Automating Information Extraction and Retrieval for Industrial Spare Parts Pooling
Pith reviewed 2026-06-28 08:20 UTC · model grok-4.3
The pith
Generative language models structure inconsistent spare part data into a virtual pool and retrieve matches with justifications under data scarcity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
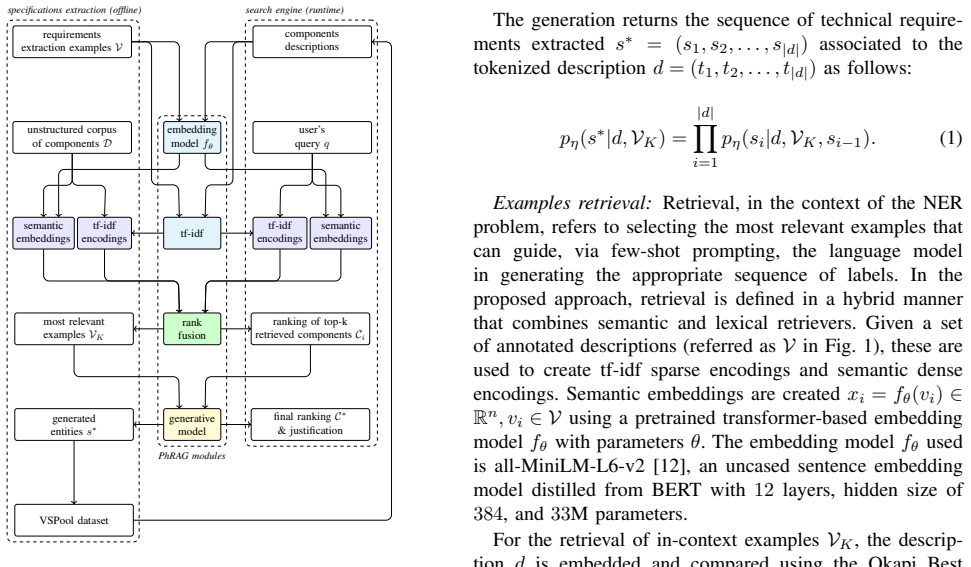
The central claim is that the PhRAG modular pipeline, by exploiting the multitasking capabilities of generative language models, performs offline named entity recognition on unstructured technical specifications from diverse sources and supports hybrid RAG retrieval that returns relevant components together with justifications, thereby creating an actionable virtual stock pool even when labeled data is scarce.
What carries the argument
The PhRAG modular pipeline that applies generative language models to offline NER-based extraction and to runtime hybrid RAG search with result justifications.
Load-bearing premise
Generative language models can reliably extract entities from technical specifications and generate accurate retrieval justifications on industrial spare part data without domain-specific fine-tuning or quantitative validation.
What would settle it
A side-by-side test on a held-out collection of real spare part listings from multiple partners that measures entity extraction accuracy and retrieval relevance for the generative pipeline versus standard NER and keyword search methods.
Figures
read the original abstract
Maintenance organizations in manufacturing try to avoid downtime and unnecessary purchasing by reusing existing assets, but the main obstacle is not a lack of parts but a lack of actionable visibility across sites and partners. Inventories are distributed, described with inconsistent naming conventions, and contain duplicates and partially specified references, so the right part often exists somewhere but remains effectively undiscoverable. The paper proposes PhRAG, a hybrid Retrieval-Augmented Generation for pooling this fragmented landscape into a Virtual Stock Pool (VSPool) that can be structured and searched as a single resource. Heterogeneous spare part descriptions are structured via Named Entity Recognition (NER) into a shared virtual pool dataset and indexed to support robust retrieval even when users express needs in natural language rather than exact technical specifications. The proposed modular pipeline leverages the multitasking nature of generative language models to cover two dimensions that make industrial parts pooling challenging: ($\boldsymbol{i}$) unstructured technical specifications from diverse data sources (e.g. new partners, catalogs, marketplace listings) are handled through an offline extraction and ($\boldsymbol{ii}$) request variability at runtime (references, partial references, specifications, price/condition constraints) is handled through a hybrid RAG-based search engine capable of retrieving relevant components and justifying results. The framework demonstrates the potential of generative approaches compared with traditional NER approaches in the presence of data scarcity for technical specifications extraction and overcomes the opacity of standard information retrieval systems by generating justifications for retrieved components.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes PhRAG, a hybrid Retrieval-Augmented Generation system for industrial spare-parts pooling. Heterogeneous descriptions are processed offline via multitasking generative LLMs performing NER-style extraction into a Virtual Stock Pool (VSPool); at runtime a hybrid RAG engine retrieves components from natural-language or partial-specification queries and supplies textual justifications. The central claim is that this generative pipeline outperforms traditional NER under data scarcity and removes the opacity of standard IR systems.
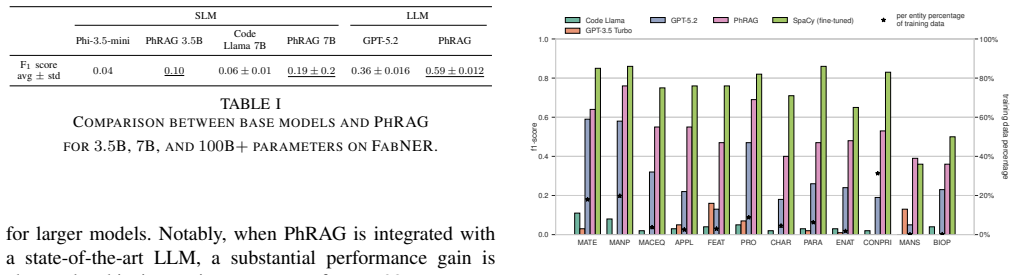
Significance. If the claimed extraction and retrieval performance were demonstrated, the work would address a concrete industrial pain point—discoverability across fragmented, inconsistently described inventories—by combining offline structuring with explainable retrieval. The modular design that separates extraction from retrieval is a practical strength, but the absence of any quantitative validation prevents the significance from being realized in the current manuscript.
major comments (3)
- [Abstract] Abstract: the statement that the framework 'demonstrates the potential of generative approaches compared with traditional NER approaches in the presence of data scarcity' is unsupported; the manuscript contains no precision/recall figures, no baseline comparisons (spaCy, CRF, fine-tuned BERT, etc.), no ablation on scarcity levels, and no retrieval metrics (nDCG, MRR) or human evaluation of justification quality.
- [Abstract] Abstract and system description: the claim that the hybrid RAG component 'overcomes the opacity of standard information retrieval systems by generating justifications' is presented as a demonstrated advantage, yet no evaluation of justification faithfulness, user utility, or comparison against black-box retrievers is provided.
- [System description (throughout)] The modular pipeline is described at the architectural level (offline extraction + runtime hybrid search) but supplies no implementation details, prompting strategies, or fine-tuning procedures that would allow reproduction or assessment of reliability under the stated data-scarcity regime.
minor comments (2)
- [Abstract] The acronyms PhRAG and VSPool are introduced without an explicit expansion on first use.
- [Conclusion] The manuscript would benefit from a dedicated 'Limitations' or 'Future Work' section that acknowledges the current lack of empirical validation.
Simulated Author's Rebuttal
We thank the referee for the constructive critique. We agree that several claims in the abstract are presented too strongly without supporting evidence and that the system description lacks sufficient implementation detail for reproducibility. We have revised the manuscript to qualify the claims, remove unsupported assertions, and expand the technical description. Point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that the framework 'demonstrates the potential of generative approaches compared with traditional NER approaches in the presence of data scarcity' is unsupported; the manuscript contains no precision/recall figures, no baseline comparisons (spaCy, CRF, fine-tuned BERT, etc.), no ablation on scarcity levels, and no retrieval metrics (nDCG, MRR) or human evaluation of justification quality.
Authors: We agree the wording 'demonstrates' is not supported by quantitative results in the current manuscript. The revised abstract now reads 'proposes a framework to explore the potential...' and the conclusion explicitly states that empirical validation against baselines such as spaCy and fine-tuned BERT, including scarcity ablations and retrieval metrics, remains future work. No new experiments have been added in this revision. revision: yes
-
Referee: [Abstract] Abstract and system description: the claim that the hybrid RAG component 'overcomes the opacity of standard information retrieval systems by generating justifications' is presented as a demonstrated advantage, yet no evaluation of justification faithfulness, user utility, or comparison against black-box retrievers is provided.
Authors: We accept that the claim is overstated. The revised abstract and system section now describe the component as one that 'seeks to reduce opacity by generating textual justifications' and include illustrative examples of justifications. We have added a limitations paragraph noting the absence of faithfulness or utility evaluations and listing them as planned future work. revision: yes
-
Referee: [System description (throughout)] The modular pipeline is described at the architectural level (offline extraction + runtime hybrid search) but supplies no implementation details, prompting strategies, or fine-tuning procedures that would allow reproduction or assessment of reliability under the stated data-scarcity regime.
Authors: We have expanded the System Description section with concrete details: the exact prompt templates used for the generative NER extraction (including few-shot examples), the hybrid retrieval implementation (BM25 combined with sentence embeddings and re-ranking), model choices and temperature settings, and pseudocode for VSPool construction. These additions are intended to improve reproducibility assessment while remaining within the scope of a system-description paper. revision: yes
Circularity Check
No significant circularity; descriptive system proposal without derivations or fitted predictions
full rationale
The paper presents a modular pipeline (PhRAG) for offline generative extraction and hybrid RAG retrieval but contains no equations, no fitted parameters, no predictions of quantities, and no derivation chain. Claims about generative NER superiority under data scarcity are stated descriptively without supporting metrics or reductions to inputs. No self-citations function as load-bearing premises that collapse the argument. The contribution is architectural and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (2)
-
PhRAG
no independent evidence
-
VSPool
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A survey of named entity recognition and classification,
D. Nadeau and S. Sekine, “A survey of named entity recognition and classification,”Lingvisticae Investiga- tiones, vol. 30, no. 1, pp. 3–26, 2007
2007
-
[2]
Neural architectures for named entity recognition,
G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, and C. Dyer, “Neural architectures for named entity recognition,” inProceedings of NAACL- HLT, 2016, pp. 260–270
2016
-
[3]
A. Kumar and B. Starly, “Fabner: Information ex- traction from manufacturing process science domain literature using named entity recognition,”Journal of Intelligent Manufacturing, vol. 33, no. 8, pp. 2393– 2407, 2022, © 2021, The Author(s), under exclusive licence to Springer Science+Business Media, LLC. DOI:10.1007/s10845-021-01807-x
-
[4]
R. Armingaud and R. Besanc ¸on,Manufactubert: Ef- ficient continual pretraining for manufacturing, 2025. arXiv:2511.05135 [cs.CL]. [Online]. Available: https://arxiv.org/abs/2511.05135
arXiv 2025
-
[5]
Gpt-ner: Named entity recognition via large language models,
S. Wang et al., “Gpt-ner: Named entity recognition via large language models,” inFindings of the association for computational linguistics: NAACL 2025, 2025, pp. 4257–4275
2025
-
[6]
Gollie: Annotation guidelines improve zero-shot information-extraction,
O. Sainz, I. Garc ´ıa-Ferrero, R. Agerri, O. L. de La- calle, G. Rigau, and E. Agirre, “Gollie: Annotation guidelines improve zero-shot information-extraction,” arXiv preprint arXiv:2310.03668, 2023
arXiv 2023
-
[7]
D. Y .-B. Wang, Z. Shen, S. S. Mishra, Z. Xu, Y . Teng, and H. Ding,Slot: Structuring the output of large language models, 2025. arXiv:2505.04016 [cs.CL]
arXiv 2025
-
[8]
Chat-rec: Towards interactive and explainable llms-augmented recommender system,
Y . Gao, T. Sheng, Y . Xiang, Y . Xiong, H. Wang, and J. Zhang, “Chat-rec: Towards interactive and explainable llms-augmented recommender system,”arXiv preprint arXiv:2303.14524, 2023
arXiv 2023
-
[9]
Gao et al.,Retrieval-augmented generation for large language models: A survey, 2024
Y . Gao et al.,Retrieval-augmented generation for large language models: A survey, 2024. arXiv:2312. 10997 [cs.CL]. [Online]. Available:https:// arxiv.org/abs/2312.10997
Pith/arXiv arXiv 2024
-
[10]
Retrieval-augmented generation for knowledge-intensive nlp tasks,
P. Lewis et al., “Retrieval-augmented generation for knowledge-intensive nlp tasks,”Advances in neural in- formation processing systems, vol. 33, pp. 9459–9474, 2020
2020
-
[11]
Language models are few-shot learners,
T. B. Brown et al., “Language models are few-shot learners,” inAdvances in Neural Information Process- ing Systems (NeurIPS), 2020
2020
-
[12]
Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained trans- formers,
W. Wang, F. Wei, L. Dong, H. Bao, N. Yang, and M. Zhou, “Minilm: Deep self-attention distillation for task-agnostic compression of pre-trained trans- formers,” inProceedings of the 34th International Conference on Neural Information Processing Sys- tems, ser. NIPS ’20, Vancouver, BC, Canada: Curran Associates Inc., 2020,ISBN: 9781713829546
2020
-
[13]
Robertson and H
S. Robertson and H. Zaragoza,The probabilistic rele- vance framework: BM25 and beyond. Now Publishers Inc, 2009, vol. 4
2009
-
[14]
Reciprocal rank fusion outperforms condorcet and individual rank learning methods,
G. V . Cormack, C. L. Clarke, and S. Buettcher, “Reciprocal rank fusion outperforms condorcet and individual rank learning methods,” inProceedings of the 32nd international ACM SIGIR conference on Research and development in information retrieval, 2009, pp. 758–759
2009
-
[15]
Code llama: Open foundation models for code,
B. Roziere et al., “Code llama: Open foundation models for code,”arXiv preprint arXiv:2308.12950, 2023
Pith/arXiv arXiv 2023
-
[16]
[Online]
Elastic NV,Elasticsearch, 2026. [Online]. Avail- able:https : / / www . elastic . co / elasticsearch/
2026
-
[17]
Spacy 2: Natural lan- guage understanding with bloom embeddings, convo- lutional neural networks and incremental parsing,
M. Honnibal and I. Montani, “Spacy 2: Natural lan- guage understanding with bloom embeddings, convo- lutional neural networks and incremental parsing,”To appear, 2017
2017
-
[18]
Leskovec and A
J. Leskovec and A. Krevl,SNAP Datasets: Stanford large network dataset collection,http : / / snap . stanford.edu/data, Jun. 2014
2014
-
[19]
A. Grattafiori et al., “The llama 3 herd of models,” arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[20]
Lora: Low-rank adaptation of large language models,
E. J. Hu et al., “Lora: Low-rank adaptation of large language models,”CoRR, vol. abs/2106.09685, 2021. arXiv:2106.09685. [Online]. Available:https: //arxiv.org/abs/2106.09685
Pith/arXiv arXiv 2021
-
[21]
Enevoldsen et al.,Mmteb: Massive multilingual text embedding benchmark, 2025
K. Enevoldsen et al.,Mmteb: Massive multilingual text embedding benchmark, 2025. arXiv:2502 . 13595 [cs.CL]. [Online]. Available:https://arxiv. org/abs/2502.13595
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.