Expectation Consistency Loss: Rethink Confidence Calibration under Covariate Shift
Pith reviewed 2026-05-22 00:42 UTC · model grok-4.3
The pith
The expectation consistency condition is necessary and sufficient for confidence calibration under covariate shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
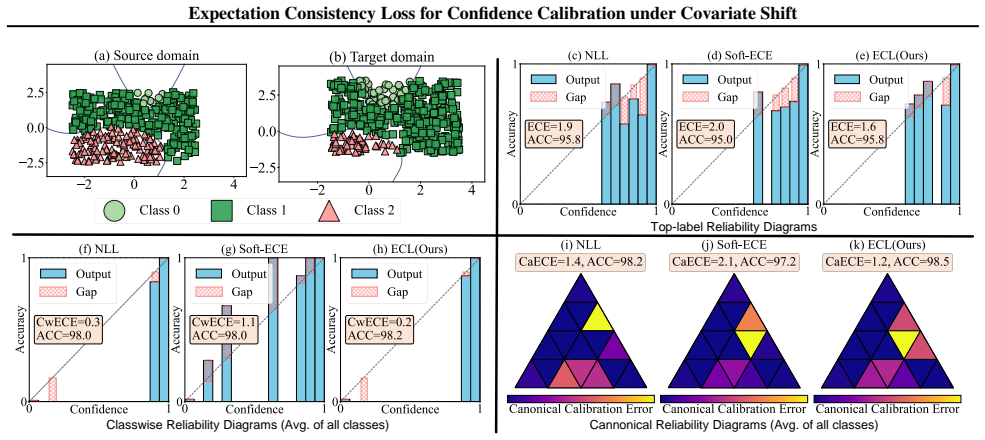
The expectation consistency condition is necessary and sufficient for confidence calibration under covariate shifts. It reveals that covariate shifts do not necessarily produce uncalibrated models and supplies a weaker requirement than global alignment of the covariate distributions. The expectation consistency loss then uses only unlabeled target samples to enforce the condition while preserving compatibility with multiple calibration definitions.
What carries the argument
Expectation consistency condition, requiring that the expected value of the model's predicted probability for the true label equals the expected value of the correctness indicator under the target distribution.
If this is right
- Calibration can hold under covariate shift without requiring the training and test covariate distributions to be identical.
- The expectation consistency loss supports canonical calibration, class-wise calibration, and top-label calibration.
- The sample complexity of computing the expectation consistency loss equals that of computing expected calibration error.
- A mini-batch scheme for training with the expectation consistency loss is supported by matching theoretical guarantees.
Where Pith is reading between the lines
- Enforcing only expectation consistency may let practitioners avoid unstable density-ratio estimates that break down under large shifts.
- The same consistency idea could be adapted to create unsupervised calibration methods for other shift types such as label shift.
- Linking calibration directly to domain-adaptation objectives may improve reliability when models are deployed in changing real-world environments.
Load-bearing premise
The derivation assumes the covariate shift preserves the conditional label distribution so that expectations over the target domain can be estimated from unlabeled samples without density-ratio bounds or support restrictions.
What would settle it
A concrete dataset or simulation in which expectation consistency holds yet calibration error remains high, or in which consistency fails yet calibration holds, under a covariate shift that leaves the conditional label distribution unchanged.
Figures


read the original abstract
Confidence calibration for classification models is vital in safety-critical decision-making scenarios and has received extensive attention. General confidence calibration methods assume training and test data are independent and identically distributed, limiting their effectiveness under covariate shifts. Previous calibration methods under covariate shift struggle with class-wise or canonical calibrations and often rely on unstable importance weighting when density ratios are large or unbounded. Given the above limitations, this paper rethinks confidence calibration under covariate shifts. First, we derive a necessary and sufficient condition for confidence calibration under covariate shifts, named Expectation consistency condition, which reveals covariate shifts do not necessarily lead to uncalibrated confidence and provides a weaker condition for confidence calibration than global covariate distribution alignment. Then, utilizing Expectation consistency condition, this paper proposes an unsupervised domain adaptation loss to calibrate confidence of the target domain, named Expectation consistency loss (ECL), which is compatible with canonical calibration, class-wise calibration, and top-label calibration. Third, we prove that computing ECL loss has the same sample complexity as Expected Calibration Error (ECE) and provide a theoretically grounded mini-batch trainable scheme for ECL loss. Finally, we validate the effectiveness of our method on both simulated and real-world covariate shift datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper derives a necessary and sufficient 'Expectation Consistency' condition for confidence calibration under covariate shift (weaker than global distribution alignment), proposes an unsupervised Expectation Consistency Loss (ECL) compatible with canonical, class-wise, and top-label calibration, proves that ECL has the same sample complexity as ECE, and validates the approach on simulated and real-world covariate-shift datasets.
Significance. If the necessity and sufficiency derivation holds under the stated assumptions, the work supplies a practical unsupervised calibration method that avoids unstable importance weighting and provides a strictly weaker condition than full covariate alignment; the matching sample-complexity result and mini-batch scheme are additional strengths.
major comments (2)
- [§3] §3 (derivation of necessity): the necessity direction equates an expectation over the target marginal to a source quantity using only P_s(Y|X)=P_t(Y|X); when target support is not contained in source support, the equality requires an explicit Radon-Nikodym factor or indicator on the overlap set that is omitted in the stated condition, so necessity does not follow from unlabeled target samples alone.
- [§4] Theorem on sample complexity (presumably §4): the claim that ECL has identical sample complexity to ECE is stated without the precise concentration inequalities or bounded-ratio assumptions needed to control the density-ratio-free estimator; the proof sketch should make these explicit.
minor comments (2)
- [§3] Notation for the expectation-consistency condition should be introduced with an explicit equation number and contrasted directly with the standard calibration definition E[1{Y=y}|f(X)=p]=p.
- [Experiments] The abstract states compatibility with canonical, class-wise, and top-label calibration, but the experimental section should report separate metrics for each rather than a single aggregate.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments highlight important points for rigor in the necessity derivation and the sample-complexity analysis. We address each major comment below and will revise the manuscript to incorporate the suggested clarifications.
read point-by-point responses
-
Referee: [§3] §3 (derivation of necessity): the necessity direction equates an expectation over the target marginal to a source quantity using only P_s(Y|X)=P_t(Y|X); when target support is not contained in source support, the equality requires an explicit Radon-Nikodym factor or indicator on the overlap set that is omitted in the stated condition, so necessity does not follow from unlabeled target samples alone.
Authors: We appreciate this observation on the support-overlap issue. The original derivation in §3 implicitly restricts attention to the common support of source and target distributions under the covariate-shift model. To make the necessity direction fully rigorous, we will revise §3 to explicitly include an indicator on the overlap set and note the role of the Radon-Nikodym derivative when the densities are unbounded. This clarification preserves the result that the expectation-consistency condition is necessary and sufficient on the relevant support while acknowledging that unlabeled target samples alone do not suffice outside the overlap. revision: yes
-
Referee: [§4] Theorem on sample complexity (presumably §4): the claim that ECL has identical sample complexity to ECE is stated without the precise concentration inequalities or bounded-ratio assumptions needed to control the density-ratio-free estimator; the proof sketch should make these explicit.
Authors: We agree that the sample-complexity argument in §4 requires more explicit technical detail. In the revised manuscript we will expand the proof to state the precise concentration inequalities (e.g., Hoeffding or Bernstein bounds) employed and to list the bounded-ratio or bounded-variance assumptions needed for the density-ratio-free estimator. These additions will render the claim that ECL matches the sample complexity of ECE fully rigorous. revision: yes
Circularity Check
Derivation of expectation consistency condition is self-contained from calibration definitions and covariate shift assumptions
full rationale
The paper derives the expectation consistency condition directly from the definition of confidence calibration (E[1{Y=y}|f(X)=p] = p) combined with the standard covariate shift assumption P_s(Y|X)=P_t(Y|X). This produces a mathematical equivalence that is not tautological or fitted; the resulting ECL loss is then defined from that condition rather than reverse-engineered to match data. No self-citation chain, ansatz smuggling, or renaming of known results is load-bearing for the central necessity/sufficiency claim. The derivation remains independent of the target result and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.1. (Expectation Consistency Condition) ∀1≤k≤K, Ps(Yk=1|S)=Pt(Yk=1|S) iff EX∼Ps(X|S)[P(Yk=1|X)]=EX∼Pt(X|S)[P(Yk=1|X)]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lecl = E_Pt(S) | E_Ps(X|S) P(Y|X) − E_Pt(X|S) P(Y|X) | (canonical form)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
cc/paper_files/paper/2010/file/ 59c33016884a62116be975a9bb8257e3- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2010/file/ 59c33016884a62116be975a9bb8257e3- Paper.pdf. Dong, J., Jiang, Z., Pan, D., Chen, Z., Guan, Q., Zhang, H., Gui, G., and Gui, W. A survey on confidence calibration of deep learning-based classification models under class imbalance data.IEEE Transactions on Neural Networks and Learning Systems,...
-
[2]
doi: 10.1007/s10462-023-10562-9. URL https: //doi.org/10.1007/s10462-023-10562-9. Grathwohl, W., Wang, K.-C., Jacobsen, J.-H., Duvenaud, D., Norouzi, M., and Swersky, K. Your classifier is secretly an energy based model and you should treat it like one. In International Conference on Learning Representations,
-
[3]
Guo, C., Pleiss, G., Sun, Y ., and Weinberger, K
URL https://openreview.net/forum? id=Hkxzx0NtDB. Guo, C., Pleiss, G., Sun, Y ., and Weinberger, K. Q. On cali- bration of modern neural networks. In Precup, D. and Teh, Y . W. (eds.),Proceedings of the 34th International Confer- ence on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pp. 1321–1330. PMLR, 06– 11 Aug 2017. URL https:...
work page 2017
-
[4]
URL https://www.sciencedirect.com/ science/article/pii/S0031320324001365
doi: https://doi.org/10.1016/j.patcog.2024.110385. URL https://www.sciencedirect.com/ science/article/pii/S0031320324001365. He, K., Zhang, X., Ren, S., and Sun, J. Deep residual learn- ing for image recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2016. Hebbalaguppe, R., Prakash, J., Madan, N., and...
-
[5]
cc/paper_files/paper/2021/file/ f8905bd3df64ace64a68e154ba72f24c- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2021/file/ f8905bd3df64ace64a68e154ba72f24c- Paper.pdf. Kimura, M. and Hino, H. A short survey on impor- tance weighting for machine learning.Transactions on Machine Learning Research, 2024. ISSN 2835-
work page 2021
-
[6]
URL https://openreview.net/forum? id=IhXM3g2gxg. Survey Certification. Kull, M., Perello Nieto, M., K ¨angsepp, M., Silva Filho, T., Song, H., and Flach, P. Beyond temperature scaling: Obtaining well-calibrated multi-class probabilities with dirichlet calibration. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alch ´e-Buc, F., Fox, E., and Garnett, R....
-
[7]
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 8ca01ea920679a0fe3728441494041b9- Paper.pdf. Lecun, Y ., Bottou, L., Bengio, Y ., and Haffner, P. Gradient- based learning applied to document recognition.Pro- ceedings of the IEEE, 86(11):2278–2324, 1998. doi: 10.1109/5.726791. LeCun, Y ., Bengio, Y ., and Hinton, G. Deep learning.Na- ture,...
-
[8]
URL https://aclanthology.org/2023. findings-acl.393/. Liu, B., Rony, J., Galdran, A., Dolz, J., and Ben Ayed, I. Class adaptive network calibration. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 16070–16079, June 2023. M¨uller, R., Kornblith, S., and Hinton, G. E. When does label smoothing help? In Wallach...
work page 2023
-
[9]
cc/paper_files/paper/2019/file/ f1748d6b0fd9d439f71450117eba2725- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ f1748d6b0fd9d439f71450117eba2725- Paper.pdf. Munir, M. A., Khan, S. H., Khan, M. H., Ali, M., and Shahbaz Khan, F. Cal-detr: Calibrated detection transformer. In Oh, A., Naumann, T., Globerson, A., Saenko, K., Hardt, M., and Levine, S. (eds.), Advances in Neural Information Processing System...
work page 2019
-
[10]
cc/paper_files/paper/2023/file/ e271e30de7a2e462ca1f85cefa816380- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2023/file/ e271e30de7a2e462ca1f85cefa816380- Paper-Conference.pdf. Netzer, Y ., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A. Y ., et al. Reading digits in natural images with unsupervised feature learning. InNIPS workshop on deep learning and unsupervised feature learning, volume 2011, pp. 7. Gra...
-
[11]
Popordanoska, T., Sayer, R., and Blaschko, M
URL https://proceedings.mlr.press/ v108/park20b.html. Popordanoska, T., Sayer, R., and Blaschko, M. A consistent and differentiable lp canonical calibration error estimator. In Koyejo, S., Mohamed, S., Agar- wal, A., Belgrave, D., Cho, K., and Oh, A. (eds.), Advances in Neural Information Processing Systems, volume 35, pp. 7933–7946. Curran Associates, In...
-
[12]
cc/paper_files/paper/2022/file/ 33d6e648ee4fb24acec3a4bbcd4f001e- Paper-Conference.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2022/file/ 33d6e648ee4fb24acec3a4bbcd4f001e- Paper-Conference.pdf. Rahimi, A., Shaban, A., Cheng, C.-A., Hartley, R., and Boots, B. Intra order-preserving functions for calibration of multi-class neural networks. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.), Advances in N...
work page 2022
-
[13]
cc/paper_files/paper/2020/file/ 9bc99c590be3511b8d53741684ef574c- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 9bc99c590be3511b8d53741684ef574c- Paper.pdf. Wang, H., Ge, S., Lipton, Z., and Xing, E. P. Learning robust global representations by penalizing local predictive power. In Wallach, H., Larochelle, H., Beygelzimer, A., d'Alch´e-Buc, F., Fox, E., and Garnett, R. (eds.),Advances in Neural Inform...
work page 2020
-
[14]
cc/paper_files/paper/2019/file/ 3eefceb8087e964f89c2d59e8a249915- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2019/file/ 3eefceb8087e964f89c2d59e8a249915- Paper.pdf. Wang, H., Yu, Z., Yue, Y ., Anandkumar, A., Liu, A., and Yan, J. Learning calibrated uncertainties for domain shift: a distributionally robust learning approach. In Proceedings of the Thirty-Second International Joint Conference on Artificial Inte...
-
[15]
URL https://doi.org/10.24963/ijcai. 2023/162. Wang, X., Long, M., Wang, J., and Jordan, M. Trans- ferable calibration with lower bias and variance in domain adaptation. In Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., and Lin, H. (eds.),Ad- vances in Neural Information Processing Systems, volume 33, pp. 19212–19223. Curran Associates, Inc.,
-
[16]
cc/paper_files/paper/2020/file/ df12ecd077efc8c23881028604dbb8cc- Paper.pdf
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ df12ecd077efc8c23881028604dbb8cc- Paper.pdf. Yang, X. and Ji, S. Jem++: Improved techniques for train- ing jem. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 6494–6503, October 2021. Zagoruyko, S. and Komodakis, N. Wide residual networks. InProcedings ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.