Can LLM Teams Play What? Where? When?
Pith reviewed 2026-06-29 07:48 UTC · model grok-4.3
The pith
LLM teams using voting and communication protocols outperform single models by up to 20 percentage points on ChGK quiz questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
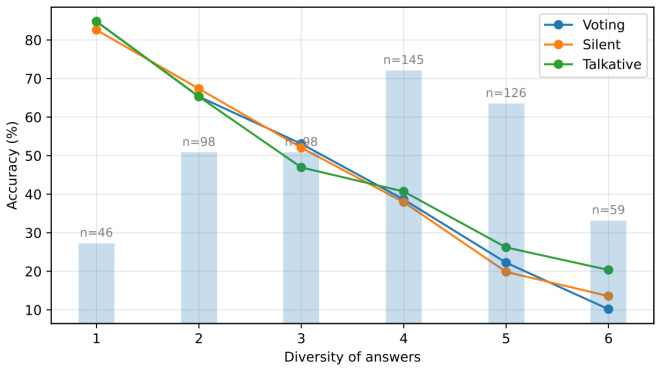
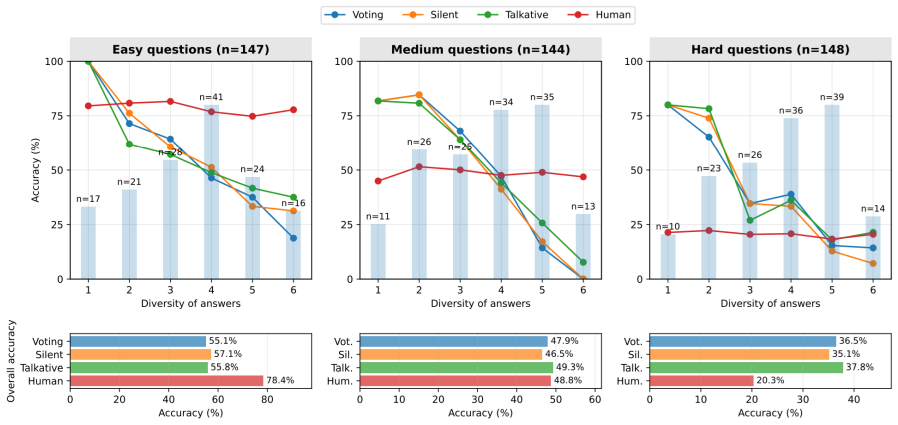
Team-based strategies improve LLM performance in ChGK, with the Voting, Silent Team, and Talkative Team protocols delivering gains of up to 20 percentage points over single-model baselines on 572 recent questions. The best team reaches 44.23 percent accuracy and approaches human team performance on questions with available statistics. Disagreement among models predicts lower accuracy, yet explanatory communication reduces the drop. Captains display no self-preference bias, and access to peer rationales improves their judgments. LLM teams operate primarily as answer selection and error-filtering mechanisms rather than generators of novel solutions.
What carries the argument
The three team interaction protocols (Voting, Silent Team where the captain sees only final answers, and Talkative Team where the captain sees answers plus rationales) that convert model disagreement into filtered selections.
If this is right
- Disagreement between models strongly predicts lower team accuracy.
- Explanatory communication substantially reduces accuracy drops caused by disagreement.
- Captains show no self-preference bias when selecting among peer answers.
- Access to peer rationales improves captain decision quality.
- LLM teams serve as answer selection and error-filtering mechanisms rather than sources of novel solutions.
Where Pith is reading between the lines
- The same interaction protocols could be tested on other benchmarks that require coordinated hypothesis testing to check whether the gains generalize.
- Smaller models might achieve larger relative improvements when teamed with stronger ones through error filtering.
- Allowing the system to switch between protocols depending on detected disagreement levels could produce additional gains beyond the fixed strategies tested.
Load-bearing premise
The 572 ChGK questions released in 2025 contain no training data overlap with the six evaluated models.
What would settle it
Applying the same three team protocols to a fresh set of ChGK questions released in 2026 and observing no accuracy gain over the single-model baselines would falsify the reported improvements.
Figures


read the original abstract
Large language models (LLMs) remain limited on tasks requiring indirect reasoning, cultural knowledge, and coordinated hypothesis testing. We investigate whether team-based interaction improves LLM performance in What? Where? When? (ChGK), a quiz game designed to reward collective reasoning. We introduce three team strategies: Voting, Silent Team (the captain observes final answers), and Talkative Team (the captain observes both answers and rationales). To minimize data leakage, we evaluate these strategies on a dataset consisting of 572 ChGK questions released in 2025. Using six recent large-scale open models, we show that team-based strategies outperform single-model baselines, yielding gains of up to 20 percentage points in accuracy. The best team achieves 44.23% accuracy, and approaches human team performance on questions with available human statistics. Analysis of inter-model diversity reveals that disagreement strongly predicts lower accuracy, but explanatory communication substantially mitigates performance drops. We further examine captain behavior and find no evidence of self-preference bias; access to peer rationales improves captain judgments. Overall, LLM teams function primarily as answer selection and error-filtering mechanisms rather than generators of novel solutions. Our findings highlight the importance of interaction and suggest adaptive strategies as a promising direction for multi-agent systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that three team interaction protocols (Voting, Silent Team, Talkative Team) among six recent open LLMs yield accuracy gains of up to 20 percentage points over single-model baselines on 572 ChGK questions released in 2025, with the best team reaching 44.23% accuracy and approaching human team performance on questions with available statistics. It further reports that inter-model disagreement predicts lower accuracy but rationale sharing mitigates drops, that captains show no self-preference bias, and that LLM teams primarily function as answer selection and error-filtering mechanisms rather than generators of novel solutions.
Significance. If the empirical results hold, the work provides concrete evidence that structured multi-agent interaction can improve LLM performance on tasks requiring indirect reasoning and cultural knowledge, with the diversity and captain-behavior analyses offering useful insights into when and how communication helps. The choice of recent questions and the explicit comparison to human statistics are strengths that make the findings more falsifiable than typical LLM evaluations.
major comments (3)
- [Abstract and §3] Abstract and §3 (Dataset and Evaluation): the statement that the 572 questions were chosen 'to minimize data leakage' is load-bearing for the central claim of genuine team gains, yet the manuscript provides no verification procedure (e.g., membership inference, n-gram overlap checks against training corpora, or held-out contamination tests). Without this, both single-model and team accuracies could be inflated by contamination.
- [§5] §5 (Results): the headline accuracy improvements (up to 20 pp, best team 44.23 %) are reported without error bars, per-question variance, or any statistical significance tests comparing team vs. single-model conditions, making it impossible to judge whether the observed differences are reliable or could arise from sampling variability.
- [§4] §4 (Team Protocols): the three interaction protocols are described at a high level but lack the precise implementation details (prompt templates, answer aggregation rules, temperature settings, and how the captain's final decision is elicited) needed to reproduce the reported numbers or to diagnose whether the gains stem from the interaction mechanism itself.
minor comments (2)
- [§3] The paper would benefit from an explicit statement of the exact six models and their release dates in the main text rather than only in an appendix.
- [Figures] Figure captions and axis labels should indicate whether accuracy is macro-averaged across questions or micro-averaged, and whether human baselines are computed on the identical question subset.
Simulated Author's Rebuttal
We thank the referee for the constructive comments that highlight opportunities to improve reproducibility, statistical rigor, and transparency. We address each major point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Dataset and Evaluation): the statement that the 572 questions were chosen 'to minimize data leakage' is load-bearing for the central claim of genuine team gains, yet the manuscript provides no verification procedure (e.g., membership inference, n-gram overlap checks against training corpora, or held-out contamination tests). Without this, both single-model and team accuracies could be inflated by contamination.
Authors: We agree that explicit verification procedures would strengthen the leakage-mitigation claim. The 2025 release date post-dates known training cutoffs for the six models, but we did not report n-gram overlap or other checks. In revision we will add a dedicated paragraph in §3 listing each model's public release date and training cutoff (where disclosed by providers), plus results of a simple 5-gram overlap scan against the question set. Full membership inference is not feasible without training data access, so this will be a partial revision focused on the checks that are practical. revision: partial
-
Referee: [§5] §5 (Results): the headline accuracy improvements (up to 20 pp, best team 44.23 %) are reported without error bars, per-question variance, or any statistical significance tests comparing team vs. single-model conditions, making it impossible to judge whether the observed differences are reliable or could arise from sampling variability.
Authors: The absence of error bars and significance tests is a clear limitation. We will revise §5 to include (i) bootstrap 95% confidence intervals computed over the 572 questions, (ii) per-question accuracy variance, and (iii) McNemar’s test for paired comparisons between each team protocol and its single-model baselines. These additions will allow readers to assess whether the reported gains are statistically reliable. revision: yes
-
Referee: [§4] §4 (Team Protocols): the three interaction protocols are described at a high level but lack the precise implementation details (prompt templates, answer aggregation rules, temperature settings, and how the captain's final decision is elicited) needed to reproduce the reported numbers or to diagnose whether the gains stem from the interaction mechanism itself.
Authors: We accept that the current high-level description impedes reproducibility. In the revised version we will add a new appendix containing the exact prompt templates for Voting, Silent Team, and Talkative Team, the aggregation rule (majority vote with captain tie-break), temperature values used (0.7 for generation, 0.0 for final answer extraction), and the full captain decision prompt. This will allow independent reproduction and diagnosis of the source of gains. revision: yes
Circularity Check
No significant circularity: purely empirical evaluation
full rationale
The paper reports direct empirical measurements of LLM accuracy on 572 held-out 2025 ChGK questions under three team protocols versus single-model baselines. No equations, derivations, fitted parameters, or self-citation chains appear in the abstract or described content. All reported gains (up to 20pp, best team 44.23%) are computed from observed answer correctness on the evaluation set and do not reduce to any input definition or prior self-citation. The work is self-contained against external benchmarks and contains no load-bearing steps that collapse by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer
Beware of reasoning overconfidence: Pitfalls in the reasoning process for multi-solution tasks.Comput- ing Research Repository, arXiv:2512.01725. Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly super- vised challenge dataset for reading comprehension. // Regina Barzilay and Min-Yen Kan,Proceedings of t...
-
[2]
Enhancing visual question answering with pre-trained vision-language models: An ensemble approach at the lava challenge 2024. // Minsu Cho, Ivan Laptev, Du Tran, Angela Yao, and Hong-Bin Zha,Computer Vision – ACCV 2024 Workshops, P 281–292, Singapore. Springer Nature Singapore. Shiwen Ni, Guhong Chen, Shuaimin Li, Xuanang Chen, Siyi Li, Bingli Wang, Qiyao...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.