When Should Queries Be Decomposed? A Stage-Aware Study of Query Decomposition for Multi-Condition Retrieval
Pith reviewed 2026-06-27 18:01 UTC · model grok-4.3
The pith
Decomposing queries during initial retrieval harms performance while improving it during reranking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
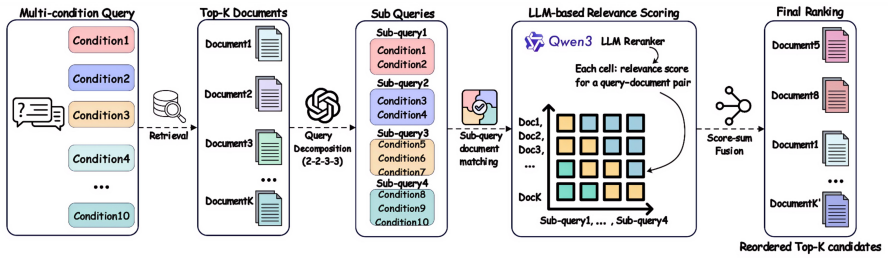
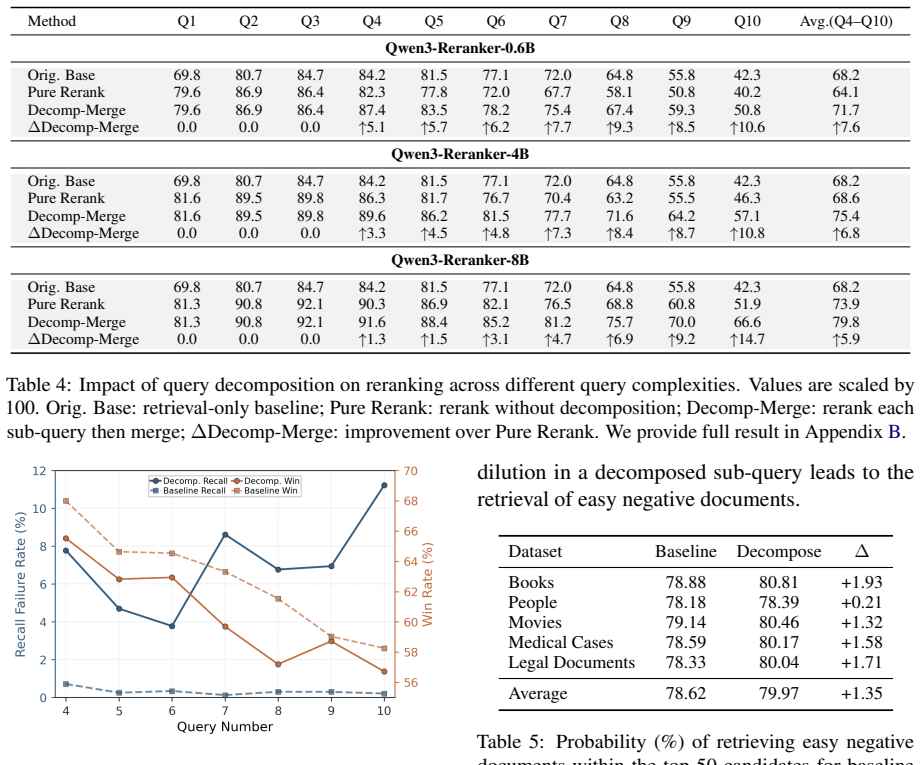
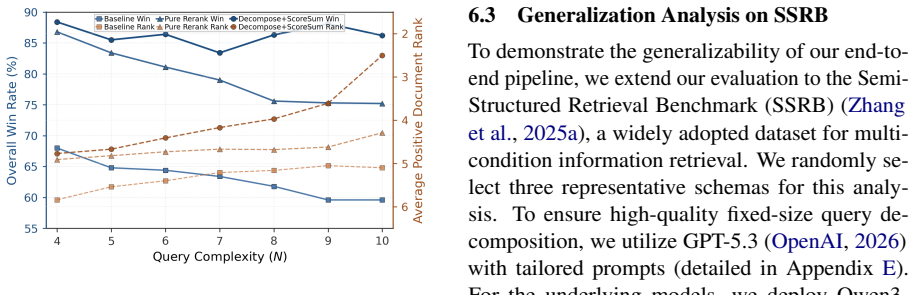
Decomposition during initial retrieval frequently harms retrieval performance due to semantic dilution, yet substantially improves reranking by enabling more fine-grained constraint verification. Motivated by this, the Stage-Aware Decomposition framework retains the monolithic query during initial retrieval to preserve global semantic context, while employing sub-queries exclusively during reranking for fine-grained constraint matching, leading to consistent improvements on the MultiConIR and SSRB benchmarks.
What carries the argument
Stage-Aware Decomposition framework that applies the full query at retrieval and decomposed queries at reranking.
If this is right
- Preserving the monolithic query in initial retrieval maintains global semantic context.
- Employing sub-queries in reranking enables fine-grained constraint verification.
- The framework improves ranking performance across multiple retrieval and reranking models.
- Evaluations show consistent gains on MultiConIR and SSRB benchmarks for compositional queries.
Where Pith is reading between the lines
- Similar stage-dependent behaviors may appear in other retrieval tasks involving complex queries.
- Retrieval systems could benefit from adaptive decomposition strategies based on pipeline stage.
- Testing on additional benchmarks would help confirm the generality of the stage-aware approach.
Load-bearing premise
The stage-dependent effects generalize beyond the specific models and benchmarks tested.
What would settle it
An experiment showing that decomposition improves initial retrieval performance on the same or similar benchmarks would contradict the main finding.
Figures
read the original abstract
Multi-condition retrieval requires systems to identify documents that satisfy multiple distinct constraints, moving beyond mere topical relevance. While query decomposition is widely adopted as an intuitive remedy, its effectiveness across different retrieval pipeline stages remains underexplored. In this paper, we conduct a stage-aware empirical study and uncover a stark, stage-dependent effect: decomposition during initial retrieval frequently harms retrieval performance due to semantic dilution, yet substantially improves reranking by enabling more fine-grained constraint verification. Motivated by these insights, we propose a principled Stage-Aware Decomposition framework that retains the monolithic query during initial retrieval to preserve global semantic context, while employing sub-queries exclusively during reranking for fine-grained constraint matching. Extensive evaluations on the MultiConIR and SSRB benchmarks demonstrate that our framework consistently improves ranking performance for compositional queries across multiple retrieval and reranking models. We release our code at https://github.com/EIT-NLP/Query-Decompose.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a stage-aware empirical study showing that query decomposition for multi-condition retrieval harms initial retrieval performance due to semantic dilution but improves reranking via finer constraint verification. It proposes a Stage-Aware Decomposition framework that retains the monolithic query for initial retrieval and applies sub-queries only at reranking, reporting consistent gains on MultiConIR and SSRB across multiple models, with code released.
Significance. If the stage-dependent pattern holds, the work offers actionable guidance for multi-condition retrieval pipelines and a practical framework that improves ranking for compositional queries. The explicit release of code supports reproducibility and external validation of the empirical findings.
major comments (1)
- [Experiments] Experiments section: results and the Stage-Aware Decomposition recommendation rest exclusively on MultiConIR and SSRB with the specific models tested; no additional benchmarks, model families, or out-of-distribution conditions are reported to test whether semantic dilution in retrieval and gains in reranking generalize when global semantics or constraint granularity differ.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for acknowledging the significance of the stage-dependent findings along with the code release. We address the major comment below.
read point-by-point responses
-
Referee: [Experiments] Experiments section: results and the Stage-Aware Decomposition recommendation rest exclusively on MultiConIR and SSRB with the specific models tested; no additional benchmarks, model families, or out-of-distribution conditions are reported to test whether semantic dilution in retrieval and gains in reranking generalize when global semantics or constraint granularity differ.
Authors: We agree that broader validation would strengthen claims about generalizability. MultiConIR and SSRB were chosen as the primary benchmarks specifically constructed for multi-condition retrieval, and the experiments already cover multiple retrieval and reranking model families with consistent stage-dependent patterns. In the revised manuscript we will expand the discussion to explicitly address potential variations under differing global semantics or constraint granularities and will add results from at least one additional benchmark if a suitable public dataset can be identified. revision: partial
Circularity Check
No circularity; purely empirical study with independent evaluations
full rationale
The paper conducts an empirical stage-aware study on query decomposition for multi-condition retrieval, reporting performance differences on MultiConIR and SSRB benchmarks across retrieval and reranking models. No mathematical derivations, equations, fitted parameters renamed as predictions, or self-citation load-bearing premises are present. The Stage-Aware Decomposition framework is motivated directly by the reported experimental observations rather than by construction from inputs or prior self-citations. This is self-contained empirical work with no reduction of claims to definitions or fits.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The MultiConIR and SSRB benchmarks are suitable proxies for real multi-condition retrieval scenarios
Reference graph
Works this paper leans on
-
[1]
What Makes Good Instruction-Tuning Data? An In-Context Learning Perspective
Precise zero-shot dense retrieval without rel- evance labels. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1762–1777. Associa- tion for Computational Linguistics. Guangzeng Han and Xiaolei Huang. 2026. What makes good instruction-tunin...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5521–5533, Singapore
Decomposing complex queries for tip-of-the- tongue retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 5521–5533, Singapore. Association for Computa- tional Linguistics. Sheng-Chieh Lin, Jheng-Hong Yang, Rodrigo Nogueira, Ming-Feng Tsai, Chuan-Ju Wang, and Jimmy Lin
2023
-
[3]
Multi-stage conversational passage retrieval: An approach to fusing term importance estimation and neural query rewriting.ACM Trans. Inf. Syst., 39(4):48:1–48:29. Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paran- jape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2024. Lost in the middle: How language mod- els use long contexts.Transactions of t...
2024
-
[4]
InForty-second In- ternational Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, vol- ume 267 ofProceedings of Machine Learning Re- search
POQD: performance-oriented query decom- poser for multi-vector retrieval. InForty-second In- ternational Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025, vol- ume 267 ofProceedings of Machine Learning Re- search. PMLR / OpenReview.net. Xuan Lu, Haohang Huang, Rui Meng, Yaohui Jin, Wen- jun Zeng, and Xiaoyu Shen. 2026a. R...
2025
-
[5]
MS MARCO: A human generated machine reading comprehension dataset. InProceedings of the Workshop on Cognitive Computation: Integrat- ing neural and symbolic approaches 2016 co-located with the 30th Annual Conference on Neural Infor- mation Processing Systems (NIPS 2016), Barcelona, Spain, December 9, 2016, volume 1773 ofCEUR Workshop Proceedings. CEUR-WS....
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[6]
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval Models
OpenReview.net. Weiwei Sun, Lingyong Yan, Xinyu Ma, Shuaiqiang Wang, Pengjie Ren, Zhumin Chen, Dawei Yin, and Zhaochun Ren. 2023. Is chatgpt good at search? investigating large language models as re-ranking agents. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, EMNLP 2023, Singapore, December 6-10, 2023, pages ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
Adaptive Granularity:Decide the optimal number of sub-queries based on the semantic structure of the original query
-
[8]
Different sub-queries may contain different numbers of conditions, depending on how the conditions naturally cluster
Semantic Coherence:Group semantically related conditions together within the same sub-query. Different sub-queries may contain different numbers of conditions, depending on how the conditions naturally cluster
-
[9]
Do not duplicate specific constraints or information across the decomposed segments
No Information Overlap:The conditions must be mutually exclusive across sub-queries. Do not duplicate specific constraints or information across the decomposed segments
-
[10]
[Sub-query text]
Preserve Original Wording:Extract and segment the text while strictly preserving the original phrasing, vocabulary, and sentence structure as much as possible. Avoid aggressively paraphrasing, rewriting, or hallucinating new information. Output Format:Strictly output the decomposed sub-queries in the following format, with one sub-query per line and no ad...
-
[11]
Assistant Message (Few-shot Example Output) 4_Query_8_subq_1,
Charlie holding onions, investigates odd smell. 3. Origin: American. 4. Charlie drunkenly sees dummy as opponent. 5. Mabel reveals dummy to fighting Charlie. 6. Director: Charlie Chaplin. 7. Cast includes Charlie Chaplin, Mabel Normand. 8. Man with tennis racquet approaches wife in bar." Assistant Message (Few-shot Example Output) 4_Query_8_subq_1, "Find ...
2024
-
[12]
If the original query only contains 2-3 conditions, output the original query as a single sub-query without splitting
Decomposition Limit:Split the original query into sub-queries. If the original query only contains 2-3 conditions, output the original query as a single sub-query without splitting. 2.Condition Threshold:Each generated sub-query MUST contain 2-3 distinct search conditions or constraints
-
[13]
Do not duplicate specific constraints or information across the decomposed segments
No Information Overlap:The semantic conditions must be mutually exclusive across sub-queries. Do not duplicate specific constraints or information across the decomposed segments
-
[14]
[Sub-query text]
Preserve Original Wording:Extract and segment the text while strictly preserving the original phrasing, vocabulary, and sentence structure as much as possible. Avoid aggressively paraphrasing, rewriting, or hallucinating new information. Ensure each segment remains a coherent sentence. # Output Format You must strictly output the decomposed sub-queries in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.