. Nieto, O. Otaegui, and L. Salgado, “Dmd: A large-scale multi-modal driver monitoring dataset for attention and alertness analysis,” inComputer Vision – ECCV 2020 Workshops, 2020, pp. 387–405. 2
2020
-
[17]
Learn- ing deep features for discriminative localization,
B. Zhou, A. Khosla, A. Lapedriza, A. Oliva, and A. Torralba, “Learn- ing deep features for discriminative localization,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016. 2
2016
-
[18]
Drive-net: Convolutional network for driver distraction detection,
M. S. Majdi, S. Ram, J. T. Gill, and J. J. Rodr ´ıguez, “Drive-net: Convolutional network for driver distraction detection,” in2018 IEEE Southwest Symposium on Image Analysis and Interpretation (SSIAI). IEEE, 2018. 2
2018
-
[19]
Rethink- ing the inception architecture for computer vision,
C. Szegedy, V . Vanhoucke, S. Ioffe, J. Shlens, and Z. Wojna, “Rethink- ing the inception architecture for computer vision,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2818–2826. 2
2016
-
[20]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inProceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 770–778. 2
2016
-
[21]
Distracted driver detection using stacking ensemble,
K. R. Dhakate and R. Dash, “Distracted driver detection using stacking ensemble,” in2020 IEEE International Students’ Conference on Elec- trical, Electronics and Computer Science (SCEECS). IEEE, 2020. 2
2020
-
[22]
A novel driver distraction behavior detection method based on self-supervised learning with masked image modeling,
Y . Zhang, T. Li, C. Li, and X. Zhou, “A novel driver distraction behavior detection method based on self-supervised learning with masked image modeling,”IEEE Internet of Things Journal, 2023. 2
2023
-
[23]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10 012–10 022. 2
2021
-
[24]
Driver distraction detection using octave-like convolutional neural network,
P. Li, Y . Yang, R. Grosu, G. Wang, R. Li, Y . Wu, and Z. Huang, “Driver distraction detection using octave-like convolutional neural network,” IEEE transactions on intelligent transportation systems, 2021. 2
2021
-
[25]
Modality mixer for multi-modal action recognition,
S. Lee, S. Woo, Y . Park, M. Adi Nugroho, and C. Kim, “Modality mixer for multi-modal action recognition,” in2023 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2023. 2
2023
-
[26]
Evaluating driver readiness in conditionally automated vehicles from eye-tracking data and head pose,
M. Kazemi, M. Rezaei, and M. Azarmi, “Evaluating driver readiness in conditionally automated vehicles from eye-tracking data and head pose,”IET Intelligent Transport Systems, vol. 19, no. 1, p. e70006,
-
[27]
Driver-net: Multi-camera fusion for assessing driver take-over readiness in automated vehicles,
M. Rezaei and M. Azarmi, “Driver-net: Multi-camera fusion for assessing driver take-over readiness in automated vehicles,” in2025 IEEE Intelligent Vehicles Symposium (IV). IEEE, 2025, pp. 1841–
2025
-
[28]
Imagebind: One embedding space to bind them all,
R. Girdhar, M. Singh, N. Ravi, L. van der Maaten, A. El-Nouby, and I. Misra, “Imagebind: One embedding space to bind them all,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023. 2
2023
-
[29]
Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment,
B. Zhu, B. Lin, M. Ning, Y . Yan, J. Cui, W. HongFa, Y . Pang, W. Jiang, J. Zhang, Z. Li, C. Zhang, Z. Li, W. Liu, and Y . Li, “Languagebind: Extending video-language pretraining to n-modality by language-based semantic alignment,” inInternational Conference on Learning Representations, 2024. 2
2024
-
[30]
Learning robust aligned representations across multiple visual modalities in human action recognition,
D. J. Lerch, B. Rothenburger, Z. Zhong, M. Martin, F. Diederichs, and R. Stiefelhagen, “Learning robust aligned representations across multiple visual modalities in human action recognition,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops. IEEE, 2025. 2, 4, 5
2025
-
[31]
Part-aware unified repre- sentation of language and skeleton for zero-shot action recognition,
A. Zhu, Q. Ke, M. Gong, and J. Bailey, “Part-aware unified repre- sentation of language and skeleton for zero-shot action recognition,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 761–18 770. 2
2024
-
[32]
Representation learning with contrastive predictive coding,
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,”ArXiv, vol. abs/1807.03748, 2018. 2, 5
Pith/arXiv arXiv 2018
-
[33]
Self-supervised driver distraction detection for imbalanced datasets,
S. Bhardwaj, D. J. Lerch, M. Martin, F. Diederichs, and R. Stiefel- hagen, “Self-supervised driver distraction detection for imbalanced datasets,” inProceedings of the IEEE 28th ITSC, 2025. 3
2025
-
[34]
Boosting contrastive self-supervised learning with false negative cancellation,
T. Huynh, S. Kornblith, M. R. Walter, M. Maire, and M. Khademi, “Boosting contrastive self-supervised learning with false negative cancellation,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022. 3
2022
-
[35]
Incremental false negative detection for contrastive learning,
T.-S. Chen, W.-C. Hung, H.-Y . Tseng, S.-Y . Chien, and M.-H. Yang, “Incremental false negative detection for contrastive learning,” in Advances in Neural Information Processing Systems (NeurIPS), 2022. 3
2022
-
[36]
Prototypical contrastive learning of unsupervised representations,
J. Li, P. Zhou, C. Xiong, and S. C. H. Hoi, “Prototypical contrastive learning of unsupervised representations,” inInternational Conference on Learning Representations (ICLR), 2021. 3
2021
-
[37]
Vision- language meets the skeleton: Progressive distillation with cross-modal knowledge for 3d action representation learning,
Y . Chen, T. He, J. Fu, L. Wang, J. Guo, T. Hu, and H. Cheng, “Vision- language meets the skeleton: Progressive distillation with cross-modal knowledge for 3d action representation learning,”IEEE Transactions on Multimedia, pp. 1–12, 2024. 3, 4, 5
2024
-
[38]
Audio-visual instance discrimination with cross-modal agreement,
P. Morgado, N. Vasconcelos, and I. Misra, “Audio-visual instance discrimination with cross-modal agreement,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 4
2021
-
[39]
Unsupervised feature learning via non-parametric instance discrimination,
Z. Wu, Y . Xiong, S. X. Yu, and D. Lin, “Unsupervised feature learning via non-parametric instance discrimination,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018. 4
2018
-
[40]
CLIP-vip: Adapting pre-trained image-text model to video-language alignment,
H. Xue, Y . Sun, B. Liu, J. Fu, R. Song, H. Li, and J. Luo, “CLIP-vip: Adapting pre-trained image-text model to video-language alignment,” inThe Eleventh International Conference on Learning Representa- tions, 2023. 5
2023
-
[41]
Omnivore: A single model for many visual modalities,
R. Girdhar, M. Singh, N. Ravi, L. van der Maaten, A. Joulin, and I. Misra, “Omnivore: A single model for many visual modalities,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2022, pp. 16 102–16 112. 5
2022
-
[42]
Colorful image colorization,
R. Zhang, P. Isola, and A. A. Efros, “Colorful image colorization,” in European Conference on Computer Vision, 2016. 5
2016
-
[43]
Quo vadis, action recognition? a new model and the kinetics dataset,
J. Carreira and A. Zisserman, “Quo vadis, action recognition? a new model and the kinetics dataset,” inproceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017. 5, 6
2017
-
[44]
Viewpoint invariant 3d driver body pose-based activity recognition,
M. Martin, D. Lerch, and M. V oit, “Viewpoint invariant 3d driver body pose-based activity recognition,” in2023 IEEE Intelligent Vehicles Symposium (IV), 2023. 6
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.