Explicit Logic Channel for Validation and Enhancement of MLLMs on Zero-Shot Tasks
Pith reviewed 2026-05-21 11:05 UTC · model grok-4.3
The pith
An explicit logic channel running parallel to multimodal models validates their zero-shot outputs and boosts accuracy by checking consistency against visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
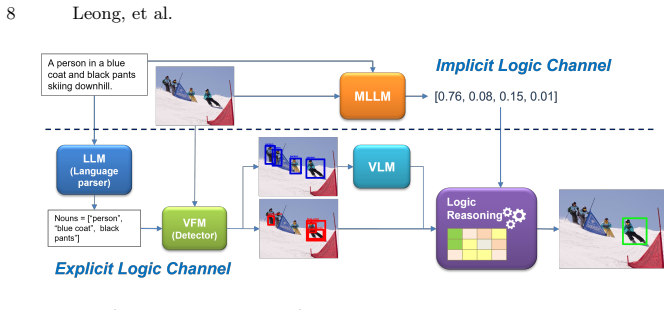
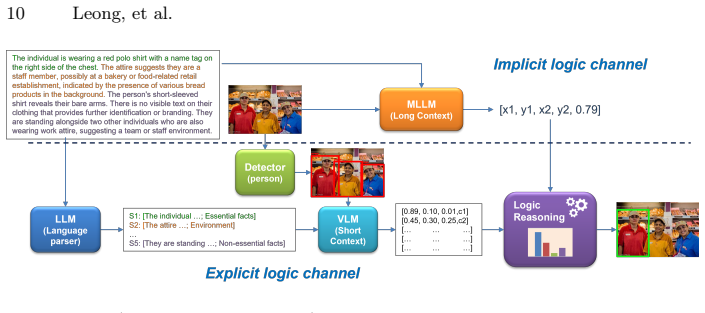
The frontier MLLM can be treated as an Implicit Logic Channel, while the proposed Explicit Logic Channel mimics human logical reasoning by incorporating an LLM, a VFM, and logical reasoning with probabilistic inference for factual, counterfactual, and relational reasoning over explicit visual evidence. A Consistency Rate enables cross-channel validation and model selection even without ground-truth annotations, and cross-channel integration further improves performance in zero-shot tasks while grounding outputs in explicit visual evidence for greater trustworthiness.
What carries the argument
The Explicit Logic Channel, which performs factual, counterfactual, and relational reasoning over explicit visual evidence using an LLM, VFM, and probabilistic inference in parallel with the MLLM's implicit channel.
If this is right
- Consistency Rate enables selection among MLLMs for zero-shot tasks without requiring ground-truth annotations.
- Cross-channel integration raises accuracy on multiple-choice visual question answering and human-centric referring expression comprehension.
- Explicit visual evidence from the logic channel increases explainability and trustworthiness of MLLM decisions.
- The approach applies across eleven open-source models from four frontier families on three challenging benchmarks.
Where Pith is reading between the lines
- The same consistency-checking idea could be tested on additional multimodal tasks such as image captioning or visual navigation to check broader applicability.
- Divergences between channels could serve as automatic signals for targeted retraining or prompt adjustment of the underlying MLLM.
- The method might support real-time deployment if the explicit channel can be distilled into a faster module while preserving the validation benefit.
Load-bearing premise
The Explicit Logic Channel can accurately carry out factual, counterfactual, and relational reasoning over explicit visual evidence to produce consistency checks that meaningfully align with the MLLM's implicit outputs.
What would settle it
Running the proposed channel on the same MC-VQA and HC-REC benchmarks and finding that consistency rate fails to predict actual accuracy gains or that integration yields no performance lift would falsify the central claim.
Figures






read the original abstract
Frontier Multimodal Large Language Models (MLLMs) exhibit remarkable capabilities in Visual-Language Comprehension (VLC) tasks. However, they are often deployed as zero-shot solution to new tasks in a black-box manner. Validating and understanding the behavior of these models become important for application to new task. We propose an Explicit Logic Channel, in parallel with the black-box model channel, to perform explicit logical reasoning for model validation, selection and enhancement. The frontier MLLM, encapsulating latent vision-language knowledge, can be considered as an Implicit Logic Channel. The proposed Explicit Logic Channel, mimicking human logical reasoning, incorporates a LLM, a VFM, and logical reasoning with probabilistic inference for factual, counterfactual, and relational reasoning over the explicit visual evidence. A Consistency Rate (CR) is proposed for cross-channel validation and model selection, even without ground-truth annotations. Additionally, cross-channel integration further improves performance in zero-shot tasks over MLLMs, grounded with explicit visual evidence to enhance trustworthiness. Comprehensive experiments conducted for two representative VLC tasks, i.e., MC-VQA and HC-REC, on three challenging benchmarks, with 11 recent open-source MLLMs from 4 frontier families. Our systematic evaluations demonstrate the effectiveness of proposed ELC and CR for model validation, selection and improvement on MLLMs with enhanced explainability and trustworthiness.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an Explicit Logic Channel (ELC) running in parallel with the Implicit Logic Channel of frontier MLLMs. ELC combines an LLM, a Visual Foundation Model, and probabilistic inference to perform factual, counterfactual, and relational reasoning over explicit visual evidence. A Consistency Rate (CR) is introduced for cross-channel validation and model selection in zero-shot settings without ground-truth labels. The authors report that cross-channel integration yields performance gains on MC-VQA and HC-REC tasks across three benchmarks and 11 open-source MLLMs from four families, while improving explainability and trustworthiness.
Significance. If ELC reasoning is shown to be accurate and sufficiently independent of the MLLM channel, the approach would supply a practical, annotation-free method for validating and improving zero-shot MLLM behavior together with explicit visual grounding. The scale of the experimental evaluation (11 models, two tasks, three benchmarks) is a clear strength and supports claims of broad applicability.
major comments (3)
- [§3] §3 (ELC construction): The claim that probabilistic inference produces reliable factual/counterfactual/relational outputs rests on an unverified assumption that the LLM+VFM component does not inherit the same zero-shot failure modes as the MLLM; no diagnostic is provided to measure or correct for such correlation.
- [§5.1] §5.1 (CR definition and use): CR is presented as a proxy for correctness without ground truth, yet the manuscript contains no held-out evaluation (even on a small annotated subset) demonstrating that high CR predicts actual accuracy rather than joint error; this directly affects the validity of both the validation and the model-selection claims.
- [§5.3] §5.3 (cross-channel integration results): Reported performance lifts from ELC+MLLM fusion are not accompanied by an ablation that isolates whether gains arise from complementary correct reasoning or from correlated mistakes; without this, the trustworthiness benefit cannot be substantiated.
minor comments (2)
- [§3.2] Notation for the probabilistic inference step inside ELC is introduced without an explicit equation or pseudocode; adding one would improve reproducibility.
- [Table 2] Table 2 (model-selection results): the CR threshold used for selection is stated but its sensitivity is not reported; a short sensitivity plot would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us identify areas where the manuscript can be strengthened. We address each major comment below and will incorporate the suggested analyses into a revised version of the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (ELC construction): The claim that probabilistic inference produces reliable factual/counterfactual/relational outputs rests on an unverified assumption that the LLM+VFM component does not inherit the same zero-shot failure modes as the MLLM; no diagnostic is provided to measure or correct for such correlation.
Authors: We acknowledge that the original manuscript does not include an explicit diagnostic measuring the correlation between failure modes of the ELC (LLM+VFM+probabilistic inference) and the MLLM. The ELC is constructed to operate on explicit visual evidence and logical rules, providing a distinct reasoning pathway from the MLLM's implicit channel. To address this concern directly, we will add a new analysis in the revised manuscript that quantifies error overlap and independence across the 11 models and benchmarks, including joint error rates and a discussion of how explicit evidence reduces shared vulnerabilities. revision: yes
-
Referee: [§5.1] §5.1 (CR definition and use): CR is presented as a proxy for correctness without ground truth, yet the manuscript contains no held-out evaluation (even on a small annotated subset) demonstrating that high CR predicts actual accuracy rather than joint error; this directly affects the validity of both the validation and the model-selection claims.
Authors: The referee correctly identifies that validating CR as a reliable proxy requires evidence beyond its logical definition. While CR is designed as an annotation-free measure of cross-channel agreement, we agree that a direct check against ground truth is needed to confirm it predicts accuracy rather than joint errors. In the revision, we will add a held-out evaluation on a small annotated subset from one benchmark, reporting metrics such as the accuracy of high-CR selections versus random or low-CR baselines to substantiate the validation and model-selection claims. revision: yes
-
Referee: [§5.3] §5.3 (cross-channel integration results): Reported performance lifts from ELC+MLLM fusion are not accompanied by an ablation that isolates whether gains arise from complementary correct reasoning or from correlated mistakes; without this, the trustworthiness benefit cannot be substantiated.
Authors: We agree that the current results do not isolate the source of the observed performance improvements in the ELC+MLLM fusion. To substantiate the trustworthiness claims, the revised §5.3 will include an ablation that categorizes outcomes into agreement and disagreement cases between the two channels. We will specifically measure gains in disagreement cases (where one channel is correct) to demonstrate benefits from complementary reasoning, while also reporting joint-error scenarios to rule out correlated mistakes as the primary driver. revision: yes
Circularity Check
No significant circularity; ELC and CR are independently proposed components evaluated via experiments
full rationale
The paper introduces the Explicit Logic Channel (ELC) as a new parallel mechanism incorporating LLM, VFM, and probabilistic inference for factual/counterfactual/relational reasoning over explicit visual evidence, alongside the Consistency Rate (CR) as a cross-channel validation proxy without ground-truth. These are not derived by fitting parameters to a subset of data and then relabeling related outputs as predictions, nor do they reduce to self-definitional loops or load-bearing self-citations. The central claims rest on systematic experiments across MC-VQA and HC-REC tasks with 11 MLLMs on three benchmarks, providing external falsifiability through performance metrics and explainability gains rather than tautological equivalence to inputs. Potential concerns about error correlation between channels pertain to empirical validity, not derivation circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Probabilistic inference can effectively model logical reasoning for factual, counterfactual, and relational tasks over visual evidence.
invented entities (2)
-
Explicit Logic Channel
no independent evidence
-
Implicit Logic Channel
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Akoglu, H.: User’s guide to correlation coefficients. Turkish Journal of Emergency Medicine18(3), 91–93 (2018).https://doi.org/https://doi.org/10.1016/ j.tjem.2018.08.001,https://www.sciencedirect.com/science/article/pii/ S2452247318302164
work page 2018
-
[2]
Alhamoud, K., Alshammari, S., Tian, Y., Li, G., Torr, P., Kim, Y., Ghassemi, M.: Vision-Language Models Do Not Understand Negation. In: CVPR-25 (2025)
work page 2025
-
[3]
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond (2023),https://arxiv.org/abs/2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., Zhou, J.: Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond (2023) 28 Leong, et al
work page 2023
-
[5]
Bai, Z., Wang, P., Xiao, T., He, T., Han, Z., Zhang, Z., Shou, M.Z.: Hallucination of multimodal large language models: A survey (2025),https://arxiv.org/abs/ 2404.18930
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Nat Commun11(1753) (2020).https://doi.org/https://doi
Balsdon, T., Wyart, V., Mamassian, P.: Confidence controls perceptual evidence accumulation. Nat Commun11(1753) (2020).https://doi.org/https://doi. org/10.1038/s41467-020-15561-w
-
[7]
In: Hans- son, S.O., Hendricks, V.F
Bradley, R.: Decision Theory: A Formal Philosophical Introduction. In: Hans- son, S.O., Hendricks, V.F. (eds.) Introduction to Formal Philosophy, pp. 611–655. Springer International Publishing (2018)
work page 2018
-
[8]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, C., Anjum, S., Gurari, D.: Grounding answers for visual questions asked by visually impaired people. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19098–19107 (June 2022)
work page 2022
-
[9]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Chen, C., Anjum, S., Gurari, D.: Vqa therapy: Exploring answer differences by visually grounding answers. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 15315–15325 (2023)
work page 2023
-
[10]
Electronics13(11), 2061 (2024)
Chen, Y., Su, L., Chen, L., Lin, Z.: Lcv2: a universal pretraining-free framework for grounded visual question answering. Electronics13(11), 2061 (2024)
work page 2061
-
[11]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Chen, Z., Wu, J., Wang, W., Su, W., Chen, G., Xing, S., Zhong, M., Zhang, Q., Zhu, X., Lu, L., Li, B., Luo, P., Lu, T., Qiao, Y., Dai, J.: InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 24185–24198 (June 2024)
work page 2024
-
[12]
ArXivabs/2512.10791 (2025),https://api.semanticscholar.org/CorpusID:283737312
Cheng, A., Jacovi, A., Globerson, A., Golan, B., Kwong, C., Alberti, C., Tao, C., Ben-David, E., Tomar, G.S., Haas, L., Bitton, Y., Bloniarz, A.E., Bai, A., Wang, A., Siddiqui, A., Castillo, A.B., Atias, A., Liu, C., Fry, C., Balle, D., Ghosal, D., Kukliansky, D., Marcus, D., Gribovskaya, E., Ofek, E.O., Zhuang, H., Laish, I., Ackermann, J., Wang, L., Ris...
- [13]
- [14]
-
[15]
In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion
Di, S., Xie, W.: Grounded question-answering in long egocentric videos. In: Pro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion. pp. 12934–12943 (2024)
work page 2024
-
[16]
Diego, C., Stefano, T., Antonio, V.: Logically Consistent Language Mod- els via Neuro-Symbolic Integration. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= 7PGluppo4k
work page 2025
-
[17]
Batch-ICL: Effective, efficient, and order-agnostic in-context learning
Feng, J., Xu, R., Hao, J., Sharma, H., Shen, Y., Zhao, D., Chen, W.: Lan- guage Models can be Deductive Solvers. In: Duh, K., Gomez, H., Bethard, S. Supplementary Material 29 (eds.) Findings of the Association for Computational Linguistics: NAACL 2024. pp. 4026–4042. Association for Computational Linguistics, Mexico City, Mex- ico (June 2024).https://doi....
-
[18]
Feng, Y., Zhou, B., Lin, W., Roth, D.: BIRD: A Trustworthy Bayesian Inference Framework for Large Language Models. In: The Thirteenth International Confer- ence on Learning Representations (2025),https://openreview.net/forum?id= fAAaT826Vv
work page 2025
-
[19]
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: Mme: A comprehensive evaluation benchmark for multimodal large language models (2025),https://arxiv.org/ abs/2306.13394
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [20]
-
[21]
Gemini Team: Gemini: A Family of Highly Capable Multimodal Models (2025), https://arxiv.org/abs/2312.11805
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Han, Z., Zhu, F., Lao, Q., Jiang, H.: Zero-shot referring expression comprehen- sion via structural similarity between images and captions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14364– 14374 (2024)
work page 2024
-
[23]
In: International Conference on Learning Representations (2025),https : / / api
Huang, J., Li, Z., Jacobs, D., Naik, M., Lim, S.N.: Laser: A neuro-symbolic framework for learning spatio-temporal scene graphs with weak supervision. In: International Conference on Learning Representations (2025),https : / / api . semanticscholar.org/CorpusID:258179880
work page 2025
-
[24]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X., Qin, B., Liu, T.: A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions. ACM Transactions on In- formation Systems43(2), 1–55 (Jan 2025).https://doi.org/10.1145/3703155, http://dx.doi.org/10.1145/3703155
-
[25]
In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Hudson, D.A., Manning, C.D.: Gqa: A new dataset for real-world visual rea- soning and compositional question answering. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 6693–6702 (2019). https://doi.org/10.1109/CVPR.2019.00686
- [26]
-
[27]
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M.A., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7B (2023),https://arxiv.org/abs/2310.06825
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[28]
In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G
Kamath, A., Hsieh, C.Y., Chang, K.W., Krishna, R.: The hard positive truth about vision-language compositionality. In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision – ECCV 2024. pp. 37–54. Springer Nature Switzerland, Cham (2025)
work page 2024
-
[29]
Derf: Decomposed radiance fields,
Khan, A.U., Kuehne, H., Duarte, K., Gan, C., Lobo, N., Shah, M.: Found a rea- son for me? weakly-supervised grounded visual question answering using capsules. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 8461–8470 (2021).https://doi.org/10.1109/CVPR46437.2021. 00836 30 Leong, et al
-
[30]
In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T
Khan, A.U., Kuehne, H., Gan, C., Lobo, N.D.V., Shah, M.: Weakly supervised grounding for vqa in vision-language transformers. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision – ECCV 2022. pp. 652–670. Springer Nature Switzerland, Cham (2022)
work page 2022
-
[31]
In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR)
Khan, Z., Fu, Y.: Consistency and uncertainty: Identifying unreliable responses from black-box vision-language models for selective visual question answering. In: ProceedingsoftheIEEE/CVFConferenceonComputerVisionandPatternRecog- nition (CVPR). pp. 10854–10863 (June 2024)
work page 2024
- [32]
-
[33]
In: International Conference on Learning Representations (2023)
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., Dollár, P., Girshick, R.: Segment anything. In: International Conference on Learning Representations (2023)
work page 2023
-
[34]
In: Advances in Neural Infor- mation Processing Systems
Li, B., Lin, Z., Peng, W., Nyandwi, J.d.D., Jiang, D., Ma, Z., Khanuja, S., Krishna, R., Neubig, G., Ramanan, D.: Naturalbench: Evaluating vision- language models on natural adversarial samples. In: Advances in Neural Infor- mation Processing Systems. vol. 37, pp. 17044–17068. Curran Associates, Inc. (2024),https : / / proceedings . neurips . cc / paper _...
work page 2024
- [35]
-
[36]
In: Chaud- huri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S
Li, J., Li, D., Xiong, C., Hoi, S.: BLIP: Bootstrapping Language-Image Pre- training for Unified Vision-Language Understanding and Generation. In: Chaud- huri, K., Jegelka, S., Song, L., Szepesvari, C., Niu, G., Sabato, S. (eds.) Pro- ceedings of the 39th International Conference on Machine Learning. Proceed- ings of Machine Learning Research, vol. 162, p...
work page 2022
-
[37]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Li, Y., Wang, X., Xiao, J., Ji, W., Chua, T.S.: Invariant grounding for video ques- tion answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 2928–2937 (2022)
work page 2022
-
[38]
Li, Z., Huang, J., Naik, M.: Scallop: A Language for Neurosymbolic Programming. Proc. ACM Program. Lang7, 166:1–166:25 (2023)
work page 2023
- [39]
-
[40]
In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence (CVPR) Workshops
Li, Z., Wu, X., Du, H., Liu, F., Nghiem, H., Shi, G.: A Survey of State of the Art Large Vision Language Models: Alignment, Benchmark, Evaluations and Chal- lenges. In: Proceedings of the Computer Vision and Pattern Recognition Confer- ence (CVPR) Workshops. pp. 1587–1606 (June 2025)
work page 2025
-
[41]
In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops
Li, Z., Wu, X., Du, H., Liu, F., Nghiem, H., Shi, G.: A Survey of State of the Art Large Vision Language Models: Benchmark Evaluations and Challenges. In: Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR) Workshops. pp. 1587–1606 (June 2025)
work page 2025
-
[42]
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual Instruction Tuning (2023),https:// arxiv.org/abs/2304.08485
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Advances in neural information processing systems36, 34892–34916 (2023) Supplementary Material 31
Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems36, 34892–34916 (2023) Supplementary Material 31
work page 2023
-
[44]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: Mmbench: Is your multi-modal model an all-around player? (2024),https://arxiv.org/abs/2307.06281
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[45]
CoRRabs/2509.11862(2025).https: //doi.org/10.48550/ARXIV.2509.11862,https://doi.org/10.48550/arXiv
Ma, H., Pathak, V., Wang, D.Z.: Bridging vision language models and symbolic grounding for video question answering. CoRRabs/2509.11862(2025).https: //doi.org/10.48550/ARXIV.2509.11862,https://doi.org/10.48550/arXiv. 2509.11862
-
[46]
Uncertainty estimation in autoregressive structured prediction, 2021
Malinin, A., Gales, M.: Uncertainty estimation in autoregressive structured pre- diction. arXiv preprint arXiv:2002.07650 (2020)
-
[47]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Mao, J., Huang, J., Toshev, A., Camburu, O., Yuille, A.L., Murphy, K.: Generation and comprehension of unambiguous object descriptions. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 11–20 (2016)
work page 2016
-
[48]
Muhammad Ahsan Awais Muhammad Ahsan Awais, Peter Redmond, T.E.W., Healy, G.: Amber: advancing multimodal brain-computer interfaces for enhanced robustness—a dataset for naturalistic settings. Front. Neuroergonomics4(2023). https://doi.org/10.3389/fnrgo.2023.1216440
-
[49]
In: Bouamor, H., Pino, J., Bali, K
Olausson, T., Gu, A., Lipkin, B., Zhang, C., Solar-Lezama, A., Tenenbaum, J., Levy, R.: LINC: A Neurosymbolic Approach for Logical Reasoning by Combining Language Models with First-Order Logic Provers. In: Bouamor, H., Pino, J., Bali, K. (eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. pp. 5153–5176. Associati...
- [50]
-
[51]
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning Trans- ferable Visual Models From Natural Language Supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Res...
work page 2021
-
[52]
Rahman, S.S., Islam, M.A., Alam, M.M., Zeba, M., Rahman, M.A., Chowa, S.S., Raiaan, M.A.K., Azam, S.: Hallucination to truth: a review of fact-checking and factuality evaluation in large language models. Artificial Intelligence Review59(2) (Jan 2026).https://doi.org/10.1007/s10462-025-11454-w,http://dx.doi. org/10.1007/s10462-025-11454-w
- [53]
-
[54]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen
Reich, D., Putze, F., Schultz, T.: Measuring faithful and plausible visual grounding in VQA. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the Association for Computational Linguistics: EMNLP 2023. pp. 3129–3144. Association for Compu- tational Linguistics, Singapore (Dec 2023).https://doi.org/10.18653/v1/2023. findings-emnlp.206,https://aclantho...
-
[55]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Shen, H., Zhao, T., Zhu, M., Yin, J.: Groundvlp: Harnessing zero-shot visual grounding from vision-language pre-training and open-vocabulary object detec- tion. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 4766–4775 (2024)
work page 2024
-
[56]
arXiv preprint arXiv:2402.04252 (2023) 32 Leong, et al
Sun, Q., Wang, J., Yu, Q., Cui, Y., Zhang, F., Zhang, X., Wang, X.: Eva-clip-18b: Scaling clip to 18 billion parameters. arXiv preprint arXiv:2402.04252 (2023) 32 Leong, et al
-
[57]
Team, G.: Gemma 3 (2025),https://goo.gle/Gemma3Report
work page 2025
-
[58]
Team, Q.: Qwen3 technical report (2025),https://arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Wang, J., Jiang, H., Liu, Y., Ma, C., Zhang, X., Pan, Y., Liu, M., Gu, P., Xia, S., Li, W., Zhang, Y., Wu, Z., Liu, Z., Zhong, T., Ge, B., Zhang, T., Qiang, N., Hu, X., Jiang, X., Zhang, X., Zhang, W., Shen, D., Liu, T., Zhang, S.: A comprehensive review of multimodal large language models: Performance and challenges across different tasks (2024),https://...
-
[60]
Frontiers in Artificial IntelligenceV olume 5 - 2022(2022).https://doi
Wang, P., Hahm, C., Hammer, P.: A Model of Unified Perception and Cogni- tion. Frontiers in Artificial IntelligenceV olume 5 - 2022(2022).https://doi. org/10.3389/frai.2022.806403,https://www.frontiersin.org/journals/ artificial-intelligence/articles/10.3389/frai.2022.806403
-
[61]
2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp
Wang, T., Lin, K., Li, L., Lin, C.C., Yang, Z., Zhang, H., Liu, Z., Wang, L.: Equivariant similarity for vision-language foundation models. 2023 IEEE/CVF International Conference on Computer Vision (ICCV) pp. 11964–11974 (2023), https://api.semanticscholar.org/CorpusID:257766245
work page 2023
-
[62]
Wang, X., Wei, J., Schuurmans, D., Le, Q., Chi, E., Narang, S., Chowdhery, A., Zhou, D.: Self-consistency improves chain of thought reasoning in language models (2023),https://arxiv.org/abs/2203.11171
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [63]
-
[64]
In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C
Wei,F.,Zhao,J.,Yan,K.,Zhang,H.,Xu,C.:ALarge-ScaleHuman-CentricBench- mark for Referring Expression Comprehension in the LMM Era. In: Globerson, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J., Zhang, C. (eds.) Ad- vances in Neural Information Processing Systems. vol. 37, pp. 69566–69587. Curran Associates, Inc. (2024)
work page 2024
-
[65]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Xiao, J., Yao, A., Li, Y., Chua, T.S.: Can i trust your answer? visually grounded video question answering. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR). pp. 13204–13214 (June 2024)
work page 2024
- [66]
-
[67]
IEEE Trans- actions on Multimedia26, 3331–3340 (2024)
Yang, X., Liu, F., Lin, G.: Neural Logic Vision Language Explainer. IEEE Trans- actions on Multimedia26, 3331–3340 (2024)
work page 2024
-
[68]
The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision)
Yang, Z., Li, L., Lin, K., Wang, J., Lin, C.C., Liu, Z., Wang, L.: The Dawn of LMMs: Preliminary Explorations with GPT-4V(ision) (2023),https://arxiv. org/abs/2309.17421
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[69]
In: Proceedings of the 37th International Conference on Neural Infor- mation Processing Systems
Yarom, M., Bitton, Y., Changpinyo, S., Aharoni, R., Herzig, J., Lang, O., Ofek, E., Szpektor, I.: What you see is what you read? improving text-image alignment evaluation. In: Proceedings of the 37th International Conference on Neural Infor- mation Processing Systems. NIPS ’23, Curran Associates Inc., Red Hook, NY, USA (2023)
work page 2023
-
[70]
Yin, S., Fu, C., Zhao, S., Li, K., Sun, X., Xu, T., Chen, E.: A survey on multimodal large language models. National Science Review11(12) (2024).https://doi.org/ 10.1093/nsr/nwae403,http://dx.doi.org/10.1093/nsr/nwae403
-
[71]
In: European conference on computer vision
Yu, L., Poirson, P., Yang, S., Berg, A.C., Berg, T.L.: Modeling context in refer- ring expressions. In: European conference on computer vision. pp. 69–85. Springer (2016)
work page 2016
- [72]
-
[73]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Yue, X., Ni, Y., Zhang, K., Zheng, T., Liu, R., Zhang, G., Stevens, S., Jiang, D., Ren, W., Sun, Y., et al.: Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9556– 9567 (2024)
work page 2024
-
[74]
Zhao, J.X., Xie, Y., Kawaguchi, K., He, J., Xie, M.Q.: Automatic model selection with large language models for reasoning (2023),https://arxiv.org/abs/2305. 14333
work page 2023
- [75]
-
[76]
Zhao, W.X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., Du, Y., Yang, C., Chen, Y., Chen, Z., Jiang, J., Ren, R., Li, Y., Tang, X., Liu, Z., Liu, P., Nie, J.Y., Wen, J.R.: A Survey of Large Language Models (2025),https://arxiv.org/abs/2303.18223
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
Zhu, Y., Groth, O., Bernstein, M., Fei-Fei, L.: Visual7w: Grounded question an- swering in images. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4995–5004 (2016).https://doi.org/10.1109/CVPR. 2016.540
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.