Counterfactual Trace Auditing of LLM Agent Skills
Pith reviewed 2026-05-13 05:29 UTC · model grok-4.3
The pith
Counterfactual Trace Auditing shows skills reshape LLM agent behavior in 522 specific ways even when pass rates change by less than one percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that Counterfactual Trace Auditing, by pairing with-skill and without-skill traces on identical tasks, segmenting into phases, and labeling Skill Influence Patterns, uncovers 522 instances of behavioral change from skills across 49 tasks, despite an average pass rate increase of only 0.3 percentage points. This reveals recurring effects such as literal template copying, off-task artifact creation, excess planning, and task recovery that standard evaluations miss. The analysis further finds that high-baseline tasks account for most effects due to saturated pass rates, moderate tasks offer recoverable gains at higher cost, and the dominant pattern type varies with the un-
What carries the argument
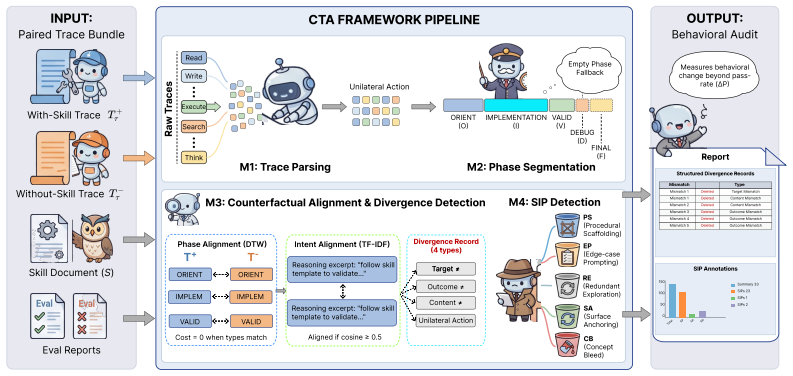
The Counterfactual Trace Auditing framework, which pairs agent execution traces with and without a skill, segments them into aligned goal-directed phases, and produces Skill Influence Pattern annotations describing the skill's behavioral effects.
If this is right
- Skills substantially reshape agent behavior, producing 522 Skill Influence Pattern instances even as pass rates change by just 0.3 percentage points.
- High baseline tasks contain most skill effects, yet their already high pass rates prevent these effects from appearing in outcome metrics.
- Moderate baseline tasks show the greatest potential for performance gains from skills, although this comes with substantially higher token costs.
- Surface anchoring effects predominate on ceiling tasks while edge-case prompting effects are most common on mid-range and floor tasks.
- Skills frequently induce specific undetectable behaviors including literal template copying, off-task artifact creation, excess planning, and task recovery.
Where Pith is reading between the lines
- Developers could use trace auditing to design skills that target precise behavioral fixes instead of relying only on outcome improvements.
- The same pairing approach might scale to evaluate other agent changes such as new tools or memory systems.
- Automated versions of the method could support ongoing checks for unintended behavior shifts after skill updates.
Load-bearing premise
That segmenting traces into goal-directed phases and aligning them across paired executions produces unbiased and reproducible annotations of skill effects.
What would settle it
High disagreement among independent annotators when labeling Skill Influence Patterns on the same trace pairs, or large changes in detected patterns when using alternative segmentation rules, would show the annotations do not reliably capture causal effects.
Figures
read the original abstract
Large Language Model agents are increasingly augmented with agent skills. Current evaluation methods for skills remain limited. Most deployed benchmarks report only pass rate before and after a skill is attached, treating the skill as a black box change to agent behavior. We introduce Counterfactual Trace Auditing (CTA), a framework for measuring how a skill changes agent behavior. CTA pairs each with skill agent trace with a without skill counterpart on the same task, segments both traces into goal directed phases, aligns the phases, and emits structured Skill Influence Pattern (SIP) annotations. These annotations describe the behavioral effect of a skill rather than only its task outcome. We instantiate CTA on SWE-Skills-Bench with Claude across 49 software engineering tasks. The resulting audit reveals a clear evaluation gap. Pass rate changes by only +0.3 percentage points on average, suggesting little aggregate effect. Yet CTA identifies 522 SIP instances across the same paired traces, showing that the skills substantially reshape agent behavior even when pass rate is nearly unchanged. The audit also separates several recurring effects that pass rate cannot detect, including literal template copying, off task artifact creation, excess planning, and task recovery. Three findings emerge. First, high baseline tasks contain most of the observed skill effects, although their pass rate is already saturated and therefore cannot reflect those effects. Second, tasks with moderate baseline performance show the most recoverable gain, but often at substantially higher token cost. Third, the dominant SIP type can be identified by baseline bucket: surface anchoring is most common on ceiling tasks and edge-case prompting is most common on mid-range and floor tasks. These regularities turn informal failure mode observations into reproducible behavioral measurements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Counterfactual Trace Auditing (CTA), a framework that pairs agent traces with and without a skill on the same task, segments them into goal-directed phases, aligns the phases, and annotates Skill Influence Patterns (SIPs) to measure behavioral changes beyond pass rates. Instantiated on SWE-Skills-Bench with Claude across 49 software engineering tasks, it reports an average pass-rate change of only +0.3 percentage points yet identifies 522 SIP instances, plus three findings on how effects vary by baseline performance bucket (surface anchoring dominant on ceiling tasks, edge-case prompting on mid-range/floor tasks).
Significance. If the CTA pipeline is shown to be reproducible and unbiased, the work provides a concrete advance over pass-rate-only evaluation by turning informal observations of skill side-effects into countable, comparable behavioral measurements. The empirical scale (49 tasks, 522 SIPs) and the separation of saturated-ceiling effects from recoverable mid-range gains are useful for the field of LLM agent evaluation.
major comments (2)
- [§3] §3 (CTA Framework description): The pipeline for segmenting traces into goal-directed phases, aligning paired phases, and emitting SIP annotations is presented at a high level but supplies no implementation details (manual, heuristic, or LLM-driven) and no validation metrics such as inter-annotator agreement, consistency across runs, or human validation of the resulting 522 SIPs. Because the headline claim (substantial behavioral reshaping despite near-zero pass-rate change) and the three reported regularities rest directly on these annotations, the absence of such checks is load-bearing.
- [Results] Results section (baseline-bucket analysis): The claim that high-baseline tasks contain most observed skill effects while moderate-baseline tasks show the most recoverable gain, and that dominant SIP type correlates with bucket, requires explicit bucket boundaries, task counts per bucket, and either statistical tests or confidence intervals; without them the regularities remain descriptive counts rather than robust findings.
minor comments (2)
- [Abstract] Abstract: 'each with skill agent trace' is missing a hyphen and should read 'each with-skill agent trace'.
- Notation: The paper introduces SIP and CTA as new terms; a short table or figure summarizing the SIP taxonomy would improve readability when the three findings are discussed.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The comments identify key areas where additional clarity and rigor will strengthen the manuscript. We address both major comments below and commit to revisions that directly incorporate the requested details and statistical support.
read point-by-point responses
-
Referee: [§3] §3 (CTA Framework description): The pipeline for segmenting traces into goal-directed phases, aligning paired phases, and emitting SIP annotations is presented at a high level but supplies no implementation details (manual, heuristic, or LLM-driven) and no validation metrics such as inter-annotator agreement, consistency across runs, or human validation of the resulting 522 SIPs. Because the headline claim (substantial behavioral reshaping despite near-zero pass-rate change) and the three reported regularities rest directly on these annotations, the absence of such checks is load-bearing.
Authors: We agree that Section 3 currently provides only a high-level overview and that reproducibility requires more detail. In the revised manuscript we will expand Section 3 with: (i) explicit pseudocode for trace segmentation into goal-directed phases, phase alignment across paired traces, and SIP annotation; (ii) specification of which steps are heuristic versus LLM-driven, including the exact prompts and decision rules employed; and (iii) validation results consisting of inter-annotator agreement (Cohen’s kappa) on a 20% random sample of traces and human expert validation of a stratified sample of the 522 SIPs. These additions will allow independent reproduction and direct assessment of annotation reliability. revision: yes
-
Referee: [Results] Results section (baseline-bucket analysis): The claim that high-baseline tasks contain most observed skill effects while moderate-baseline tasks show the most recoverable gain, and that dominant SIP type correlates with bucket, requires explicit bucket boundaries, task counts per bucket, and either statistical tests or confidence intervals; without them the regularities remain descriptive counts rather than robust findings.
Authors: We concur that the bucket analysis would be more robust with explicit definitions and statistical grounding. In the revision we will: (i) state the precise bucket thresholds (high: baseline pass rate ≥ 80 %, moderate: 40–79 %, low: < 40 %); (ii) report the number of tasks and SIPs falling into each bucket; and (iii) add chi-squared tests for the association between bucket and dominant SIP type together with 95 % confidence intervals on all reported proportions and pass-rate deltas. These changes will convert the current descriptive regularities into statistically supported observations. revision: yes
Circularity Check
No circularity: SIP counts and regularities are direct empirical outputs of trace auditing
full rationale
The paper's derivation consists of running paired agent traces (with/without skill), applying the described segmentation/alignment/ annotation pipeline to produce SIP instances, and tabulating the resulting 522 counts plus bucketed regularities. No parameters are fitted on a data subset and then invoked to 'predict' the same or closely related quantities. No equations reduce the headline measurements to self-definitions or prior self-citations by construction. The framework is presented as a measurement procedure whose outputs are the observed annotations; the central claim therefore remains independent of the inputs rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent traces can be reliably segmented into goal-directed phases and aligned across with-skill and without-skill conditions.
invented entities (2)
-
Skill Influence Pattern (SIP)
no independent evidence
-
Counterfactual Trace Auditing (CTA)
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Harnessing Agent Skills: Architectural Patterns and a Reference Architecture for Skill-Mediated LLM Agents
Catalogs ten patterns and synthesizes a four-layer reference architecture for skill harnessing in LLM agents, evaluated via cross-instantiation on eight systems.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.