Improving Cross-Format Robustness in Language Models with Multi-Format Training
Pith reviewed 2026-06-27 10:11 UTC · model grok-4.3
The pith
Multi-format training on equivalent question variants improves both accuracy and consistency across answer formats in language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
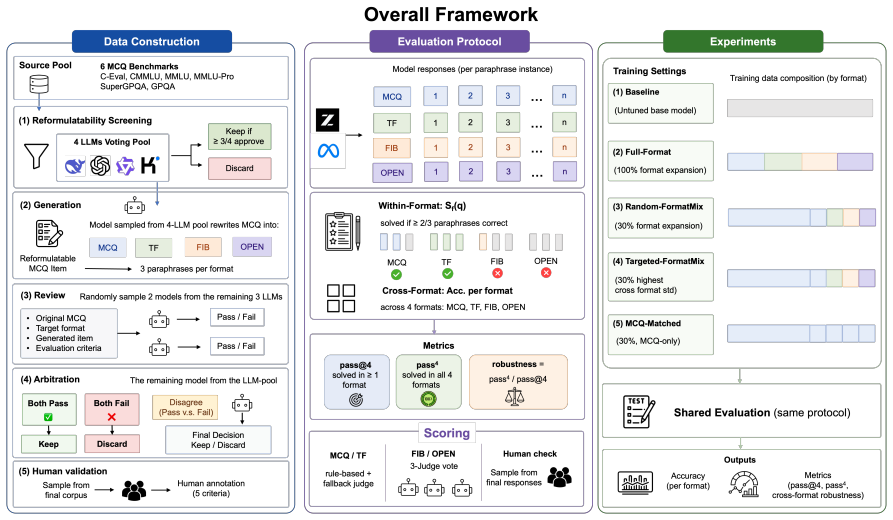
Multi-format supervision consistently improves both task performance and cross-format robustness across GLM4 and Llama-3.1, whereas MCQ-only supervision alone brings little benefit and can even reduce robustness. Expanding only about 30% of the training set into multiple formats often recovers most of the gain from full-format training, and this effect appears across the model families and sizes studied.
What carries the argument
FormatMix, which expands a chosen subset of training items into multiple semantically equivalent formats via random or targeted selection to supply multi-format supervision during training.
If this is right
- Multi-format supervision raises cross-format robustness without any change to the underlying model architecture.
- Partial expansion of roughly 30% of items into multiple formats captures most of the robustness and accuracy benefit of full multi-format training.
- MCQ-only training does not reliably improve and can lower robustness compared with mixed-format training.
- The benefit holds across different model families and sizes when the same multi-format procedure is applied.
Where Pith is reading between the lines
- Models trained this way may require less careful prompt engineering to match the exact formats seen at training time.
- The approach could extend to other consistency problems such as robustness to paraphrased instructions or different output styles.
- If the 30% threshold generalizes, it offers a low-cost way to retrofit existing training pipelines for better format tolerance.
Load-bearing premise
The different formats created for each training item are semantically equivalent and the measured gains come from the added format diversity rather than from selection effects or other training differences.
What would settle it
Train two models on the same base data, one with single-format items and one with 30% multi-format items, then test both on a held-out set of questions presented in formats never seen during training and measure whether the multi-format model shows a smaller performance drop.
Figures











read the original abstract
Large language models often remain sensitive to answer format: a question solved correctly in one form may fail in another semantically equivalent form. To study this gap, we define cross-format robustness as the extent to which a model answers the same underlying question consistently across formats. We then compare full-format training with FormatMix, which expands only a subset of training items into multiple equivalent formats using either random or targeted selection. Across GLM4 and Llama-3.1, multi-format supervision consistently improves both task performance and cross-format robustness, whereas Multiple-choice question (MCQ)-only supervision alone brings little benefit and can even reduce robustness. We further find that expanding only about 30% of the training set into multiple formats often recovers most of the gain from full-format training, and this effect appears across the model families and sizes we study. These results suggest that format diversity, rather than additional supervision alone, is the key driver of robustness. That lightweight multi-format augmentation is a practical way to make LLMs less sensitive to answer format without changing the base model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper defines cross-format robustness as consistent performance on the same underlying question across semantically equivalent answer formats. It introduces FormatMix, which expands a subset (~30%) of training items into multiple formats via random or targeted selection, and reports that this yields consistent gains in both task accuracy and robustness across GLM-4 and Llama-3.1 families, outperforming MCQ-only training (which can even hurt robustness). The authors conclude that format diversity, not merely additional supervision volume, drives the improvements.
Significance. If the attribution to format diversity is isolated from confounds, the work offers a lightweight, practical augmentation strategy that recovers most robustness gains without full multi-format expansion or base-model changes. The cross-family, cross-size empirical comparisons constitute a strength, as does the direct (non-circular) evaluation on held-out format variants.
major comments (2)
- [Abstract] Abstract: The claim that 'format diversity, rather than additional supervision alone, is the key driver of robustness' is load-bearing yet rests on an unverified assumption. The description of format creation via 'random or targeted selection' provides no equivalence verification (e.g., semantic similarity scores, human judgments, or model-based checks that the generated formats preserve question content) and no matched-token or matched-example-count baselines comparing MCQ-only training to multi-format training at identical volume. Consequently, the 30% subset result could arise from non-random item selection or token-count differences rather than diversity per se.
- [Abstract] Abstract / experimental description: The abstract states that multi-format supervision 'consistently improves' performance and robustness, but supplies neither the precise metrics used to quantify cross-format robustness, nor any statistical tests, confidence intervals, or per-format breakdown tables. Without these, it is impossible to judge whether the reported gains are large enough, reliable across formats, or robust to the format-generation process itself.
minor comments (2)
- [Abstract] The abstract would be strengthened by including at least one concrete performance delta (e.g., accuracy or robustness score) and the exact number of formats per item.
- [Abstract] Clarify whether the 'targeted selection' heuristic is deterministic or involves any learned component; if the latter, state how it avoids introducing new selection biases.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on our manuscript. We address each major comment below and agree that targeted additions will strengthen the presentation of our results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'format diversity, rather than additional supervision alone, is the key driver of robustness' is load-bearing yet rests on an unverified assumption. The description of format creation via 'random or targeted selection' provides no equivalence verification (e.g., semantic similarity scores, human judgments, or model-based checks that the generated formats preserve question content) and no matched-token or matched-example-count baselines comparing MCQ-only training to multi-format training at identical volume. Consequently, the 30% subset result could arise from non-random item selection or token-count differences rather than diversity per se.
Authors: We appreciate this concern regarding potential confounds. Formats are generated by applying transformations to identical underlying questions, preserving content by construction via templates and generation rules described in the methods. We did not report quantitative equivalence metrics (such as embedding-based similarity) in the abstract. To isolate diversity from volume or selection effects, we will add matched-token and matched-example baselines (MCQ-only training at equivalent supervision volume) plus semantic similarity verification in the revised version. revision: yes
-
Referee: [Abstract] Abstract / experimental description: The abstract states that multi-format supervision 'consistently improves' performance and robustness, but supplies neither the precise metrics used to quantify cross-format robustness, nor any statistical tests, confidence intervals, or per-format breakdown tables. Without these, it is impossible to judge whether the reported gains are large enough, reliable across formats, or robust to the format-generation process itself.
Authors: Cross-format robustness is defined in Section 3 as the rate of consistent correct answers to the same question across formats. The abstract summarizes aggregate gains. We agree additional detail improves interpretability. In revision we will reference the exact metric in the abstract, add paired statistical tests with confidence intervals, and include per-format breakdown tables in the results. revision: yes
Circularity Check
No circularity: purely empirical comparisons of training regimes
full rationale
The paper reports direct experimental results from training GLM4 and Llama-3.1 variants under MCQ-only, full-format, and FormatMix regimes, then measuring task accuracy and cross-format robustness on held-out evaluations. No equations, derivations, parameter fits, or self-citations are invoked to derive the outcomes; the robustness metric is defined once and applied uniformly. The 30% subset finding is likewise an observed empirical pattern, not a constructed prediction. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Different answer formats can be generated that preserve the semantic meaning of the original question.
Reference graph
Works this paper leans on
-
[1]
Llms are biased towards output formats! systematically evaluating and mitigating output format bias of llms , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[2]
Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
MCQFormatBench: Robustness Tests for Multiple-Choice Questions , author=. Proceedings of the Fourth Workshop on Generation, Evaluation and Metrics (GEM ^2 ) , pages=
-
[3]
arXiv e-prints , pages=
Stress testing generalization: How minor modifications undermine large language model performance , author=. arXiv e-prints , pages=
-
[4]
arXiv preprint arXiv:2510.11905 , year=
LLM Knowledge is Brittle: Truthfulness Representations Rely on Superficial Resemblance , author=. arXiv preprint arXiv:2510.11905 , year=
-
[5]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Right answer, wrong score: Uncovering the inconsistencies of LLM evaluation in multiple-choice question answering , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[6]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Wait, that’s not an option: Llms robustness with incorrect multiple-choice options , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[7]
arXiv preprint arXiv:2406.07545 , year=
Open-llm-leaderboard: From multi-choice to open-style questions for llms evaluation, benchmark, and arena , author=. arXiv preprint arXiv:2406.07545 , year=
-
[8]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Artifacts or abduction: How do llms answer multiple-choice questions without the question? , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
arXiv preprint arXiv:2507.02856 , year=
Answer matching outperforms multiple choice for language model evaluation , author=. arXiv preprint arXiv:2507.02856 , year=
-
[10]
arXiv preprint arXiv:2407.15018 , year=
Answer, assemble, ace: Understanding how transformers answer multiple choice questions , author=. arXiv preprint arXiv:2407.15018 , year=
-
[11]
arXiv preprint arXiv:2009.03300 , year=
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
Pith/arXiv arXiv 2009
-
[12]
Advances in Neural Information Processing Systems , volume=
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Advances in Neural Information Processing Systems , volume=
Supergpqa: Scaling llm evaluation across 285 graduate disciplines , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
arXiv preprint arXiv:2311.12022 , year=
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
-
[15]
Advances in neural information processing systems , volume=
C-eval: A multi-level multi-discipline chinese evaluation suite for foundation models , author=. Advances in neural information processing systems , volume=
-
[16]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Cmmlu: Measuring massive multitask language understanding in chinese , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[17]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
Can multiple-choice questions really be useful in detecting the abilities of LLMs? , author=. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024) , pages=
2024
-
[18]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
LLMs may perform MCQA by selecting the least incorrect option , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[19]
arXiv preprint arXiv:2511.21860 , year=
Improving Score Reliability of Multiple Choice Benchmarks with Consistency Evaluation and Altered Answer Choices , author=. arXiv preprint arXiv:2511.21860 , year=
-
[20]
Can you unpack that? learning to rewrite questions-in-context , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[21]
EQUATOR: A Deterministic Framework for Evaluating LLM Reasoning with Open-Ended Questions.\# v1. 0.0-beta , author=. arXiv preprint arXiv:2501.00257 , year=
-
[22]
Judging the judges: A systematic study of position bias in llm-as-a-judge , author=. Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics , pages=
-
[23]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[24]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Llms instead of human judges? a large scale empirical study across 20 nlp evaluation tasks , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[25]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Qgeval: benchmarking multi-dimensional evaluation for question generation , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[26]
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
On the robustness of question rewriting systems to questions of varying hardness , author=. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[27]
arXiv preprint arXiv:2510.27106 , year=
Rating Roulette: Self-Inconsistency in LLM-As-A-Judge Frameworks , author=. arXiv preprint arXiv:2510.27106 , year=
-
[28]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Flaw or Artifact? Rethinking Prompt Sensitivity in Evaluating LLMs , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[29]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
Are Large Language Models Consistent over Value-laden Questions? , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages=
2024
-
[30]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Which of these best describes multiple choice evaluation with llms? a) forced b) flawed c) fixable d) all of the above , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[31]
2024 , eprint=
DeepSeek-V3 Technical Report , author=. 2024 , eprint=
2024
-
[32]
2025 , eprint=
Qwen3 Technical Report , author=. 2025 , eprint=
2025
-
[33]
2026 , eprint=
Kimi K2.5: Visual Agentic Intelligence , author=. 2026 , eprint=
2026
-
[34]
2025 , eprint=
gpt-oss-120b & gpt-oss-20b Model Card , author=. 2025 , eprint=
2025
-
[35]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Challenging big-bench tasks and whether chain-of-thought can solve them , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[36]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
A Strategic Coordination Framework of Small LMs Matches Large LMs in Data Synthesis , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.