Investigating Self-Attention Network for Chinese Word Segmentation
Pith reviewed 2026-05-24 15:54 UTC · model grok-4.3
The pith
Self-attention networks achieve highly competitive results with BiLSTM-CRF on Chinese word segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Self-attention networks give highly competitive results compared with BiLSTMs, with BERT and word information further improving segmentation for in-domain and cross-domain segmentation; the final models give the best results for 6 heterogeneous domain benchmarks.
What carries the argument
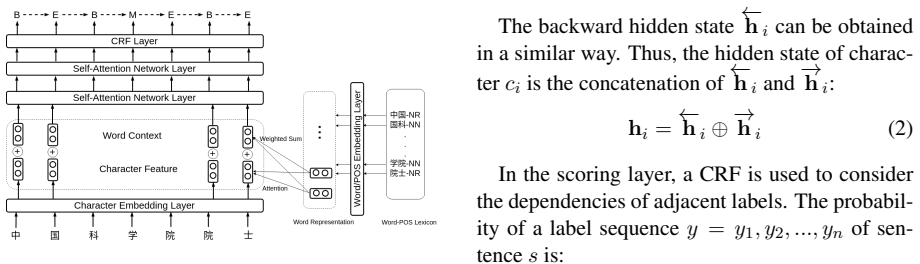
Self-attention network applied to sequence labeling for Chinese word segmentation, with optional BERT embeddings and word-information integration.
If this is right
- SAN models can replace BiLSTMs for Chinese word segmentation without loss of accuracy.
- BERT embeddings provide consistent gains on top of either architecture.
- Explicit word-information integration improves cross-domain generalization.
- The combined SAN + BERT + word model sets new best scores on multiple domain benchmarks.
Where Pith is reading between the lines
- If SAN scales similarly on other sequence-labeling tasks, it could replace recurrent backbones more broadly in NLP.
- The parallel nature of SAN opens the possibility of training larger segmentation models on the same hardware budget.
- Cross-domain gains suggest the architecture may reduce the need for domain-specific retraining in practice.
Load-bearing premise
The experimental comparisons between SAN and BiLSTM-CRF models are fair, with no hidden differences in hyper-parameters, preprocessing, or evaluation that favor one architecture.
What would settle it
A controlled experiment that re-runs both SAN and BiLSTM-CRF under identical hyper-parameters, data splits, and evaluation code and finds SAN accuracy materially lower than BiLSTM accuracy.
Figures



read the original abstract
Neural network has become the dominant method for Chinese word segmentation. Most existing models cast the task as sequence labeling, using BiLSTM-CRF for representing the input and making output predictions. Recently, attention-based sequence models have emerged as a highly competitive alternative to LSTMs, which allow better running speed by parallelization of computation. We investigate self attention network for Chinese word segmentation, making comparisons between BiLSTM-CRF models. In addition, the influence of contextualized character embeddings is investigated using BERT, and a method is proposed for integrating word information into SAN segmentation. Results show that SAN gives highly competitive results compared with BiLSTMs, with BERT and word information further improving segmentation for in-domain and cross-domain segmentation. Our final models give the best results for 6 heterogenous domain benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript investigates self-attention networks (SAN) for Chinese word segmentation (CWS) as an alternative to BiLSTM-CRF sequence labeling models. It examines the addition of BERT contextualized embeddings and proposes a method for integrating word information into SAN. The central claim is that SAN yields highly competitive results versus BiLSTMs, that BERT and word information further improve both in-domain and cross-domain performance, and that the final models achieve the best results across six heterogeneous domain benchmarks.
Significance. If the head-to-head comparisons prove fair, the work would establish SAN as a practical, parallelizable substitute for BiLSTM-CRF in CWS and illustrate the additive value of pre-trained embeddings plus explicit word features; the multi-domain evaluation would strengthen claims of robustness.
major comments (2)
- [Abstract / Experiments] Abstract and experimental sections: the headline claim that SAN (and final BERT+word models) outperform or match BiLSTM-CRF on six benchmarks rests on the unverified premise that hyper-parameter search budgets, character embedding initialization, learning-rate schedules, early-stopping rules, and preprocessing pipelines (OOV handling, sentence segmentation, cross-domain adaptation) were held constant; no such equivalence is documented, so observed F1 differences cannot be attributed to architecture.
- [Abstract / Results] Results presentation: the abstract asserts 'best results for 6 heterogeneous domain benchmarks' yet reports neither raw F1 scores, baseline numbers, standard deviations, nor statistical significance tests; without these quantities the magnitude and reliability of the claimed improvements cannot be evaluated.
minor comments (1)
- [Abstract] The abstract refers to 'six heterogenous domain benchmarks' without naming the datasets or citing their sources.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on our work investigating self-attention networks for Chinese word segmentation. We address the two major comments point by point below, focusing on experimental fairness and results reporting. Where revisions are needed to strengthen the manuscript, we indicate them explicitly.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and experimental sections: the headline claim that SAN (and final BERT+word models) outperform or match BiLSTM-CRF on six benchmarks rests on the unverified premise that hyper-parameter search budgets, character embedding initialization, learning-rate schedules, early-stopping rules, and preprocessing pipelines (OOV handling, sentence segmentation, cross-domain adaptation) were held constant; no such equivalence is documented, so observed F1 differences cannot be attributed to architecture.
Authors: We agree that documenting equivalence in experimental conditions is essential for attributing performance differences to the architecture. The manuscript follows standard preprocessing and hyperparameter settings reported in prior BiLSTM-CRF CWS work (e.g., same character embeddings, learning rate schedules, and early stopping criteria), with SAN-specific tuning performed under comparable search effort. However, the paper does not explicitly tabulate or describe the full search budgets and preprocessing equivalence. We will revise the experimental section to include a dedicated subsection detailing the shared preprocessing pipeline, embedding initialization, and hyperparameter search protocol for both SAN and BiLSTM-CRF models, confirming that the same settings were applied across architectures. revision: yes
-
Referee: [Abstract / Results] Results presentation: the abstract asserts 'best results for 6 heterogeneous domain benchmarks' yet reports neither raw F1 scores, baseline numbers, standard deviations, nor statistical significance tests; without these quantities the magnitude and reliability of the claimed improvements cannot be evaluated.
Authors: The abstract provides a high-level summary due to length constraints and refers readers to the experimental results for details. The full manuscript contains tables reporting F1 scores for SAN, BiLSTM-CRF, BERT-augmented variants, and word-integrated models across all six benchmarks. We did not include standard deviations (from multiple random seeds) or formal significance tests in the original submission. We will revise the experimental section to report mean F1 with standard deviations over multiple runs and add pairwise significance tests (e.g., via bootstrap or t-test) for the key comparisons. The abstract itself will remain unchanged as it is a summary, but we will ensure the main text makes the quantitative evidence fully transparent. revision: partial
Circularity Check
No circularity: empirical results on held-out benchmarks
full rationale
The paper reports experimental F1 scores from training and evaluating SAN, BiLSTM-CRF, BERT-augmented, and word-information models on six heterogeneous Chinese word segmentation test sets. These are direct measurements on independent held-out data; the abstract and described content contain no equations, fitted parameters renamed as predictions, or self-citation chains that reduce any claimed performance number to an input quantity by construction. The central claims are therefore self-contained empirical comparisons.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We extend the model of Vaswani et al. (2017) for the SAN segmentor. The model has multiple identical layers, each of which is composed of a multi-head self-attention sub-layer and a position-wise fully connected feed-forward network.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Results show that SAN gives highly competitive results compared with BiLSTMs, with BERT and word information further improving segmentation for in-domain and cross-domain segmentation.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Fast and accurate neural word segmentation for chinese. In Proceedings of the 55th Annual Meeting of the As- sociation for Computational Linguistics (Volume 2: Short Papers), volume 2, pages 608–615. Xinchi Chen, Xipeng Qiu, Chenxi Zhu, and Xuanjing Huang. 2015a. Gated recursive neural network for chinese word segmentation. In Proceedings of the 53rd Annu...
work page 2015
-
[2]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Bert: Pre-training of deep bidirectional transformers for language understand- ing. arXiv preprint arXiv:1810.04805. Jeffrey L Elman
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. Nikita Kitaev and Dan Klein
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Proceedings of COLING 2012: Posters, pages 745–
Unsupervised domain adaptation for joint segmentation and pos-tagging. Proceedings of COLING 2012: Posters, pages 745–
work page 2012
-
[5]
Effective Approaches to Attention-based Neural Machine Translation
Effective approaches to attention- based neural machine translation. arXiv preprint arXiv:1508.04025. Ji Ma, Kuzman Ganchev, and David Weiss
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
State-of-the-art chinese word segmentation with bi- lstms. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Process- ing, pages 4902–4908. Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Cor- rado, and Jeff Dean
work page 2018
-
[7]
Glove: Global vectors for word representation. In Proceedings of the 2014 confer- ence on empirical methods in natural language pro- cessing (EMNLP), pages 1532–1543. Matthew E Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer
work page 2014
-
[8]
Deep contextualized word representations
Deep contextualized word rep- resentations. arXiv preprint arXiv:1802.05365. Likun Qiu and Yue Zhang
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Directional skip-gram: Explicitly distinguish- ing left and right context for word embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computa- tional Linguistics: Human Language Technologies, Volume 2 (Short Papers), volume 2, pages 175–180. Emma Strubell, Patrick Verga, Daniel Andor, David Weiss, and An...
work page 2018
-
[10]
Linguistically-informed self-attention for semantic role labeling. In Proceedings of the 2018 Confer- ence on Empirical Methods in Natural Language Processing, pages 5027–5038. Weiwei Sun and Jia Xu
work page 2018
-
[11]
Why self-attention? a targeted eval- uation of neural machine translation architectures. In Proceedings of the 2018 Conference on Empiri- cal Methods in Natural Language Processing, pages 4263–4272. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin
work page 2018
-
[12]
Chinese word segmentation as character tagging. International Journal of Compu- tational Linguistics & Chinese Language Process- ing, Volume 8, Number 1, February 2003: Special Issue on Word Formation and Chinese Language Processing, 8(1):29–48. Jie Yang, Yue Zhang, and Fei Dong
work page 2003
-
[13]
Neural Word Segmentation with Rich Pretraining
Neu- ral word segmentation with rich pretraining. arXiv preprint arXiv:1704.08960. Jie Yang, Yue Zhang, and Shuailong Liang
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Subword Encoding in Lattice LSTM for Chinese Word Segmentation
Sub- word encoding in lattice lstm for chinese word seg- mentation. arXiv preprint arXiv:1810.12594. Yuxiao Ye, Weikang Li, Yue Zhang, Likun Qiu, and Jian Sun
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
arXiv preprint arXiv:1903.01698
Improving cross-domain chinese word segmentation with word embeddings. arXiv preprint arXiv:1903.01698. Meishan Zhang, Yue Zhang, Wanxiang Che, and Ting Liu
-
[16]
Word-context character embeddings for chinese word segmenta- tion. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Process- ing, pages 760–766
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.