Next-Latent Prediction Transformers Learn Compact World Models
Pith reviewed 2026-05-25 07:18 UTC · model grok-4.3
The pith
Adding a next-latent prediction loss makes transformer internal states converge to belief states that compress history for future prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
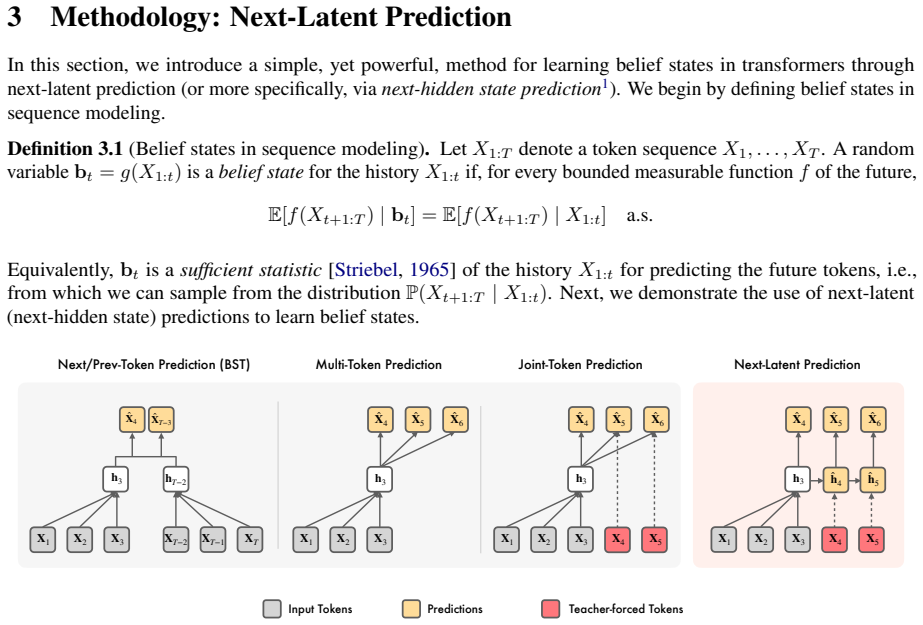
NextLat extends standard next-token training with self-supervised predictions in the latent space, training the model to predict its next latent state given the next token. The paper shows theoretically that the resulting latents converge to belief states, which are compressed summaries of history sufficient for predicting future observations. This auxiliary objective injects a recurrent inductive bias into transformers, encouraging formation of compact internal world models with coherent transition dynamics that standard next-token prediction does not guarantee.
What carries the argument
The next-latent prediction auxiliary loss, jointly optimized with the primary next-token loss, which drives convergence of latents to belief states.
If this is right
- The learned latents become more compressed representations of history.
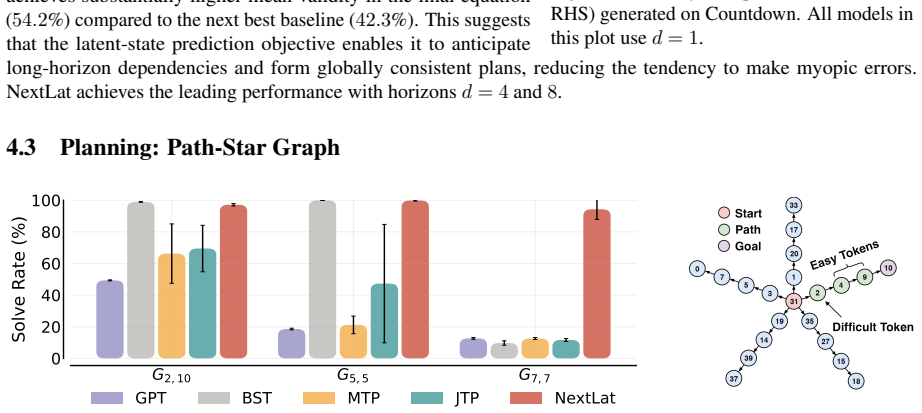
- Downstream accuracy improves on world modeling, reasoning, planning, and language modeling tasks.
- Variable-length self-speculative decoding becomes possible, accelerating inference up to 3.3x.
- The transformer architecture, parallel training efficiency, and inference procedure remain unchanged.
Where Pith is reading between the lines
- The same auxiliary objective might be added to other non-recurrent sequence models to induce similar compression.
- Improved lookahead planning may stem directly from the enforced consistency of the learned transition dynamics.
- Smaller models trained with NextLat could match the effective capacity of larger models trained only on next-token loss.
Load-bearing premise
Jointly optimizing the auxiliary latent-prediction loss with the main next-token loss will produce convergence to belief states without the auxiliary term dominating or destabilizing training.
What would settle it
Train a transformer under the NextLat objective and check whether its latent representations fail to compress history or produce inconsistent next-state predictions across different sequences of the same underlying process.
Figures







read the original abstract
Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc lookups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next token. Theoretically, we show that these latents provably converge towards belief states, compressed information about the history necessary to predict the future. This simple auxiliary objective injects a recurrent inductive bias into transformers while leaving their architecture, parallel training efficiency, and inference unchanged. NextLat effectively encourages transformers to form compact internal world models with coherent belief states and transition dynamics -- crucial properties not guaranteed by standard next-token prediction alone. Empirically, across benchmarks in world modeling, reasoning, planning, and language modeling, NextLat demonstrates significant gains over standard next-token prediction and other baselines in downstream accuracy, representation compression, and lookahead planning. Furthermore, NextLat enables variable-length self-speculative decoding, accelerating inference by up to 3.3x in language modeling. NextLat offers a simple yet effective paradigm for learning compact, predictive representations in transformers that generalize better. Our code is available at https://github.com/microsoft/NextLat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Next-Latent Prediction (NextLat), which augments standard next-token cross-entropy training of transformers with an auxiliary self-supervised loss that predicts the next latent representation given the next token. It claims that the resulting latents provably converge to belief states (compressed sufficient statistics of history for future prediction), inject a recurrent inductive bias without altering architecture or inference, and yield empirical gains in world modeling, reasoning, planning, language modeling, representation compression, and up to 3.3x faster self-speculative decoding.
Significance. If the convergence result holds under the joint objective actually used in training and the reported gains are robust to controls, the method would offer a lightweight way to encourage compact, predictive internal world models in transformers while preserving their parallel training advantages. The combination of a theoretical fixed-point argument with downstream improvements in lookahead planning and variable-length decoding would be a notable contribution to representation learning for sequential decision-making tasks.
major comments (2)
- [Abstract / theoretical analysis section] The theoretical claim that latents converge to belief states is derived only for the auxiliary latent-prediction objective (abstract and the paragraph beginning 'Theoretically, we show...'). No argument is supplied that the stationary points of the combined loss (next-token cross-entropy plus weighted auxiliary term) remain belief states; the next-token term could in principle select representations that are locally predictive of the immediate token but violate the belief-state fixed-point condition. This gap is load-bearing for the central 'provably converge' claim.
- [Experiments section] The empirical sections report gains on world-modeling, reasoning, and planning benchmarks, but the manuscript does not include an ablation that isolates whether the auxiliary loss alone (without the next-token term) already produces the claimed belief-state convergence, nor does it verify that the learned latents satisfy the belief-state property on the actual trained models.
minor comments (2)
- [Abstract] The abstract states 'Our code is available at https://github.com/microsoft/NextLat' but does not specify the commit or tag corresponding to the reported experiments.
- [Theoretical analysis] Notation for the latent transition and belief-state definitions should be introduced with explicit equations rather than prose descriptions to allow direct comparison with the derived fixed-point condition.
Simulated Author's Rebuttal
We are grateful to the referee for the constructive feedback on our manuscript. We address the two major comments below and plan to make revisions to strengthen the theoretical claims and experimental validation.
read point-by-point responses
-
Referee: [Abstract / theoretical analysis section] The theoretical claim that latents converge to belief states is derived only for the auxiliary latent-prediction objective (abstract and the paragraph beginning 'Theoretically, we show...'). No argument is supplied that the stationary points of the combined loss (next-token cross-entropy plus weighted auxiliary term) remain belief states; the next-token term could in principle select representations that are locally predictive of the immediate token but violate the belief-state fixed-point condition. This gap is load-bearing for the central 'provably converge' claim.
Authors: The referee correctly identifies that our theoretical analysis derives the convergence to belief states specifically for the auxiliary latent-prediction objective. We did not provide a proof that the stationary points of the joint loss are belief states. In the revised manuscript, we will revise the abstract and the theoretical section to accurately reflect that the auxiliary objective has belief states as fixed points, and that the combined training is intended to encourage this property while maintaining next-token prediction performance. We will also add a discussion on why the next-token loss is not expected to violate the fixed-point condition under suitable hyperparameter choices for the auxiliary weight. revision: yes
-
Referee: [Experiments section] The empirical sections report gains on world-modeling, reasoning, and planning benchmarks, but the manuscript does not include an ablation that isolates whether the auxiliary loss alone (without the next-token term) already produces the claimed belief-state convergence, nor does it verify that the learned latents satisfy the belief-state property on the actual trained models.
Authors: We agree that the manuscript would benefit from an ablation isolating the auxiliary loss and direct verification of the belief-state property on the trained models. In the revision, we will add such an ablation study where possible (noting that training solely with the auxiliary loss may require adjustments for stability) and include metrics or checks to verify that the learned latents act as sufficient statistics for future predictions. This will help confirm the empirical realization of the theoretical property. revision: yes
Circularity Check
No circularity; theoretical claim presented as independent proof
full rationale
The paper states a theoretical result that latents converge to belief states under the auxiliary latent-prediction objective. No quoted equations or self-citations reduce this claim by construction to fitted inputs, renamed empirical patterns, or load-bearing prior work by the same authors. The joint next-token + auxiliary loss is acknowledged as the actual training objective, but the provided text frames the convergence as a separate proof rather than a statistical consequence of the fit itself. This is the normal case of a self-contained derivation; the skeptic concern is a potential applicability gap, not a circular reduction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Theoretically, we show that these latents provably converge towards belief states, compressed information about the history necessary to predict the future. ... For these consistency objectives to be satisfied, ht must converge to a belief state
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Optimizing for next-token consistency ... and transition consistency ... ensures existence of measurable maps ... ht must jointly optimize toward a belief state
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 4 Pith papers
-
Semantic Step Prediction: Multi-Step Latent Forecasting in LLM Reasoning Trajectories via Step Sampling
Applying STP at consecutive semantic reasoning steps achieves 168x more accurate multi-step latent prediction on ProcessBench than frozen baselines, with trajectories forming smooth curves best captured by non-linear ...
-
Improving Sampling for Masked Diffusion Models via Information Gain
Info-Gain Sampler improves MDM decoding by using bidirectional information gain to reduce cumulative uncertainty, outperforming greedy samplers on reasoning accuracy and creative writing tasks.
-
Exploring the Potential of Probabilistic Transformer for Time Series Modeling: A Report on the ST-PT Framework
ST-PT turns transformers into explicit factor graphs for time series, enabling structural injection of symbolic priors, per-sample conditional generation, and principled latent autoregressive forecasting via MFVI iterations.
-
The Depth Ceiling: On the Limits of Large Language Models in Discovering Latent Planning
LLMs discover latent planning strategies up to five steps during training and execute them up to eight steps at test time, with larger models reaching seven under few-shot prompting, revealing a dissociation between d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.