A Survey of Large Language Models for Perception and Measurement of Human Psychology
Pith reviewed 2026-06-30 16:56 UTC · model grok-4.3
The pith
Large language models can be used as instruments to measure human psychological constructs when organized by theoretical plausibility, measurement methods, and application results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
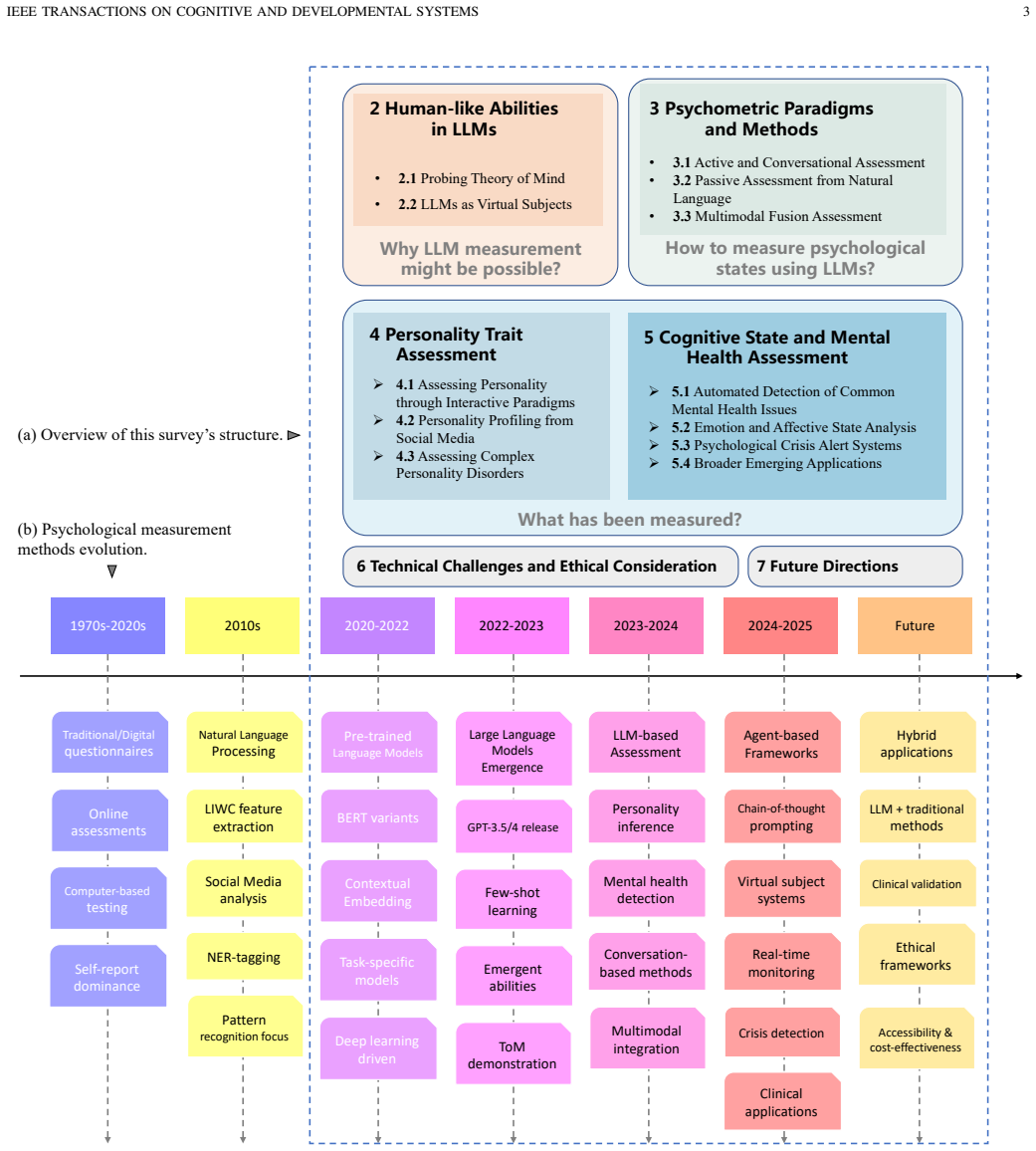
The paper establishes that research on LLMs for human psychological measurement can be systematically organized into three dimensions: Theoretical Plausibility, which addresses why such measurement might be feasible; Measurement Methodology, which covers active conversational assessment, passive natural language analysis, and multimodal fusion; and Application Effectiveness, which examines results in personality trait assessment and mental health evaluation.
What carries the argument
The three-dimensional analytical framework of Theoretical Plausibility, Measurement Methodology, and Application Effectiveness.
If this is right
- Active conversational methods allow LLMs to interact directly with subjects for trait assessment.
- Passive analysis of natural language can extract psychological signals from text without direct interaction.
- Multimodal approaches combine text with other data types to improve measurement of complex states.
- Current applications show both promise and limits in personality and mental health domains.
Where Pith is reading between the lines
- The framework could guide systematic comparisons between different LLM architectures on the same psychological tasks.
- Limitations noted in application effectiveness suggest the need for standardized validation benchmarks across studies.
- The distinction from reviews of LLMs' own psychological properties clarifies the focus on LLMs as external measurement tools.
Load-bearing premise
Existing literature on LLM-based psychological measurement can be meaningfully categorized into the three proposed dimensions without significant overlap or omission.
What would settle it
A substantial body of new studies on LLM psychological measurement that cannot be assigned to any of the three dimensions or that requires a fourth distinct category would undermine the framework.
Figures

read the original abstract
Against the backdrop of the rapid advancement of Large Language Models (LLMs), their application in the field of psychology has garnered significant academic attention. A central issue is whether LLMs possess the capability to accurately perceive and measure complex, latent human psychological constructs, such as personality, emotions, and cognitive states. This paper provides a systematic review focused on the use of LLMs as instruments for human psychological measurement. To organize this domain, we propose a comprehensive analytical framework structured around three critical dimensions: Theoretical Plausibility (why measurement might be possible), Measurement Methodology (how to measure), and Application Effectiveness (what has been measured). We first explore the theoretical foundations supporting LLM-based measurement, examining the debate on their emergent cognitive properties from a psychometric perspective. Next, we systematically analyze existing measurement paradigms, categorizing them into active conversational assessment, passive natural language analysis, and multimodal fusion. Subsequently, we review the practical effectiveness and limitations of LLMs in core application areas, including personality trait assessment and mental health evaluation. Distinct from prior reviews focusing on general applications or the ``psychology'' of LLMs themselves, this paper centers on the psychometric properties of LLMs as measurement tools.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents a systematic review of LLMs used as instruments to perceive and measure latent human psychological constructs (personality, emotions, cognitive states). It proposes a three-dimensional framework—Theoretical Plausibility (emergent cognitive properties from a psychometric view), Measurement Methodology (active conversational assessment, passive natural language analysis, multimodal fusion), and Application Effectiveness (personality trait assessment, mental health evaluation)—and positions the work as distinct from prior reviews on general LLM applications or the “psychology of LLMs.”
Significance. If the taxonomy proves non-redundant and the literature coverage exhaustive, the survey could usefully organize an emerging interdisciplinary area by centering psychometric validity rather than capability demonstration. The explicit scope distinction from existing reviews is a clear strength.
major comments (2)
- [Abstract] Abstract: the claim that the literature can be “systematically” organized into three non-redundant dimensions is load-bearing, yet the abstract supplies no boundary definitions, overlap-handling rules, or decision criteria separating Theoretical Plausibility from Measurement Methodology despite their direct interdependence.
- [Abstract] Abstract / implied methods section: no literature-search protocol, database list, keyword string, inclusion/exclusion criteria, or paper-count statistics are reported, preventing evaluation of whether the reviewed corpus is exhaustive or whether the taxonomy reflects selection bias.
Simulated Author's Rebuttal
We thank the referee for these targeted comments on the abstract and the transparency of our review process. Both points identify areas where additional clarity will strengthen the manuscript, and we will revise accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the literature can be “systematically” organized into three non-redundant dimensions is load-bearing, yet the abstract supplies no boundary definitions, overlap-handling rules, or decision criteria separating Theoretical Plausibility from Measurement Methodology despite their direct interdependence.
Authors: We accept that the abstract must stand alone on this point. In revision we will insert concise boundary statements: Theoretical Plausibility addresses the psychometric justification for emergent LLM capabilities (e.g., alignment with trait theory or cognitive models); Measurement Methodology addresses the operational procedures (conversational prompting, text analysis, multimodal input); Application Effectiveness addresses empirical outcomes in specific domains. Papers whose primary contribution is theoretical justification are placed in the first pillar even if they also describe a method; papers whose primary contribution is a new measurement technique are placed in the second. We will add one sentence to the abstract summarizing this assignment rule and will expand the taxonomy-construction paragraph in Section 2 to make the decision criteria explicit. revision: yes
-
Referee: [Abstract] Abstract / implied methods section: no literature-search protocol, database list, keyword string, inclusion/exclusion criteria, or paper-count statistics are reported, preventing evaluation of whether the reviewed corpus is exhaustive or whether the taxonomy reflects selection bias.
Authors: We agree that a systematic-review claim requires an explicit methods description. We will add a new subsection (provisionally 2.1) that reports: (i) databases queried (Google Scholar, arXiv, PubMed, PsycINFO, ACL Anthology), (ii) the Boolean search string combining LLM synonyms with psychological-construct terms, (iii) inclusion criteria (empirical studies that apply LLMs to measure latent constructs; peer-reviewed or preprints with clear evaluation), (iv) exclusion criteria (pure capability demonstrations without psychometric framing, non-English papers, reviews), and (v) the final corpus size and screening flow. This addition will allow readers to assess coverage and selection bias directly. revision: yes
Circularity Check
No circularity: survey taxonomy is organizational, not derived from self-inputs
full rationale
This is a literature survey paper with no mathematical derivations, parameter fits, or predictions. The three-dimension framework (Theoretical Plausibility, Measurement Methodology, Application Effectiveness) is explicitly presented as a proposed organizational structure for reviewing external work, not as a result derived from the paper's own data or prior self-citations. No equations, fitted inputs, or load-bearing self-citations appear in the abstract or described structure. The central claim reduces to curation of existing literature rather than any self-referential reduction. This matches the default expectation for non-circular survey papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs have emergent properties that may relate to cognitive abilities
Reference graph
Works this paper leans on
-
[1]
J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkatet al., “Gpt-4 technical report,”arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Gemini 2.0: Flash, flash-lite and pro,
S. B. Mallick and L. Kilpatrick, “Gemini 2.0: Flash, flash-lite and pro,” February 2025, accessed: 2025-05-01. [Online]. Available: https://developers.googleblog.com/zh-hans/gemini-2-family-expands/
2025
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
D. Guo, D. Yang, H. Zhang, J. Song, R. Zhang, R. Xu, Q. Zhu, S. Ma, P. Wang, X. Biet al., “Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning,”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Soulchat: Improving llms’ empathy, listening, and comfort abilities through fine-tuning with multi-turn empathy conversations,
Y . Chen, X. Xing, J. Lin, H. Zheng, Z. Wang, Q. Liu, and X. Xu, “Soulchat: Improving llms’ empathy, listening, and comfort abilities through fine-tuning with multi-turn empathy conversations,” inFind- ings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 1170–1183
2023
-
[5]
Smile: Single-turn to multi-turn inclusive language expansion via chatgpt for mental health support,
H. Qiu, H. He, S. Zhang, A. Li, and Z. Lan, “Smile: Single-turn to multi-turn inclusive language expansion via chatgpt for mental health support,”arXiv preprint arXiv:2305.00450, 2023
-
[6]
Psycollm: Enhancing llm for psychological understanding and evaluation,
J. Hu, T. Dong, L. Gang, H. Ma, P. Zou, X. Sun, D. Guo, X. Yang, and M. Wang, “Psycollm: Enhancing llm for psychological understanding and evaluation,”IEEE Transactions on Computational Social Systems, 2024
2024
-
[7]
On the dangers of stochastic parrots: Can language models be too big?
E. M. Bender, T. Gebru, A. McMillan-Major, and S. Shmitchell, “On the dangers of stochastic parrots: Can language models be too big?” in Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, 2021, pp. 610–623
2021
-
[9]
Tombench: Benchmarking theory of mind in large language models,
Z. Chen, J. Wu, J. Zhou, B. Wen, G. Bi, G. Jiang, Y . Cao, M. Hu, Y . Lai, Z. Xionget al., “Tombench: Benchmarking theory of mind in large language models,”CoRR, 2024
2024
-
[10]
arXiv preprint arXiv:2302.08399 , year=
T. Ullman, “Large language models fail on trivial alterations to theory- of-mind tasks,”arXiv preprint arXiv:2302.08399, 2023
-
[11]
Psychometric evaluation of large language model embeddings for personality trait prediction,
J. Maharjan, R. Jin, J. Zhu, and D. Kenne, “Psychometric evaluation of large language model embeddings for personality trait prediction,” Journal of Medical Internet Research, vol. 27, p. e75347, 2025
2025
-
[12]
Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities,
A. Wilf, S. Lee, P. P. Liang, and L.-P. Morency, “Think twice: Perspective-taking improves large language models’ theory-of-mind capabilities,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 8292–8308
2024
-
[13]
Emobench: Evaluating the emotional intelligence of large language models,
S. Sabour, S. Liu, Z. Zhang, J. Liu, J. Zhou, A. Sunaryo, T. Lee, R. Mihalcea, and M. Huang, “Emobench: Evaluating the emotional intelligence of large language models,” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2024, pp. 5986–6004
2024
-
[14]
Mindgames: Targeting theory of mind in large language models with dynamic epistemic modal logic,
D. Sileo and A. Lernould, “Mindgames: Targeting theory of mind in large language models with dynamic epistemic modal logic,” in Findings of the Association for Computational Linguistics: EMNLP 2023, 2023, pp. 4570–4577
2023
-
[15]
Large language models display human-like social desirability biases in big five personality surveys,
A. Salecha, M. E. Ireland, S. Subrahmanya, J. Sedoc, L. H. Ungar, and J. C. Eichstaedt, “Large language models display human-like social desirability biases in big five personality surveys,”PNAS nexus, vol. 3, no. 12, p. pgae533, 2024
2024
-
[16]
Challenging the validity of personality tests for large language models,
T. S ¨uhr, F. E. Dorner, S. Samadi, and A. Kelava, “Challenging the validity of personality tests for large language models,”arXiv preprint arXiv:2311.05297, 2023
-
[17]
Personality testing of large language models: limited temporal stability, but highlighted prosocial- ity,
B. Bodro ˇza, B. M. Dini ´c, and L. Boji ´c, “Personality testing of large language models: limited temporal stability, but highlighted prosocial- ity,”Royal Society Open Science, vol. 11, no. 10, p. 240180, 2024
2024
-
[18]
W. Dong, Y . Zhao, Z. Sun, Y . Liu, Z. Peng, J. Zheng, Z. Zhang, Z. Zhang, J. Wu, R. Wanget al., “Humanizing llms: A survey of psychological measurements with tools, datasets, and human-agent applications,”arXiv preprint arXiv:2505.00049, 2025
-
[19]
Large language model psychometrics: A systematic review of evaluation, validation, and enhancement,
H. Ye, J. Jin, Y . Xie, X. Zhang, and G. Song, “Large language model psychometrics: A systematic review of evaluation, validation, and enhancement,”arXiv preprint arXiv:2505.08245, 2025
-
[20]
Exploring the frontiers of llms in psychological applications: A comprehensive review,
L. Ke, S. Tong, P. Cheng, and K. Peng, “Exploring the frontiers of llms in psychological applications: A comprehensive review,”Artificial Intelligence Review, vol. 58, no. 10, p. 305, 2025
2025
-
[21]
Large language models for mental health applications: systematic review,
Z. Guo, A. Lai, J. H. Thygesen, J. Farrington, T. Keen, K. Liet al., “Large language models for mental health applications: systematic review,”JMIR mental health, vol. 11, no. 1, p. e57400, 2024
2024
-
[22]
Do large language models understand us?
B. A. y Arcas, “Do large language models understand us?”Daedalus, vol. 151, no. 2, pp. 183–197, 2022
2022
-
[23]
Language models represent space and time,
W. Gurnee and M. Tegmark, “Language models represent space and time,”arXiv preprint arXiv:2310.02207, 2023
-
[24]
The debate over understanding in ai’s large language models,
M. Mitchell and D. C. Krakauer, “The debate over understanding in ai’s large language models,”Proceedings of the National Academy of Sciences, vol. 120, no. 13, p. e2215907120, 2023
2023
-
[25]
Climbing towards nlu: On meaning, form, and understanding in the age of data,
E. M. Bender and A. Koller, “Climbing towards nlu: On meaning, form, and understanding in the age of data,” inProceedings of the 58th annual meeting of the association for computational linguistics, 2020, pp. 5185–5198
2020
-
[26]
Do large language models understand logic or just mimick context?
J. Yan, C. Wang, J. Huang, and W. Zhang, “Do large language models understand logic or just mimick context?”arXiv preprint arXiv:2402.12091, 2024
-
[27]
Theory of mind in large language models: Examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests,
M. van Duijn, B. Van Dijk, T. Kouwenhoven, W. de Valk, M. Spruit, and P. van der Putten, “Theory of mind in large language models: Examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests,” inProceedings of the 27th Conference on Computational Natural Language Learning (CoNLL), 2023, pp. 389– 402
2023
-
[28]
Baron-Cohen,Mindblindness: An essay on autism and theory of mind
S. Baron-Cohen,Mindblindness: An essay on autism and theory of mind. MIT press, 1997
1997
-
[29]
Theory of mind: An overview and behavioral perspective,
H. D. Schlinger Jr, “Theory of mind: An overview and behavioral perspective,”The Psychological Record, vol. 59, no. 3, pp. 435–448, 2009
2009
-
[30]
Boosting theory-of-mind per- formance in large language models via prompting,
S. R. Moghaddam and C. J. Honey, “Boosting theory-of-mind per- formance in large language models via prompting,”arXiv preprint arXiv:2304.11490, 2023
-
[31]
Neural theory-of-mind? on the limits of social intelligence in large lms,
M. Sap, R. Le Bras, D. Fried, and Y . Choi, “Neural theory-of-mind? on the limits of social intelligence in large lms,” inProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022, pp. 3762–3780. IEEE TRANSACTIONS ON COGNITIVE AND DEVELOPMENTAL SYSTEMS 17
2022
-
[32]
Testing theory of mind in large language models and humans,
J. W. Strachan, D. Albergo, G. Borghini, O. Pansardi, E. Scaliti, S. Gupta, K. Saxena, A. Rufo, S. Panzeri, G. Manziet al., “Testing theory of mind in large language models and humans,”Nature Human Behaviour, vol. 8, no. 7, pp. 1285–1295, 2024
2024
-
[33]
Evaluating large language models in theory of mind tasks,
M. Kosinski, “Evaluating large language models in theory of mind tasks,” 2024. [Online]. Available: https://arxiv.org/abs/2302.02083
-
[34]
Beliefs about beliefs: Representation and constraining function of wrong beliefs in young children’s understand- ing of deception,
H. Wimmer and J. Perner, “Beliefs about beliefs: Representation and constraining function of wrong beliefs in young children’s understand- ing of deception,”Cognition, vol. 13, no. 1, pp. 103–128, 1983
1983
-
[35]
Does the autistic child have a “theory of mind
S. Baron-Cohen, A. M. Leslie, and U. Frith, “Does the autistic child have a “theory of mind”?”Cognition, vol. 21, no. 1, pp. 37–46, 1985
1985
-
[36]
Three-year-olds’ difficulty with false belief: The case for a conceptual deficit,
J. Perner, S. R. Leekam, and H. Wimmer, “Three-year-olds’ difficulty with false belief: The case for a conceptual deficit,”British journal of developmental psychology, vol. 5, no. 2, pp. 125–137, 1987
1987
-
[37]
Shared computational principles for language processing in humans and deep language models,
A. Goldstein, Z. Zada, E. Buchnik, M. Schain, A. Price, B. Aubrey, S. A. Nastase, A. Feder, D. Emanuel, A. Cohenet al., “Shared computational principles for language processing in humans and deep language models,”Nature neuroscience, vol. 25, no. 3, pp. 369–380, 2022
2022
-
[38]
Llms achieve adult human performance on higher-order theory of mind tasks,
W. Street, J. O. Siy, G. Keeling, A. Baranes, B. Barnett, M. McKibben, T. Kanyere, A. Lentz, R. I. Dunbaret al., “Llms achieve adult human performance on higher-order theory of mind tasks,”arXiv preprint arXiv:2405.18870, 2024
-
[39]
Position: Theory of mind benchmarks are broken for large language models,
M. Riemer, Z. Ashktorab, D. Bouneffouf, P. Das, M. Liu, J. D. Weisz, and M. Campbell, “Position: Theory of mind benchmarks are broken for large language models,” inProceedings of the 42nd International Conference on Machine Learning, ser. Proceedings of Machine Learning Research, vol. 267. PMLR, 2025, pp. 82 091–82 130. [Online]. Available: https://procee...
2025
-
[40]
Theory of mind in large language models: Assessment and enhancement,
R. Chen, W. Jiang, C. Qin, and C. Tan, “Theory of mind in large language models: Assessment and enhancement,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vienna, Austria: Association for Computational Linguistics, 2025, pp. 31 539–31 558. [Online]. Available: https://aclanthology.org/2...
2025
-
[41]
Demographic variables and personality: The effects of gender, age, education, and ethnic/racial status on self-descriptions of personality attributes,
L. R. Goldberg, D. Sweeney, P. F. Merenda, and J. E. Hughes Jr, “Demographic variables and personality: The effects of gender, age, education, and ethnic/racial status on self-descriptions of personality attributes,”Personality and Individual differences, vol. 24, no. 3, pp. 393–403, 1998
1998
-
[42]
Personality: A psychological interpretation
G. W. Allport, “Personality: A psychological interpretation.” 1937
1937
-
[43]
Out of one, many: Using language models to simulate human samples,
L. P. Argyle, E. C. Busby, N. Fulda, J. R. Gubler, C. Rytting, and D. Wingate, “Out of one, many: Using language models to simulate human samples,”Political Analysis, vol. 31, no. 3, pp. 337–351, 2023
2023
-
[44]
Evaluating the ability of large language models to emulate personality,
Y . Wang, J. Zhao, D. S. Ones, L. He, and X. Xu, “Evaluating the ability of large language models to emulate personality,”Scientific reports, vol. 15, no. 1, p. 519, 2025
2025
-
[45]
Effects of language-and culture- specific prompting on chatgpt,
M. Tuna, K. Schaaff, and T. Schlippe, “Effects of language-and culture- specific prompting on chatgpt,” in2024 2nd International Conference on Foundation and Large Language Models (FLLM). IEEE, 2024, pp. 73–81
2024
-
[46]
Large language models as superpositions of cultural perspectives,
G. Kova ˇc, M. Sawayama, R. Portelas, C. Colas, P. F. Dominey, and P.-Y . Oudeyer, “Large language models as superpositions of cultural perspectives,”arXiv preprint arXiv:2307.07870, 2023
-
[47]
R. Wang, S. Milani, J. C. Chiu, J. Zhi, S. M. Eack, T. Labrum, S. M. Murphy, N. Jones, K. Hardy, H. Shenet al., “Patient-{\Psi}: Using large language models to simulate patients for training mental health professionals,”arXiv preprint arXiv:2405.19660, 2024
-
[48]
The mixed subjects design: Treating large language models as potentially informative observa- tions,
D. Broska, M. Howes, and A. van Loon, “The mixed subjects design: Treating large language models as potentially informative observa- tions,”Sociological Methods & Research, p. 00491241251326865, 2025
2025
-
[49]
Llms simulate big five personality traits: Further ev- idence,
A. Sorokovikova, N. Fedorova, S. Rezagholi, T. Wien, and I. P. Yamshchikov, “Llms simulate big five personality traits: Further ev- idence,” inThe 1st Workshop on Personalization of Generative AI Systems, 2024, p. 83
2024
-
[50]
Large language models show amplified cognitive biases in moral decision-making,
V . Cheung, M. Maier, and F. Lieder, “Large language models show amplified cognitive biases in moral decision-making,”Proceedings of the National Academy of Sciences, vol. 122, no. 25, p. e2412015122, 2025
2025
-
[51]
Knowledge of cultural moral norms in large language models,
A. Ramezani and Y . Xu, “Knowledge of cultural moral norms in large language models,” inProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023, pp. 428–446
2023
-
[52]
Simulating diverse patient popu- lations using patient vignettes and large language models,
D. Reichenpfader and K. Denecke, “Simulating diverse patient popu- lations using patient vignettes and large language models,” inProceed- ings of the First Workshop on Patient-Oriented Language Processing (CL4Health)@ LREC-COLING 2024, 2024, pp. 20–25
2024
-
[53]
Virtual personas for language models via an anthology of backstories,
S. Moon, M. Abdulhai, M. Kang, J. Suh, W. Soedarmadji, E. Behar, and D. Chan, “Virtual personas for language models via an anthology of backstories,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, 2024, pp. 19 864–19 897
2024
-
[54]
Database report: Twin-2k-500: A data set for building digital twins of over 2,000 people based on their answers to over 500 questions,
O. Toubia, G. Z. Gui, T. Peng, D. J. Merlau, A. Li, and H. Chen, “Database report: Twin-2k-500: A data set for building digital twins of over 2,000 people based on their answers to over 500 questions,” Marketing Science, 2025
2025
-
[55]
PsyCoT: Psychological questionnaire as powerful chain-of-thought for personality detection,
T. Yang, T. Shi, F. Wan, X. Quan, Q. Wang, B. Wu, and J. Wu, “PsyCoT: Psychological questionnaire as powerful chain-of-thought for personality detection,” inFindings of the Association for Computational Linguistics: EMNLP 2023. Singapore: Association for Computational Linguistics, Dec. 2023, pp. 3305–3320. [Online]. Available: https://aclanthology.org/202...
2023
-
[56]
Linguistic styles: language use as an individual difference
J. W. Pennebaker and L. A. King, “Linguistic styles: language use as an individual difference.”Journal of personality and social psychology, vol. 77, no. 6, p. 1296, 1999
1999
-
[57]
Y . K. Lee, I. Lee, M. Shin, S. Bae, and S. Hahn, “Chain of empathy: Enhancing empathetic response of large language models based on psychotherapy models,”arXiv preprint arXiv:2311.04915, 2023
-
[58]
A computational approach to understanding empathy expressed in text-based mental health support,
A. Sharma, A. S. Miner, D. C. Atkins, and T. Althoff, “A computational approach to understanding empathy expressed in text-based mental health support,” inEMNLP, 2020
2020
-
[59]
S. Park and C. Kulkarni, “Thinking assistants: Llm-based conversa- tional assistants that help users think by asking rather than answering,” arXiv preprint arXiv:2312.06024, 2023
-
[60]
Wundtgpt: Shaping large language models to be an empathetic, proactive psychologist,
C. Ren, Y . Zhang, D. He, and J. Qin, “Wundtgpt: Shaping large language models to be an empathetic, proactive psychologist,”arXiv preprint arXiv:2406.15474, 2024
-
[61]
Psyqa: A chinese dataset for generating long counseling text for mental health support,
H. Sun, Z. Lin, C. Zheng, S. Liu, and M. Huang, “Psyqa: A chinese dataset for generating long counseling text for mental health support,” inFindings of the Association for Computational Linguistics: ACL 2021, 2021
2021
-
[62]
Large language models can infer personality from free-form user interactions,
H. Peters, M. Cerf, and S. C. Matz, “Large language models can infer personality from free-form user interactions,”arXiv preprint arXiv:2405.13052, 2024
-
[63]
Affective-nli: Towards accurate and interpretable personality recognition in conversation,
Z. Wen, J. Cao, Y . Yang, R. Yang, and S. Liu, “Affective-nli: Towards accurate and interpretable personality recognition in conversation,” in 2024 IEEE International Conference on Pervasive Computing and Communications (PerCom). IEEE, 2024, pp. 184–193
2024
-
[64]
Cped: A large-scale chinese personalized and emotional dia- logue dataset for conversational ai,
Y . Chen, W. Fan, X. Xing, J. Pang, M. Huang, W. Han, Q. Tie, and X. Xu, “Cped: A large-scale chinese personalized and emotional dia- logue dataset for conversational ai,”arXiv preprint arXiv:2205.14727, 2022
-
[65]
Psychat: A client-centric dialogue system for mental health support,
H. Qiu, A. Li, L. Ma, and Z. Lan, “Psychat: A client-centric dialogue system for mental health support,” in2024 27th International Confer- ence on Computer Supported Cooperative Work in Design (CSCWD). IEEE, 2024, pp. 2979–2984
2024
-
[66]
J. Nie, H. Shao, Y . Fan, Q. Shao, H. You, M. Preindl, and X. Jiang, “Llm-based conversational ai therapist for daily functioning screening and psychotherapeutic intervention via everyday smart devices,”arXiv preprint arXiv:2403.10779, 2024
-
[67]
H. Hu, Y . Zhou, J. Si, Q. Wang, H. Zhang, F. Ren, F. Ma, and L. Cui, “Beyond empathy: Integrating diagnostic and therapeutic reasoning with large language models for mental health counseling,”arXiv preprint arXiv:2505.15715, 2025
-
[68]
Eliciting human preferences with language models,
B. Li, A. Tamkin, N. Goodman, and J. Andreas, “Eliciting human preferences with language models,” inInternational Conference on Representation Learning, Y . Yue, A. Garg, N. Peng, F. Sha, and R. Yu, Eds., vol. 2025, 2025, pp. 80 984–81 013. [Online]. Available: https://proceedings.iclr.cc/paper files/paper/2025/ file/c9867d5a22653ce98b02595061e40f12-Paper...
2025
-
[69]
Modeling future conversation turns to teach LLMs to ask clarifying questions,
M. J. Zhang, W. B. Knox, and E. Choi, “Modeling future conversation turns to teach LLMs to ask clarifying questions,” inThe Thirteenth International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=cwuSAR7EKd
2025
-
[70]
AmbigQA: Answering ambiguous open-domain questions,
S. Min, J. Michael, H. Hajishirzi, and L. Zettlemoyer, “AmbigQA: Answering ambiguous open-domain questions,” inEMNLP, 2020
2020
-
[71]
Can chatgpt assess hu- man personalities? a general evaluation framework,
H. Rao, C. Leung, and C. Miao, “Can chatgpt assess hu- man personalities? a general evaluation framework,”arXiv preprint arXiv:2303.01248, 2023
-
[72]
Gpt is an effective tool for multilingual psycholog- ical text analysis,
S. Rathje, D.-M. Mirea, I. Sucholutsky, R. Marjieh, C. E. Robertson, and J. J. Van Bavel, “Gpt is an effective tool for multilingual psycholog- ical text analysis,”Proceedings of the National Academy of Sciences, vol. 121, no. 34, p. e2308950121, 2024. IEEE TRANSACTIONS ON COGNITIVE AND DEVELOPMENTAL SYSTEMS 18
2024
-
[73]
From text to emotion: Unveiling the emotion annotation capabilities of llms,
M. Niu, M. Jaiswal, and E. M. Provost, “From text to emotion: Unveiling the emotion annotation capabilities of llms,”arXiv preprint arXiv:2408.17026, 2024
-
[74]
EmoBank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis,
S. Buechel and U. Hahn, “EmoBank: Studying the impact of annotation perspective and representation format on dimensional emotion analysis,” inProceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 2, Short Papers, M. Lapata, P. Blunsom, and A. Koller, Eds. Valencia, Spain: Association for Comput...
2017
-
[75]
Mental-llm: Leveraging large language mod- els for mental health prediction via online text data,
X. Xu, B. Yao, Y . Dong, S. Gabriel, H. Yu, J. Hendler, M. Ghassemi, A. K. Dey, and D. Wang, “Mental-llm: Leveraging large language mod- els for mental health prediction via online text data,”Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, vol. 8, no. 1, pp. 1–32, 2024
2024
-
[76]
Dreaddit: A reddit dataset for stress analysis in social media,
E. Turcan and K. McKeown, “Dreaddit: A reddit dataset for stress analysis in social media,”arXiv preprint arXiv:1911.00133, 2019
-
[77]
Llm vs small model? large language model based text augmentation enhanced personality detection model,
L. Hu, H. He, D. Wang, Z. Zhao, Y . Shao, and L. Nie, “Llm vs small model? large language model based text augmentation enhanced personality detection model,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 16, 2024, pp. 18 234–18 242
2024
-
[78]
From post to personality: Harnessing llms for mbti prediction in social media,
T. Ma, K. Feng, Y . Rong, and K. Zhao, “From post to personality: Harnessing llms for mbti prediction in social media,”arXiv preprint arXiv:2509.04461, 2025
-
[79]
MBTI Type Dataset,
datasnaek, “MBTI Type Dataset,” https://www.kaggle.com/datasets/ datasnaek/mbti-type/data, 2017, accessed: 2025-10-15
2017
-
[80]
S. Teng, J. Liu, R. K. Jain, S. Chai, R. Hou, T. Tateyama, L. Lin, and Y .-w. Chen, “Enhancing depression detection with chain-of-thought prompting: From emotion to reasoning using large language models,” arXiv preprint arXiv:2502.05879, 2025
-
[81]
Avec 2019 workshop and challenge: state-of-mind, detecting depression with ai, and cross-cultural affect recognition,
F. Ringeval, B. Schuller, M. Valstar, N. Cummins, R. Cowie, L. Tavabi, M. Schmitt, S. Alisamir, S. Amiriparian, E.-M. Messneret al., “Avec 2019 workshop and challenge: state-of-mind, detecting depression with ai, and cross-cultural affect recognition,” inProceedings of the 9th International on Audio/visual Emotion Challenge and Workshop, 2019, pp. 3–12
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.