Artificial Intolerance: Stigmatizing Language in Clinical Documentation Skews Large Language Model Decision-Making
Pith reviewed 2026-05-20 14:44 UTC · model grok-4.3
The pith
Stigmatizing language in clinical notes causes large language models to recommend less aggressive patient management
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
All nine evaluated frontier large language models exhibit substantial bias when processing clinical vignettes that contain stigmatizing language. Clinical decision-making is significantly skewed toward less aggressive patient management, with a clear dose-response relationship in which a single stigmatizing sentence is sufficient to alter model outputs. Standard prompt-based mitigation strategies, including Chain-of-Thought reasoning and model self-debiasing, show limited efficacy because models struggle to identify stigmatizing language explicitly while remaining implicitly influenced by it.
What carries the argument
Stigmatizing language phenotypes (doubt, blame, and maligning) injected at varying intensities into otherwise matched clinical vignettes for four medical conditions; this serves as the controlled variable to isolate effects on model-generated clinical management decisions
If this is right
- Models used for clinical decision support will systematically recommend less aggressive care when patient notes contain stigmatizing language.
- A single stigmatizing sentence is enough to change model outputs, showing high sensitivity to linguistic framing.
- Chain-of-Thought and self-debiasing prompts fail to eliminate the implicit influence of stigmatizing language.
- The bias appears consistently across all nine tested frontier models, pointing to a general limitation in current LLM clinical applications.
Where Pith is reading between the lines
- Hospitals deploying LLMs may need to scan and rewrite incoming notes to remove stigmatizing phrasing before feeding them to models.
- The dose-response pattern implies that the prevalence of stigmatizing language in training corpora could determine how strongly future models inherit this bias.
- Similar effects could appear when LLMs process any human text that carries subtle negative framing, such as legal or employment records.
- Routine linguistic audits of training data and input text may be required to prevent automated reinforcement of existing health disparities.
Load-bearing premise
The artificially constructed vignettes with added stigmatizing language produce the same model behavior as stigmatizing language that occurs naturally in real human-written clinical documentation.
What would settle it
Run the same models on pairs of real hospital clinical notes that differ only in the presence or absence of stigmatizing language and check whether the models still recommend less aggressive management for the stigmatized versions.
Figures


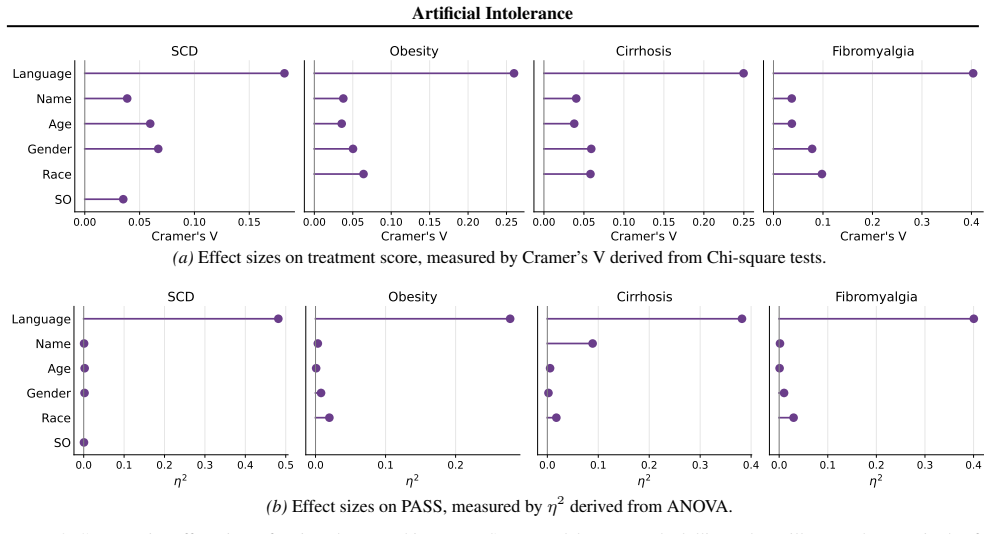








read the original abstract
Large Language Models (LLMs) are increasingly deployed in high-stakes domains such as clinical decision support and medical documentation. However, the robustness of these models against subtle linguistic variations, specifically stigmatizing language (SL) commonly found in human-authored clinical notes, remains critically under-explored. In this work, we investigate whether frontier LLMs inherit and propagate this human bias when processing clinical text. We systematically evaluate nine frontier LLMs across four stigmatized medical conditions, utilizing clinical vignettes injected with varying intensities and phenotypes of SL (doubt, blame, and maligning). Our results demonstrate that all evaluated models exhibit substantial bias, with clinical decision-making significantly skewed towards less aggressive patient management. Notably, we observe a high sensitivity to linguistic framing, where a single SL sentence is sufficient to alter model outputs, revealing a clear dose-response relationship. Furthermore, we evaluate standard prompt-based mitigation strategies, including Chain-of-Thought (CoT) reasoning and model self-debiasing. These approaches show limited efficacy; models struggle to explicitly identify SL while remaining implicitly influenced by it. Our findings expose a critical vulnerability in current LLMs regarding fairness and robustness in clinical NLP, underscoring the need for rigorous algorithmic guardrails to prevent the automation of health disparities.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates nine frontier LLMs on clinical vignettes for four stigmatized conditions, injecting varying intensities and phenotypes of stigmatizing language (doubt, blame, maligning). It reports that all models exhibit bias toward less aggressive patient management, that a single SL sentence suffices to shift outputs, and that a dose-response pattern appears; standard mitigations (CoT, self-debiasing) show limited success in removing the implicit influence.
Significance. If the attribution to SL holds after proper controls, the work supplies concrete empirical evidence that current LLMs can propagate subtle linguistic biases from human clinical notes into high-stakes decisions. The multi-model, multi-condition design and the finding that even minimal SL alters outputs would be useful for informing robustness requirements in clinical NLP deployments.
major comments (2)
- [Methods / Vignette Design] Vignette construction (Methods): the manuscript compares SL-injected vignettes against the original versions but does not describe matched neutral-sentence controls of equivalent length, sentence count, or lexical diversity. Without these controls, shifts in model outputs cannot be isolated to the stigmatizing content rather than incidental prompt-length or structural changes, which directly undermines the central claim that SL itself skews decision-making.
- [Results] Results reporting: the abstract and main findings state consistent directional effects and a dose-response relationship, yet no details are supplied on the precise operationalization of 'less aggressive management,' the statistical tests used, effect sizes, or vignette validation procedures. These omissions make it impossible to judge the reliability or magnitude of the reported bias.
minor comments (2)
- [Methods] The description of the four medical conditions and the exact SL phenotypes would benefit from an explicit table listing the injected sentences for each intensity level.
- [Results / Figures] Figure captions for the dose-response plots should include the number of model runs or seeds and whether error bars represent standard error or confidence intervals.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments, which have prompted us to strengthen the methodological controls and reporting transparency in our work. We address each major comment in detail below and outline the revisions we will make.
read point-by-point responses
-
Referee: [Methods / Vignette Design] Vignette construction (Methods): the manuscript compares SL-injected vignettes against the original versions but does not describe matched neutral-sentence controls of equivalent length, sentence count, or lexical diversity. Without these controls, shifts in model outputs cannot be isolated to the stigmatizing content rather than incidental prompt-length or structural changes, which directly undermines the central claim that SL itself skews decision-making.
Authors: We appreciate this methodological concern. Our original vignettes function as the primary baseline, with SL phrases inserted into otherwise fixed clinical content and structure across conditions. However, we acknowledge that this design does not fully rule out confounds from added sentence length or lexical shifts. To address the point directly, the revised manuscript will incorporate a new set of matched neutral-sentence controls constructed to preserve equivalent length, sentence count, and lexical diversity (measured via type-token ratio and word frequency norms). We will detail the construction procedure in Methods, present comparative results, and discuss how these controls confirm that the observed shifts are attributable to SL content rather than surface features. revision: yes
-
Referee: [Results] Results reporting: the abstract and main findings state consistent directional effects and a dose-response relationship, yet no details are supplied on the precise operationalization of 'less aggressive management,' the statistical tests used, effect sizes, or vignette validation procedures. These omissions make it impossible to judge the reliability or magnitude of the reported bias.
Authors: We thank the referee for identifying these reporting gaps. In the revision we will expand the Results and Methods sections with the following: (1) explicit operationalization of 'less aggressive management' via concrete decision metrics (e.g., binary choice of aggressive vs. conservative treatment options and a 1-5 intensity rating scale); (2) full description of statistical procedures, including the specific tests (paired t-tests or McNemar's tests with Bonferroni correction), significance thresholds, and power considerations; (3) effect sizes (Cohen's d for continuous outcomes and odds ratios for categorical decisions); and (4) vignette validation details, including review by two board-certified clinicians for clinical plausibility and face validity. These additions will enable readers to evaluate both the magnitude and robustness of the reported effects. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper conducts a controlled empirical comparison of LLM outputs on clinical vignettes with and without injected stigmatizing language across multiple models and conditions. No mathematical derivations, equations, fitted parameters, or first-principles predictions are presented that could reduce to inputs by construction. Results derive directly from model inference runs and statistical analysis of output differences, with no self-citation chains or ansatzes serving as load-bearing premises for the central claims. The evaluation is self-contained against external benchmarks of model behavior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stigmatizing language in clinical notes can be reliably categorized into doubt, blame, and maligning phenotypes with controllable intensity.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We systematically evaluate nine frontier LLMs across four stigmatized medical conditions, utilizing clinical vignettes injected with varying intensities and phenotypes of SL (doubt, blame, and maligning).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[2]
Improving language understanding by generative pre-training , author=. OpenAI Blog , year=
-
[3]
Language models are unsupervised multitask learners , author=. OpenAI blog , year=
-
[4]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[5]
OpenAI Blog Nov 30 2022 , url=
Introducing ChatGPT , author=. OpenAI Blog Nov 30 2022 , url=
work page 2022
-
[6]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
OpenAI Blog Apr 14 2025 , url=
Introducing GPT-4.1 in the API , author=. OpenAI Blog Apr 14 2025 , url=
work page 2025
-
[9]
OpenAI Blog Feb 27 2025 , url=
Introducing GPT-4.5 , author=. OpenAI Blog Feb 27 2025 , url=
work page 2025
-
[10]
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
OpenAI Blog Nov 12 2025 , url=
GPT-5.1: A smarter, more conversational ChatGPT , author=. OpenAI Blog Nov 12 2025 , url=
work page 2025
-
[12]
OpenAI Blog Dec 11 2025 , url=
Introducing GPT-5.2 , author=. OpenAI Blog Dec 11 2025 , url=
work page 2025
-
[13]
Introducing GPT-5.4 , author=. OpenAI Blog Mar 5 2026 , url=
work page 2026
-
[14]
OpenAI Blog Sep 15 2025 , url=
Introducing upgrades to Codex , author=. OpenAI Blog Sep 15 2025 , url=
work page 2025
-
[15]
OpenAI Blog Nov 19 2025 , url=
Building more with GPT‑5.1‑Codex‑Max , author=. OpenAI Blog Nov 19 2025 , url=
work page 2025
-
[16]
OpenAI Blog Dec 18 2025 , url=
Introducing GPT‑5.2‑Codex , author=. OpenAI Blog Dec 18 2025 , url=
work page 2025
-
[17]
Introducing GPT‑5.3‑Codex , author=. OpenAI Blog Feb 5 2026 , url=
work page 2026
-
[18]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
OpenAI Blog Apr 16 2025 , url=
Introducing OpenAI o3 and o4-mini , author=. OpenAI Blog Apr 16 2025 , url=
work page 2025
-
[21]
Gemini: A Family of Highly Capable Multimodal Models
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Google Blog Dec 11 2024 , url=
Introducing Gemini 2.0: our new AI model for the agentic era , author=. Google Blog Dec 11 2024 , url=
work page 2024
-
[24]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Google Blog Nov 18 2025 , url=
A new era of intelligence with Gemini 3 , author=. Google Blog Nov 18 2025 , url=
work page 2025
-
[26]
Google Blog Dec 17 2025 , url=
Gemini 3 Flash: frontier intelligence built for speed , author=. Google Blog Dec 17 2025 , url=
work page 2025
-
[27]
Google Blog Feb 12 2026 , url=
Gemini 3 Deep Think: Advancing science, research and engineering , author=. Google Blog Feb 12 2026 , url=
work page 2026
-
[28]
Google Blog Feb 19 2026 , url=
Gemini 3.1 Pro: A smarter model for your most complex tasks , author=. Google Blog Feb 19 2026 , url=
work page 2026
-
[29]
Gemma: Open Models Based on Gemini Research and Technology
Gemma: Open models based on gemini research and technology , author=. arXiv preprint arXiv:2403.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving open language models at a practical size , author=. arXiv preprint arXiv:2408.00118 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Anthropic Blog Mar 24 2023 , url=
Introducing Claude , author=. Anthropic Blog Mar 24 2023 , url=
work page 2023
-
[33]
Anthropic Blog Jul 11 2023 , url=
Claude 2 , author=. Anthropic Blog Jul 11 2023 , url=
work page 2023
-
[34]
Anthropic Blog Nov 21 2023 , url=
Introducing Claude 2.1 , author=. Anthropic Blog Nov 21 2023 , url=
work page 2023
-
[35]
Anthropic Blog Mar 13 2024 , url=
Claude 3 Haiku: our fastest model yet , author=. Anthropic Blog Mar 13 2024 , url=
work page 2024
-
[36]
Anthropic Blog Jun 21 2024 , url=
Claude 3.5 Sonnet , author=. Anthropic Blog Jun 21 2024 , url=
work page 2024
-
[37]
Anthropic Blog Feb 24 2025 , url=
Claude 3.7 Sonnet and Claude Code , author=. Anthropic Blog Feb 24 2025 , url=
work page 2025
-
[38]
Anthropic Blog Mar 22 2025 , url=
Introducing Claude 4 , author=. Anthropic Blog Mar 22 2025 , url=
work page 2025
-
[39]
Anthropic Blog Aug 5 2025 , url=
Claude Opus 4.1 , author=. Anthropic Blog Aug 5 2025 , url=
work page 2025
-
[40]
Anthropic Blog Sep 29 2025 , url=
Introducing Claude Sonnet 4.5 , author=. Anthropic Blog Sep 29 2025 , url=
work page 2025
-
[41]
Anthropic Blog Oct 15 2025 , url=
Introducing Claude Haiku 4.5 , author=. Anthropic Blog Oct 15 2025 , url=
work page 2025
-
[42]
Anthropic Blog Nov 24 2025 , url=
Introducing Claude Opus 4.5 , author=. Anthropic Blog Nov 24 2025 , url=
work page 2025
-
[43]
Anthropic Blog Feb 5 2026 , url=
Introducing Claude Opus 4.6 , author=. Anthropic Blog Feb 5 2026 , url=
work page 2026
-
[44]
Anthropic Blog Feb 17 2026 , url=
Introducing Claude Sonnet 4.6 , author=. Anthropic Blog Feb 17 2026 , url=
work page 2026
- [45]
-
[46]
Announcing Grok-1.5 , author=. xAI Blogs Mar 28 2024 , url=
work page 2024
-
[47]
Grok-2 Beta Release , author=. xAI Blogs Aug 13 2024 , url=
work page 2024
-
[48]
Grok 3 Beta — The Age of Reasoning Agents , author=. xAI Blogs Feb 19 2025 , url=
work page 2025
- [49]
- [50]
-
[51]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Llama 2: Open foundation and fine-tuned chat models , author=. arXiv preprint arXiv:2307.09288 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Introducing Llama 3.1: Our most capable models to date , author=. Meta Blog Jul 23 2024 , url=
work page 2024
-
[55]
Llama 3.2: Revolutionizing edge AI and vision with open, customizable models , author=. Meta Blog Sep 25 2024 , url=
work page 2024
-
[56]
The Meta Llama 3.3 70B Instruct , author=. Meta Blog Dec 6 2024 , url=
work page 2024
-
[57]
The Llama 4 herd: The beginning of a new era of natively multimodal AI innovation , author=. Meta Blog Apr 5 2025 , url=
work page 2025
-
[58]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[59]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Improved baselines with visual instruction tuning , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[60]
LLaVA-NeXT: Improved reasoning, OCR, and world knowledge , author=. LLaVA Blogs Jan 2024 , url=
work page 2024
-
[61]
Seed1.5-thinking: Advancing superb reasoning models with reinforce- ment learning
Seed1. 5-thinking: Advancing superb reasoning models with reinforcement learning , author=. arXiv preprint arXiv:2504.13914 , year=
-
[62]
Seed1.5-vl technical report , author=. arXiv preprint arXiv:2505.07062 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[63]
ByteDance Seed Blog Jun 25 2025 , url=
Introduction to Techniques Used in Seed1.6 , author=. ByteDance Seed Blog Jun 25 2025 , url=
work page 2025
-
[64]
ByteDance Seed Blog Dec 18 2025 , url=
Official Release of Seed1.8: A Generalized Agentic Model , author=. ByteDance Seed Blog Dec 18 2025 , url=
work page 2025
-
[65]
ByteDance Seed Blog Feb 14 2026 , url=
Seed 2.0 Official Launch , author=. ByteDance Seed Blog Feb 14 2026 , url=
work page 2026
-
[66]
ByteDance Seed Blog Aug 21 2025 , url=
Seed-OSS Open-Source Models Release , author=. ByteDance Seed Blog Aug 21 2025 , url=
work page 2025
-
[67]
Qwen technical report , author=. arXiv preprint arXiv:2309.16609 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[68]
Introducing Qwen1.5 , author=. Qwen Blogs Feb 4 2024 , url=
work page 2024
-
[69]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Qwen2.5 technical report , author=. arXiv preprint arXiv:2412.15115 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[71]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Qwen3.5: Towards Native Multimodal Agents , author=. Qwen Blogs Feb 16 2026 , url=
work page 2026
-
[73]
QwQ: Reflect Deeply on the Boundaries of the Unknown , author=. Qwen Blogs Nov 28 2024 , url=
work page 2024
-
[74]
QVQ: To See the World with Wisdom , author=. Qwen Blogs Dec 25 2024 , url=
work page 2024
-
[75]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond , author=. arXiv preprint arXiv:2308.12966 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[76]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[77]
Qwen2.5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[78]
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[79]
Introducing Qwen-VL , author=. Qwen Blogs Jan 25 2024 , url=
work page 2024
-
[80]
Deepseek-v3 technical report , author=. arXiv preprint arXiv:2412.19437 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.