Mechanisms of Object Localization in Vision-Language Models
Pith reviewed 2026-05-20 06:42 UTC · model grok-4.3
The pith
Vision-language models localize objects by using specific tokens to mark boundaries, with the arrangement of tokens inside those boundaries having little impact on the box prediction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
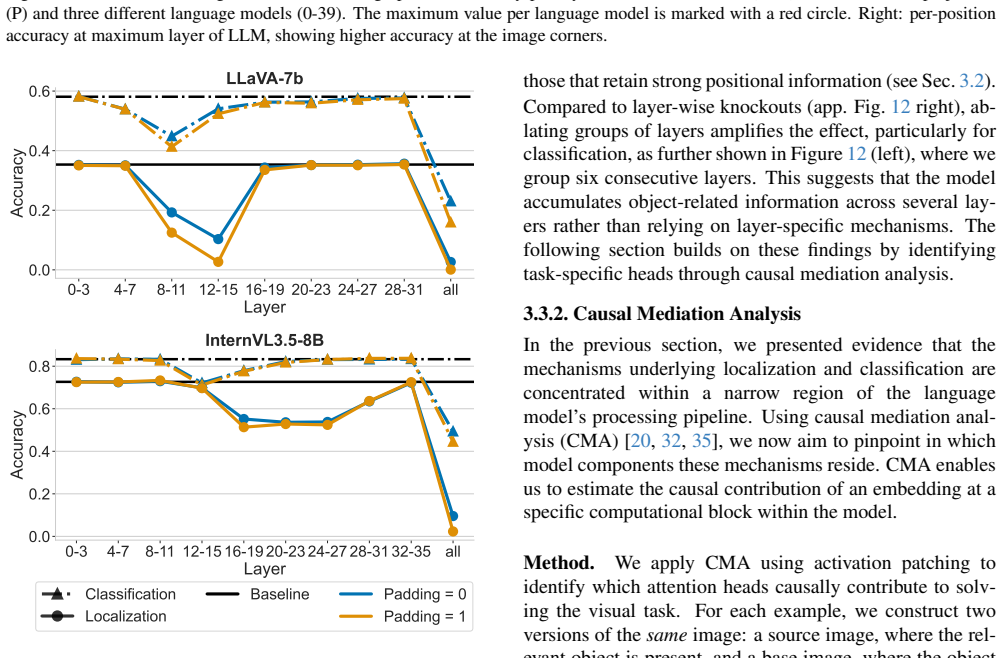
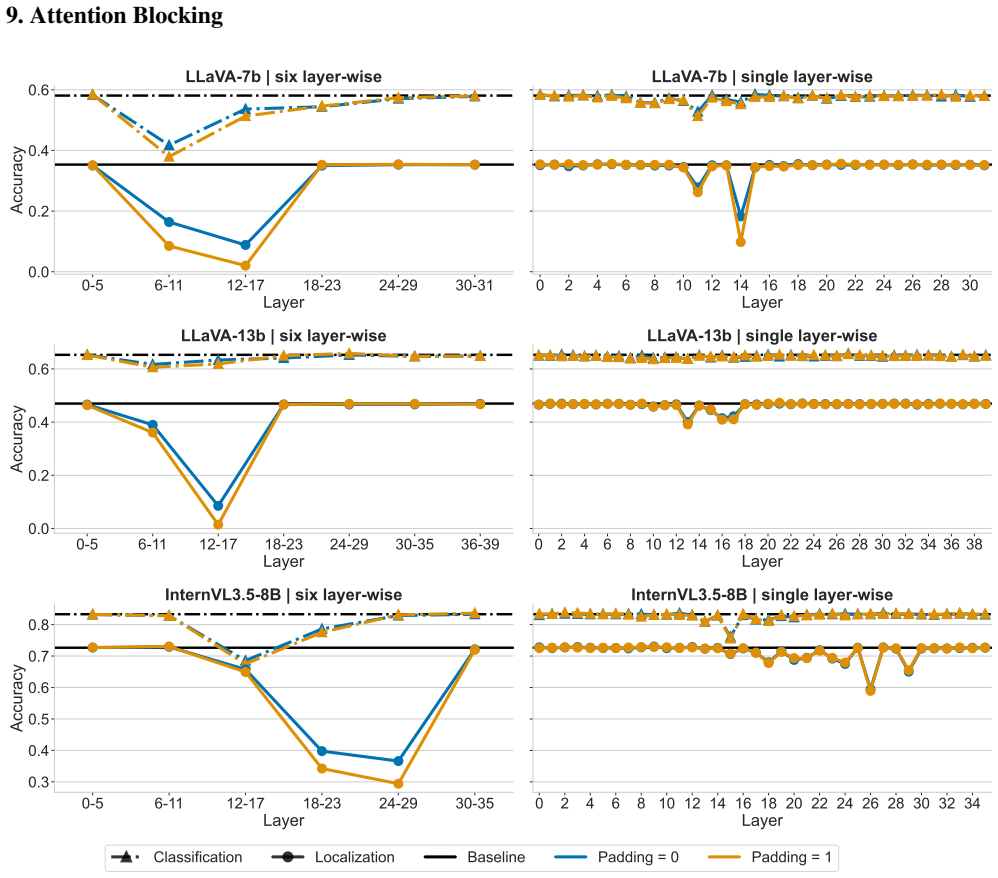
Localization is driven by a containerization mechanism in which object-aligned tokens define the spatial extent of the object, while the semantic arrangement of tokens within those boundaries is largely irrelevant to the predicted box. Only a very small set of attention heads mediates the causal effect for both classification and localization, concentrating in early-mid layers for LLaVA and mid-late layers for InternVL. The two tasks share some early processing but ultimately depend on largely distinct specialized heads.
What carries the argument
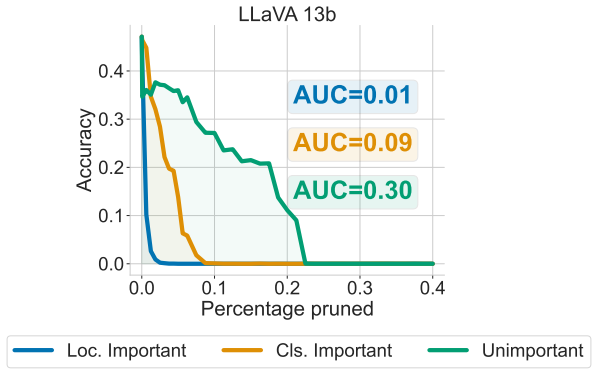
Containerization mechanism, where object-aligned tokens define the spatial extent of the object for the localization task.
If this is right
- Revealing these narrow computational pathways can guide future model design for better visual grounding.
- Grounding objectives can be optimized around boundary definition rather than full semantic processing inside objects.
- Interventions on the small set of specialized heads could simultaneously affect classification and localization performance.
- The layer differences between models suggest architecture-dependent strategies for improving localization.
Where Pith is reading between the lines
- Similar containerization might occur in other multimodal models, allowing targeted debugging of localization errors.
- Models could be made more efficient by focusing training resources on the identified attention heads.
- Prompt engineering that targets boundary tokens might selectively impair or enhance localization without affecting other capabilities.
Load-bearing premise
Token ablations and attention knockouts isolate the exact causal roles of specific tokens and heads without interference from remaining model components or dependence on the particular images and prompts tested.
What would settle it
Ablating the identified small set of attention heads on a fresh set of images and prompts, then finding that localization performance stays intact or shifts to other heads, would show the claimed mechanism does not hold generally.
Figures










read the original abstract
Visually-grounded language models (VLMs) are highly effective in linking visual and textual information, yet they often struggle with basic classification and localization tasks. While classification mechanisms have been studied more extensively, the processes that support object localization remain poorly understood. In this work, we investigate two representative families, LLaVA-1.5 and InternVL-3.5, using a suite of mechanistic interpretability tools, including token ablations, attention knockout, and causal mediation analysis. We find that localization is driven by a containerization mechanism in which object-aligned tokens define the spatial extent of the object, while the semantic arrangement of tokens within those boundaries is largely irrelevant to the predicted box. Only a very small set of attention heads mediates the causal effect for both classification and localization, concentrating in early-mid layers for LLaVA and mid-late layers for InternVL. The two tasks share some early processing but ultimately depend on largely distinct specialized heads. Overall, we provide the first layer- and head-level account of localization in VLMs, revealing narrow computational pathways that can guide future model design and grounding objectives.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates mechanisms of object localization in VLMs (LLaVA-1.5 and InternVL-3.5) via token ablations, attention knockout, and causal mediation analysis. It claims localization follows a containerization mechanism in which object-aligned tokens set spatial extent while internal semantic arrangement is largely irrelevant to the predicted box; only a small set of attention heads (early-mid layers in LLaVA, mid-late in InternVL) mediates causal effects for both classification and localization, with shared early processing but distinct later heads.
Significance. If the interventional results hold, the work supplies the first layer- and head-level mechanistic account of localization in VLMs. The identification of narrow computational pathways and the containerization finding could directly inform grounding objectives and architecture choices. The reliance on causal interventions rather than purely correlational measures is a methodological strength.
major comments (2)
- [Results and Causal Mediation Analysis sections] The containerization claim and narrow-head conclusion rest on the assumption that token ablations and attention knockouts cleanly isolate contributions without compensatory interference from remaining heads or layers. The manuscript does not report controls for this (e.g., random-head knockouts or tests for performance recovery in unablated components), which is load-bearing for the central mechanism.
- [Token Ablation Experiments] The finding that semantic arrangement inside object-aligned tokens is irrelevant depends on the specific images and prompts tested. No robustness checks across prompt variations or diverse image datasets are described, leaving open the possibility that the 'irrelevant arrangement' result is sensitive to experimental choices.
minor comments (2)
- [Methods] Clarify the exact quantitative thresholds used to identify the 'very small set' of mediating heads (e.g., effect-size cutoffs in the mediation analysis).
- [Figures] Ensure all figures showing head concentrations include explicit layer and head indices for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major point below and outline revisions that strengthen the manuscript's methodological rigor and robustness.
read point-by-point responses
-
Referee: [Results and Causal Mediation Analysis sections] The containerization claim and narrow-head conclusion rest on the assumption that token ablations and attention knockouts cleanly isolate contributions without compensatory interference from remaining heads or layers. The manuscript does not report controls for this (e.g., random-head knockouts or tests for performance recovery in unablated components), which is load-bearing for the central mechanism.
Authors: We agree that explicit controls for compensatory interference are necessary to support the specificity of the identified heads and the containerization mechanism. While the causal mediation analysis already isolates effects at the head level, we recognize that the original submission lacked random ablation baselines. We have since run additional experiments ablating matched numbers of randomly selected heads across the same layers; these show substantially smaller performance drops in both localization and classification compared to ablating the specialized heads. We will add these control results, along with a discussion of their implications, to the Results and Causal Mediation Analysis sections in the revised manuscript. revision: yes
-
Referee: [Token Ablation Experiments] The finding that semantic arrangement inside object-aligned tokens is irrelevant depends on the specific images and prompts tested. No robustness checks across prompt variations or diverse image datasets are described, leaving open the possibility that the 'irrelevant arrangement' result is sensitive to experimental choices.
Authors: We concur that the irrelevance of internal token arrangement within object boundaries requires demonstration of robustness. The original experiments spanned multiple object categories and image sources, yet did not include systematic prompt paraphrasing or additional datasets. We will therefore incorporate new experiments that vary prompt wording (e.g., different phrasings of the localization query) and evaluate on a broader collection of images drawn from additional benchmarks. These results will be reported in an expanded Token Ablation Experiments section to confirm that the containerization finding is not an artifact of the original experimental choices. revision: yes
Circularity Check
No circularity: empirical interventions produce independent mechanistic findings
full rationale
The paper reports results from token ablations, attention knockout, and causal mediation analysis applied to LLaVA-1.5 and InternVL-3.5. These interventions directly yield the containerization mechanism, narrow head involvement, and task-specific specialization as experimental outputs. No equations, fitted parameters, or self-citations are invoked to derive the central claims; the findings are not presupposed by the methods or reduced to inputs by construction. The work is self-contained against external benchmarks of interpretability tooling.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Token ablations, attention knockout, and causal mediation analysis accurately identify causal contributions of individual heads and tokens in transformer-based VLMs.
Reference graph
Works this paper leans on
-
[1]
Jinze Bai, Shuai Bai, Shusheng Yang, et al. Qwen-vl: A ver- satile vision-language model for understanding, localization, text reading, and beyond, 2023. 1, 8
work page 2023
-
[2]
Samyadeep Basu, Martin Grayson, Cecily Morrison, et al. Understanding information storage and transfer in multi- modal large language models.Advances in Neural Informa- tion Processing Systems, 37:7400–7426, 2024. 8
work page 2024
-
[3]
Grounding everything: Emerging localiza- tion properties in vision-language transformers
Walid Bousselham, Felix Petersen, Vittorio Ferrari, and Hilde Kuehne. Grounding everything: Emerging localiza- tion properties in vision-language transformers. InProceed- ings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3828–3837, 2024. 1
work page 2024
-
[4]
Understanding the limits of vision language models through the lens of the binding problem
Declan Iain Campbell, Sunayana Rane, and Tyler Giallanza. Understanding the limits of vision language models through the lens of the binding problem. InThe Thirty-eighth An- nual Conference on Neural Information Processing Systems,
-
[5]
Why is spa- tial reasoning hard for VLMs? an attention mechanism per- spective on focus areas
Shiqi Chen, Tongyao Zhu, and Ruochen Zhou. Why is spa- tial reasoning hard for VLMs? an attention mechanism per- spective on focus areas. InForty-second International Con- ference on Machine Learning, 2025. 8
work page 2025
-
[6]
Internvl: Scal- ing up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, et al. Internvl: Scal- ing up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24185–24198, 2024. 2
work page 2024
-
[7]
Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality,
Wei-Lin Chiang, Zhuohan Li, Zi Lin, et al. Vicuna: An open- source chatbot impressing gpt-4 with 90%* chatgpt quality,
-
[8]
Wenliang Dai, Junnan Li, Dongxu Li, et al. Instructblip: To- wards general-purpose vision-language models with instruc- tion tuning.Advances in neural information processing sys- tems, 36:49250–49267, 2023. 1
work page 2023
-
[9]
Vision transformers need registers
Timoth ´ee Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. InThe Twelfth International Conference on Learning Representa- tions, 2024. 3
work page 2024
-
[10]
Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models
Matt Deitke, Christopher Clark, Sangho Lee, et al. Molmo and pixmo: Open weights and open data for state-of-the-art vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 91–104,
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, et al. Imagenet: A large-scale hierarchical image database. In2009 IEEE con- ference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3
work page 2009
-
[12]
Williams, John Winn, and Andrew Zisserman
Mark Everingham, Luc Gool, Christopher K. Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge.Int. J. Comput. Vision, 88(2): 303–338, 2010. 3, 4
work page 2010
-
[13]
Dissecting recall of factual associations in auto- regressive language models
Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto- regressive language models. InProceedings of the 2023 Con- ference on Empirical Methods in Natural Language Process- ing, pages 12216–12235, 2023. 5
work page 2023
-
[14]
Dongsheng Jiang, Yuchen Liu, Songlin Liu, et al. From clip to dino: Visual encoders shout in multi-modal large language models.arXiv preprint arXiv:2310.08825, 2023. 5
-
[15]
Interpreting and editing vision-language representations to mitigate hallucinations
Nicholas Jiang, Anish Kachinthaya, Suzanne Petryk, and Yossi Gandelsman. Interpreting and editing vision-language representations to mitigate hallucinations. InThe Thir- teenth International Conference on Learning Representa- tions, 2025. 8
work page 2025
-
[16]
What’s in the im- age? a deep-dive into the vision of vision language models
Omri Kaduri, Shai Bagon, and Tali Dekel. What’s in the im- age? a deep-dive into the vision of vision language models. InProceedings of the Computer Vision and Pattern Recogni- tion Conference, pages 14549–14558, 2025. 8
work page 2025
-
[17]
Qiming Li, Zekai Ye, Xiaocheng Feng, Weihong Zhong, Weitao Ma, and Xiachong Feng. Causal tracing of object representations in large vision language models: Mechanis- tic interpretability and hallucination mitigation. InProceed- ings of the AAAI Conference on Artificial Intelligence, pages 31645–31653, 2026. 8
work page 2026
-
[18]
Mi- crosoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, et al. Mi- crosoft coco: Common objects in context. InEuropean con- ference on computer vision, pages 740–755. Springer, 2014. 2, 1, 5
work page 2014
-
[19]
Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning.Advances in neural information processing systems, 36:34892–34916, 2023. 1, 2
work page 2023
-
[20]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Be- linkov. Locating and editing factual associations in gpt. In Proceedings of the 36th International Conference on Neural Information Processing Systems, Red Hook, NY , USA, 2022. Curran Associates Inc. 6
work page 2022
-
[21]
Towards in- terpreting visual information processing in vision-language models
Clement Neo, Luke Ong, Philip Torr, et al. Towards in- terpreting visual information processing in vision-language models. InThe Thirteenth International Conference on Learning Representations, 2025. 1, 5
work page 2025
-
[22]
Towards vision-language mechanistic interpretabil- ity: A causal tracing tool for blip
Vedant Palit, Rohan Pandey, Aryaman Arora, and Paul Pu Liang. Towards vision-language mechanistic interpretabil- ity: A causal tracing tool for blip. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2856–2861, 2023. 8
work page 2023
-
[23]
Georgios Pantazopoulos and Eda B ¨Ozyi˘git. Towards under- standing visual grounding in visual language models.arXiv preprint arXiv:2509.10345, 2025. 8
-
[24]
Grounding multimodal large language models to the world
Zhiliang Peng, Wenhui Wang, Li Dong, et al. Grounding multimodal large language models to the world. InThe Twelfth International Conference on Learning Representa- tions, 2024. 8
work page 2024
-
[25]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, et al. Learning transferable visual models from natural language supervision. InInter- national conference on machine learning, pages 8748–8763. PmLR, 2021. 1, 2
work page 2021
-
[26]
Sunayana Rane, Alexander Ku, and Jason Michael Baldridge. Can generative multimodal models count to ten? InICLR 2024 Workshop on Representational Align- ment, 2024. 8
work page 2024
-
[27]
Ex- plore the potential of clip for training-free open vocabulary semantic segmentation
Tong Shao, Zhuotao Tian, Hang Zhao, and Jingyong Su. Ex- plore the potential of clip for training-free open vocabulary semantic segmentation. InEuropean Conference on Com- puter Vision, pages 139–156. Springer, 2024. 1
work page 2024
-
[28]
Benchmark- ing object detectors with coco: A new path forward
Shweta Singh, Aayan Yadav, Jitesh Jain, et al. Benchmark- ing object detectors with coco: A new path forward. 2024. 2, 1
work page 2024
-
[29]
Axiomatic attribution for deep networks
Mukund Sundararajan, Ankur Taly, and Qiqi Yan. Axiomatic attribution for deep networks. InInternational conference on machine learning, pages 3319–3328. PMLR, 2017. 3
work page 2017
-
[30]
Resolution-robust large mask inpainting with fourier convolutions
Roman Suvorov, Elizaveta Logacheva, Anton Mashikhin, et al. Resolution-robust large mask inpainting with fourier convolutions. In2022 IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 3172–3182,
-
[31]
Eyes wide shut? exploring the visual shortcomings of multi- modal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, et al. Eyes wide shut? exploring the visual shortcomings of multi- modal llms. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9568– 9578, 2024. 1
work page 2024
-
[32]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Ro Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. In The Eleventh International Conference on Learning Repre- sentations, 2023. 6
work page 2023
-
[33]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265,
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
An Yang, Anfeng Li, Baosong Yang, et al. Qwen3 technical report, 2025. 2
work page 2025
-
[35]
Yukang Yang, Declan Campbell, Kaixuan Huang, Mengdi Wang, Jonathan Cohen, and Taylor Webb. Emergent sym- bolic mechanisms support abstract reasoning in large lan- guage models.Proceedings of Machine Learning Research, 267:70515–70549, 2025. 6
work page 2025
-
[36]
Zhuoran Yu and Yong Jae Lee. How multimodal LLMs solve image tasks: A lens on visual grounding, task reasoning, and answer decoding. InSecond Conference on Language Mod- eling, 2025. 8
work page 2025
-
[37]
Llava-grounding: Grounded visual chat with large multimodal models
Hao Zhang, Hongyang Li, Feng Li, et al. Llava-grounding: Grounded visual chat with large multimodal models. In European Conference on Computer Vision, pages 19–35. Springer, 2024. 8
work page 2024
-
[38]
Yuhui Zhang, Alyssa Unell, Xiaohan Wang, et al. Why are visually-grounded language models bad at image classifica- tion? InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. 1, 8
work page 2024
-
[39]
Re- gionclip: Region-based language-image pretraining
Yiwu Zhong, Jianwei Yang, Pengchuan Zhang, et al. Re- gionclip: Region-based language-image pretraining. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16793–16803, 2022. 1 Mechanisms of Object Localization in Vision–Language Models Supplementary Material
work page 2022
-
[40]
Dataset We provide additional details on dataset construction, task prompting, and representative examples. 6.1. Dataset Filtering Details We evaluate on the COCO validation split [18] with label corrections from [28], and apply the following filtering steps to improve annotation quality and satisfy the requirements of our experimental setup. 1.Object siz...
-
[41]
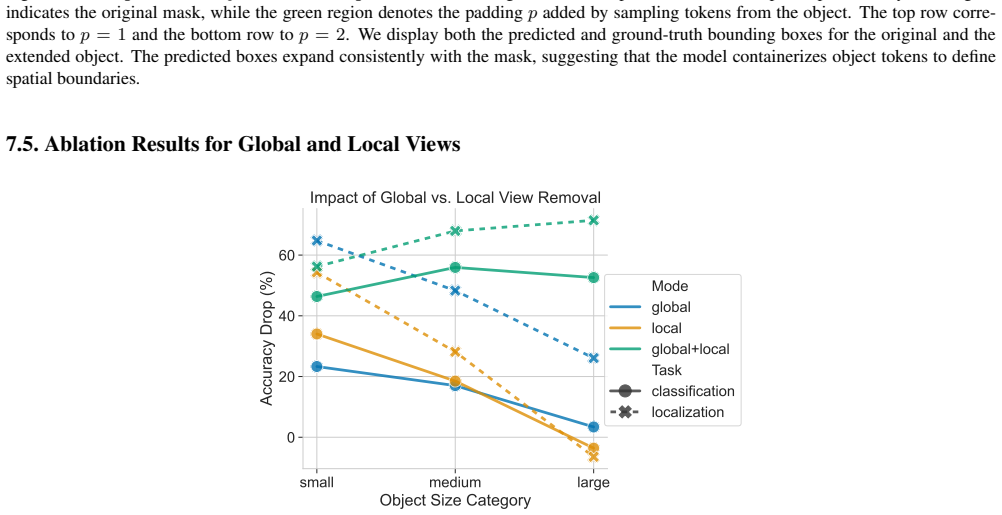
Ablation Study 7.1. Visualization of Masking 0 100 200 300 0 50 100 150 200 250 300 Image with ground-truth Mask 0 5 10 15 20 0 5 10 15 20 Resized Mask 0 5 10 15 20 0 5 10 15 20 Mask with Padding Padding T ypes Padding = -2 Padding = -1 Padding = 0 Padding = +1 Padding = +2 Figure 7.Visualization of object mask for the ablation experiment. Left: the origi...
-
[42]
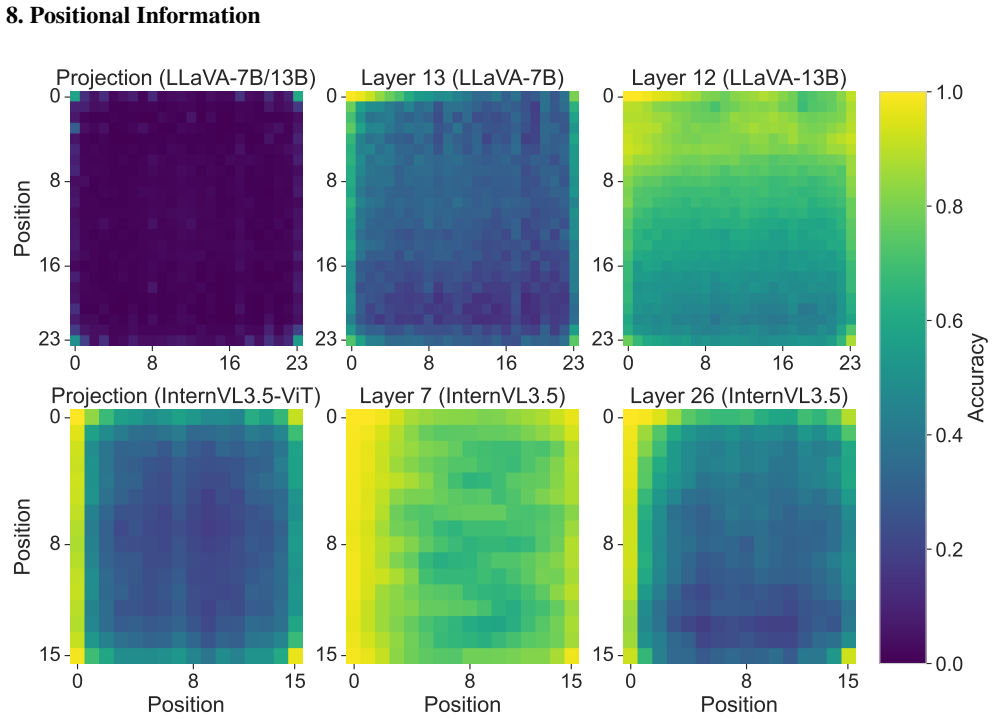
Positional Information 0 8 16 23 0 8 16 23 Position Projection (LLaVA-7B/13B) 0 8 16 23 0 8 16 23 Layer 13 (LLaVA-7B) 0 8 16 23 0 8 16 23 Layer 12 (LLaVA-13B) 0 8 15 Position 0 8 15 Position Projection (InternVL3.5-ViT) 0 8 15 Position 0 8 15 Layer 7 (InternVL3.5) 0 8 15 Position 0 8 15 Layer 26 (InternVL3.5) 0.0 0.2 0.4 0.6 0.8 1.0 Accuracy Figure 11.Hea...
-
[43]
Attention Blocking 0-5 6-11 12-17 18-23 24-29 30-31 Layer 0.0 0.2 0.4 0.6Accuracy LLaVA-7b | six layer-wise 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 Layer LLaVA-7b | single layer-wise 0-5 6-11 12-17 18-23 24-29 30-35 36-39 Layer 0.0 0.2 0.4 0.6Accuracy LLaVA-13b | six layer-wise 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30 32 34 36 38 Layer LLaVA-13b | si...
-
[44]
Causal Mediation Analysis 10.1. Visualization of CMA Method ViT Is there a motorcycle in the image? P Yes No ViT Is there a motorcycle in the image? P
-
[45]
Patched Run ViT Is there a motorcycle in the image? P LLM LLM LLM Activation Transfer1. Source Run
-
[46]
Base Run Yes No Yes No Logits Logits Logits Transformer Layer Attention Head Forward Pass Legend: Patching Figure 13.Causal mediation via activation patching.We compare three model runs: (1) the source run, where the object is present and the model produces the correct answer; (2) the base run, where the object is removed and the model fails; and (3) the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.