BatchGen: An Architecture for Scalable and Efficient Batch Inference
Pith reviewed 2026-06-26 12:56 UTC · model grok-4.3
The pith
Representing sequences as event-driven coroutines lets batch inference systems reorganize work at runtime for higher GPU utilization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
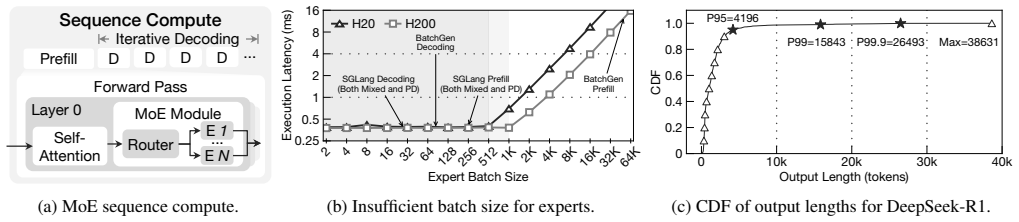
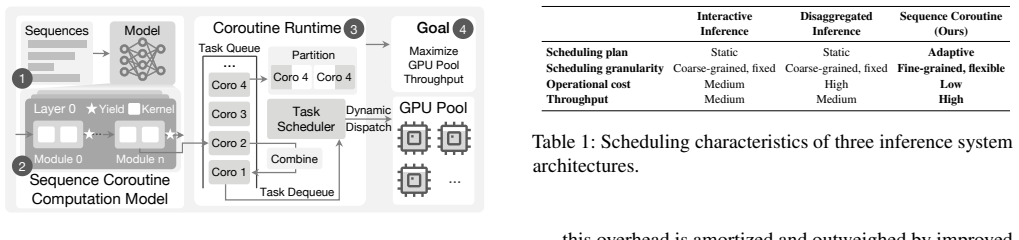
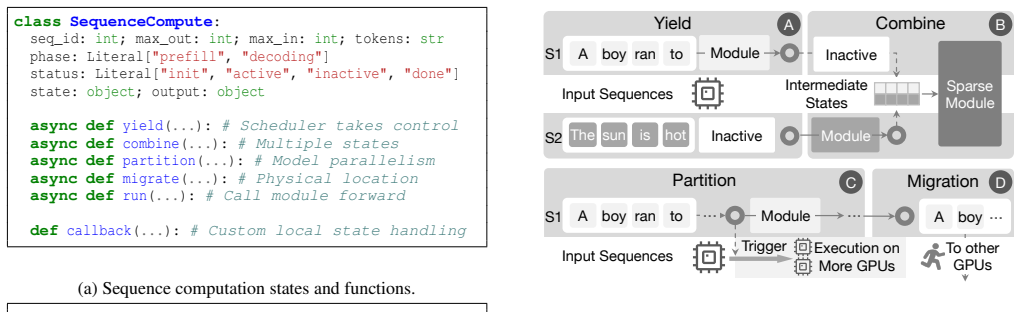
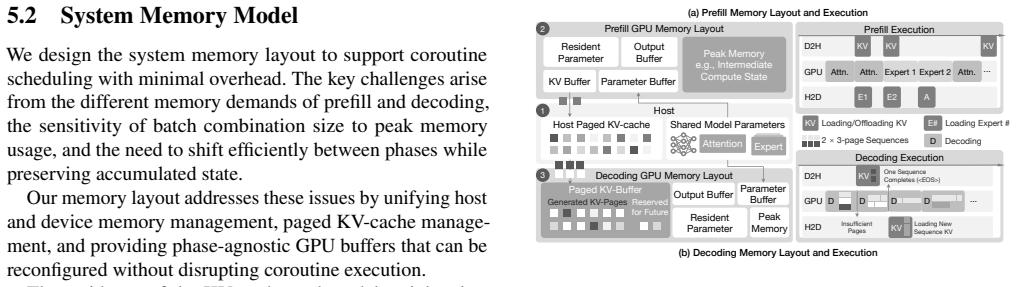
The sequence coroutine compute model represents each sequence as a fine-grained, event-driven coroutine. This abstraction exposes primitives that allow the runtime to reorganize work dynamically, enabling larger expert-level batches, mitigating stragglers, reallocating work across devices, and maintaining utilization even on cost-effective or memory-constrained GPUs.
What carries the argument
The sequence coroutine compute model, which turns each sequence into an event-driven coroutine so the runtime can reorganize computation on the fly.
If this is right
- Larger expert-level batches become feasible without straggler bottlenecks.
- Work can be reallocated across devices at runtime to keep all GPUs busy.
- Utilization remains high on memory-constrained or lower-cost accelerators.
- Batch completion time drops by up to 2.3 imes on 128-GPU clusters.
- Outperformance versus offloading baselines reaches up to 9.6 imes on memory-limited hardware.
Where Pith is reading between the lines
- The same coroutine primitives could be applied to other variable-workload distributed tasks such as large-scale simulation or data processing.
- Production inference engines might adopt the model incrementally by wrapping existing kernels rather than rewriting entire schedulers.
- The approach could lower the hardware requirements for high-throughput batch jobs by extracting more performance from commodity GPUs.
Load-bearing premise
The observed speedups stem primarily from the coroutine primitives rather than from unstated implementation choices, workload selection, or hardware tuning.
What would settle it
A controlled run on the same 128-GPU cluster and workloads that turns off the dynamic reorganization primitives while retaining all other optimizations and measures whether the 2.3 imes and 9.6 imes gains disappear.
Figures




read the original abstract
Batch inference has become a central mode of AI computation, yet existing inference engines still rely on execution models designed for interactive serving. When scaled to millions of sequences, batch workloads reveal two fundamental requirements: the ability to handle extreme inter- and intra-sequence load variation that emerges only at runtime, and the ability to sustain high utilization across large fleets of GPUs. Existing systems fail to meet these requirements, losing substantial fractions of achievable throughput. We introduce a new architectural foundation for batch inference: the sequence coroutine compute model, which represents each sequence as a fine-grained, event-driven coroutine. This model exposes expressive primitives that allow the runtime to reorganize work dynamically, enabling larger expert-level batches, mitigating stragglers, reallocating work across devices, and maintaining utilization even on cost-effective or memory-constrained GPUs. Building on this abstraction, we implement BatchGen, a production-ready system that uses the coroutine model at cluster scale. On a 128-GPU cluster, BatchGen reduces batch completion time by up to $2.3\times$, and on memory-constrained accelerators it outperforms the strongest offloading baseline by up to $9.6\times$. We will open-source BatchGen at https://github.com/batchgen-project/batchgen
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents BatchGen, a system for scalable and efficient batch inference based on the sequence coroutine compute model. This model treats each sequence as a fine-grained, event-driven coroutine, exposing primitives for dynamic work reorganization to handle inter- and intra-sequence load variation, mitigate stragglers, reallocate work across devices, and maintain high utilization on various GPUs including memory-constrained ones. On a 128-GPU cluster, it claims up to 2.3× reduction in batch completion time, and up to 9.6× better performance than the strongest offloading baseline on memory-constrained accelerators. The system is to be open-sourced.
Significance. Should the reported performance improvements be validated through detailed experiments, this work would offer a significant advancement in the design of batch inference systems for large-scale AI workloads. By shifting from interactive-serving-oriented models to one optimized for batch processing with high variability, it addresses key inefficiencies in current systems. The open-source release would be particularly valuable for the community.
major comments (1)
- [Abstract] Abstract: The abstract reports concrete speedups (2.3× on 128-GPU cluster and 9.6× vs offloading baseline) but provides no details on experimental setup, baselines, error bars, workload characteristics, or measurement methodology. As noted in the review materials, the central performance claims cannot be evaluated from the given information, undermining the ability to assess the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential significance of the sequence coroutine model for batch inference. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports concrete speedups (2.3× on 128-GPU cluster and 9.6× vs offloading baseline) but provides no details on experimental setup, baselines, error bars, workload characteristics, or measurement methodology. As noted in the review materials, the central performance claims cannot be evaluated from the given information, undermining the ability to assess the contribution.
Authors: We agree that the abstract, in its current form, is concise and omits explicit details on experimental setup, baselines, workloads, error bars, and methodology. This is a valid observation, as abstracts are intentionally brief. The full manuscript (Sections 5 and 6) provides the requested information, including the 128-GPU cluster configuration, workload characteristics (sequence length distributions and batch sizes drawn from production traces), comparison baselines (including the strongest offloading system), measurement methodology (end-to-end batch completion time with wall-clock timing), and reporting of results with variability. To directly address the concern, we will revise the abstract in the next version to include a short clause summarizing the evaluation setting (e.g., 'evaluated on a 128-GPU cluster using diverse LLM inference workloads against state-of-the-art baselines'). We believe this change will allow readers to better contextualize the reported speedups without exceeding typical abstract length constraints. revision: yes
Circularity Check
No significant circularity
full rationale
The paper introduces the sequence coroutine compute model as an architectural foundation and reports empirical speedups (2.3× on 128-GPU cluster, 9.6× vs offloading baseline) from system implementation and measurements. No equations, derivations, fitted parameters, predictions, or self-citations appear in the provided text. All central claims are performance statements grounded in experiments rather than any reduction to inputs by construction, self-definition, or load-bearing self-citation chains. The derivation chain is therefore self-contained with no circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Process multiple prompts with batch in- ference
Amazon AWS. Process multiple prompts with batch in- ference. https://docs.aws.amazon.com/bedrock/ latest/userguide/batch-inference.html, 2025. Accessed: 2025-12-02
2025
-
[2]
L-eval: Instituting standardized evaluation for long context language models
Chenxin An, Shansan Gong, Ming Zhong, Xingjian Zhao, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models. InProceedings of the 62nd An- nual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 14388–14411, 2024
2024
-
[3]
Apache HTTP server project
Apache HTTP Server Project Members. Apache HTTP server project. https://httpd.apache.org/, 2025. Accessed: 2025-12-06
2025
-
[4]
LongBench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. LongBench: A bilingual, multitask benchmark for long context understanding. InACL (1), pages 3119–3137. Association for Computational Linguistics, 2024
2024
-
[5]
Beyond the imitation game: Quan- tifying and extrapolating the capabilities of language models.Trans
BIG-bench authors. Beyond the imitation game: Quan- tifying and extrapolating the capabilities of language models.Trans. Mach. Learn. Res., 2023, 2023
2023
-
[6]
verl: V olcano Engine Reinforce- ment Learning for LLMs
Bytedance Seed. verl: V olcano Engine Reinforce- ment Learning for LLMs . https://github.com/ volcengine/verl, 2025. Accessed: 2025-12-09
2025
-
[7]
Gonzalez, Matei Za- haria, and Ion Stoica
Shiyi Cao, Shu Liu, Tyler Griggs, Peter Schafhalter, Xi- aoxuan Liu, Ying Sheng, Joseph E. Gonzalez, Matei Za- haria, and Ion Stoica. MoE-Lightning: High-throughput moe inference on memory-constrained gpus. InASP- LOS (1), pages 715–730. ACM, 2025
2025
-
[8]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y . Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory- efficient exact attention with io-awareness. InNeurIPS, 2022
2022
-
[9]
Deepseek AI. DeepEP. https://github.com/ deepseek-ai/DeepEP, 2025. Accessed: 2025-12-06
2025
-
[10]
DeepGEMM
Deepseek AI. DeepGEMM. https://github.com/ deepseek-ai/DeepGEMM, 2025. Accessed: 2025-12- 06
2025
-
[11]
DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning
DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in llms via reinforcement learning. 2025
2025
-
[12]
DeepSpeed
DeepSpeed Team. DeepSpeed. https://github.com/ deepspeedai/DeepSpeed, 2025. Accessed: 2025-12- 09
2025
-
[13]
Bitdecoding: Unlocking tensor cores for long-context llms with low-bit kv cache, 2025
Dayou Du, Shijie Cao, Jianyi Cheng, Luo Mai, Ting Cao, and Mao Yang. Bitdecoding: Unlocking tensor cores for long-context llms with low-bit kv cache, 2025
2025
-
[14]
Eltabakh, Zan Ahmad Naeem, Moham- mad Shahmeer Ahmad, Mourad Ouzzani, and Nan Tang
Mohamed Y . Eltabakh, Zan Ahmad Naeem, Moham- mad Shahmeer Ahmad, Mourad Ouzzani, and Nan Tang. RetClean: Retrieval-based tabular data cleaning using llms and data lakes.Proc. VLDB Endow., 17(12):4421– 4424, 2024
2024
-
[15]
ServerlessLLM: Low-latency serverless inference for large language models
Yao Fu, Leyang Xue, Yeqi Huang, Andrei-Octavian Brabete, Dmitrii Ustiugov, Yuvraj Patel, and Luo Mai. ServerlessLLM: Low-latency serverless inference for large language models. InOSDI. USENIX Association, 2024
2024
-
[16]
RollPacker: Mitigating long-tail rollouts for fast, synchronous RL post-training
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, Jiamang Wang, Lin Qu, Bo Zheng, and Wei Wang. RollPacker: Mitigating long-tail rollouts for fast, synchronous RL post-training. 2025
2025
-
[17]
OpenRLHF: A ray-based easy-to-use, scalable and high-performance rlhf frame- work
Jian Hu, Xibin Wu, Wei Shen, Jason Klein Liu, Weixun Wang, Songlin Jiang, Haoran Wang, Hao Chen, Bin Chen, Wenkai Fang, et al. OpenRLHF: A ray-based easy-to-use, scalable and high-performance rlhf frame- work. InProceedings of the 2025 Conference on Empir- ical Methods in Natural Language Processing: System Demonstrations, pages 656–666, 2025
2025
-
[18]
Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bam- ford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon An- toniak, T...
2024
-
[19]
NEO: saving GPU memory crisis with CPU offloading for online LLM inference, 2024
Xuanlin Jiang, Yang Zhou, Shiyi Cao, Ion Stoica, and Minlan Yu. NEO: saving GPU memory crisis with CPU offloading for online LLM inference, 2024
2024
-
[20]
MoE-CAP: Benchmarking cost, accuracy and performance of sparse mixture-of-experts systems
Yinsicheng Jiang, Yao Fu, Yeqi Huang, Ping Nie, Zhan Lu, Leyang Xue, Congjie He, Man-Kit Sit, Jilong Xue, Li Dong, et al. MoE-CAP: Benchmarking cost, accuracy and performance of sparse mixture-of-experts systems. Advances in Neural Information Processing Systems, 38, 2026
2026
-
[21]
Fiddler: CPU-GPU orchestration for fast inference of mixture-of-experts models, 2024
Keisuke Kamahori, Yile Gu, Kan Zhu, and Baris Kasikci. Fiddler: CPU-GPU orchestration for fast inference of mixture-of-experts models, 2024
2024
-
[22]
Kimi K2: open agentic intelligence, 2025
Kimi Team. Kimi K2: open agentic intelligence, 2025
2025
-
[23]
Efficient memory manage- ment for large language model serving with pagedatten- tion
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory manage- ment for large language model serving with pagedatten- tion. InSOSP, pages 611–626. ACM, 2023
2023
-
[24]
Accelerating distributed MoE training and inference with Lina
Jiamin Li, Yimin Jiang, Yibo Zhu, Cong Wang, and Hong Xu. Accelerating distributed MoE training and inference with Lina. InUSENIX Annual Technical Con- ference, pages 945–959. USENIX Association, 2023
2023
-
[25]
Holistic eval- uation of language models.Trans
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, and et al. Holistic eval- uation of language models.Trans. Mach. Learn. Res., 2023, 2023
2023
-
[26]
Janus: A unified distributed training framework for sparse Mixture-of-Experts models
Juncai Liu, Jessie Hui Wang, and Yimin Jiang. Janus: A unified distributed training framework for sparse Mixture-of-Experts models. InSIGCOMM, pages 486–
-
[27]
On LLMs-driven synthetic data generation, curation, and evaluation: A survey
Lin Long, Rui Wang, Ruixuan Xiao, Junbo Zhao, Xiao Ding, Gang Chen, and Haobo Wang. On LLMs-driven synthetic data generation, curation, and evaluation: A survey. InACL (Findings), pages 11065–11082. Associ- ation for Computational Linguistics, 2024
2024
-
[28]
The streaming batch model for efficient and fault-tolerant heteroge- neous execution, 2024
Frank Sifei Luan, Ziming Mao, Ron Yifeng Wang, Char- lotte Lin, Amog Kamsetty, Hao Chen, Cheng Su, Balaji Veeramani, Scott Lee, SangBin Cho, Clark Zinzow, Eric Liang, Ion Stoica, and Stephanie Wang. The streaming batch model for efficient and fault-tolerant heteroge- neous execution, 2024
2024
-
[29]
Taming hyper- parameters in deep learning systems.ACM SIGOPS Operating Systems Review, 53(1):52–58, 2019
Luo Mai, Alexandros Koliousis, Guo Li, Andrei- Octavian Brabete, and Peter Pietzuch. Taming hyper- parameters in deep learning systems.ACM SIGOPS Operating Systems Review, 53(1):52–58, 2019
2019
-
[30]
KungFu: Making training in distributed machine learn- ing adaptive
Luo Mai, Guo Li, Marcel Wagenländer, Konstantinos Fertakis, Andrei-Octavian Brabete, and Peter Pietzuch. KungFu: Making training in distributed machine learn- ing adaptive. In14th USENIX Symposium on Operating Systems Design and Implementation (OSDI 20), pages 937–954. USENIX Association, November 2020
2020
-
[31]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Hongyi Jin, Tianqi Chen, and Zhihao Jia. To- wards efficient generative large language model serving: A survey from algorithms to systems.arXiv preprint arXiv:2312.15234, 2023
arXiv 2023
-
[32]
Batch Endpoints
Microsoft Azure. Batch Endpoints. https://learn. microsoft.com/en-us/azure/machine-learning/ concept-endpoints-batch?view=azureml-api-2 ,
-
[33]
Accessed: 2025-12-02
2025
-
[34]
Jordan, and Ion Stoica
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Eli- bol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. Ray: A distributed framework for emerg- ing AI applications. InOSDI, pages 561–577. USENIX Association, 2018
2018
-
[35]
NGINX open source
NGINX Team. NGINX open source. https://nginx. org/index.html, 2025. Accessed: 2025-12-06
2025
-
[36]
TensorRT-LLM
NVIDIA. TensorRT-LLM. https://github.com/ NVIDIA/TensorRT-LLM, 2024. Accessed: 2024-05-17
2024
-
[37]
Ollama. Ollama. https://github.com/ollama/ ollama, 2025
2025
-
[38]
Batch API
OpenAI. Batch API. https://platform.openai. com/docs/guides/batch, 2025. Accessed: 2025-12- 02
2025
-
[39]
Gpt-5 system card
OpenAI. Gpt-5 system card. Technical report, OpenAI, August 2025. Accessed: 2025-12-11
2025
-
[40]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. Training lan- guage models to follow instructions with human f...
2022
-
[41]
Splitwise: Efficient generative LLM inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative LLM inference using phase splitting. InISCA, pages 118–132. IEEE, 2024
2024
-
[42]
A new era of intelligence with gem- ini 3
Sundar Pichai. A new era of intelligence with gem- ini 3. https://blog.google/products/gemini/ gemini-3/#note-from-ceo , November 2025. Ac- cessed: 2025-12-11
2025
-
[43]
Mooncake: Trading more storage for less computation - A kvcache-centric architecture for serving LLM chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation - A kvcache-centric architecture for serving LLM chatbot. InFAST, pages 155–170. USENIX Association, 2025
2025
-
[44]
Laradji, Parmida Atighehchian, David Vázquez, and Dzmitry Bahdanau
Gaurav Sahu, Pau Rodríguez, Issam H. Laradji, Parmida Atighehchian, David Vázquez, and Dzmitry Bahdanau. Data augmentation for intent classification with off-the- shelf large language models. InConvAI@ACL, pages 47–
-
[45]
Association for Computational Linguistics, 2022
2022
-
[46]
FlexGen: High- throughput generative inference of large language mod- els with a single GPU
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Ryabinin, Beidi Chen, Percy Liang, Christo- pher Ré, Ion Stoica, and Ce Zhang. FlexGen: High- throughput generative inference of large language mod- els with a single GPU. InICML, volume 202 ofPro- ceedings of Machine Learning Research, pages 31094– 31116. PMLR, 2023
2023
-
[47]
PowerInfer: Fast large language model serving with a consumer-grade GPU, 2023
Yixin Song, Zeyu Mi, Haotong Xie, and Haibo Chen. PowerInfer: Fast large language model serving with a consumer-grade GPU, 2023
2023
-
[48]
Obando-Ceron, Yoshua Bengio, Brian R
Siddarth Venkatraman, Vineet Jain, Sarthak Mittal, Vedant Shah, Johan S. Obando-Ceron, Yoshua Bengio, Brian R. Bartoldson, Bhavya Kailkhura, Guillaume La- joie, Glen Berseth, Nikolay Malkin, and Moksh Jain. Re- cursive self-aggregation unlocks deep thinking in large language models, 2025
2025
-
[49]
Tenplex: Dynamic parallelism for deep learning using parallelizable tensor collections
Marcel Wagenländer, Guo Li, Bo Zhao, Luo Mai, and Peter Pietzuch. Tenplex: Dynamic parallelism for deep learning using parallelizable tensor collections. InPro- ceedings of the ACM SIGOPS 30th Symposium on Op- erating Systems Principles, pages 195–210, 2024
2024
-
[50]
GEAR: A GPU-centric experience replay system for large reinforcement learning models
Hanjing Wang, Man-Kit Sit, Congjie He, Ying Wen, Weinan Zhang, Jun Wang, Yaodong Yang, and Luo Mai. GEAR: A GPU-centric experience replay system for large reinforcement learning models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceed- ings of the 40th International Conference on Ma...
2023
-
[51]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V . Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. InICLR. Open- Review.net, 2023
2023
-
[52]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V . Le, and Denny Zhou. Chain-of-Thought prompting elicits reasoning in large language models. InNeurIPS, 2022
2022
-
[53]
Culler, and Eric A
Matt Welsh, David E. Culler, and Eric A. Brewer. SEDA: an architecture for well-conditioned, scalable internet services. InSOSP, pages 230–243. ACM, 2001
2001
-
[54]
Grok 4 model card
xAI. Grok 4 model card. Technical report, xAI, August
-
[55]
Accessed: 2025-12-11
2025
-
[56]
Qwen2.5-omni technical report, 2025
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Jun- yang Lin. Qwen2.5-omni technical report, 2025
2025
-
[57]
Leyang Xue, Yao Fu, Zhan Lu, Luo Mai, and Ma- hesh Marina. Moe-infinity: Activation-aware expert offloading for efficient moe serving.arXiv preprint arXiv:2401.14361, 3, 2024
arXiv 2024
-
[58]
vllm-omni: Fully disaggregated serving for any-to-any multimodal models, 2026
Peiqi Yin, Jiangyun Zhu, Han Gao, Chenguang Zheng, Yongxiang Huang, Taichang Zhou, Ruirui Yang, Weizhi Liu, Weiqing Chen, Canlin Guo, Didan Deng, Zifeng Mo, Cong Wang, James Cheng, Roger Wang, and Hong- sheng Liu. vllm-omni: Fully disaggregated serving for any-to-any multimodal models, 2026
2026
-
[59]
Orca: A distributed serving system for transformer-based generative models
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soo- jeong Kim, and Byung-Gon Chun. Orca: A distributed serving system for transformer-based generative models. InOSDI, pages 521–538. USENIX Association, 2022
2022
-
[60]
Resilient dis- tributed datasets: A {Fault-Tolerant} abstraction for {In- Memory} cluster computing
Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauly, Michael J Franklin, Scott Shenker, and Ion Stoica. Resilient dis- tributed datasets: A {Fault-Tolerant} abstraction for {In- Memory} cluster computing. In9th USENIX symposium on networked systems design and implementation (NSDI 12), pages 15–28, 2012
2012
-
[61]
SmartMoE: Efficiently training sparsely-activated models through combining offline and online parallelization
Mingshu Zhai, Jiaao He, Zixuan Ma, Zan Zong, Run- qing Zhang, and Jidong Zhai. SmartMoE: Efficiently training sparsely-activated models through combining offline and online parallelization. InUSENIX Annual Technical Conference, pages 961–975. USENIX Asso- ciation, 2023
2023
-
[62]
Data cleaning using large language models
Shuo Zhang, Zezhou Huang, and Eugene Wu. Data cleaning using large language models. InICDEW, pages 28–32. IEEE, 2025
2025
-
[63]
Blendserve: Optimizing offline inference with resource-aware batching
Yilong Zhao, Shuo Yang, Kan Zhu, Lianmin Zheng, Baris Kasikci, Yifan Qiao, Yang Zhou, Jiarong Xing, and Ion Stoica. Blendserve: Optimizing offline inference with resource-aware batching. InProceedings of the 31st ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2, ASPLOS ’26, pages 255–273, New ...
2026
-
[64]
Xing, Joseph E
Lianmin Zheng, Zhuohan Li, Hao Zhang, Yonghao Zhuang, Zhifeng Chen, Yanping Huang, Yida Wang, Yuanzhong Xu, Danyang Zhuo, Eric P. Xing, Joseph E. Gonzalez, and Ion Stoica. Alpa: Automating inter- and intra-operator parallelism for distributed deep learning. InOSDI, pages 559–578. USENIX Association, 2022
2022
-
[65]
Gonzalez, Clark W
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark W. Barrett, and Ying Sheng. Sglang: Efficient execution of structured language model programs. InNeurIPS, 2024
2024
-
[66]
Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jianbo Hu, Yibo Zhu, Xuanzhe Liu, Xin Jin, and Hao Zhang. Dist- Serve: Disaggregating prefill and decoding for goodput- optimized large language model serving. InOSDI, pages 193–210. USENIX Association, 2024
2024
-
[67]
A survey on efficient inference for large language models.arXiv preprint arXiv:2404.14294, 2024
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Ji- aming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhi- hang Yuan, Xiuhong Li, et al. A survey on efficient inference for large language models.arXiv preprint arXiv:2404.14294, 2024
Pith/arXiv arXiv 2024
-
[68]
Nanoflow: Towards optimal large language model serving throughput
Kan Zhu, Yufei Gao, Yilong Zhao, Liangyu Zhao, Gefei Zuo, Yile Gu, Dedong Xie, Zihao Ye, Keisuke Kamahori, Chien-Yu Lin, Ziren Wang, Stephanie Wang, Arvind Krishnamurthy, and Baris Kasikci. Nanoflow: Towards optimal large language model serving throughput. In OSDI, pages 749–765. USENIX Association, 2025
2025
-
[69]
Ruidong Zhu, Ziheng Jiang, Chao Jin, Peng Wu, Cesar A. Stuardo, Dongyang Wang, Xinlei Zhang, Huaping Zhou, Haoran Wei, Yang Cheng, Jianzhe Xiao, Xinyi Zhang, Lingjun Liu, Haibin Lin, Li-Wen Chang, Jianxi Ye, Xiao Yu, Xuanzhe Liu, Xin Jin, and Xin Liu. MegaScale- Infer: Efficient mixture-of-experts model serving with disaggregated expert parallelism. InSIG...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.