Forecasting With LLMs: Improved Generalization Through Feature Steering
Pith reviewed 2026-06-26 04:39 UTC · model grok-4.3
The pith
Amplifying time-awareness features in LLMs reduces look-ahead bias while preserving general reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
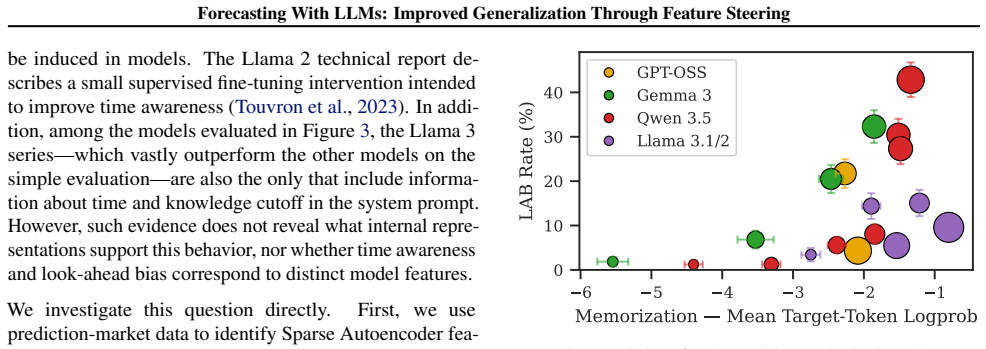
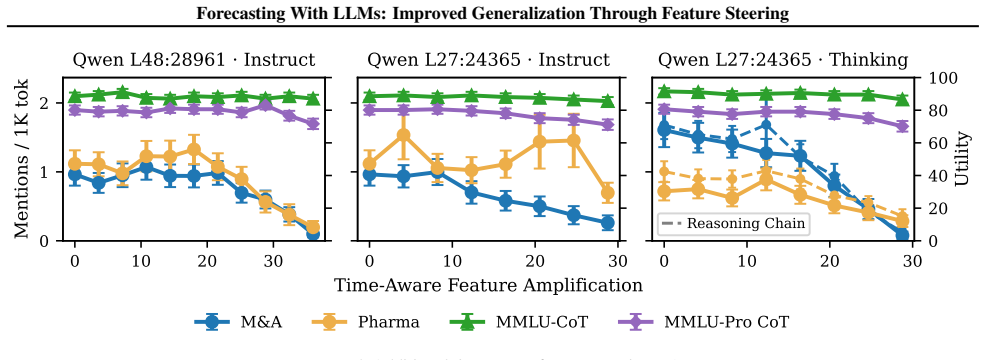
The authors use sparse autoencoders to find features associated with time-aware reasoning and look-ahead-biased reasoning in LLMs on forecasting tasks. Intervening by amplifying the time-awareness features in an entirely different domain reduces look-ahead bias on forecasting prompts while preserving general reasoning performance. In contrast, steering the candidate look-ahead-bias features does not produce an effect. This suggests that interpretable temporal features can be used to causally shift LLMs toward more historically grounded reasoning.
What carries the argument
Sparse autoencoders that identify and allow intervention on features for time-aware reasoning versus look-ahead-biased reasoning within LLM activations.
If this is right
- Amplifying time-awareness features reduces look-ahead bias on forecasting prompts.
- General reasoning performance is preserved after the intervention.
- Steering look-ahead-bias features does not reduce the bias.
- The effect transfers when applied to an entirely different domain.
- Interpretable features enable causal shifts in LLM reasoning toward historical grounding.
Where Pith is reading between the lines
- If feature steering works for temporal bias, it may apply to other biases like factual or logical ones by targeting their corresponding features.
- Models could be made more reliable for real-world forecasting applications by routinely amplifying such time-awareness features.
- The asymmetry in effects suggests look-ahead bias may arise from more distributed mechanisms than time-awareness.
- Further tests could check if the same features work across different model architectures.
Load-bearing premise
The features extracted by sparse autoencoders causally correspond to time-aware versus look-ahead-biased reasoning and interventions on them transfer across domains.
What would settle it
If amplifying the time-awareness features fails to reduce look-ahead bias or harms general reasoning on the new domain, the central claim would not hold.
Figures


read the original abstract
Successful forecasting involves identifying patterns between historical and future states of the world which generalize to future observations. We apply LLMs to a variety of forecasting tasks and inspect their internal states using sparse autoencoders to understand whether they appear to rely on time-specific pieces of knowledge versus generalizable patterns. Our analyses identify features associated with both time-aware reasoning and look-ahead-biased reasoning. We then apply the LLMs to an entirely different domain and intervene on these features. We find that amplifying time-awareness features substantially reduces look-ahead bias on forecasting prompts while preserving general reasoning performance. In contrast, steering the candidate look-ahead-bias features does not produce an effect. These results suggest that interpretable temporal features can be used to causally shift LLMs toward more historically grounded reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper applies LLMs to forecasting tasks and uses sparse autoencoders to identify internal features associated with time-aware reasoning versus look-ahead-biased reasoning. It then performs interventions on these features in a held-out domain, reporting that amplification of time-awareness features reduces look-ahead bias on forecasting prompts while preserving general reasoning performance, whereas steering the candidate look-ahead-bias features produces no effect.
Significance. If the empirical dissociation holds under rigorous controls, the work supplies a concrete demonstration that SAE-derived features can be causally manipulated to shift LLM behavior toward more historically grounded forecasting without collateral damage to general capabilities. This is a useful data point for mechanistic interpretability research and for practical feature-steering techniques.
minor comments (2)
- [Abstract] Abstract: the summary of results would be strengthened by a brief mention of the number of forecasting tasks, model scale, or quantitative effect sizes (e.g., accuracy deltas or bias metrics) so readers can immediately gauge the magnitude of the reported dissociation.
- [Methods] The manuscript should clarify in the methods section how the held-out domain was chosen and whether any domain-specific adaptation of the SAE or steering vectors was performed.
Simulated Author's Rebuttal
We thank the referee for their positive summary of the work and for recommending minor revision. The referee's description of the paper is accurate. No specific major comments were listed in the report.
Circularity Check
No significant circularity identified
full rationale
The paper's central result derives from empirical SAE feature extraction on internal activations followed by targeted steering interventions on a held-out domain, producing a selective behavioral dissociation (time-awareness features reduce look-ahead bias; candidate bias features do not). No equations, parameter fits presented as predictions, self-definitional loops, or load-bearing self-citation chains appear in the described protocol. The claims rest on observable intervention outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
invented entities (2)
-
time-awareness features
no independent evidence
-
look-ahead-bias features
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Fast and Effective Solution to the Problem of Look-ahead Bias in
Humzah Merchant and Bradford Levy , booktitle=. A Fast and Effective Solution to the Problem of Look-ahead Bias in. 2026 , url=
2026
-
[2]
Forty-third International Conference on Machine Learning , year=
Divergence Decoding: Inference-Time Unlearning via Auxiliary Models , author=. Forty-third International Conference on Machine Learning , year=. 2605.31293 , archivePrefix=
-
[3]
Position: Evaluating
Yaxuan Kong and Hoyoung Lee and Yoontae Hwang and Alejandro Lopez-Lira and Bradford Levy and Dhagash Mehta and Qingsong Wen and CHANYEOL CHOI and Yongjae Lee and Stefan Zohren , booktitle=. Position: Evaluating. 2026 , url=
2026
-
[6]
2023 , eprint=
Llama 2: Open Foundation and Fine-Tuned Chat Models , author=. 2023 , eprint=
2023
-
[7]
2024 , eprint=
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2 , author=. 2024 , eprint=
2024
-
[9]
2024 , month=
Lookahead Bias in Pretrained Language Models , author=. 2024 , month=
2024
-
[10]
2025 , eprint=
Chronologically Consistent Large Language Models , author=. 2025 , eprint=
2025
-
[11]
2025 , month=
Entity Neutering , author=. 2025 , month=
2025
-
[12]
2023 , eprint=
Assessing Look-Ahead Bias in Stock Return Predictions Generated By GPT Sentiment Analysis , author=. 2023 , eprint=
2023
-
[13]
2025 , eprint=
LLM-as-a-Prophet: Understanding Predictive Intelligence with Prophet Arena , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
Time Awareness in Large Language Models: Benchmarking Fact Recall Across Time , author=. 2025 , eprint=
2025
-
[15]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[16]
The Twelfth International Conference on Learning Representations , year=
Sparse Autoencoders Find Highly Interpretable Features in Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[17]
2024 , journal=
Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet , author=. 2024 , journal=
2024
-
[18]
2025 , eprint=
Steering Language Model Refusal with Sparse Autoencoders , author=. 2025 , eprint=
2025
-
[20]
E., Hume, T., Carter, S., Henighan, T., and Olah, C
Bricken, T., Templeton, A., Batson, J., Chen, B., Jermyn, A., Conerly, T., Turner, N., Anil, C., Denison, C., Askell, A., Lasenby, R., Wu, Y., Kravec, S., Schiefer, N., Maxwell, T., Joseph, N., Hatfield-Dodds, Z., Tamkin, A., Nguyen, K., McLean, B., Burke, J. E., Hume, T., Carter, S., Henighan, T., and Olah, C. Towards monosemanticity: Decomposing languag...
2023
-
[21]
Qwen-Scope : Turning sparse features into development tools for large language models, 2026
Deng, B., Wang, X., Wang, Y., Wan, Y., Ma, Y., Yang, B., Wei, H., Tang, J., Lin, H., Gao, R., Li, T., Cao, Q., Ren, X., Deng, X., Yang, A., Huang, F., Liu, D., and Zhou, J. Qwen-Scope : Turning sparse features into development tools for large language models, 2026. URL https://arxiv.org/abs/2605.11887
Pith/arXiv arXiv 2026
-
[22]
and Eisenschlos, Julian Martin and Gillick, Daniel and Eisenstein, Jacob and Cohen, William W
Dhingra, B., Cole, J. R., Eisenschlos, J. M., Gillick, D., Eisenstein, J., and Cohen, W. W. Time-aware language models as temporal knowledge bases. Transactions of the Association for Computational Linguistics, 10: 0 257–273, 2022. ISSN 2307-387X. doi:10.1162/tacl_a_00459. URL http://dx.doi.org/10.1162/tacl_a_00459
-
[23]
Drinkall, F., Rahimikia, E., Pierrehumbert, J., and Zohren, S. Time machine GPT . In Duh, K., Gomez, H., and Bethard, S. (eds.), Findings of the Association for Computational Linguistics: NAACL 2024, pp.\ 3281--3292, Mexico City, Mexico, June 2024. Association for Computational Linguistics. doi:10.18653/v1/2024.findings-naacl.208. URL https://aclanthology...
-
[24]
Engelberg, J., Manela, A., Mullins, W., and Vulicevic, L. Entity neutering. March 2025. doi:10.2139/ssrn.5182756. Available at SSRN: 5182756
-
[25]
Glasserman, P. and Lin, C. Assessing look-ahead bias in stock return predictions generated by gpt sentiment analysis, 2023. URL https://arxiv.org/abs/2309.17322
arXiv 2023
-
[26]
Chronologically consistent large language models, 2025
He, S., Lv, L., Manela, A., and Wu, J. Chronologically consistent large language models, 2025. URL https://arxiv.org/abs/2502.21206
arXiv 2025
-
[27]
Time awareness in large language models: Benchmarking fact recall across time, 2025
Herel, D., Bartek, V., Jirak, J., and Mikolov, T. Time awareness in large language models: Benchmarking fact recall across time, 2025. URL https://arxiv.org/abs/2409.13338
arXiv 2025
-
[28]
R., Ewart, A., and Sharkey, L
Huben, R., Cunningham, H., Smith, L. R., Ewart, A., and Sharkey, L. Sparse autoencoders find highly interpretable features in language models. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=F76bwRSLeK
2024
-
[29]
Position: Evaluating LLM s in finance requires explicit bias consideration
Kong, Y., Lee, H., Hwang, Y., Lopez-Lira, A., Levy, B., Mehta, D., Wen, Q., CHOI, C., Lee, Y., and Zohren, S. Position: Evaluating LLM s in finance requires explicit bias consideration. In Forty-third International Conference on Machine Learning Position Paper Track, 2026. URL https://openreview.net/forum?id=EDsAEXBFBk
2026
-
[30]
Caution ahead: Numerical reasoning and look-ahead bias in ai models
Levy, B. Caution ahead: Numerical reasoning and look-ahead bias in ai models. Journal of Accounting Research, 64 0 (3): 0 1139--1188, 2026. doi:https://doi.org/10.1111/1475-679x.70058. URL https://onlinelibrary.wiley.com/doi/abs/10.1111/1475-679x.70058
-
[31]
Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024
Lieberum, T., Rajamanoharan, S., Conmy, A., Smith, L., Sonnerat, N., Varma, V., Kramár, J., Dragan, A., Shah, R., and Nanda, N. Gemma scope: Open sparse autoencoders everywhere all at once on gemma 2, 2024. URL https://arxiv.org/abs/2408.05147
Pith/arXiv arXiv 2024
-
[32]
and Levy, B
Merchant, H. and Levy, B. A fast and effective solution to the problem of look-ahead bias in LLM s. In NeurIPS 2025 Workshop: Generative AI in Finance, 2026 a . URL https://openreview.net/forum?id=zYsLIPgM28
2025
-
[33]
and Levy, B
Merchant, H. and Levy, B. Divergence decoding: Inference-time unlearning via auxiliary models. In Forty-third International Conference on Machine Learning, 2026 b . URL https://openreview.net/forum?id=JPbp2S9yTO
2026
-
[34]
Steering language model refusal with sparse autoencoders, 2025
O'Brien, K., Majercak, D., Fernandes, X., Edgar, R., Bullwinkel, B., Chen, J., Nori, H., Carignan, D., Horvitz, E., and Poursabzi-Sangdeh, F. Steering language model refusal with sparse autoencoders, 2025. URL https://arxiv.org/abs/2411.11296
arXiv 2025
-
[35]
Sarkar, S. and Vafa, K. Lookahead bias in pretrained language models. June 2024. doi:10.2139/ssrn.4754678. Available at SSRN: 4754678
-
[36]
L., McDougall, C., MacDiarmid, M., Freeman, C
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., Pearce, A., Citro, C., Ameisen, E., Jones, A., Cunningham, H., Turner, N. L., McDougall, C., MacDiarmid, M., Freeman, C. D., Sumers, T. R., Rees, E., Batson, J., Jermyn, A., Carter, S., Olah, C., and Henighan, T. Scaling monosemanticity: Extracting interpretable features from clau...
2024
-
[37]
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., Bikel, D., Blecher, L., Ferrer, C. C., Chen, M., Cucurull, G., Esiobu, D., Fernandes, J., Fu, J., Fu, W., Fuller, B., Gao, C., Goswami, V., Goyal, N., Hartshorn, A., Hosseini, S., Hou, R., Inan, H., Kardas, M., Kerkez, V., Khabsa...
Pith/arXiv arXiv 2023
-
[38]
Llm-as-a-prophet: Understanding predictive intelligence with prophet arena, 2025
Yang, Q., Mahns, S., Li, S., Gu, A., Wu, J., and Xu, H. Llm-as-a-prophet: Understanding predictive intelligence with prophet arena, 2025. URL https://arxiv.org/abs/2510.17638
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.