SemBlock: Semantic Boundary Dynamic Blocks for Diffusion LLMs
Pith reviewed 2026-06-28 06:10 UTC · model grok-4.3
The pith
Predicting semantic boundaries from hidden states enables dynamic block decoding that improves diffusion LLMs over fixed blocks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
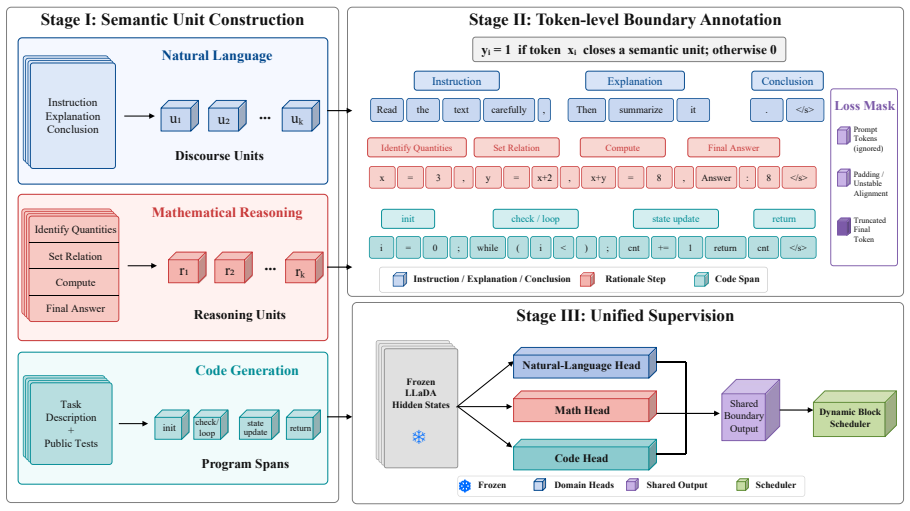
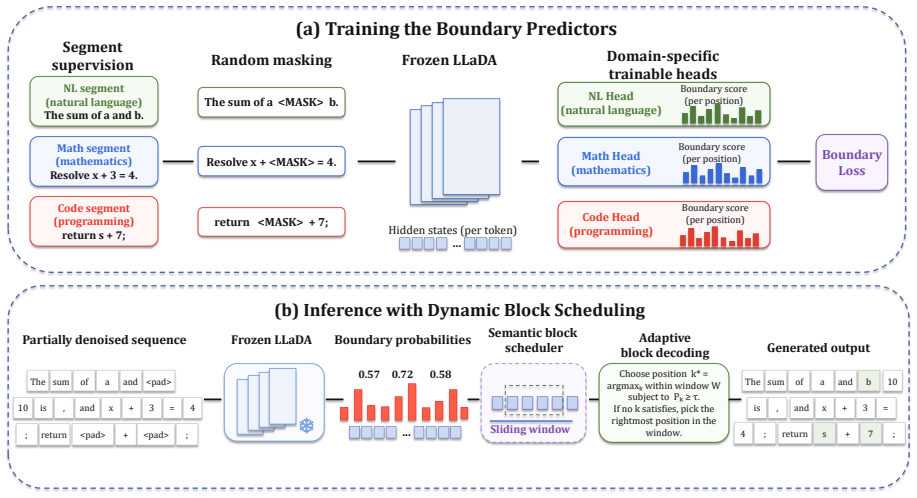
SemBlock formulates dynamic block construction as semantic boundary prediction and trains lightweight predictors on frozen LLaDA hidden states, using supervision from the SemBound dataset derived from discourse units, reasoning steps, and implementation spans. During inference, predicted boundary probabilities determine the end of each dynamic block, leading to improved performance over fixed-block decoding and AdaBlock on GSM8K, IFEval, MATH, and HumanEval.
What carries the argument
Lightweight semantic boundary predictors trained on frozen model hidden states, supervised by boundary labels from SemBound.
If this is right
- Dynamic blocks aligned with semantics reduce misalignment in token commitment during denoising.
- Performance gains appear across natural language, math, and code generation tasks.
- The approach works with existing frozen diffusion LLMs without retraining the base model.
- Boundary prediction adds minimal overhead at inference time.
Where Pith is reading between the lines
- Similar boundary prediction could apply to other non-autoregressive generation methods.
- Optimizing the boundary labels might further close the gap to oracle dynamic blocks.
- This suggests semantic structure is a useful signal for controlling generation granularity in DLMs.
Load-bearing premise
Boundary labels derived from discourse units and reasoning steps provide the right supervision for optimal points to commit tokens in the diffusion process.
What would settle it
An experiment where using the predicted boundaries leads to no improvement or worse results than fixed blocks on the same set of tasks and models.
Figures

read the original abstract
Diffusion language models (DLMs) generate text through iterative denoising, and blockwise decoding improves their practicality by committing tokens in local blocks. However, existing blockwise methods typically rely on fixed block sizes or delimiter-based runtime signals, which do not necessarily align with semantic boundaries. In this paper, we propose SemBlock, a semantic-boundary-driven dynamic block decoding framework for diffusion LLMs. SemBlock formulates dynamic block construction as semantic boundary prediction and trains lightweight predictors on frozen LLaDA hidden states. To provide supervision, we construct SemBound, a semantic-boundary dataset that derives boundary labels from discourse units, reasoning steps, and implementation spans across natural language, math, and code tasks. During inference, SemBlock uses predicted boundary probabilities to select the ending position of each dynamic block. Experiments on GSM8K, IFEval, MATH, and HumanEval show that SemBlock consistently improves over fixed-block decoding and AdaBlock. Our code is publicly available: https://github.com/TH-AI-Lab-PKU/SemBlock.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SemBlock, a semantic-boundary-driven dynamic block decoding framework for diffusion LLMs. It formulates block construction as semantic boundary prediction, trains lightweight predictors on frozen LLaDA hidden states, and constructs the SemBound dataset with boundary labels derived from discourse units, reasoning steps, and implementation spans. At inference, predicted boundary probabilities determine dynamic block endings. Experiments on GSM8K, IFEval, MATH, and HumanEval report consistent improvements over fixed-block decoding and AdaBlock, with code released publicly.
Significance. If the gains prove robust, the approach could improve the practicality of diffusion LLMs by aligning block commitments more closely with semantic structure across language, math, and code domains. The public code release is a clear strength that supports reproducibility.
major comments (2)
- Abstract: the claim of 'consistent improvements' over fixed-block decoding and AdaBlock is presented without any numerical results, standard deviations, ablation tables, or statistical tests, which prevents assessment of effect size and reliability on GSM8K, IFEval, MATH, and HumanEval.
- Paragraph on SemBound construction: the assumption that labels derived from discourse units, reasoning steps, and code spans align with optimal token-commit points in the diffusion denoising process is load-bearing for the method, yet no direct validation (e.g., correlation with denoising quality or oracle-boundary comparison) is supplied beyond downstream task performance.
minor comments (2)
- Methods section: clarify the exact training objective and architecture details of the lightweight boundary predictors (e.g., number of layers, input features from hidden states).
- Figure and table captions: ensure all experimental settings (block-size ranges, predictor thresholds, number of denoising steps) are fully specified so results can be reproduced from the public code.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the recommendation for minor revision. We address the major comments point by point below.
read point-by-point responses
-
Referee: Abstract: the claim of 'consistent improvements' over fixed-block decoding and AdaBlock is presented without any numerical results, standard deviations, ablation tables, or statistical tests, which prevents assessment of effect size and reliability on GSM8K, IFEval, MATH, and HumanEval.
Authors: We agree that the abstract would be improved by including quantitative results. In the revised version, we will update the abstract to include specific performance gains (e.g., percentage point improvements on each dataset) and mention that results are averaged over multiple runs with standard deviations reported in the main text. revision: yes
-
Referee: Paragraph on SemBound construction: the assumption that labels derived from discourse units, reasoning steps, and code spans align with optimal token-commit points in the diffusion denoising process is load-bearing for the method, yet no direct validation (e.g., correlation with denoising quality or oracle-boundary comparison) is supplied beyond downstream task performance.
Authors: This point is well-taken. The current manuscript relies on downstream task performance as the primary evidence for the effectiveness of the boundary labels. We will revise the relevant paragraph to more explicitly discuss the rationale for using these semantic units as proxies for optimal commit points and add a brief note on this as a potential limitation and avenue for future direct validation studies. revision: partial
Circularity Check
No significant circularity identified
full rationale
The paper trains lightweight boundary predictors on externally labeled SemBound data (derived from discourse units, reasoning steps, and code spans) and evaluates the resulting dynamic blocks on independent benchmarks (GSM8K, IFEval, MATH, HumanEval). The performance comparison to fixed-block and AdaBlock baselines is an empirical test of the proxy's utility rather than a quantity defined inside the same equations. No self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation appears in the described construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic boundaries derived from discourse units, reasoning steps, and code spans provide useful supervision for block-ending decisions in diffusion decoding.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , year =
Diffusion-LM Improves Controllable Text Generation , author =. Advances in Neural Information Processing Systems , year =
-
[2]
Proceedings of the 41st International Conference on Machine Learning , year =
Discrete Diffusion Modeling by Estimating the Ratios of the Data Distribution , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[3]
Advances in Neural Information Processing Systems , year =
Simple and Effective Masked Diffusion Language Models , author =. Advances in Neural Information Processing Systems , year =
-
[4]
arXiv preprint arXiv:2503.09573 , year =
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models , author =. arXiv preprint arXiv:2503.09573 , year =
-
[5]
arXiv preprint arXiv:2505.22618 , year =
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding , author =. arXiv preprint arXiv:2505.22618 , year =
-
[6]
arXiv preprint arXiv:2509.26432 , year =
AdaBlock-dLLM: Semantic-Aware Diffusion LLM Inference via Adaptive Block Size , author =. arXiv preprint arXiv:2509.26432 , year =
-
[7]
Zeldes, Amir , journal =. The
-
[8]
Zeldes, Amir and Das, Debopam and Maziero, Erick Galani and Antonio, Juliano and Iruskieta, Mikel , booktitle =. The
-
[9]
Yu, Yue and Zhu, Yilun and Liu, Yang and Liu, Yan and Peng, Siyao and Gong, Mackenzie and Zeldes, Amir , booktitle =
-
[10]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =
Program Induction by Rationale Generation: Learning to Solve and Explain Algebraic Word Problems , author =. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2017 , publisher =
2017
-
[11]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =
-
[12]
arXiv preprint arXiv:2110.14168 , year =
Training Verifiers to Solve Math Word Problems , author =. arXiv preprint arXiv:2110.14168 , year =
-
[13]
arXiv preprint arXiv:2502.09992 , year=
Large Language Diffusion Models , author=. arXiv preprint arXiv:2502.09992 , year=
-
[14]
arXiv preprint arXiv:2505.19223 , year=
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models , author=. arXiv preprint arXiv:2505.19223 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
arXiv preprint arXiv:2107.03374 , year=
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
-
[17]
arXiv preprint arXiv:2508.15487 , year =
Dream 7B: Diffusion Large Language Models , author =. arXiv preprint arXiv:2508.15487 , year =
-
[18]
International Conference on Learning Representations , year =
Soft-Masked Diffusion Language Models , author =. International Conference on Learning Representations , year =
-
[19]
arXiv preprint arXiv:2311.07911 , year=
Instruction-Following Evaluation for Large Language Models , author=. arXiv preprint arXiv:2311.07911 , year=
-
[20]
2026 , eprint=
Swordsman: Entropy-Driven Adaptive Block Partition for Efficient Diffusion Language Models , author=. 2026 , eprint=
2026
-
[21]
2019 , eprint=
Mask-Predict: Parallel Decoding of Conditional Masked Language Models , author=. 2019 , eprint=
2019
-
[22]
Husain, Hamel and Wu, Ho-Hsiang and Gazit, Tiferet and Allamanis, Miltiadis and Brockschmidt, Marc , journal =
-
[23]
Competition-Level Code Generation with
Li, Yujia and Choi, David and Chung, Junyoung and Kushman, Nate and Schrittwieser, Julian and Leblond, R. Competition-Level Code Generation with. Science , volume =. 2022 , doi =
2022
-
[24]
Luo, Lizhuo and Li, Shenggui and Wen, Yonggang and Zhang, Tianwei , year =. 2602.05992 , archivePrefix =
-
[25]
2026 , eprint =
Learning Unmasking Policies for Diffusion Language Models , author =. 2026 , eprint =
2026
-
[26]
Xia, Hanchen and Chen, Baoyou and Ge, Yutang and Zhao, Guojiang and Zhu, Siyu , year =. 2601.11214 , archivePrefix =
-
[27]
2026 , eprint =
DualDiffusion: A Speculative Decoding Strategy for Masked Diffusion Models , author =. 2026 , eprint =
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.