NGM: A Plug-and-Play Training-Free Memory Module for LLMs
Pith reviewed 2026-05-19 20:44 UTC · model grok-4.3
pith:FQXNA77O Add to your LaTeX paper
What is a Pith Number?\usepackage{pith}
\pithnumber{FQXNA77O}
Prints a linked pith:FQXNA77O badge after your title and writes the identifier into PDF metadata. Compiles on arXiv with no extra files. Learn more
The pith
Averaging pretrained token embeddings creates n-gram representations that a cosine-gated injector adds to LLMs without training or extra parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
NGM consists of a Causal N-Gram Encoder that constructs n-gram representations by averaging the backbone model's pretrained token embeddings and a Cosine-Gated Memory Injector that modulates these representations into contextual hidden states using a non-parametric cosine gate combined with ReLU. When integrated into Qwen3 models from 0.6B to 14B parameters, this module raises average benchmark scores by 0.5 to 1.2 points and delivers larger lifts on code generation and knowledge-intensive tasks such as +3.0 on LiveCodeBench and +3.03 on GPQA for the 14B model, while also improving multimodal performance.
What carries the argument
The Causal N-Gram Encoder, which builds n-gram vectors by direct averaging of pretrained token embeddings, and the Cosine-Gated Memory Injector, which applies a non-parametric cosine similarity gate with ReLU to blend the n-gram embeddings into the model's representations.
If this is right
- Performance gains appear on code generation benchmarks and knowledge-intensive question answering.
- The method works across model scales from 0.6B to 14B and extends to vision-language models.
- No additional parameters or training are needed, making it immediately applicable to existing pretrained models.
- The design avoids both learned memory tables and separate retrieval pipelines.
- It provides a more direct knowledge access route than mixture-of-experts routing.
Where Pith is reading between the lines
- Since the n-gram representations come from the model's own embeddings, the approach may generalize to other sequence lengths or higher-order n-grams with minimal adjustment.
- Future work could test whether the same averaging principle applies to other forms of structured memory such as phrases or facts extracted from text.
- The cosine gate's simplicity might allow similar non-parametric modulation in other injection scenarios beyond n-grams.
- Combining this with larger context windows could amplify the benefits on long-document tasks.
Load-bearing premise
That directly averaging pretrained token embeddings produces useful n-gram representations that the cosine-gated injector can meaningfully modulate without introducing noise or requiring any learned parameters or additional training.
What would settle it
Running the same benchmarks on the same models with the averaging step replaced by random vectors or with the cosine gate removed entirely, and checking whether the performance gains disappear.
Figures



read the original abstract
Recent studies introduce conditional memory modules that decouple knowledge storage from neural computation, enabling more direct knowledge access. Compared to MoE, which relies on dynamic computation paths, explicit lookup provides a more efficient knowledge retrieval mechanism. However, these approaches still depend on learned memory embeddings, requiring additional training and limiting flexibility. To address this, we propose N-gram Memory (NGM), a training-free, plug-and-play module composed of a Causal N-Gram Encoder and a Cosine-Gated Memory Injector. The Causal N-Gram Encoder directly averages the pretrained token embeddings of the backbone model to construct N-gram representations, thereby eliminating the need to train separate N-gram embeddings from scratch. This design requires neither an additional memory table nor a retrieval pipeline. The Cosine-Gated Memory Injector then uses a non-parametric cosine gate with ReLU to modulate the retrieved embeddings into the contextual representations. We evaluate NGM on the Qwen3 series from 0.6B to 14B across eight benchmarks. NGM improves average performance by 0.5 to 1.2 points, with particularly clear gains on code generation and knowledge-intensive tasks (e.g., +3.0 on LiveCodeBench and +3.03 on GPQA for Qwen3-14B). Moreover, NGM also improves performance in multimodal benchmarks (e.g., MMStar +1.53 on Qwen3-VL-2B).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
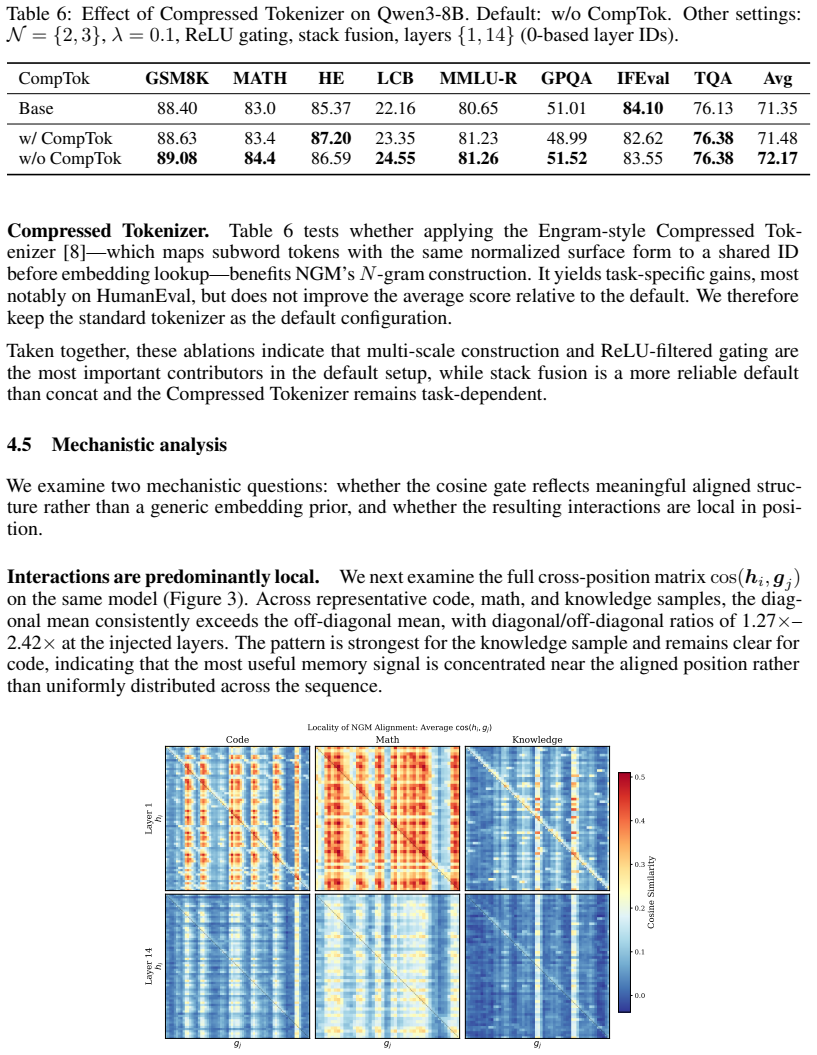
Summary. The paper proposes NGM, a training-free plug-and-play memory module for LLMs consisting of a Causal N-Gram Encoder that constructs n-gram representations by averaging pretrained token embeddings from the backbone model and a Cosine-Gated Memory Injector that applies a non-parametric cosine similarity gate with ReLU to modulate injection into hidden states. It reports evaluation on Qwen3 models (0.6B to 14B) across eight benchmarks, claiming average gains of 0.5–1.2 points with larger improvements on code generation (+3.0 on LiveCodeBench) and knowledge tasks (+3.03 on GPQA for Qwen3-14B), plus multimodal gains (e.g., +1.53 on MMStar for Qwen3-VL-2B).
Significance. If the gains prove robust, the work would demonstrate a simple, zero-parameter approach to explicit n-gram memory that avoids training separate embeddings or retrieval pipelines, offering efficiency advantages over MoE-style methods. Strengths include the fully non-parametric design, evaluation across model scales, and inclusion of multimodal results. The empirical focus with external benchmarks and absence of fitted parameters or self-referential definitions are positive.
major comments (2)
- [§3.1] §3.1 (Causal N-Gram Encoder): the central assumption that directly averaging pretrained token embeddings yields semantically coherent n-gram vectors compatible with the fixed cosine-ReLU injector is load-bearing for attributing any gains to the module, yet no ablation or analysis addresses whether this averaging discards critical positional/higher-order interactions or introduces dilution/collision noise that the non-parametric gate cannot filter.
- [Results] Results (benchmark tables): reported deltas of 0.5–1.2 average points (and task-specific +3.0/+3.03) are presented without error bars, statistical significance tests, or controls for selective task emphasis; for gains this small, absence of these details prevents determining whether improvements exceed variance or multiple-comparison effects.
minor comments (2)
- [Abstract] The abstract states evaluation on eight benchmarks but does not enumerate them; listing the full set (including any held-out controls) would aid reproducibility.
- [§3.2] Notation for the cosine gate threshold and ReLU modulation in the injector would benefit from an explicit equation to clarify the non-parametric computation.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and describe the revisions we will incorporate to improve the manuscript.
read point-by-point responses
-
Referee: [§3.1] §3.1 (Causal N-Gram Encoder): the central assumption that directly averaging pretrained token embeddings yields semantically coherent n-gram vectors compatible with the fixed cosine-ReLU injector is load-bearing for attributing any gains to the module, yet no ablation or analysis addresses whether this averaging discards critical positional/higher-order interactions or introduces dilution/collision noise that the non-parametric gate cannot filter.
Authors: We agree that the averaging step in the Causal N-Gram Encoder is a foundational assumption. Pretrained embeddings from the backbone model already encode substantial semantic and syntactic information, and averaging provides a simple, training-free way to form n-gram representations that align with the non-parametric cosine gate. However, we acknowledge that this may overlook higher-order interactions or introduce noise. In the revised manuscript we will add a targeted ablation (new subsection in §3 and corresponding appendix table) that compares plain averaging against (i) position-augmented averaging and (ii) a lightweight learned linear projection over the same n-gram tokens. This will quantify any dilution effects and directly support the design choice. revision: yes
-
Referee: [Results] Results (benchmark tables): reported deltas of 0.5–1.2 average points (and task-specific +3.0/+3.03) are presented without error bars, statistical significance tests, or controls for selective task emphasis; for gains this small, absence of these details prevents determining whether improvements exceed variance or multiple-comparison effects.
Authors: The referee is correct that modest average gains require statistical support to be convincing. We will revise the results section and tables to include (i) standard deviations or error bars from repeated evaluations where computationally feasible, (ii) paired significance tests (e.g., Wilcoxon signed-rank) between baseline and NGM runs, and (iii) an explicit statement that the reported average is the uniform mean across all eight benchmarks with no post-hoc selection. These additions will appear in the updated experimental tables and a new paragraph in §4. revision: yes
Circularity Check
No circularity: NGM is an empirical training-free proposal with gains measured on external benchmarks
full rationale
The paper defines NGM via direct averaging of pretrained token embeddings in the Causal N-Gram Encoder and a fixed non-parametric cosine-ReLU gate in the injector. These are architectural choices, not derived quantities. Performance deltas (0.5-1.2 average, +3.0 on LiveCodeBench) are reported from direct evaluation on held-out benchmarks (Qwen3 series, GPQA, MMStar). No equations, fitted parameters, or self-citations reduce the claimed improvements to the inputs by construction. The design is self-contained against external test sets.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained token embeddings from the backbone LLM contain useful compositional information for n-grams when simply averaged.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The Causal N-Gram Encoder directly averages the pretrained token embeddings of the backbone model to construct N-gram representations... The Cosine-Gated Memory Injector then uses a non-parametric cosine gate with ReLU to modulate the retrieved embeddings
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
st,n = cos(hl_t, gt,n) = ⟨hl_t, gt,n⟩ / (∥hl_t∥ ∥gt,n∥); optionally ReLU to suppress negatively aligned updates
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Y uxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report. arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Enriching word vec- tors with subword information
Piotr Bojanowski, Edouard Grave, Armand Joulin, and Tomas Mikolov. Enriching word vec- tors with subword information. Transactions of the association for computational linguistics , 5:135–146, 2017
work page 2017
-
[3]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George Bm V an Den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, et al. Improving language models by retrieving from trillions of tokens. In International conference on machine learning, pages 2206–2240. PMLR, 2022
work page 2022
-
[4]
Large language models in machine translation
Thorsten Brants, Ashok Popat, Peng Xu, Franz Josef Och, and Jeffrey Dean. Large language models in machine translation. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), pages 858–867, 2007
work page 2007
-
[5]
Lin Chen, Jinsong Li, Xiaoyi Dong, Pan Zhang, Y uhang Zang, Zehui Chen, Haodong Duan, Jiaqi Wang, Y u Qiao, Dahua Lin, et al. Are we on the right way for evaluating large vision- language models? Advances in Neural Information Processing Systems , 37:27056–27087, 2024
work page 2024
-
[6]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Y uan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Y uri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
An empirical study of smoothing techniques for lan- guage modeling
Stanley F Chen and Joshua Goodman. An empirical study of smoothing techniques for lan- guage modeling. Computer Speech & Language , 13(4):359–394, 1999
work page 1999
-
[8]
Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
Xin Cheng, Wangding Zeng, Damai Dai, Qinyu Chen, Bingxuan Wang, Zhenda Xie, Kezhao Huang, Xingkai Y u, Zhewen Hao, Y ukun Li, et al. Conditional memory via scalable lookup: A new axis of sparsity for large language models. arXiv preprint arXiv:2601.07372, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[9]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[10]
Survey: multiword expression processing: a survey
Matthieu Constant, Gül¸ sen Eryi˘git, Johanna Monti, Lonneke V an Der Plas, Carlos Ramisch, Michael Rosner, and Amalia Todirascu. Survey: multiword expression processing: a survey. Computational Linguistics, 43(4):837–892, 2017
work page 2017
-
[11]
Jump to conclusions: Short-cutting transformers with linear transformations
Alexander Y om Din, Taelin Karidi, Leshem Choshen, and Mor Geva. Jump to conclusions: Short-cutting transformers with linear transformations. In Proceedings of the 2024 Joint In- ternational Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING 2024), pages 9615–9625, 2024
work page 2024
- [12]
-
[13]
Vlmevalkit: An open-source toolkit for evaluating large multi-modality models
Haodong Duan, Junming Y ang, Y uxuan Qiao, Xinyu Fang, Lin Chen, Y uan Liu, Xiaoyi Dong, Y uhang Zang, Pan Zhang, Jiaqi Wang, et al. Vlmevalkit: An open-source toolkit for evaluating large multi-modality models. In Proceedings of the 32nd ACM International Conference on Multimedia, pages 11198–11201, 2024
work page 2024
-
[14]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Y untao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 1(1):12, 2021
work page 2021
-
[15]
The idiom principle and the open choice principle
Britt Erman. The idiom principle and the open choice principle. Text-Interdisciplinary Journal for the Study of Discourse , 2000. 10
work page 2000
-
[16]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. Journal of Machine Learning Research , 23(120):1–39, 2022
work page 2022
-
[17]
Aryo Pradipta Gema, Joshua Ong Jun Leang, Giwon Hong, Alessio Devoto, Alberto Carlo Maria Mancino, Rohit Saxena, Xuanli He, Y u Zhao, Xiaotang Du, Mohammad Reza Ghasemi Madani, et al. Are we done with mmlu? In Proceedings of the 2025 Confer- ence of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Techno...
work page 2025
-
[18]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex V aughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Retrieval aug- mented language model pre-training
Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval aug- mented language model pre-training. In International conference on machine learning , pages 3929–3938. PMLR, 2020
work page 2020
-
[20]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[21]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[22]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Y an, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contami- nation free evaluation of large language models for code. arXiv preprint arXiv:2403.07974 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Albert Qiaochu Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Deven- dra Singh Chaplot, Diego de Las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lam- ple, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b. ArXiv, abs/23...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
Gen- eralization through memorization: Nearest neighbor language models
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. Gen- eralization through memorization: Nearest neighbor language models. arXiv preprint arXiv:1911.00172, 2019
-
[25]
Improved backing-off for m-gram language modeling
Reinhard Kneser and Hermann Ney. Improved backing-off for m-gram language modeling. In 1995 international conference on acoustics, speech, and signal processing , volume 1, pages 181–184. IEEE, 1995
work page 1995
-
[26]
Truthfulqa: Measuring how models mimic human falsehoods
Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th annual meeting of the association for computa- tional linguistics (volume 1: long papers) , pages 3214–3252, 2022
work page 2022
-
[27]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report. arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Hong Liu, Jiaqi Zhang, Chao Wang, Xing Hu, Linkun Lyu, Jiaqi Sun, Xurui Y ang, Bo Wang, Fengcun Li, Y ulei Qian, Lingtong Si, Y erui Sun, Rumei Li, Peng Pei, Y uchen Xie, and Xunliang Cai. Scaling embeddings outperforms scaling experts in language mod- els. ArXiv, abs/2601.21204, 2026. URL https://api.semanticscholar.org/CorpusID: 285140484
-
[29]
Infini- gram: Scaling unbounded n-gram language models to a trillion tokens
Jiacheng Liu, Sewon Min, Luke Zettlemoyer, Y ejin Choi, and Hannaneh Hajishirzi. Infini- gram: Scaling unbounded n-gram language models to a trillion tokens. arXiv preprint arXiv:2401.17377, 2024. 11
-
[30]
Y uan Liu, Haodong Duan, Y uanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Y uan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? In European conference on computer vision , pages 216–233. Springer, 2024
work page 2024
-
[31]
Ocrbench: on the hidden mystery of ocr in large multimodal models
Y uliang Liu, Zhang Li, Mingxin Huang, Biao Y ang, Wenwen Y u, Chunyuan Li, Xu-Cheng Yin, Cheng-Lin Liu, Lianwen Jin, and Xiang Bai. Ocrbench: on the hidden mystery of ocr in large multimodal models. Science China Information Sciences , 67(12):220102, 2024
work page 2024
-
[32]
Generalizing and hybridizing count-based and neural lan- guage models
Graham Neubig and Chris Dyer. Generalizing and hybridizing count-based and neural lan- guage models. In Proceedings of the 2016 Conference on Empirical Methods in Natural Lan- guage Processing, pages 1163–1172, 2016
work page 2016
-
[33]
Understanding transformers via n-gram statistics
Timothy Nguyen. Understanding transformers via n-gram statistics. Advances in neural infor- mation processing systems, 37:98049–98082, 2024
work page 2024
-
[34]
interpreting GPT: the logit lens
nostalgebraist. interpreting GPT: the logit lens. https://www.lesswrong.com/posts/ AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens , 2020
work page 2020
-
[35]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Y uanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. In First conference on language modeling, 2024
work page 2024
-
[36]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[37]
EvalScope: Evaluation framework for large models, 2024
ModelScope Team. EvalScope: Evaluation framework for large models, 2024. URL https: //github.com/modelscope/evalscope
work page 2024
-
[38]
Albert Tseng and Christopher De Sa. L 3: Large lookup layers. arXiv preprint arXiv:2601.21461, 2026
-
[39]
Ashish V aswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
work page 2017
-
[40]
Y uhuai Wu, Markus N Rabe, DeLesley Hutchins, and Christian Szegedy. Memorizing trans- formers. arXiv preprint arXiv:2203.08913, 2022
-
[41]
An Y ang, Anfeng Li, Baosong Y ang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Y u, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Scaling embedding layers in language models
Da Y u, Edith Cohen, Badih Ghazi, Y angsibo Huang, Pritish Kamath, Ravi Kumar, Daogao Liu, and Chiyuan Zhang. Scaling embedding layers in language models. ArXiv, abs/2502.01637,
-
[43]
URL https://api.semanticscholar.org/CorpusID:276106917
-
[44]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models. arXiv preprint arXiv:2311.07911, 2023. 12 A NGM implementation Listing 1 gives a simplified PyTorch implementation of NGM. def ngm_forward(hidden_states, input_ids, embed_matrix, ngram_sizes,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.