A Generalization Theory for JEPA-Based World Models
Pith reviewed 2026-06-26 05:36 UTC · model grok-4.3
The pith
JEPA pretraining error connects to planning regret through low-rank factorization, producing finite-sample generalization bounds for world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate JEPA pretraining as a conditional spectral graph learning problem and show that the JEPA objective is equivalent to a low-rank factorization of an action-conditioned co-occurrence matrix. Building on this characterization, we establish a connection between JEPA pretraining error and downstream planning regret, leading to a finite-sample generalization bound for JEPA-based world models. Our analysis reveals an inherent trade-off between approximation and sample errors with respect to the latent dimension.
What carries the argument
The equivalence of the JEPA objective to low-rank factorization of an action-conditioned co-occurrence matrix, obtained by casting pretraining as conditional spectral graph learning.
If this is right
- JEPA-based world models admit finite-sample generalization bounds that tie pretraining performance to planning regret.
- The bound exhibits a trade-off between approximation error and sample error controlled by the choice of latent dimension.
- Latent predictive models possess specific advantages and limitations relative to input-level predictive approaches.
- The connection supplies a theoretical route to predict downstream planning performance from pretraining error alone.
Where Pith is reading between the lines
- Practitioners could use the bound to select latent dimension by estimating the point where approximation and sample errors balance for a given data budget.
- Similar matrix-factorization equivalences might be sought for other latent predictive architectures to obtain analogous regret bounds.
- The theory suggests that increasing latent dimension beyond a certain point may degrade planning performance under limited samples even if reconstruction improves.
Load-bearing premise
JEPA pretraining can be formulated as a conditional spectral graph learning problem whose objective is exactly equivalent to low-rank factorization of an action-conditioned co-occurrence matrix.
What would settle it
A concrete counter-example would be a planning task in which measured regret grows faster than the derived bound as the number of pretraining samples increases while holding latent dimension fixed.
Figures
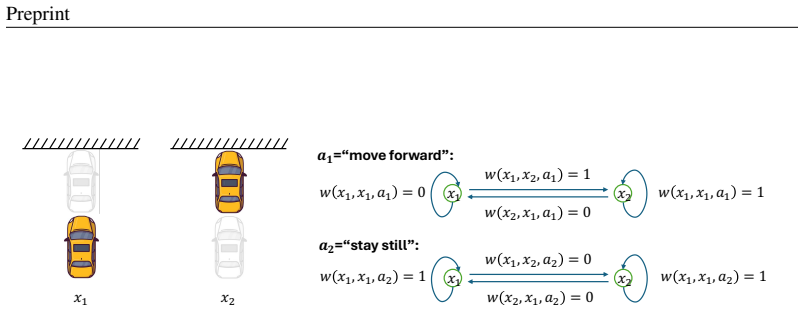
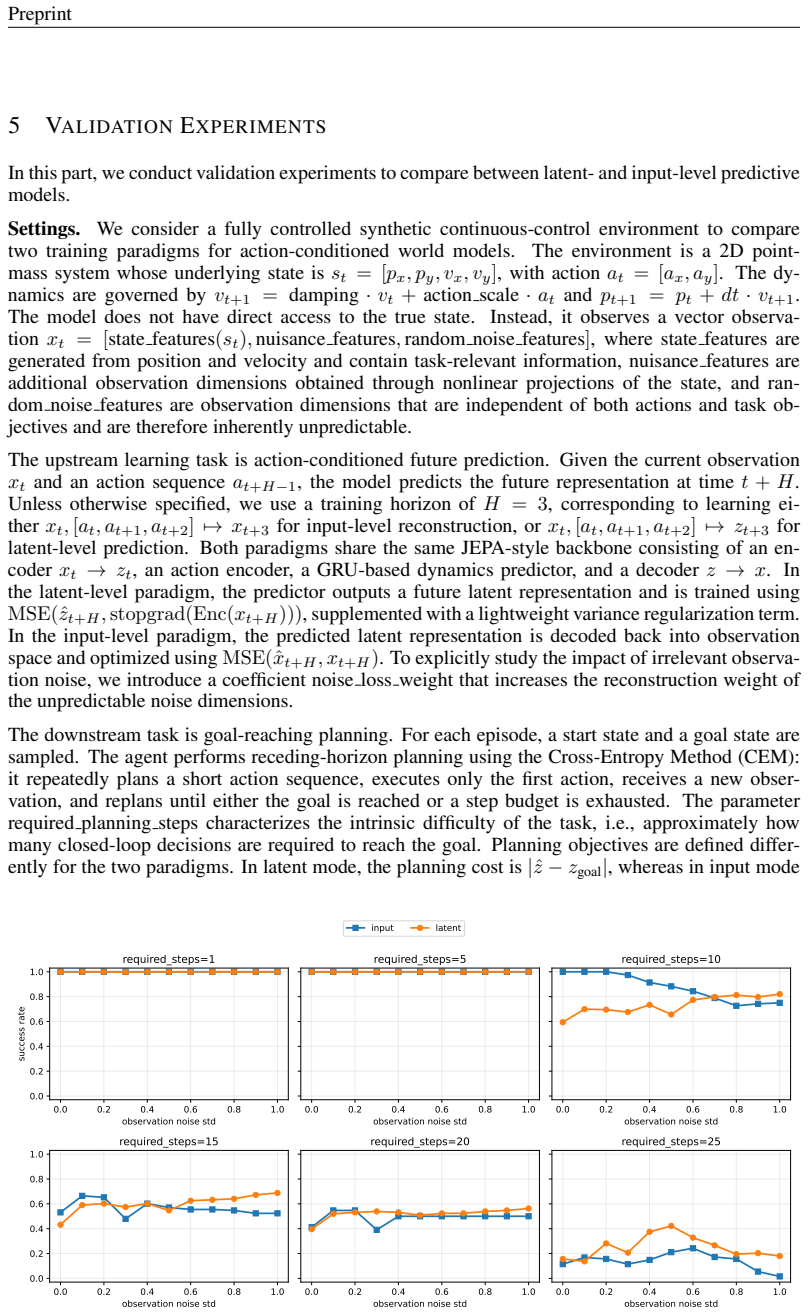
read the original abstract
Joint Embedding Predictive Architectures (JEPAs) have recently emerged as a promising paradigm for world modeling by learning predictive dynamics in a latent space rather than generating future observations at the input level. Despite their empirical success, the theoretical understanding of JEPA-based world models remains limited. In this paper, we develop the first generalization theory for JEPA-based world models. We formulate JEPA pretraining as a conditional spectral graph learning problem and show that the JEPA objective is equivalent to a low-rank factorization of an action-conditioned co-occurrence matrix. Building on this characterization, we establish a connection between JEPA pretraining error and downstream planning regret, leading to a finite-sample generalization bound for JEPA-based world models. Our analysis reveals an inherent trade-off between approximation and sample errors with respect to the latent dimension, providing theoretical insights into the advantages and limitations of latent predictive models compared with input-level predictive approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to develop the first generalization theory for JEPA-based world models. It formulates JEPA pretraining as a conditional spectral graph learning problem whose objective is exactly equivalent to low-rank factorization of an action-conditioned co-occurrence matrix. Building on this, it connects JEPA pretraining error to downstream planning regret and derives a finite-sample generalization bound, revealing an inherent trade-off between approximation and sample errors with respect to the latent dimension.
Significance. If the claimed equivalence and regret connection hold rigorously, the work would supply the first theoretical account of why latent-space predictive models like JEPA can outperform input-level predictors for planning, including explicit guidance on latent-dimension selection.
major comments (1)
- [Abstract (JEPA pretraining characterization)] The central claim rests on the exact equivalence between the JEPA objective and low-rank factorization of the action-conditioned co-occurrence matrix (stated in the abstract as following from the conditional spectral graph learning formulation). If this equivalence holds only approximately or under unstated restrictions on graph construction, normalization, or the predictive loss, the subsequent mapping from pretraining error to planning regret cannot be rigorous and the finite-sample bound does not follow.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for identifying the centrality of the equivalence claim. Below we address the concern directly by reference to the manuscript's derivations.
read point-by-point responses
-
Referee: [Abstract (JEPA pretraining characterization)] The central claim rests on the exact equivalence between the JEPA objective and low-rank factorization of the action-conditioned co-occurrence matrix (stated in the abstract as following from the conditional spectral graph learning formulation). If this equivalence holds only approximately or under unstated restrictions on graph construction, normalization, or the predictive loss, the subsequent mapping from pretraining error to planning regret cannot be rigorous and the finite-sample bound does not follow.
Authors: The equivalence is exact. Section 3 derives the JEPA objective from the conditional spectral graph learning formulation and shows, via direct algebraic manipulation of the loss (Equations 4–7), that it is identical to the low-rank factorization objective on the action-conditioned co-occurrence matrix. Graph construction, normalization (row-stochastic transition probabilities), and the predictive loss are all stated explicitly in Definitions 1–2 and Assumption 1; no approximations are introduced. Because the equivalence is identity-level, the subsequent regret connection (Theorem 4) and finite-sample bound (Theorem 5) follow directly without additional error terms. revision: no
Circularity Check
No significant circularity in derivation chain
full rationale
The paper derives an equivalence between the JEPA objective and low-rank factorization of an action-conditioned co-occurrence matrix via conditional spectral graph learning, then connects pretraining error to planning regret to obtain a finite-sample bound. No load-bearing step reduces by construction to its inputs, no fitted parameter is renamed as a prediction, and no self-citation chain is invoked as the sole justification for a uniqueness result or ansatz. The derivation is presented as self-contained mathematical work with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption JEPA pretraining can be formulated as a conditional spectral graph learning problem
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.05949 , year=
Gaussian embeddings: How jepas secretly learn your data density , author=. arXiv preprint arXiv:2510.05949 , year=
-
[2]
arXiv preprint arXiv:2511.08544 , year=
Lejepa: Provable and scalable self-supervised learning without the heuristics , author=. arXiv preprint arXiv:2511.08544 , year=
-
[3]
arXiv preprint arXiv:2506.09985 , year=
V-jepa 2: Self-supervised video models enable understanding, prediction and planning , author=. arXiv preprint arXiv:2506.09985 , year=
-
[4]
arXiv preprint arXiv:2512.10942 , year=
Vl-jepa: Joint embedding predictive architecture for vision-language , author=. arXiv preprint arXiv:2512.10942 , year=
-
[5]
arXiv preprint arXiv:2603.19312 , year=
Leworldmodel: Stable end-to-end joint-embedding predictive architecture from pixels , author=. arXiv preprint arXiv:2603.19312 , year=
-
[6]
NeurIPS , year=
Provable guarantees for self-supervised deep learning with spectral contrastive loss , author=. NeurIPS , year=
-
[7]
ICML , year=
Look Ahead or Look Around? A Theoretical Comparison Between Autoregressive and Masked Pretraining , author=. ICML , year=
-
[8]
CVPR , year=
Self-supervised learning from images with a joint-embedding predictive architecture , author=. CVPR , year=
-
[9]
V-jepa: Latent video prediction for visual representation learning , author=
-
[10]
2, 2022-06-27 , author=
A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27 , author=. Open Review , volume=
2022
-
[11]
NeurIPS , year=
How jepa avoids noisy features: The implicit bias of deep linear self distillation networks , author=. NeurIPS , year=
-
[12]
arXiv preprint arXiv:2605.26379 , year=
When Does LeJEPA Learn a World Model? , author=. arXiv preprint arXiv:2605.26379 , year=
-
[13]
Difficult Examples Hurt Unsupervised Contrastive Learning: A Theoretical Perspective , author=
-
[14]
ICML , year=
Connect, not collapse: Explaining contrastive learning for unsupervised domain adaptation , author=. ICML , year=
-
[15]
ICML , year=
Rethinking weak supervision in helping contrastive learning , author=. ICML , year=
-
[16]
ICML , year=
On the generalization of multi-modal contrastive learning , author=. ICML , year=
-
[17]
arXiv preprint arXiv:2411.04983 , year=
Dino-wm: World models on pre-trained visual features enable zero-shot planning , author=. arXiv preprint arXiv:2411.04983 , year=
-
[18]
IEEE Signal Processing Magazine , volume=
Spectral Graph Theory: The mathematics of self-supervised learning [Special Issue on the Mathematics of Deep Learning] , author=. IEEE Signal Processing Magazine , volume=. 2026 , publisher=
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.