Optimal Deterministic Multicalibration and Omniprediction
Pith reviewed 2026-06-26 18:24 UTC · model grok-4.3
The pith
A deterministic algorithm achieves the minimax-optimal sample complexity for multicalibration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that there exists a deterministic predictor attaining ε-multicalibration with sample complexity matching the known minimax lower bound of Õ(ε^{-3}). The algorithm is then lifted to produce deterministic predictors satisfying outcome indistinguishability for any finite or finitely covered collection of tests, which immediately yields deterministic omnipredictors and panpredictors with the same optimal sample complexity.
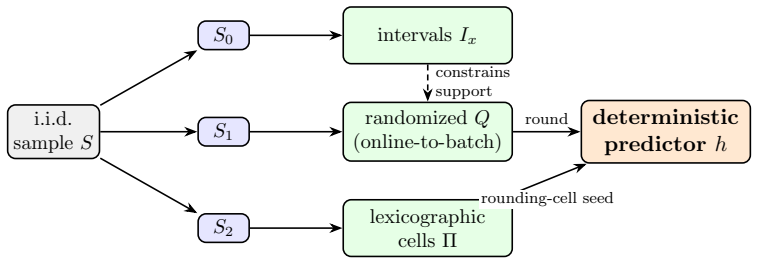
What carries the argument
The deterministic multicalibration algorithm that iteratively enforces calibration constraints across the given groups without introducing randomness.
If this is right
- Deterministic omnipredictors achieve the optimal sample complexity previously known only for randomized versions.
- Outcome indistinguishability holds deterministically for any finite collection of tests at the minimax rate.
- Panpredictors likewise admit deterministic constructions with optimal sample complexity.
- Multicalibration and its generalizations no longer require randomization to attain best-known efficiency.
Where Pith is reading between the lines
- Reproducibility improves in applications that cannot tolerate randomized outputs.
- The finite-test restriction may still allow practical coverage of many fairness or calibration constraints via suitable discretization.
- Similar derandomization techniques could be tested on related notions such as multiaccuracy or other conditional unbiasedness properties.
Load-bearing premise
The collection of groups or tests is finite or admits a finite cover.
What would settle it
A distribution over contexts and outcomes together with a finite group collection such that every deterministic predictor requires more than Õ(ε^{-3}) samples to achieve ε-multicalibration would falsify the claim.
Figures

read the original abstract
A model is multicalibrated on a collection of group weights $G$ if it is calibrated -- i.e. unbiased even conditional on its prediction -- not just overall, but also after reweighting contexts by each $g \in G$. It is a useful property for many downstream applications and is a basic desideratum of trustworthy machine learning. Before this work, all predictors known to attain the minimax-optimal $\widetilde O(\varepsilon^{-3})$ sample complexity rate for $\varepsilon$-multicalibration were randomized, while deterministic predictors were known only with substantially worse sample complexity. Whether randomization is necessary for optimal sample complexity in multicalibration was explicitly asked by [CLNR26] and implicitly in several prior works. We resolve this open problem by giving a minimax-optimal multicalibration algorithm that outputs a deterministic predictor. We then generalize the algorithm to produce optimal deterministic predictors that satisfy outcome indistinguishability (OI) with respect to finite or finitely covered collections of tests. As an application, this also gives deterministic omnipredictors and panpredictors with optimal sample complexity, resolving open problems posed by [OKK25] and [BHHLZ25].
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to resolve the open question of whether randomization is required to achieve the minimax-optimal ̃O(ε^{-3}) sample complexity for ε-multicalibration by constructing a deterministic algorithm that attains this rate. It further extends the approach to produce deterministic predictors satisfying outcome indistinguishability (OI) for finite or finitely covered test collections, and derives from this optimal deterministic omnipredictors and panpredictors, addressing open problems in prior work.
Significance. If the algorithmic construction and its analysis are correct, the result is significant: it shows that deterministic predictors can match the optimal sample complexity previously known only for randomized predictors in multicalibration, OI, and omniprediction settings. This strengthens the toolkit for trustworthy ML by removing the need to trade determinism for statistical efficiency and directly resolves multiple cited open problems.
minor comments (2)
- The abstract states the existence of the algorithm and its optimality but does not include even a high-level sketch of the construction or the key technical step that enables determinism while preserving the ̃O(ε^{-3}) rate; adding one sentence on the high-level idea would improve accessibility.
- Notation for the collection of group weights is introduced as G in the abstract; ensure consistent use of this symbol (and any related notation for tests in the OI generalization) throughout the manuscript and that all symbols are defined before first use.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the paper and for recommending minor revision. The report correctly captures the main contributions and the resolution of the cited open questions. No major comments appear in the report, so there are no specific points requiring a point-by-point response.
Circularity Check
No significant circularity identified
full rationale
The paper claims to resolve an open problem by constructing a new minimax-optimal deterministic multicalibration algorithm (and its generalization to outcome indistinguishability for finite/finitely covered tests). The provided abstract and description contain no self-definitional reductions, no fitted parameters renamed as predictions, no load-bearing self-citations that justify uniqueness or ansatzes, and no renaming of known results. The central contribution is an explicit algorithmic construction whose correctness is independent of the cited open-problem statements; those citations identify the target rather than supply the derivation. The result is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
S´ ılvia Casacuberta, Cynthia Dwork, and Salil Vadhan
URLhttps://arxiv.org/abs/2510.27638. S´ ılvia Casacuberta, Cynthia Dwork, and Salil Vadhan. Complexity-theoretic implications of multicalibration. InProceedings of the 56th Annual ACM Symposium on Theory of Computing, pages 1071–1082,
-
[2]
Optimal Lower Bounds for Online Multicalibration
Natalie Collina, Ira Globus-Harris, Surbhi Goel, Varun Gupta, Aaron Roth, and Mirah Shi. Collaborative prediction: Tractable information aggregation via agreement. InProceedings of the 2026 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA). SIAM, 2026a. Natalie Collina, Jiuyao Lu, Georgy Noarov, and Aaron Roth. Optimal lower bounds for online multic...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2604.21923 2026
-
[3]
doi: 10.1145/3717823.3718178. A Philip Dawid. The well-calibrated bayesian.Journal of the American Statistical Association, 77 (379):605–610,
-
[4]
A Stochastic Approximat ion Method
doi: 10.1214/aoms/1177729689. URLhttps://doi.org/10.1214/aoms/1177729689. Cynthia Dwork and Pranay Tankala. Supersimulators.arXiv preprint arXiv:2509.17994,
-
[5]
Oracle efficient online multi- calibration and omniprediction
Sumegha Garg, Christopher Jung, Omer Reingold, and Aaron Roth. Oracle efficient online multi- calibration and omniprediction. InProceedings of the 2024 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 2725–2792. Society for Industrial and Applied Mathematics,
2024
-
[6]
Om- nipredictors
Parikshit Gopalan, Adam Tauman Kalai, Omer Reingold, Vatsal Sharan, and Udi Wieder. Om- nipredictors. In13th Innovations in Theoretical Computer Science Conference (ITCS 2022), pages 79:1–79:21. Schloss Dagstuhl – Leibniz-Zentrum f¨ ur Informatik,
2022
-
[7]
Loss minimization through the lens of outcome indistinguishability
Parikshit Gopalan, Lunjia Hu, Michael P Kim, Omer Reingold, and Udi Wieder. Loss minimization through the lens of outcome indistinguishability. In14th Innovations in Theoretical Computer Science Conference (ITCS 2023), 2023a. Parikshit Gopalan, Michael Kim, and Omer Reingold. Swap agnostic learning, or characterizing omniprediction via multicalibration. I...
2023
-
[8]
Ursula Hebert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum
doi: 10.1016/ 0890-5401(92)90010-D. Ursula Hebert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. Multicalibration: Calibration for the (computationally-identifiable) masses. InProceedings of the 35th International Conference on Machine Learning, pages 1939–1948. PMLR,
1939
-
[9]
Comparative Learning: A Sample Complexity Theory for Two Hypothesis Classes
Lunjia Hu and Charlotte Peale. Comparative Learning: A Sample Complexity Theory for Two Hypothesis Classes. In Yael Tauman Kalai, editor,14th Innovations in Theoretical Computer Science Conference (ITCS 2023), volume 251 ofLeibniz International Proceedings in Informatics (LIPIcs), pages 72:1–72:30, Dagstuhl, Germany,
2023
-
[10]
Schloss Dagstuhl – Leibniz- Zentrum f¨ ur Informatik. ISBN 978-3-95977-263-1. doi: 10.4230/LIPIcs.ITCS.2023.72. URL https://drops.dagstuhl.de/entities/document/10.4230/LIPIcs.ITCS.2023.72. 31 Lunjia Hu, Charlotte Peale, and Omer Reingold. Metric entropy duality and the sample complexity of Outcome Indistinguishability. In Sanjoy Dasgupta and Nika Haghtala...
-
[11]
Michael Kearns, Aaron Roth, and Emily Ryu
URL https: //proceedings.mlr.press/v167/hu22a.html. Michael Kearns, Aaron Roth, and Emily Ryu. Networked information aggregation via machine learning. InProceedings of the 2026 Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), pages 4799–4845. SIAM,
2026
-
[12]
Derandomizing multi-distribution learning
Kasper Green Larsen, Omar Montasser, and Nikita Zhivotovskiy. Derandomizing multi-distribution learning. InAdvances in Neural Information Processing Systems 37 (NeurIPS 2024),
2024
-
[13]
URLhttps://arxiv.org/abs/2409.17567
doi: 10.52202/079017-2989. URLhttps://arxiv.org/abs/2409.17567. Daniel Lee, Georgy Noarov, Mallesh Pai, and Aaron Roth. Online minimax multiobjective opti- mization: Multicalibeating and other applications.Advances in Neural Information Processing Systems, 35:29051–29063,
-
[14]
Harrison Rosenberg, Robi Bhattacharjee, Kassem Fawaz, and Somesh Jha
doi: 10.1145/3406325.3451050. Harrison Rosenberg, Robi Bhattacharjee, Kassem Fawaz, and Somesh Jha. An exploration of multicalibration uniform convergence bounds.arXiv preprint arXiv:2202.04530,
-
[15]
URLhttps://doi.org/10.1137/S089548019223872X
doi: 10.1137/S089548019223872X. URLhttps://doi.org/10.1137/S089548019223872X. Eliran Shabat, Lee Cohen, and Yishay Mansour. Sample complexity of uniform convergence for multicalibration. InAdvances in Neural Information Processing Systems, volume 33, pages 13331–13340,
-
[16]
URLhttps://msp.org/pjm/1958/8-1/pjm-v8-n1-p14-s.pdf
doi: 10.2140/pjm.1958.8.171. URLhttps://msp.org/pjm/1958/8-1/pjm-v8-n1-p14-s.pdf. Zihan Zhang, Wenhao Zhan, Yuxin Chen, Simon S Du, and Jason D Lee. Optimal multi-distribution learning. InThe Thirty Seventh Annual Conference on Learning Theory, pages 5220–5223. PMLR,
-
[17]
Since T contains both signs of each test in A, this is exactly OIErrP (Q; A)
On the intersection of the two events, the population residual is bounded by the claimed quantity for every signed test in T . Since T contains both signs of each test in A, this is exactly OIErrP (Q; A). Finally, M≤ 2|A| and supp(Qx) ⊆ Λx because each online action has this support. E Deterministic panprediction from OI tests We use the notation of Balak...
2026
-
[18]
We use the standard Chernoff–Hoeffding moment bound for bounded k-wise independent sums [Schmidt et al., 1995]: if ZC are mean-zero, k-wise independent, |ZC| ≤b C, and B2 =P C b2 C, then for evenk, P X C ZC > C1B √ k ! ≤exp(−k). For the simple form used here, this follows directly from the usualkth-moment proof for independent bounded sums, since the kth ...
1995
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.