When Does LeJEPA Learn a World Model?
Pith reviewed 2026-06-29 20:06 UTC · model grok-4.3
The pith
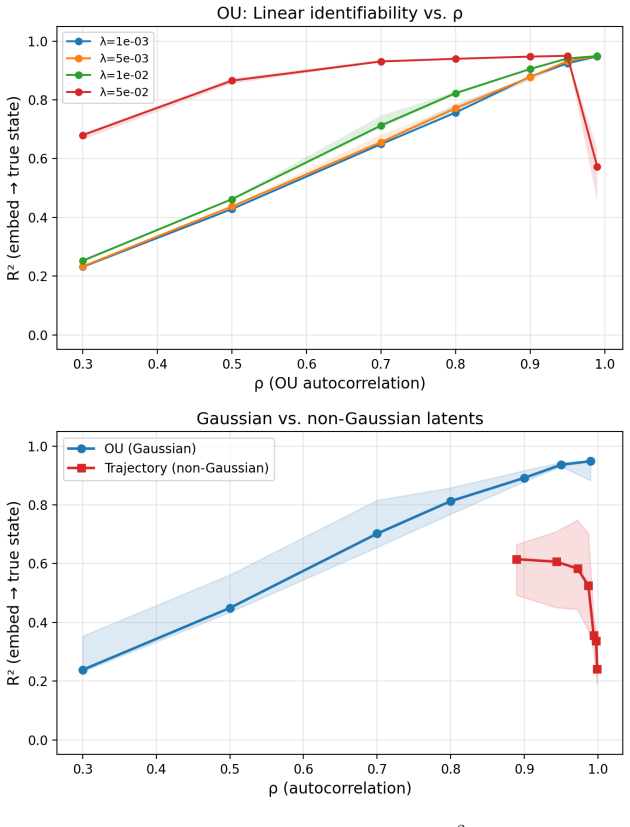
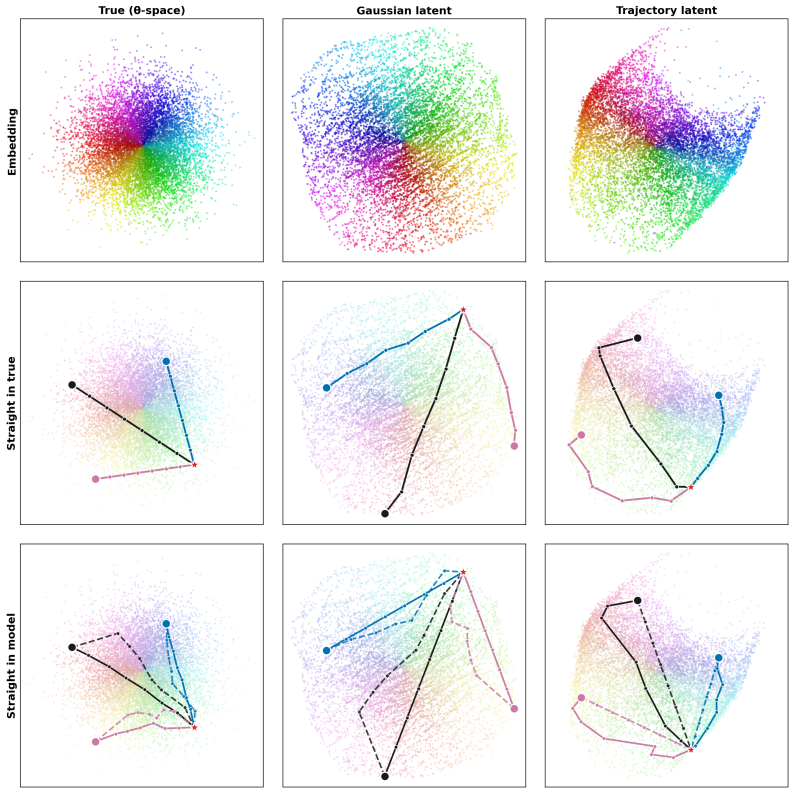
LeJEPA linearly recovers the world's latent variables from nonlinear observations precisely when the latents are Gaussian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
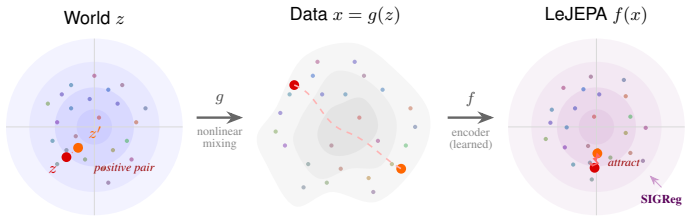
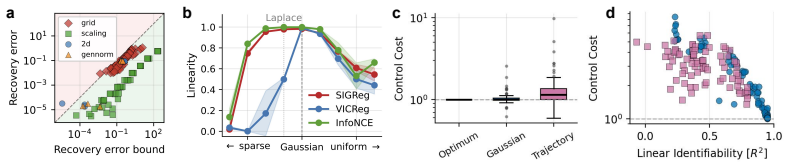
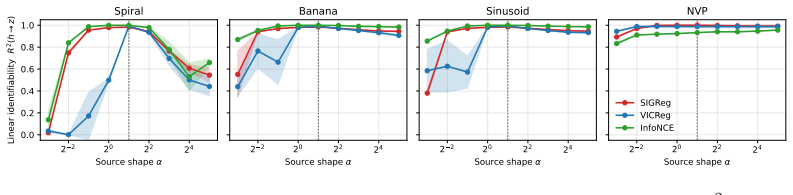
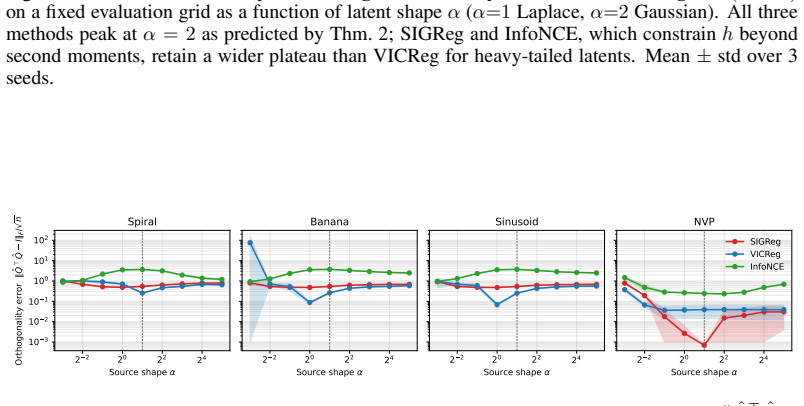
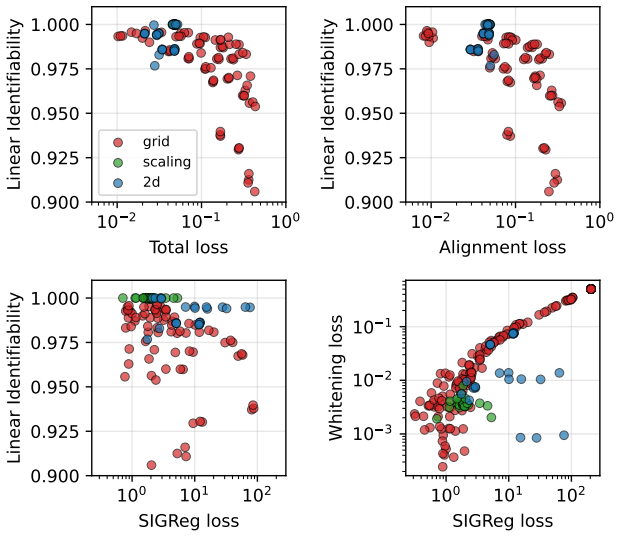
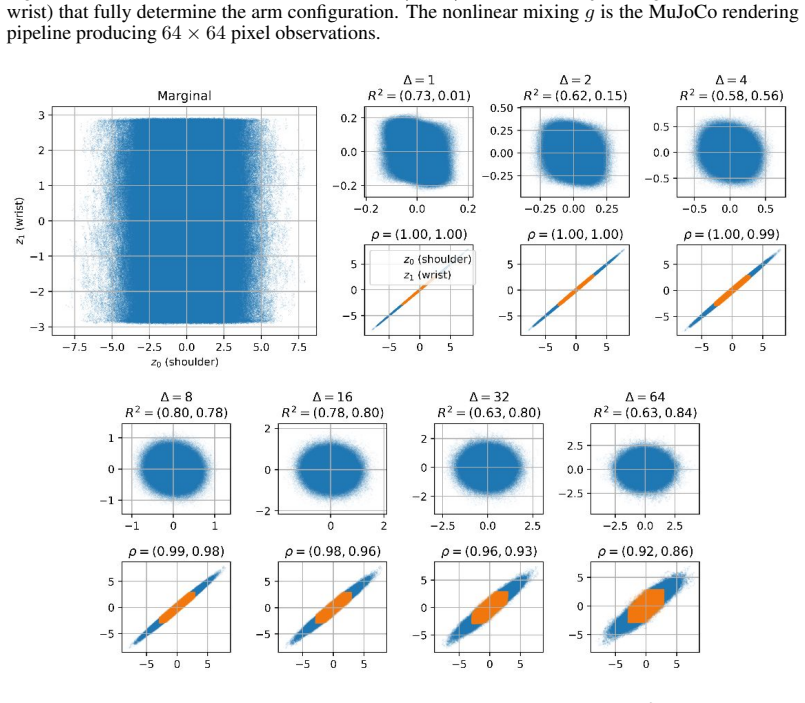
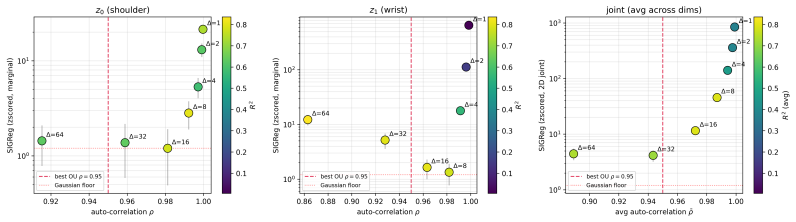
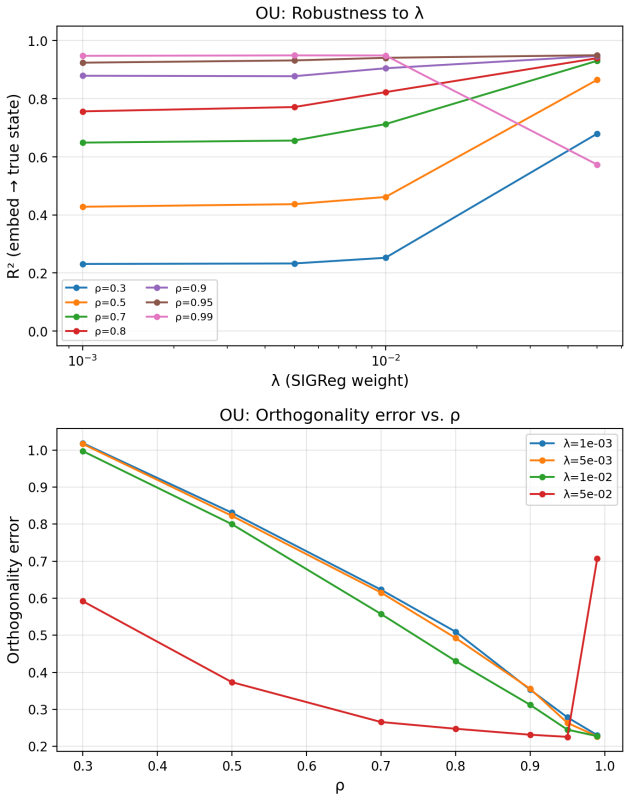
LeJEPA (alignment plus Gaussian regularization) linearly recovers the world's latent variables from nonlinear observations in worlds where latents evolve under stationary additive-noise transitions. The central result is that the Gaussian is the unique latent distribution for which this linear identifiability holds. The forward direction follows from a spectral decomposition in which alignment strictly penalizes nonlinearity, rendering the linear map optimal; the converse rules out every non-Gaussian alternative. An approximate identifiability result is also proved, and linear orthogonal identifiability is shown to enable optimal latent-space planning.
What carries the argument
LeJEPA's alignment objective with Gaussian regularization, which enforces linear identifiability through spectral decomposition that penalizes nonlinearity.
If this is right
- Linear identifiability supports reliable planning directly in the recovered latent space.
- The guarantee applies across a broad class of worlds with stationary additive-noise transitions.
- An approximate version of the result allows the guarantee to degrade gracefully with distribution mismatch.
- Orthogonal linear identifiability enables optimal latent-space planning.
- The theory converts an empirical recipe into a mathematical guarantee for world-model structure recovery.
Where Pith is reading between the lines
- Designers of other self-supervised objectives for world models could incorporate similar Gaussian regularization to target identifiability.
- Testing whether learned latents in deployed models are approximately Gaussian could serve as a practical diagnostic for planning reliability.
- Extensions to non-stationary or multiplicative noise transitions would require new proof techniques beyond the current spectral argument.
- The result connects to broader questions in causal representation learning about when nonlinear observations can be inverted to linear latent structure.
Load-bearing premise
The latent variables evolve under stationary additive-noise transitions.
What would settle it
A non-Gaussian latent distribution under stationary additive-noise transitions where LeJEPA nevertheless achieves exact linear identifiability would falsify the uniqueness claim.
Figures






read the original abstract
A representation that scrambles the true degrees of freedom of the world cannot support reliable planning or compositional generalization. We prove that LeJEPA (alignment plus Gaussian regularization) linearly recovers the world's latent variables from nonlinear observations, a property known as linear identifiability, in a broad class of worlds where latents evolve under stationary, additive-noise transitions. Our main result is that among all such worlds, the Gaussian is the unique latent distribution for which this guarantee holds. The forward direction rests on a spectral decomposition in which each degree of nonlinearity is strictly penalized by alignment, making the linear map the optimum; the converse rules out every non-Gaussian alternative. We further prove an approximate identifiability result where the guarantee degrades gracefully, and show that linear, orthogonal identifiability enables optimal latent-space planning. We validate the theory with experiments ranging from 2D examples to 1024-dimensional latents, including distributional ablations and pixel-based robotic control. Our theory turns an empirically successful recipe into a mathematical guarantee, providing the foundation for building World Models that provably recover the structure of the world.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to prove that LeJEPA (alignment plus Gaussian regularization) linearly recovers latent variables from nonlinear observations under stationary additive-noise transitions, with Gaussian as the unique latent distribution enabling this linear identifiability. The forward direction uses a spectral decomposition penalizing nonlinearity, the converse rules out non-Gaussians, an approximate version is shown, and linear identifiability is linked to optimal planning; experiments from 2D to 1024D latents plus robotic control support the claims.
Significance. If the central proof holds, the result supplies a mathematical guarantee that converts an empirical recipe into a foundation for world models with provable structure recovery, which would be a notable advance in representation learning for planning and generalization. The combination of spectral argument, uniqueness converse, approximate extension, and scaling experiments to high dimensions is a strength.
minor comments (3)
- [Abstract] Abstract: the phrasing 'among all such worlds, the Gaussian is the unique latent distribution' would benefit from an explicit qualifier that uniqueness holds within the stationary additive-noise class stated in the setup.
- The experimental section should include a table or appendix listing exact hyperparameters, random seeds, and precise metrics (e.g., recovery error norms) for the 1024-dimensional and robotic-control runs to support reproducibility claims.
- Notation: ensure the definition of the alignment loss and the spectral penalty term are introduced with consistent symbols before their use in the main theorem statement.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our manuscript and the recommendation for minor revision. We appreciate the recognition that the combination of the spectral argument, uniqueness result, approximate extension, and scaling experiments constitutes a strength, and that the result could provide a foundation for world models with provable structure recovery.
Circularity Check
No significant circularity
full rationale
The paper presents a mathematical proof of linear identifiability for LeJEPA under stationary additive-noise latent transitions, relying on a forward spectral decomposition that penalizes nonlinearity and a converse establishing Gaussian uniqueness. No steps reduce by construction to fitted parameters, self-referential definitions, or load-bearing self-citations; the derivation is self-contained within the stated class of worlds and does not rename known results or smuggle ansatzes via prior work. This matches the default expectation for a proof-based paper with independent mathematical content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latents evolve under stationary, additive-noise transitions
Forward citations
Cited by 5 Pith papers
-
A Generalization Theory for JEPA-Based World Models
The paper formulates JEPA pretraining as conditional spectral graph learning equivalent to low-rank factorization of an action-conditioned co-occurrence matrix and derives a finite-sample generalization bound connecti...
-
Identifiability Without Gaussianity: Symbolic World Models and Near-Infinite Temporal Consistency
PGSA achieves exact linear identifiability and near-infinite temporal consistency for non-Gaussian regimes via symbolic causal grounding, with four theorems formalized in Lean 4.
-
Information Lattice Learning as Probabilistic Graphical Model Structure Learning
ILL rules on PMFs are marginal laws on deterministic quotient variables; the resulting constraint sets define log-linear factor graphs whose factors are indexed by learned abstractions, positioning ILL as interpretabl...
-
Exact equivariance, kept through training, buys zero-shot generalisation across the symmetry group
Exact equivariance preserved through training makes prediction and closed-loop errors invariant across the symmetry group, enabling zero-shot generalization from a data slice to the full orbit.
-
Dual-Channel Grounded World Modeling (DCGWM): Structural Prevention of Objective Interference Collapse via Heterogeneous External Grounding with Inward-Only Gradient Flow
Proposes DCGWM architecture that partitions latent space into physical and behavioral subspaces with isolated gradient flows to structurally prevent objective interference collapse in grounded JEPA world models.
Reference graph
Works this paper leans on
-
[1]
A path towards autonomous machine intelligence, 2022
Yann LeCun. A path towards autonomous machine intelligence, 2022. URLhttps: //openreview.net/forum?id=BZ5a1r-kVsf. (Cited on pages 1, 2, 2, and 2.)
2022
-
[2]
Randall Balestriero and Yann LeCun. Lejepa: Provable and scalable self-supervised learning without the heuristics.arXiv preprint arXiv:2511.08544, 2025. (Cited on pages 1, 1, 2, 2, 4, 7, and 33.)
Pith/arXiv arXiv 2025
-
[3]
Adrien Bardes, Jean Ponce, and Yann LeCun. Vicreg: Variance-invariance-covariance regu- larization for self-supervised learning.CoRR, abs/2105.04906, 2021. URLhttps://arxiv. org/abs/2105.04906. (Cited on pages 1, 2, and 7.)
Pith/arXiv arXiv 2021
-
[4]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15619–15629, 2023. (Cited on pages 1 and 2.)
2023
-
[5]
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual repre- sentations from video.arXiv preprint arXiv:2404.08471, 2024. (Cited on pages 1 and 2.)
Pith/arXiv arXiv 2024
-
[6]
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, et al. V-jepa 2: Self- supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025. (Cited on pages 1 and 2.)
Pith/arXiv arXiv 2025
-
[7]
Vlad Sobal, Wancong Zhang, Kyunghyun Cho, Randall Balestriero, Tim G. J. Rudner, and Yann LeCun. Stress-testing offline reward-free reinforcement learning: A case for planning with latent dynamics models. In7th Robot Learning Workshop: Towards Robots with Human- Level Abilities, 2025. URLhttps://openreview.net/forum?id=jON7H6A9UU. (Cited on page 1.)
2025
-
[8]
DINO-WM: World models on pre-trained visual features enable zero-shot planning
Gaoyue Zhou, Hengkai Pan, Yann LeCun, and Lerrel Pinto. DINO-WM: World models on pre-trained visual features enable zero-shot planning. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025), 2025. (Cited on page 1.)
2025
-
[9]
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. LeWorldModel: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint arXiv:2603.19312, 2026. (Cited on pages 1, 2, 2, 2, 6, 7, 8, 9, 26, and 35.)
Pith/arXiv arXiv 2026
-
[10]
Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021
Bernhard Sch ¨olkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning.Proceedings of the IEEE, 109(5):612–634, 2021. (Cited on page 2.)
2021
-
[11]
Identifiability of latent-variable and structural-equation models: from linear to nonlinear.Annals of the Institute of Statistical Mathematics, 76(1):1–33, 2024
Aapo Hyv ¨arinen, Ilyes Khemakhem, and Ricardo Monti. Identifiability of latent-variable and structural-equation models: from linear to nonlinear.Annals of the Institute of Statistical Mathematics, 76(1):1–33, 2024. (Cited on pages 2 and 3.)
2024
-
[12]
Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes.arXiv preprint arXiv:1610.01644, 2016. (Cited on page 2.)
Pith/arXiv arXiv 2016
-
[13]
A model for analogical reasoning.Cognitive Psychology, 5(1):1–28, July 1973
David E Rumelhart and Adele A Abrahamson. A model for analogical reasoning.Cognitive Psychology, 5(1):1–28, July 1973. ISSN 0010-0285. doi: 10.1016/0010-0285(73)90023-6. URLhttps://www.sciencedirect.com/science/article/pii/0010028573900236. (Cited on page 2.) 10
-
[14]
Learning distributed representations of concepts
Geoffrey E Hinton. Learning distributed representations of concepts. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 8, 1986. (Cited on page 2.)
1986
-
[15]
Paul Smolensky. Tensor product variable binding and the representation of symbolic struc- tures in connectionist systems.Artificial intelligence, 46(1-2):159–216, 1990. URLhttps: //www.sciencedirect.com/science/article/pii/000437029090007M. Publisher: El- sevier. (Cited on pages 2 and 9.)
arXiv 1990
-
[16]
Linear Algebraic Structure of Word Senses, with Applications to Polysemy.Transactions of the Association for Computational Linguistics, 6:483–495, December 2018
Sanjeev Arora, Yuanzhi Li, Yingyu Liang, Tengyu Ma, and Andrej Risteski. Linear Algebraic Structure of Word Senses, with Applications to Polysemy.Transactions of the Association for Computational Linguistics, 6:483–495, December 2018. ISSN 2307-387X. doi: 10.1162/ tacl a 00034. URLhttps://direct.mit.edu/tacl/article/43451. (Cited on page 2.)
2018
-
[17]
The Linear Representation Hypothesis and the Geometry of Large Language Models, July 2024
Kiho Park, Yo Joong Choe, and Victor Veitch. The Linear Representation Hypothesis and the Geometry of Large Language Models, July 2024. URLhttp://arxiv.org/abs/2311. 03658. arXiv:2311.03658 [cs, stat]. (Cited on page 2.)
Pith/arXiv arXiv 2024
-
[18]
David Klindt, Charles O’Neill, Patrik Reizinger, Harald Maurer, and Nina Miolane. From superposition to sparse codes: interpretable representations in neural networks.arXiv preprint arXiv:2503.01824, 2025. (Cited on pages 2, 9, and 9.)
arXiv 2025
-
[19]
Vit ´oria Barin Pacela, Shruti Joshi, Isabela Camacho, Simon Lacoste-Julien, and David Klindt. Stop probing, start coding: Why linear probes and sparse autoencoders fail at compositional generalisation, 2026. URLhttps://arxiv.org/abs/2603.28744. (Cited on page 2.)
arXiv 2026
-
[20]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750– 15758, 2021. (Cited on page 2 and 2.)
2021
-
[21]
Bootstrap your own latent: A new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altch ´e, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Ghesh- laghi Azar, et al. Bootstrap your own latent: A new approach to self-supervised learning. InAdvances in Neural Information Processing Systems, 2020. (Cited on page 2 and 2.)
2020
-
[22]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Herv ´e J´egou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceed- ings of the IEEE/CVF International Conference on Computer Vision, pages 9650–9660, 2021. (Cited on page 2 and 2.)
2021
-
[23]
Information theory and statistical mechanics.Physical review, 106(4):620,
Edwin T Jaynes. Information theory and statistical mechanics.Physical review, 106(4):620,
-
[24]
(Cited on pages 2, 4, and 8.)
-
[25]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational Conference on Machine Learning, pages 1597–1607. PMLR, 2020. (Cited on page 2.)
2020
-
[26]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9729–9738, 2020. (Cited on page 2.)
2020
-
[27]
Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018
Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.arXiv preprint arXiv:1807.03748, 2018. (Cited on pages 2 and 7.)
Pith/arXiv arXiv 2018
-
[28]
Barlow twins: Self- supervised learning via redundancy reduction.International Conference on Machine Learning,
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and St ´ephane Deny. Barlow twins: Self- supervised learning via redundancy reduction.International Conference on Machine Learning,
-
[29]
DINOv3.arXiv preprint arXiv:2508.10104, 2025
Oriane Sim ´eoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Micha ¨el Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timoth´ee Darcet, Th ´eo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, ...
Pith/arXiv arXiv 2025
-
[30]
Understanding contrastive representation learning through alignment and uniformity on the hypersphere
Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. InInternational conference on machine learn- ing, pages 9929–9939. PMLR, 2020. (Cited on page 2.)
2020
-
[31]
Rethinking negative pairs in code search
Haochen Li, Xin Zhou, Luu Anh Tuan, and Chunyan Miao. Rethinking negative pairs in code search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 12760–12774, 2023. (Cited on page 2.)
2023
-
[32]
On the importance of gaussianizing representations
Daniel Eftekhari and Vardan Papyan. On the importance of gaussianizing representations. arXiv preprint arXiv:2505.00685, 2025. (Cited on page 2.)
arXiv 2025
-
[33]
InfoNCE induces Gaussian dis- tribution
Roy Betser, Eyal Gofer, Meir Yossef Levi, and Guy Gilboa. InfoNCE induces Gaussian dis- tribution. InInternational Conference on Learning Representations, 2026. (Cited on page 2.)
2026
-
[34]
Cambridge University Press, 1943
Kenneth J W Craik.The Nature of Explanation. Cambridge University Press, 1943. (Cited on page 2.)
1943
-
[35]
Cognitive maps in rats and men.Psychological Review, 55(4):189–208,
Edward C Tolman. Cognitive maps in rats and men.Psychological Review, 55(4):189–208,
-
[36]
Harvard University Press, 1983
Philip N Johnson-Laird.Mental Models: Towards a Cognitive Science of Language, Inference, and Consciousness. Harvard University Press, 1983. (Cited on page 2.)
1983
-
[37]
An internal model for sensori- motor integration.Science, 269(5232):1880–1882, 1995
Daniel M Wolpert, Zoubin Ghahramani, and Michael I Jordan. An internal model for sensori- motor integration.Science, 269(5232):1880–1882, 1995. (Cited on page 2.)
1995
-
[38]
Perceptions as hypotheses.Philosophical Transactions of the Royal Society of London
Richard L Gregory. Perceptions as hypotheses.Philosophical Transactions of the Royal Society of London. B, Biological Sciences, 290(1038):181–197, 1980. (Cited on page 2.)
1980
-
[39]
The free-energy principle: a unified brain theory?Nature Reviews Neuroscience, 11(2):127–138, 2010
Karl Friston. The free-energy principle: a unified brain theory?Nature Reviews Neuroscience, 11(2):127–138, 2010. (Cited on page 2.)
2010
-
[40]
Human-level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015
Brenden M Lake, Ruslan Salakhutdinov, and Joshua B Tenenbaum. Human-level concept learning through probabilistic program induction.Science, 350(6266):1332–1338, 2015. (Cited on page 2.)
2015
-
[41]
Every good regulator of a system must be a model of that system.International Journal of Systems Science, 1(2):89–97, 1970
Roger C Conant and W Ross Ashby. Every good regulator of a system must be a model of that system.International Journal of Systems Science, 1(2):89–97, 1970. (Cited on page 2.)
1970
-
[42]
The internal model principle of control theory.Automatica, 12(5):457–465, 1976
B A Francis and W M Wonham. The internal model principle of control theory.Automatica, 12(5):457–465, 1976. (Cited on page 2.)
1976
-
[43]
Princeton University Press, 1957
Richard Bellman.Dynamic Programming. Princeton University Press, 1957. (Cited on page 2.)
1957
-
[44]
A new approach to linear filtering and prediction problems.Transactions of the ASME – Journal of Basic Engineering, 82(Series D):35–45, 1960
Rudolph E Kalman. A new approach to linear filtering and prediction problems.Transactions of the ASME – Journal of Basic Engineering, 82(Series D):35–45, 1960. (Cited on page 2.)
1960
-
[45]
Neural networks for self-learning control systems
Derrick H Nguyen and Bernard Widrow. Neural networks for self-learning control systems. IEEE Control systems magazine, 10(3):18–23, 1990. (Cited on pages 2 and 26.)
1990
-
[46]
Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environ- ments
J ¨urgen Schmidhuber. Making the world differentiable: On using fully recurrent self-supervised neural networks for dynamic reinforcement learning and planning in non-stationary environ- ments. Technical Report FKI-126-90, Institut f¨ur Informatik, Technische Universit¨at M¨unchen,
-
[47]
Integrated architectures for learning, planning, and reacting based on ap- proximating dynamic programming
Richard S Sutton. Integrated architectures for learning, planning, and reacting based on ap- proximating dynamic programming. InProceedings of the Seventh International Conference on Machine Learning, pages 216–224, 1990. (Cited on page 2.)
1990
-
[48]
Embed to control: A locally linear latent dynamics model for control from raw images
Manuel Watter, Jost Tobias Springenberg, Joschka Boedecker, and Martin Riedmiller. Embed to control: A locally linear latent dynamics model for control from raw images. InAdvances in Neural Information Processing Systems, 2015. (Cited on page 2.) 12
2015
-
[49]
Action- conditional video prediction using deep networks in Atari games
Junhyuk Oh, Xiaoxiao Guo, Honglak Lee, Richard L Lewis, and Satinder Singh. Action- conditional video prediction using deep networks in Atari games. InAdvances in Neural In- formation Processing Systems, 2015. (Cited on page 2.)
2015
-
[50]
Unsupervised learning for physical interac- tion through video prediction
Chelsea Finn, Ian Goodfellow, and Sergey Levine. Unsupervised learning for physical interac- tion through video prediction. InAdvances in Neural Information Processing Systems, 2016. (Cited on page 2.)
2016
-
[51]
World models.arXiv preprint arXiv:1803.10122, 2(3): 440, 2018
David Ha and J ¨urgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3): 440, 2018. (Cited on pages 2 and 26.)
Pith/arXiv arXiv 2018
-
[52]
Learning latent dynamics for planning from pixels
Danijar Hafner, Timothy Lillicrap, Ian Fischer, Ruben Villegas, David Ha, Honglak Lee, and James Davidson. Learning latent dynamics for planning from pixels. InInternational Confer- ence on Machine Learning, pages 2555–2565. PMLR, 2019. (Cited on page 2.)
2019
-
[53]
Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020
Julian Schrittwieser, Ioannis Antonoglou, Thomas Hubert, Karen Simonyan, Laurent Sifre, Simon Schmitt, Arthur Guez, Edward Lockhart, Demis Hassabis, Thore Graepel, Timothy Lillicrap, and David Silver. Mastering Atari, Go, chess and shogi by planning with a learned model.Nature, 588(7839):604–609, 2020. (Cited on page 2.)
2020
-
[54]
Mastering diverse control tasks through world models.Nature, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, 2025. (Cited on page 2.)
2025
-
[55]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, Clarence Wing Yin Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. OpenAI Technical Report, 2024. URLhttps: //openai.com/index/video-generation-models-as-world-simulators/. (Cited on page 2.)
2024
-
[56]
Genie: Generative interactive envi- ronments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Maria Elisabeth Bechtle, Feryal Behbahani, Stephanie C Y Chan, Nicolas Heess, Lucy Gon- zalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando...
2024
-
[57]
Nonlinear independent component analysis: Existence and uniqueness results.Neural Networks, 12(3):429–439, 1999
Aapo Hyv ¨arinen and Petteri Pajunen. Nonlinear independent component analysis: Existence and uniqueness results.Neural Networks, 12(3):429–439, 1999. (Cited on page 2.)
1999
-
[58]
Challenging common assumptions in the unsupervised learn- ing of disentangled representations
Francesco Locatello, Stefan Bauer, Mario Lucic, Gunnar R ¨atsch, Sylvain Gelly, Bernhard Sch¨olkopf, and Olivier Bachem. Challenging common assumptions in the unsupervised learn- ing of disentangled representations. InInternational Conference on Machine Learning, 2019. (Cited on page 2.)
2019
-
[59]
Unsupervised feature extraction by time-contrastive learning and nonlinear ICA
Aapo Hyv ¨arinen and Hiroshi Morioka. Unsupervised feature extraction by time-contrastive learning and nonlinear ICA. InAdvances in Neural Information Processing Systems, 2016. (Cited on page 2.)
2016
-
[60]
Nonlinear ICA of temporally dependent stationary sources
Aapo Hyv ¨arinen and Hiroshi Morioka. Nonlinear ICA of temporally dependent stationary sources. InInternational Conference on Artificial Intelligence and Statistics, 2017. (Cited on page 2.)
2017
-
[61]
Towards nonlinear disentanglement in natural data with temporal sparse coding
David Klindt, Lukas Schott, Yash Sharma, Ivan Ustyuzhaninov, Wieland Brendel, Matthias Bethge, and Dylan Paiton. Towards nonlinear disentanglement in natural data with temporal sparse coding. InInternational Conference on Learning Representations, 2021. (Cited on page 2.)
2021
-
[62]
Variational autoen- coders and nonlinear ICA: A unifying framework
Ilyes Khemakhem, Diederik Kingma, Ricardo Monti, and Aapo Hyv¨arinen. Variational autoen- coders and nonlinear ICA: A unifying framework. InInternational Conference on Artificial Intelligence and Statistics, 2020. (Cited on page 2.) 13
2020
-
[63]
Nonlinear ICA Using Auxiliary Vari- ables and Generalized Contrastive Learning
Aapo Hyvarinen, Hiroaki Sasaki, and Richard Turner. Nonlinear ICA Using Auxiliary Vari- ables and Generalized Contrastive Learning. InProceedings of the Twenty-Second Interna- tional Conference on Artificial Intelligence and Statistics, pages 859–868. PMLR, April 2019. URLhttps://proceedings.mlr.press/v89/hyvarinen19a.html. (Cited on page 2.)
2019
-
[64]
Contrastive learning inverts the data generating process
Roland S Zimmermann, Yash Sharma, Steffen Schneider, Matthias Bethge, and Wieland Bren- del. Contrastive learning inverts the data generating process. InInternational Conference on Machine Learning, 2021. (Cited on page 2.)
2021
-
[65]
Self-supervised learning with data augmentations provably isolates content from style
Julius von K ¨ugelgen, Yash Sharma, Luigi Gresele, Wieland Brendel, Bernhard Sch ¨olkopf, Michel Besserve, and Francesco Locatello. Self-supervised learning with data augmentations provably isolates content from style. InAdvances in Neural Information Processing Systems,
-
[66]
Disentanglement via mechanism sparsity regularization: A new principle for nonlinear ICA
S ´ebastien Lachapelle, Pau Rodriguez, Yash Sharma, Katie E Everett, R´emi Le Priol, Alexandre Lacoste, and Simon Lacoste-Julien. Disentanglement via mechanism sparsity regularization: A new principle for nonlinear ICA. InConference on Causal Learning and Reasoning, 2022. (Cited on page 2.)
2022
-
[67]
Interventional causal repre- sentation learning
Kartik Ahuja, Divyat Mahajan, Yixin Wang, and Yoshua Bengio. Interventional causal repre- sentation learning. InInternational Conference on Machine Learning, 2023. (Cited on pages 2, 9, and 26.)
2023
-
[68]
Learning linear causal representations from interventions under gen- eral nonlinear mixing.Advances in Neural Information Processing Systems, 36:45419–45462,
Simon Buchholz, Goutham Rajendran, Elan Rosenfeld, Bryon Aragam, Bernhard Sch ¨olkopf, and Pradeep Ravikumar. Learning linear causal representations from interventions under gen- eral nonlinear mixing.Advances in Neural Information Processing Systems, 36:45419–45462,
-
[69]
(Cited on pages 2, 9, and 26.)
-
[70]
Cross-entropy is all you need to invert the data generating process
Patrik Reizinger, Alice Bizeul, Attila Juhos, Julia E V ogt, Randall Balestriero, Wieland Bren- del, and David Klindt. Cross-entropy is all you need to invert the data generating process. arXiv preprint arXiv:2410.21869, 2024. (Cited on page 2.)
arXiv 2024
-
[71]
On linear identifiability of learned represen- tations
Geoffrey Roeder, Luke Metz, and Durk Kingma. On linear identifiability of learned represen- tations. InInternational Conference on Machine Learning, pages 9030–9039. PMLR, 2021. (Cited on page 2.)
2021
-
[72]
Slow feature analysis: Unsupervised learning of invariances.Neural Computation, 14(4):715–770, 2002
Laurenz Wiskott and Terrence J Sejnowski. Slow feature analysis: Unsupervised learning of invariances.Neural Computation, 14(4):715–770, 2002. (Cited on pages 2, 28, and 29.)
2002
-
[73]
Vlad Sobal, S V Jyothir, Siddhartha Jalagam, Nicolas Carion, Kyunghyun Cho, and Yann LeCun. Joint embedding predictive architectures focus on slow features.arXiv preprint arXiv:2211.10831, 2022. (Cited on pages 2, 5, and 28.)
arXiv 2022
-
[74]
An extension of slow feature analysis for nonlinear blind source separation.Journal of Machine Learning Research, 15:921–947,
Henning Sprekeler, Tiziano Zito, and Laurenz Wiskott. An extension of slow feature analysis for nonlinear blind source separation.Journal of Machine Learning Research, 15:921–947,
-
[75]
(Cited on pages 2, 5, 5, 22, 28, 29, 29, 29, 29, 30, 30, 30, 30, 30, and 31.)
-
[76]
Randall Balestriero and Yann LeCun. Contrastive and non-contrastive self-supervised learning recover global and local spectral embedding methods, 2022. URLhttps://arxiv.org/ abs/2205.11508. (Cited on pages 2 and 30.)
arXiv 2022
-
[77]
Robustness of nonlinear representation learning
Simon Buchholz and Bernhard Sch ¨olkopf. Robustness of nonlinear representation learning. arXiv preprint arXiv:2503.15355, 2025. (Cited on pages 2, 6, and 26.)
arXiv 2025
-
[78]
Beatrix MG Nielsen, Emanuele Marconato, Andrea Dittadi, and Luigi Gresele. When does closeness in distribution imply representational similarity? an identifiability perspective.arXiv preprint arXiv:2506.03784, 2025. (Cited on page 2.)
arXiv 2025
-
[79]
Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013
Yoshua Bengio, Aaron Courville, and Pascal Vincent. Representation learning: A review and new perspectives.IEEE transactions on pattern analysis and machine intelligence, 35(8): 1798–1828, 2013. (Cited on page 3 and 3.)
2013
-
[80]
On the theory of the Brownian motion.Physical Review, 36(5):823–841, 1930
George E Uhlenbeck and Leonard S Ornstein. On the theory of the Brownian motion.Physical Review, 36(5):823–841, 1930. (Cited on page 4.) 14
1930
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.