Actuator Reality Shaping for Zero-Shot Sim-to-Real Robot Learning
Pith reviewed 2026-07-03 11:23 UTC · model grok-4.3
The pith
Shaping physical actuator dynamics to idealized simulation models allows reinforcement learning policies to transfer zero-shot to real robots.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
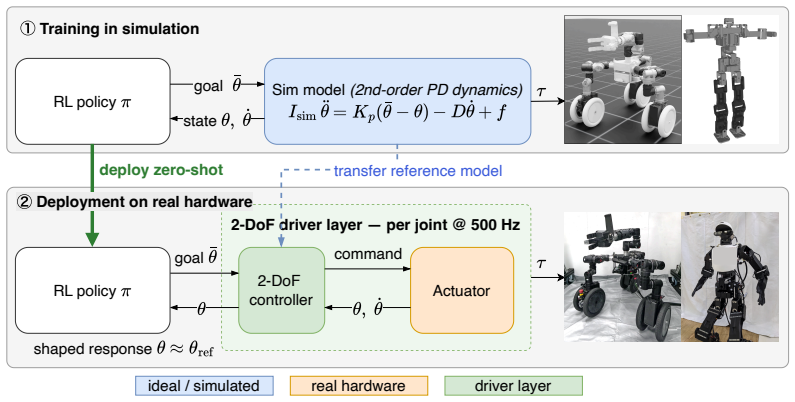
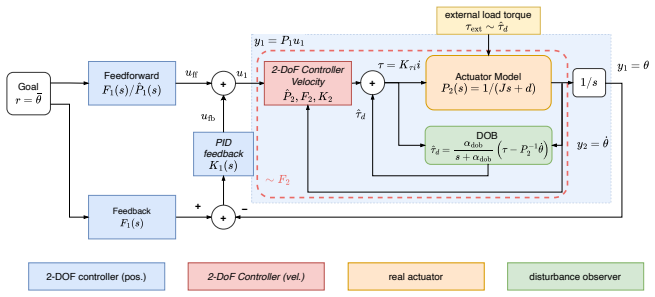
Actuator reality shaping equips each joint with a two-degree-of-freedom feedforward-feedback controller that decouples reference-response shaping from robust stabilization, thereby providing a standardized actuator interface. Policies trained only with the prescribed reference model can therefore be deployed zero-shot on real hardware without task-level fine-tuning or learned actuator models. The method reduces sim-to-real tracking error on a single-joint high-gear-ratio servo under external loads and improves zero-shot reaching performance on a 7-DOF arm, with further demonstrations on a wheeled-legged robot and a humanoid.
What carries the argument
The two-degree-of-freedom feedforward-feedback controller that shapes closed-loop physical actuator dynamics to an idealized second-order reference model.
If this is right
- Simulation-trained policies deploy directly on physical robots without fine-tuning or actuator modeling.
- Tracking error between simulation and reality drops substantially on both single-joint and multi-joint systems.
- Zero-shot transfer succeeds on wheeled-legged and humanoid platforms using the same reference model.
- The shaped actuator interface becomes reusable across diverse robot hardware.
Where Pith is reading between the lines
- Policies could transfer between robots of different designs if both apply the same shaping controller.
- The method could be layered with existing domain-randomization techniques to handle remaining uncertainties.
- It offers a route to standardize actuator behavior so that one training run serves multiple physical platforms.
- High-precision tasks such as grasping could be tested to check whether the shaped dynamics preserve the required accuracy.
Load-bearing premise
The controller can force real actuators to follow the idealized reference dynamics across varying loads and hardware without introducing unmodeled effects that degrade policy performance.
What would settle it
A policy trained only with the reference model either succeeds at the target task on real hardware when the shaping controller is active or fails to do so under the same loads when the controller is removed.
Figures


read the original abstract
Sim-to-real transfer in robot learning is often limited by discrepancies between the ideal actuator dynamics assumed during policy training and the nonlinear, hardware-dependent behavior of physical motors. While conventional approaches attempt to bridge this gap by increasing simulator fidelity through system identification, domain randomization, or learned actuator models, we introduce an alternative paradigm: actuator reality shaping. Instead of modifying the simulator to match the real world, our method shapes the closed-loop behavior of physical actuators to match the idealized second-order reference dynamics used in simulation. By equipping each joint with a two-degree-of-freedom feedforward--feedback controller, we decouple reference-response shaping from robust stabilization, thereby providing a standardized actuator interface for reinforcement learning policies. As a result, policies trained only with the prescribed reference model can be deployed zero-shot on real hardware without task-level fine-tuning or learned actuator models. We validate the approach on a single-joint high-gear-ratio servo under external loads and a 7-DOF robotic arm reaching task, where actuator reality shaping substantially reduces sim-to-real tracking error and improves zero-shot task performance compared with standard servo-control and representative real-to-sim-to-real baselines. We further demonstrate zero-shot transfer on a wheeled-legged robot driving over a slope and a humanoid robot walking, suggesting that actuator reality shaping can serve as a reusable interface for robot learning across diverse hardware platforms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes actuator reality shaping: a two-degree-of-freedom feedforward-feedback controller is placed around each physical joint to force its closed-loop response to match an idealized second-order reference model used during simulation-based RL policy training. The resulting standardized actuator interface is claimed to enable zero-shot deployment of policies trained exclusively against the reference model, without task-level fine-tuning or learned actuator models. Validation is reported on a single-joint high-gear-ratio servo under external loads, a 7-DOF arm reaching task, a wheeled-legged robot on a slope, and a humanoid walking task, with reported reductions in tracking error and improved task performance versus standard servo control and real-to-sim-to-real baselines.
Significance. If the controller reliably produces closed-loop trajectories indistinguishable from the reference model across loads and platforms, the method supplies a reusable, hardware-agnostic actuator interface that could simplify sim-to-real transfer by avoiding domain randomization or system identification. The multi-platform demonstrations constitute a concrete strength. The approach is internally consistent with standard 2DOF control design and does not rely on circular fitting of parameters from evaluation data.
major comments (3)
- [Abstract / single-joint validation] Abstract and single-joint validation section: the central zero-shot claim requires that residual dynamics after shaping remain negligible for arbitrary external loads, yet the reported evidence consists only of task-level performance metrics; no Bode plots, step-response overlays, or load-sweep error statistics are supplied to confirm that the closed-loop transfer function matches the idealized second-order reference under the tested loads.
- [7-DOF arm reaching task / wheeled-legged and humanoid demonstrations] 7-DOF arm and multi-platform sections: the claim that policies trained solely against the reference model transfer without fine-tuning rests on the assumption that the nominal feedforward inverse remains accurate despite load-dependent parameter drift (inertia, friction, backlash); the manuscript provides no quantitative bound on the resulting distribution shift or stability margin under varying payloads.
- [Actuator reality shaping / controller design] Controller design description: while the 2DOF structure decouples shaping from stabilization in nominal conditions, the feedforward compensation is necessarily based on a fixed inverse model; any unmodeled higher-order poles or load-induced variation produces a residual transfer function that the zero-shot argument does not bound or mitigate.
minor comments (2)
- [Controller design] Notation for the reference model parameters and the 2DOF controller gains should be introduced with explicit equations rather than descriptive text to allow reproduction.
- [Abstract] The abstract states 'substantially reduces sim-to-real tracking error' without defining the baseline tracking metric or reporting numerical values; a table summarizing error statistics across platforms would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for major revision. We address each major comment point-by-point below, agreeing to revisions that enhance the clarity and evidence for our claims where appropriate.
read point-by-point responses
-
Referee: [Abstract / single-joint validation] Abstract and single-joint validation section: the central zero-shot claim requires that residual dynamics after shaping remain negligible for arbitrary external loads, yet the reported evidence consists only of task-level performance metrics; no Bode plots, step-response overlays, or load-sweep error statistics are supplied to confirm that the closed-loop transfer function matches the idealized second-order reference under the tested loads.
Authors: We agree that providing direct evidence of the closed-loop transfer function matching the reference model under load would better support the zero-shot claim. Although the single-joint section reports tracking performance under external loads, we will revise the manuscript to include step-response overlays and load-sweep error statistics. This will explicitly demonstrate the alignment with the idealized second-order dynamics. revision: yes
-
Referee: [7-DOF arm reaching task / wheeled-legged and humanoid demonstrations] 7-DOF arm and multi-platform sections: the claim that policies trained solely against the reference model transfer without fine-tuning rests on the assumption that the nominal feedforward inverse remains accurate despite load-dependent parameter drift (inertia, friction, backlash); the manuscript provides no quantitative bound on the resulting distribution shift or stability margin under varying payloads.
Authors: The successful zero-shot deployments on the 7-DOF arm, wheeled-legged robot, and humanoid provide empirical support for the transfer without fine-tuning. We acknowledge that explicit quantitative bounds on distribution shift due to payload variations are not provided. In the revised manuscript, we will include additional discussion and, where possible, quantitative analysis of tracking errors under different conditions to address stability margins. revision: partial
-
Referee: [Actuator reality shaping / controller design] Controller design description: while the 2DOF structure decouples shaping from stabilization in nominal conditions, the feedforward compensation is necessarily based on a fixed inverse model; any unmodeled higher-order poles or load-induced variation produces a residual transfer function that the zero-shot argument does not bound or mitigate.
Authors: The design intentionally uses the 2DOF structure to achieve shaping while the feedback loop mitigates variations. The multi-platform experiments serve as validation that residuals are manageable for the demonstrated tasks. We will expand the controller design section to better explain how the approach mitigates residuals and acknowledge the limitations of the fixed inverse model for extreme load variations. revision: yes
Circularity Check
No significant circularity; claims rest on independent hardware validation
full rationale
The paper defines actuator reality shaping via an explicit 2DOF feedforward-feedback controller that is designed to enforce closed-loop matching to a prescribed second-order reference model; policies are then trained exclusively against that reference in simulation and transferred zero-shot. Validation consists of separate physical experiments (single-joint servo under load, 7-DOF arm, wheeled-legged robot, humanoid) that measure tracking error and task success, none of which are used to fit the controller parameters or the reference model itself. No equation or claim reduces the reported performance gain to a quantity fitted from the evaluation data, nor does any central premise rest on a self-citation whose content is unverified. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A two-degree-of-freedom controller can decouple reference tracking from robust stabilization on physical actuators under external loads.
Reference graph
Works this paper leans on
-
[1]
J. Hwangbo, J. Lee, A. Dosovitskiy, D. Bellicoso, V . Tsounis, V . Koltun, and M. Hutter. Learn- ing agile and dynamic motor skills for legged robots.Science Robotics, 4(26):eaau5872, 2019. doi:10.1126/scirobotics.aau5872
-
[2]
A. Kumar, Z. Fu, D. Pathak, and J. Malik. RMA: Rapid motor adaptation for legged robots. Robotics: Science and Systems, 2021. doi:10.15607/RSS.2021.XVII.011
-
[3]
Schulman, F
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov. Proximal policy optimization algorithms, 2017
2017
-
[4]
Grandia, E
R. Grandia, E. Knoop, M. A. Hopkins, G. Wiedebach, J. Bishop, S. Pickles, D. M ¨uller, and M. B¨acher. Design and control of a bipedal robotic character. InRobotics: Science and Systems (RSS), 2024
2024
-
[5]
Z. Fu, Q. Zhao, Q. Wu, G. Wetzstein, and C. Finn. HumanPlus: Humanoid shadowing and imitation from humans. InConference on Robot Learning (CoRL), 2024
2024
-
[6]
Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World,
J. Tobin, R. Fong, A. Ray, J. Schneider, W. Zaremba, and P. Abbeel. Domain randomization for transferring deep neural networks from simulation to the real world. In2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 23–30, 2017. doi: 10.1109/IROS.2017.8202133
-
[7]
Solving Rubik's Cube with a Robot Hand
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, J. Schneider, N. Tezak, J. Tworek, P. Welinder, L. Weng, Q. Yuan, W. Zaremba, and L. Zhang. Solving Rubik’s Cube with a Robot Hand. arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[8]
F. Bjelonic, F. Tischhauser, and M. Hutter. Towards bridging the gap: Systematic sim-to-real transfer for diverse legged robots.arXiv preprint arXiv:2509.06342, 2025
-
[9]
T. Sugie and T. Yoshikawa. General solution of robust tracking problem in two-degree-of- freedom control systems.IEEE Transactions on Automatic Control, 31(6):552–554, 1986. doi:10.1109/TAC.1986.1104337
-
[10]
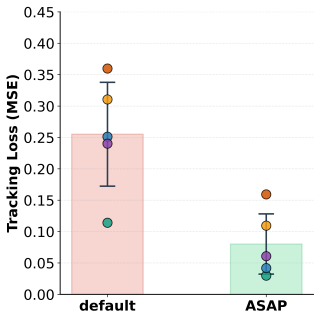
T. He, J. Gao, W. Xiao, Y . Zhang, Z. Wang, J. Wang, Z. Luo, G. He, N. Sobanbabu, C. Pan, Z. Yi, G. Qu, K. Kitani, J. Hodgins, L. Fan, Y . Zhu, C. Liu, and G. Shi. ASAP: Aligning simulation and real-world physics for learning agile humanoid whole-body skills. InRobotics: Science and Systems (RSS), 2025. 9
2025
-
[11]
X. B. Peng, M. Andrychowicz, W. Zaremba, and P. Abbeel. Sim-to-real transfer of robotic control with dynamics randomization. In2018 IEEE International Conference on Robotics and Automation (ICRA), pages 3803–3810, 2018. doi:10.1109/ICRA.2018.8460528
-
[12]
J. Tan, T. Zhang, E. Coumans, A. Iscen, Y . Bai, D. Hafner, S. Bohez, and V . Vanhoucke. Sim- to-Real: Learning agile locomotion for quadruped robots. InProceedings of Robotics: Science and Systems XIV, 2018. doi:10.15607/RSS.2018.XIV .010
-
[13]
M. Andrychowicz, B. Baker, M. Chociej, R. J ´ozefowicz, B. McGrew, J. Pachocki, A. Petron, M. Plappert, G. Powell, A. Ray, J. Schneider, S. Sidor, J. Tobin, P. Welinder, L. Weng, and W. Zaremba. Learning dexterous in-hand manipulation.The International Journal of Robotics Research, 39(1):3–20, 2020. doi:10.1177/0278364919887447
-
[14]
Y . Chebotar, A. Handa, V . Makoviychuk, M. Macklin, J. Issac, N. Ratliff, and D. Fox. Closing the Sim-to-Real loop: Adapting simulation randomization with real world experience. In2019 International Conference on Robotics and Automation (ICRA), pages 8973–8979, 2019. doi: 10.1109/ICRA.2019.8793789
-
[15]
J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning quadrupedal lo- comotion over challenging terrain.Science Robotics, 5(47):eabc5986, 2020. doi:10.1126/ scirobotics.abc5986
2020
-
[16]
T. Miki, J. Lee, J. Hwangbo, L. Wellhausen, V . Koltun, and M. Hutter. Learning robust percep- tive locomotion for quadrupedal robots in the wild.Science Robotics, 7(62):eabk2822, 2022. doi:10.1126/scirobotics.abk2822
-
[17]
J.-J. E. Slotine and W. Li.Applied Nonlinear Control. Prentice Hall, Englewood Cliffs, New Jersey, USA, 1991
1991
-
[18]
K. J. ˚Astr¨om and B. Wittenmark.Adaptive Control. Dover Publications, 2nd edition, 2008
2008
-
[19]
Morimoto and C
J. Morimoto and C. G. Atkeson. Minimax differential dynamic programming: An application to robust biped walking. In S. Becker, S. Thrun, and K. Obermayer, editors,Advances in Neural Information Processing Systems, volume 15, pages 1563–1570, Vancouver, British Columbia, Canada, 2002. MIT Press
2002
-
[20]
Morimoto and C
J. Morimoto and C. G. Atkeson. Nonparametric representation of an approximated Poincar ´e map for learning biped locomotion.Autonomous Robots, 27(2):131–144, 2009. doi:10.1007/ s10514-009-9133-z
2009
-
[21]
W. Yu, J. Tan, C. K. Liu, and G. Turk. Preparing for the unknown: Learning a universal policy with online system identification. In N. M. Amato, S. S. Srinivasa, N. Ayanian, and S. Kuinder- sma, editors,Proceedings of Robotics: Science and Systems XIII, Cambridge, Massachusetts, USA, 2017. doi:10.15607/RSS.2017.XIII.048
-
[22]
W. Yu, V . C. V . Kumar, G. Turk, and C. K. Liu. Sim-to-real transfer for biped locomotion. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3503–3510, Macau, China, 2019. IEEE. doi:10.1109/IROS40897.2019.8968053
-
[23]
X. B. Peng, E. Coumans, T. Zhang, T.-W. E. Lee, J. Tan, and S. Levine. Learning agile robotic locomotion skills by imitating animals. InProceedings of Robotics: Science and Systems XVI, Held Virtually, 2020. doi:10.15607/RSS.2020.XVI.064
-
[24]
Araki and H
M. Araki and H. Taguchi. Two-degree-of-freedom PID controllers.International Journal of Control, Automation, and Systems, 1(4):401–411, 2003
2003
-
[25]
T. Umeno and Y . Hori. Robust speed control of DC servomotors using modern two degrees-of- freedom controller design.IEEE Transactions on Industrial Electronics, 38(5):363–368, 1991. doi:10.1109/41.97556. 10
-
[26]
K. Ohishi, M. Nakao, K. Ohnishi, and K. Miyachi. Microprocessor-controlled DC motor for load-insensitive position servo system.IEEE Transactions on Industrial Electronics, IE-34(1): 44–49, 1987. doi:10.1109/TIE.1987.350923
-
[27]
E. Sariyildiz and K. Ohnishi. Stability and robustness of disturbance-observer-based motion control systems.IEEE Transactions on Industrial Electronics, 62(1):414–422, 2015. doi: 10.1109/TIE.2014.2327009
-
[28]
W.-H. Chen, J. Yang, L. Guo, and S. Li. Disturbance-observer-based control and related methods—An overview.IEEE Transactions on Industrial Electronics, 63(2):1083–1095, 2016. doi:10.1109/TIE.2015.2478397
-
[29]
Isaac Sim
NVIDIA. Isaac Sim. URLhttps://github.com/isaac-sim/IsaacSim
-
[30]
Makoviychuk, L
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State. Isaac Gym: High Performance GPU-Based Physics Simulation for Robot Learning. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, 2021
2021
-
[31]
M. Mittal, C. Yu, Q. Yu, J. Liu, N. Rudin, D. Hoeller, J. L. Yuan, R. Singh, Y . Guo, H. Mazhar, A. Mandlekar, B. Babich, G. Birchfield, M. Hutter, and A. Garg. Orbit: A unified simulation framework for interactive robot learning environments.IEEE Robotics and Automation Letters, 8(6):3740–3747, 2023. doi:10.1109/LRA.2023.3270034
-
[32]
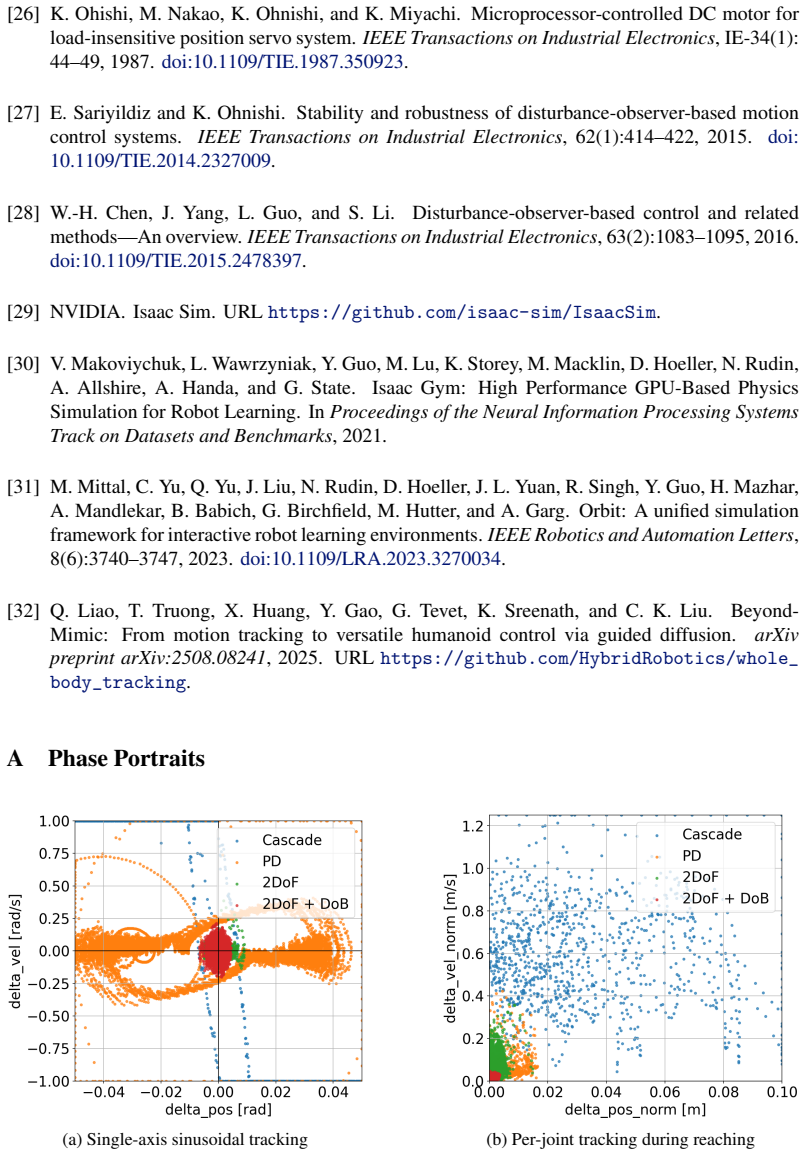
Q. Liao, T. Truong, X. Huang, Y . Gao, G. Tevet, K. Sreenath, and C. K. Liu. Beyond- Mimic: From motion tracking to versatile humanoid control via guided diffusion.arXiv preprint arXiv:2508.08241, 2025. URLhttps://github.com/HybridRobotics/whole_ body_tracking. A Phase Portraits (a) Single-axis sinusoidal tracking (b) Per-joint tracking during reaching Fi...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.