LLM-Enhanced Deep Reinforcement Learning for Task Offloading in Collaborative Edge Computing
Pith reviewed 2026-05-08 05:30 UTC · model grok-4.3
The pith
LeDRL integrates a lightweight LLM to supply strategy priors that improve DRL-based task offloading decisions in collaborative edge networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
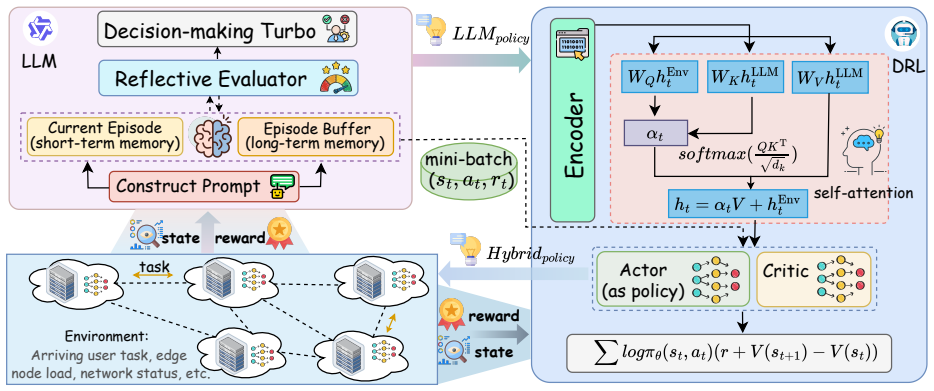
LeDRL constructs context-aware prompts from node status, task semantics, and link dynamics so a lightweight LLM can derive high-level strategy priors; a self-attention alignment module selectively incorporates those priors into DRL policy optimization; and a reflective evaluator distills semantic feedback from completed trajectories to make subsequent LLM queries more informative and temporally stable.
What carries the argument
The LeDRL hybrid framework that couples a lightweight LLM for generating strategy priors from structured prompts with a self-attention-enhanced DRL agent and a reflective evaluator that improves future prompts from execution history.
If this is right
- LeDRL raises task success rate by more than 17 percent over baselines across different network scales.
- The hybrid approach reaches policy convergence faster and maintains better responsiveness under changing conditions.
- The full system runs on Jetson-based edge hardware in the CoEdgeSys prototype without violating resource limits.
Where Pith is reading between the lines
- The same pattern of LLM-generated priors plus trajectory reflection could shorten learning time for DRL agents in other uncertain allocation settings such as wireless channel assignment.
- Reflective prompt improvement offers a concrete mechanism for making repeated LLM calls in sequential decision loops more efficient rather than treating each query in isolation.
- Successful edge-device deployment shows that hybrid LLM-DRL stacks need not require continuous cloud access to deliver usable performance.
Load-bearing premise
The lightweight LLM must reliably produce useful, context-appropriate strategy priors from the structured prompts in real time without adding unacceptable latency or unstable guidance.
What would settle it
Running identical experiments with the LLM component removed and checking whether the reported gains in task success rate and convergence speed disappear or reverse.
Figures






read the original abstract
Collaborative edge computing uses edge nodes in different locations to execute tasks, necessitating dynamic task offloading decisions to maintain low latency and high reliability, especially under unpredictable node failures. Although deep reinforcement learning (DRL) and large language models (LLMs) have shown promise for task offloading, DRL often suffers from poor sample efficiency and local optima, while LLMs are difficult to use directly due to inference overhead and output uncertainty. To address these limitations, we propose \textbf{LeDRL}, a hybrid decision framework that couples a \emph{lightweight LLM} with self-attention-enhanced DRL for real-time task offloading. LeDRL constructs structured, context-aware prompts capturing node status, task semantics, and link dynamics to derive high-level strategy priors. These are selectively processed by a self-attention-based alignment module for context-aware policy optimization. A reflective evaluator further distills semantic feedback from past trajectories to refine subsequent prompts and provide consistent guidance. Extensive experiments show that LeDRL outperforms representative baselines in task success rate, convergence speed, and real-time responsiveness across diverse network scales, achieving over 17\% improvement in success rate. Furthermore, we deploy LeDRL on Jetson-based edge devices using our prototype system \textit{CoEdgeSys}, demonstrating its robustness and feasibility under resource constraints. Our code is available at:https://github.com/GalleyG5/LeDRL.git.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LeDRL, a hybrid framework coupling a lightweight LLM with self-attention-enhanced DRL for real-time task offloading in collaborative edge computing. Structured prompts capture node status, task semantics, and link dynamics to produce strategy priors; a self-attention alignment module and reflective evaluator distill semantic feedback from trajectories to improve policy optimization. The central claims are that LeDRL outperforms baselines in task success rate (by over 17%), convergence speed, and responsiveness across network scales, with a Jetson-based deployment via the CoEdgeSys prototype demonstrating feasibility under resource constraints. Code is released at the cited GitHub repository.
Significance. If the empirical gains prove robust, the work offers a concrete demonstration of how lightweight LLMs can supply temporally generalizable priors to mitigate DRL sample inefficiency in latency-sensitive edge settings. The open-source release and hardware prototype are clear strengths that aid reproducibility and practical assessment.
major comments (2)
- [Experimental evaluation] The experimental results (described in the abstract and presumably §5) report >17% success-rate improvement and faster convergence without stating the number of independent trials, baseline configurations, statistical significance tests, or controls for overfitting/hyperparameter sensitivity. This leaves the central performance claim weakly supported.
- [Architecture and system deployment] No ablation removing the reflective evaluator, no per-component latency breakdown on Jetson hardware, and no measurement of how often LLM priors are used versus overridden by the DRL policy are provided. Without these, the attribution of convergence-speed and real-time responsiveness gains specifically to the hybrid mechanism cannot be verified, directly affecting the deployment claims.
minor comments (1)
- [Abstract] The abstract states 'over 17% improvement in success rate' without naming the precise baseline or metric variant in the summary paragraph.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment below and outline the revisions we will implement to improve experimental rigor and clarify component contributions.
read point-by-point responses
-
Referee: [Experimental evaluation] The experimental results (described in the abstract and presumably §5) report >17% success-rate improvement and faster convergence without stating the number of independent trials, baseline configurations, statistical significance tests, or controls for overfitting/hyperparameter sensitivity. This leaves the central performance claim weakly supported.
Authors: We acknowledge that the manuscript does not explicitly report the number of independent trials or include statistical significance testing. In the revised version, Section 5 will be updated to state that all results are averaged over 10 independent runs using different random seeds, with means and standard deviations provided. A table will be added detailing baseline configurations and hyperparameter settings. We will also include paired t-test results to establish statistical significance of the performance gains (p < 0.05). A hyperparameter sensitivity analysis will be incorporated to address overfitting concerns. These additions will strengthen the empirical claims. revision: yes
-
Referee: [Architecture and system deployment] No ablation removing the reflective evaluator, no per-component latency breakdown on Jetson hardware, and no measurement of how often LLM priors are used versus overridden by the DRL policy are provided. Without these, the attribution of convergence-speed and real-time responsiveness gains specifically to the hybrid mechanism cannot be verified, directly affecting the deployment claims.
Authors: We agree that these details are needed to verify the hybrid mechanism's contributions. The revision will include an ablation study removing the reflective evaluator, with quantitative comparison of its effect on convergence and success rates. For the Jetson-based CoEdgeSys deployment, we will add per-component latency measurements for LLM inference, self-attention alignment, and DRL policy execution. We will also instrument and report the frequency of LLM prior adoption versus DRL overrides based on alignment module outputs. These will be added to the experimental and deployment sections. revision: yes
Circularity Check
No circularity: empirical claims rest on experiments without self-referential derivations or fitted predictions
full rationale
The paper proposes the LeDRL hybrid framework (lightweight LLM for strategy priors + self-attention DRL + reflective evaluator) and supports its performance claims solely through experimental comparisons to baselines plus a Jetson deployment. No equations, parameter-fitting procedures, or derivation chains are present in the abstract or described architecture that could reduce a 'prediction' to an input by construction. Self-citations, if any, are not load-bearing for the central empirical results, which remain externally falsifiable via the reported success-rate gains and latency measurements.
Axiom & Free-Parameter Ledger
invented entities (1)
-
LeDRL hybrid framework
no independent evidence
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.