SFHand: Learning Embodied Manipulation by Streaming Egocentric 3D Hand Forecasting
Pith reviewed 2026-05-21 17:48 UTC · model grok-4.3
The pith
SFHand is the first streaming framework that autoregressively forecasts future 3D hand states from continuous egocentric video and language instructions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
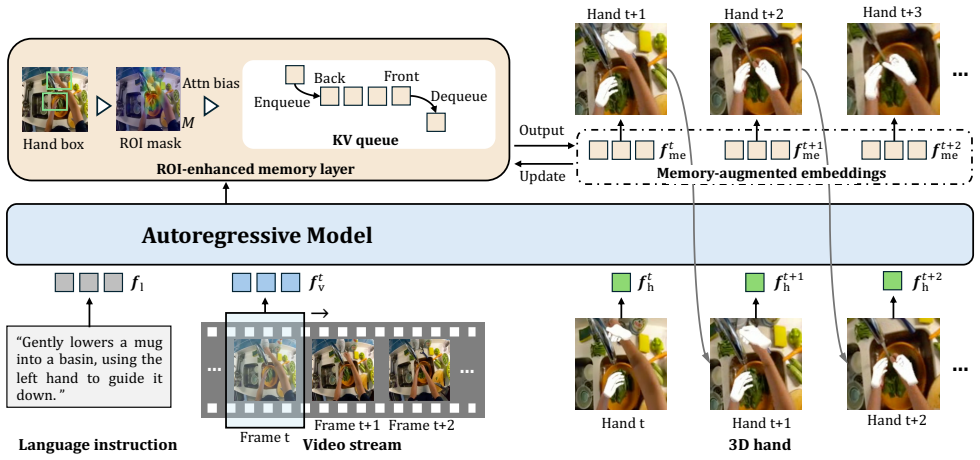
SFHand autoregressively predicts a comprehensive set of future 3D hand states, including hand type, 2D bounding box, 3D pose, and trajectory, from a continuous stream of video and language instructions by combining a streaming autoregressive architecture with an ROI-enhanced memory layer that captures temporal context while focusing on salient hand-centric regions.
What carries the argument
Streaming autoregressive architecture combined with an ROI-enhanced memory layer for capturing temporal context in hand-centric regions.
If this is right
- Outperforms prior work by up to 35.8% in 3D hand forecasting tasks.
- Transfers learned representations to improve embodied manipulation task success rates by up to 13.4% on multiple benchmarks.
- Supports real-time applications in AR and assistive robotics by processing live video streams without future frames.
- Enables research through the introduction of the EgoHaFL dataset featuring synchronized 3D hand poses and language instructions.
Where Pith is reading between the lines
- Such streaming methods could reduce latency in interactive systems by avoiding batch processing of video.
- Integrating language instructions might enable more adaptive and intent-aware hand predictions in dynamic environments.
- The autoregressive nature suggests potential for long-term forecasting sequences if memory mechanisms scale appropriately.
Load-bearing premise
The approach relies on the ROI-enhanced memory layer and autoregressive design continuing to deliver accurate predictions in live streaming scenarios without any access to future video frames or offline post-processing.
What would settle it
Running the model on a live egocentric video feed in a real-time setting and measuring if forecasting accuracy drops significantly below offline baselines or fails to run at interactive speeds.
Figures





read the original abstract
Real-time 3D hand forecasting is a critical component for fluid human-computer interaction in applications like AR and assistive robotics. However, existing methods are ill-suited for these scenarios, as they typically require offline access to accumulated video sequences and cannot incorporate language guidance that conveys task intent. To overcome these limitations, we introduce SFHand, the first streaming framework for language-guided 3D hand forecasting. SFHand autoregressively predicts a comprehensive set of future 3D hand states, including hand type, 2D bounding box, 3D pose, and trajectory, from a continuous stream of video and language instructions. Our framework combines a streaming autoregressive architecture with an ROI-enhanced memory layer, capturing temporal context while focusing on salient hand-centric regions. To enable this research, we also introduce EgoHaFL, the first large-scale dataset featuring synchronized 3D hand poses and language instructions. We demonstrate that SFHand achieves new state-of-the-art results in 3D hand forecasting, outperforming prior work by a significant margin of up to 35.8%. Furthermore, we show the practical utility of our learned representations by transferring them to downstream embodied manipulation tasks, improving task success rates by up to 13.4% on multiple benchmarks. Dataset page: https://huggingface.co/datasets/ut-vision/EgoHaFL, project page: https://github.com/ut-vision/SFHand.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SFHand, the first streaming framework for language-guided 3D hand forecasting from egocentric video. SFHand employs an autoregressive architecture augmented by an ROI-enhanced memory layer to predict hand type, 2D bounding box, 3D pose, and trajectory from a continuous video stream and language instructions. The authors release the EgoHaFL dataset containing synchronized 3D hand poses and language annotations. They report new state-of-the-art forecasting performance with gains of up to 35.8% and demonstrate transfer to embodied manipulation tasks yielding up to 13.4% higher success rates.
Significance. If the streaming evaluation protocol is rigorously causal and the quantitative gains are reproducible under consistent metrics with proper controls, the work would advance real-time 3D hand forecasting for AR and robotics applications. The dataset release constitutes a concrete community contribution, and the downstream transfer results supply an external check on the utility of the learned representations.
major comments (3)
- [Evaluation] Evaluation section: The central streaming claim requires that test-time rollouts are strictly causal (frame-by-frame autoregressive inference using only past and current frames with forward-only memory state). The manuscript does not explicitly confirm this protocol or rule out batch/offline evaluation with future-frame access; without such confirmation the reported 35.8% forecasting margin cannot be taken as evidence for the streaming regime advertised in the motivation.
- [§4] §4 (Experiments) and Table 2: The paper reports large quantitative improvements but provides no error bars, statistical significance tests, or full ablation controls isolating the ROI-enhanced memory layer and language conditioning. These omissions make it difficult to assess whether the gains are robust or attributable to the proposed architecture.
- [Dataset] Dataset section: Construction details for EgoHaFL (annotation protocol, train/val/test splits, language instruction collection) are insufficiently described to allow independent verification or reproduction of the reported results.
minor comments (2)
- [Notation] Notation for the four predicted outputs (hand type, 2D bbox, 3D pose, trajectory) should be introduced once and used consistently in equations and figures.
- [Figures] Figure captions describing the streaming pipeline would benefit from explicit arrows or labels indicating causal information flow versus any non-causal components.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the streaming evaluation protocol, experimental reporting, and dataset documentation. We address each major comment below and have revised the manuscript to incorporate the suggested improvements for clarity and reproducibility.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The central streaming claim requires that test-time rollouts are strictly causal (frame-by-frame autoregressive inference using only past and current frames with forward-only memory state). The manuscript does not explicitly confirm this protocol or rule out batch/offline evaluation with future-frame access; without such confirmation the reported 35.8% forecasting margin cannot be taken as evidence for the streaming regime advertised in the motivation.
Authors: We agree that explicit confirmation of the causal protocol is essential. In the revised manuscript, we have added a new subsection in Section 4.1 detailing the streaming inference procedure, including confirmation that all test-time rollouts are strictly causal with frame-by-frame autoregressive prediction and forward-only memory state updates. We have also included pseudocode for the rollout process and a figure illustrating the causal data flow to rule out any future-frame access. revision: yes
-
Referee: [§4] §4 (Experiments) and Table 2: The paper reports large quantitative improvements but provides no error bars, statistical significance tests, or full ablation controls isolating the ROI-enhanced memory layer and language conditioning. These omissions make it difficult to assess whether the gains are robust or attributable to the proposed architecture.
Authors: We acknowledge that the original presentation lacked sufficient statistical controls. We have updated Table 2 to include error bars computed over five independent runs with different random seeds. Additional ablation experiments isolating the ROI-enhanced memory layer and language conditioning have been added to the supplementary material, along with paired t-test p-values comparing SFHand to baselines to assess statistical significance of the reported gains. revision: yes
-
Referee: [Dataset] Dataset section: Construction details for EgoHaFL (annotation protocol, train/val/test splits, language instruction collection) are insufficiently described to allow independent verification or reproduction of the reported results.
Authors: We thank the referee for pointing out the need for greater detail on reproducibility. Section 3 has been expanded with a full description of the annotation protocol, the crowdsourcing interface and quality control steps used for language instruction collection, the precise criteria and ratios for the train/val/test splits, and additional summary statistics. The complete annotation guidelines have also been added to the supplementary material and linked from the dataset page. revision: yes
Circularity Check
No circularity: empirical results on new dataset and architecture
full rationale
The paper introduces a new streaming autoregressive architecture (ROI-enhanced memory + decoder) and a new dataset (EgoHaFL) for language-guided 3D hand forecasting, then reports empirical SOTA gains (up to 35.8%) and downstream transfer improvements (up to 13.4%). No derivation chain, first-principles result, or prediction is shown to reduce by construction to its own inputs or fitted parameters; the claims rest on experimental comparison against prior methods on held-out data and external manipulation benchmarks, which constitute independent checks.
Axiom & Free-Parameter Ledger
free parameters (1)
- ROI memory size and attention window
axioms (1)
- domain assumption Language instructions provide sufficient task intent to condition future hand states
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SFHand autoregressively predicts ... from a continuous stream of video and language instructions. Our framework combines a streaming autoregressive architecture with an ROI-enhanced memory layer
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
ROI-enhanced memory layer ... fixed-size FIFO queue ... additive bias ... α·M
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
Perception or Prejudice: Can MLLMs Go Beyond First Impressions of Personality?
Introduces the Grounded Personality Reasoning task and MM-OCEAN dataset to show that MLLMs frequently produce correct Big Five personality ratings without grounding them in observable video evidence.
-
SocialDirector: Training-Free Social Interaction Control for Multi-Person Video Generation
SocialDirector uses spatiotemporal actor masking and directional reweighting on cross-attention maps to reduce actor-action mismatches and improve target-directed interactions in generated multi-person videos.
Reference graph
Works this paper leans on
-
[1]
Hierarq: Task-aware hierarchical q-former for enhanced video understanding
Shehreen Azad, Vibhav Vineet, and Yogesh Singh Rawat. Hierarq: Task-aware hierarchical q-former for enhanced video understanding. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 8545–8556,
-
[2]
Uncertainty-aware state space transformer for egocentric 3d hand trajectory forecasting
Wentao Bao, Lele Chen, Libing Zeng, Zhong Li, Yi Xu, Junsong Yuan, and Yu Kong. Uncertainty-aware state space transformer for egocentric 3d hand trajectory forecasting. In Proceedings of the IEEE/CVF international conference on computer vision, pages 13702–13711, 2023. 1, 2, 5, 6
work page 2023
-
[3]
Aydar Bulatov, Yury Kuratov, and Mikhail Burtsev. Recur- rent memory transformer.Advances in Neural Information Processing Systems, 35:11079–11091, 2022. 3
work page 2022
-
[4]
Kaylee Burns, Zach Witzel, Jubayer Ibn Hamid, Tianhe Yu, Chelsea Finn, and Karol Hausman. What makes pre-trained visual representations successful for robust manipulation? arXiv preprint arXiv:2312.12444, 2023. 3
-
[5]
Xiongyi Cai, Ri-Zhao Qiu, Geng Chen, Lai Wei, Isabella Liu, Tianshu Huang, Xuxin Cheng, and Xiaolong Wang. In- n-on: Scaling egocentric manipulation with in-the-wild and on-task data.arXiv preprint arXiv:2511.15704, 2025. 1
-
[6]
End-to- end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to- end object detection with transformers. InEuropean confer- ence on computer vision, pages 213–229. Springer, 2020. 3, 4
work page 2020
-
[7]
Hanzhi Chen, Boyang Sun, Anran Zhang, Marc Pollefeys, and Stefan Leutenegger. Vidbot: Learning generalizable 3d actions from in-the-wild 2d human videos for zero-shot robotic manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27661–27672,
-
[8]
Li Chen, Penghao Wu, Kashyap Chitta, Bernhard Jaeger, An- dreas Geiger, and Hongyang Li. End-to-end autonomous driving: Challenges and frontiers.IEEE Transactions on Pat- tern Analysis and Machine Intelligence, 2024. 3
work page 2024
-
[9]
Sirui Chen, Chen Wang, Kaden Nguyen, Li Fei-Fei, and C Karen Liu. Arcap: Collecting high-quality human demon- strations for robot learning with augmented reality feedback. In2025 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 8291–8298. IEEE, 2025. 1
work page 2025
-
[10]
Scaling egocentric vision: The epic-kitchens dataset
Dima Damen, Hazel Doughty, Giovanni Maria Farinella, Sanja Fidler, Antonino Furnari, Evangelos Kazakos, Davide Moltisanti, Jonathan Munro, Toby Perrett, Will Price, et al. Scaling egocentric vision: The epic-kitchens dataset. In Proceedings of the European conference on computer vision (ECCV), pages 720–736, 2018. 3
work page 2018
-
[11]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009. 3
work page 2009
-
[12]
Shangzhe Di, Zhelun Yu, Guanghao Zhang, Haoyuan Li, Tao Zhong, Hao Cheng, Bolin Li, Wanggui He, Fangxun Shu, and Hao Jiang. Streaming video question-answering with in-context video kv-cache retrieval.arXiv preprint arXiv:2503.00540, 2025. 3
-
[13]
Long-term recurrent convolutional net- works for visual recognition and description
Jeffrey Donahue, Lisa Anne Hendricks, Sergio Guadarrama, Marcus Rohrbach, Subhashini Venugopalan, Kate Saenko, and Trevor Darrell. Long-term recurrent convolutional net- works for visual recognition and description. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 2625–2634, 2015. 3
work page 2015
-
[14]
Tripad: Touch input in ar on ordinary surfaces with hand tracking only
Camille Dupr ´e, Caroline Appert, St ´ephanie Rey, Houssem Saidi, and Emmanuel Pietriga. Tripad: Touch input in ar on ordinary surfaces with hand tracking only. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–18, 2024. 1
work page 2024
-
[15]
Generalized procrustes analysis.Psychome- trika, 40(1):33–51, 1975
John C Gower. Generalized procrustes analysis.Psychome- trika, 40(1):33–51, 1975. 5
work page 1975
-
[16]
Ego4d: Around the world in 3,000 hours of egocentric video
Kristen Grauman, Andrew Westbury, Eugene Byrne, Zachary Chavis, Antonino Furnari, Rohit Girdhar, Jackson Hamburger, Hao Jiang, Miao Liu, Xingyu Liu, et al. Ego4d: Around the world in 3,000 hours of egocentric video. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 18995–19012, 2022. 3, 5
work page 2022
-
[17]
Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives
Kristen Grauman, Andrew Westbury, Lorenzo Torresani, Kris Kitani, Jitendra Malik, Triantafyllos Afouras, Kumar Ashutosh, Vijay Baiyya, Siddhant Bansal, Bikram Boote, et al. Ego-exo4d: Understanding skilled human activity from first-and third-person perspectives. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 193...
work page 2024
-
[18]
Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning
Abhishek Gupta, Vikash Kumar, Corey Lynch, Sergey Levine, and Karol Hausman. Relay policy learning: Solving long-horizon tasks via imitation and reinforcement learning. InConference on Robot Learning, pages 1025–1037. PMLR,
-
[19]
Nicklas Hansen, Zhecheng Yuan, Yanjie Ze, Tongzhou Mu, Aravind Rajeswaran, Hao Su, Huazhe Xu, and Xiao- long Wang. On pre-training for visuo-motor control: Re- visiting a learning-from-scratch baseline.arXiv preprint arXiv:2212.05749, 2022. 3
-
[20]
Emag: ego-motion aware and generalizable 2d hand forecasting from egocentric videos
Masashi Hatano, Ryo Hachiuma, and Hideo Saito. Emag: ego-motion aware and generalizable 2d hand forecasting from egocentric videos. InEuropean Conference on Com- puter Vision, pages 119–136. Springer, 2024. 2
work page 2024
-
[21]
Masashi Hatano, Zhifan Zhu, Hideo Saito, and Dima Damen. The invisible egohand: 3d hand forecasting through egobody pose estimation.arXiv preprint arXiv:2504.08654, 2025. 1, 2, 5, 6
-
[22]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016. 8
work page 2016
-
[23]
Egoexobench: A benchmark for first-and third-person view video understanding in mllms
Yuping He, Yifei Huang, Guo Chen, Baoqi Pei, Jilan Xu, Tong Lu, and Jiangmiao Pang. Egoexobench: A benchmark for first-and third-person view video understanding in mllms. arXiv preprint arXiv:2507.18342, 2025. 1
-
[24]
EgoDex: Learning Dexterous Manipulation from Large-Scale Egocentric Video
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapu- rapu, and Jian Zhang. Egodex: Learning dexterous manip- ulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[25]
Zhiming Hu, Zheming Yin, Daniel Haeufle, Syn Schmitt, and Andreas Bulling. Hoimotion: Forecasting human motion during human-object interactions using egocentric 3d object bounding boxes.IEEE Transactions on Visualization and Computer Graphics, 2024. 1
work page 2024
-
[26]
Predicting gaze in egocentric video by learning task- dependent attention transition
Yifei Huang, Minjie Cai, Zhenqiang Li, and Yoichi Sato. Predicting gaze in egocentric video by learning task- dependent attention transition. InECCV, 2018. 1, 3
work page 2018
-
[27]
Yifei Huang, Minjie Cai, Zhenqiang Li, Feng Lu, and Yoichi Sato. Mutual context network for jointly estimating egocen- tric gaze and action.IEEE Transactions on Image Process- ing, 29:7795–7806, 2020. 1
work page 2020
-
[28]
Improving action segmentation via graph-based temporal reasoning
Yifei Huang, Yusuke Sugano, and Yoichi Sato. Improving action segmentation via graph-based temporal reasoning. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 14024–14034, 2020. 3
work page 2020
-
[29]
Compound pro- totype matching for few-shot action recognition
Yifei Huang, Lijin Yang, and Yoichi Sato. Compound pro- totype matching for few-shot action recognition. InECCV,
-
[30]
Yifei Huang, Guo Chen, Jilan Xu, Mingfang Zhang, Li- jin Yang, Baoqi Pei, Hongjie Zhang, Lu Dong, Yali Wang, Limin Wang, et al. Egoexolearn: A dataset for bridging asyn- chronous ego-and exo-centric view of procedural activities in real world. InCVPR, pages 22072–22086, 2024. 3
work page 2024
-
[31]
Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yuping He, Guo Chen, Xinyuan Chen, Yaohui Wang, Zheng Nie, et al. Vinci: A real-time smart assistant based on egocentric vision-language model for portable devices.Pro- ceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies, 9(3):1–33, 2025. 1
work page 2025
-
[32]
Language-driven representation learning for robotics
Siddharth Karamcheti, Suraj Nair, Annie S Chen, Thomas Kollar, Chelsea Finn, Dorsa Sadigh, and Percy Liang. Language-driven representation learning for robotics. In Robotics: Science and Systems, 2023. 3, 5, 8
work page 2023
-
[33]
Simple but effective: Clip embed- dings for embodied ai
Apoorv Khandelwal, Luca Weihs, Roozbeh Mottaghi, and Aniruddha Kembhavi. Simple but effective: Clip embed- dings for embodied ai. InProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14829–14838, 2022. 3
work page 2022
-
[34]
Minsoo Kim, Kyuhong Shim, Jungwook Choi, and Simyung Chang. Infinipot-v: Memory-constrained kv cache com- pression for streaming video understanding.arXiv preprint arXiv:2506.15745, 2025. 3
-
[35]
The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97,
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97,
-
[36]
Handy ar: Markerless in- spection of augmented reality objects using fingertip track- ing
Taehee Lee and Tobias Hollerer. Handy ar: Markerless in- spection of augmented reality objects using fingertip track- ing. In2007 11th IEEE International Symposium on Wear- able Computers, pages 83–90. IEEE, 2007. 1
work page 2007
-
[37]
Online human action de- tection using joint classification-regression recurrent neural networks
Yanghao Li, Cuiling Lan, Junliang Xing, Wenjun Zeng, Chunfeng Yuan, and Jiaying Liu. Online human action de- tection using joint classification-regression recurrent neural networks. InEuropean conference on computer vision, pages 203–220. Springer, 2016. 3
work page 2016
-
[38]
Point cloud classification via learnable memory bank
Lisa Liu, William Y Wang, and Pingping Cai. Point cloud classification via learnable memory bank. InInterna- tional Conference on Multimedia Modeling, pages 216–229. Springer, 2024. 3
work page 2024
-
[39]
Miao Liu, Siyu Tang, Yin Li, and James M Rehg. Fore- casting human-object interaction: joint prediction of motor attention and actions in first person video. InEuropean con- ference on computer vision, pages 704–721. Springer, 2020. 2
work page 2020
-
[40]
Uvagaze: Unsupervised 1-to- 2 views adaptation for gaze estimation
Ruicong Liu and Feng Lu. Uvagaze: Unsupervised 1-to- 2 views adaptation for gaze estimation. InProceedings of the AAAI Conference on Artificial Intelligence, pages 3693– 3701, 2024. 1
work page 2024
-
[41]
Ruicong Liu, Yunfei Liu, Haofei Wang, and Feng Lu. Pnp- ga+: Plug-and-play domain adaptation for gaze estimation using model variants.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3707–3721, 2024. 1
work page 2024
-
[42]
Single-to-dual-view adaptation for egocentric 3d hand pose estimation
Ruicong Liu, Takehiko Ohkawa, Mingfang Zhang, and Yoichi Sato. Single-to-dual-view adaptation for egocentric 3d hand pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 677–686, 2024. 1
work page 2024
-
[43]
Ruicong Liu, Haofei Wang, and Feng Lu. From gaze jitter to domain adaptation: Generalizing gaze estimation by manip- ulating high-frequency components.International Journal of Computer Vision, 133(3):1290–1305, 2025. 1
work page 2025
-
[44]
Joint hand motion and interaction hotspots prediction from egocentric videos
Shaowei Liu, Subarna Tripathi, Somdeb Majumdar, and Xi- aolong Wang. Joint hand motion and interaction hotspots prediction from egocentric videos. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3282–3292, 2022. 2
work page 2022
-
[45]
Goal-oriented gaze estimation for zero-shot learning
Yang Liu, Lei Zhou, Xiao Bai, Yifei Huang, Lin Gu, Jun Zhou, and Tatsuya Harada. Goal-oriented gaze estimation for zero-shot learning. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 3794–3803, 2021. 4
work page 2021
-
[46]
Yumeng Liu, Yaxun Yang, Youzhuo Wang, Xiaofei Wu, Ji- amin Wang, Yichen Yao, S ¨oren Schwertfeger, Sibei Yang, Wenping Wang, Jingyi Yu, et al. Realdex: Towards human- like grasping for robotic dexterous hand.arXiv preprint arXiv:2402.13853, 2024. 1
-
[47]
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: vision-language-action pre- training from large-scale human videos.arXiv preprint arXiv:2507.15597, 2025. 1
-
[48]
Junyi Ma, Xieyuanli Chen, Wentao Bao, Jingyi Xu, and Hes- heng Wang. Madiff: Motion-aware mamba diffusion models for hand trajectory prediction on egocentric videos.arXiv preprint arXiv:2409.02638, 2024. 2
-
[49]
Junyi Ma, Jingyi Xu, Xieyuanli Chen, and Hesheng Wang. Diff-ip2d: Diffusion-based hand-object interaction predic- tion on egocentric videos.arXiv preprint arXiv:2405.04370,
-
[50]
VIP: Towards Universal Visual Reward and Representation via Value-Implicit Pre-Training
Yecheng Jason Ma, Shagun Sodhani, Dinesh Jayaraman, Os- bert Bastani, Vikash Kumar, and Amy Zhang. Vip: Towards universal visual reward and representation via value-implicit pre-training.arXiv preprint arXiv:2210.00030, 2022. 3
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[51]
Liv: Language-image represen- tations and rewards for robotic control
Yecheng Jason Ma, Vikash Kumar, Amy Zhang, Osbert Bas- tani, and Dinesh Jayaraman. Liv: Language-image represen- tations and rewards for robotic control. InInternational Con- ference on Machine Learning, pages 23301–23320. PMLR,
-
[52]
R3m: A universal visual repre- sentation for robot manipulation
Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. R3m: A universal visual repre- sentation for robot manipulation. InConference on Robot Learning, pages 892–909. PMLR, 2023. 3, 5, 8
work page 2023
-
[53]
Pha Nguyen, Sailik Sengupta, Girik Malik, Arshit Gupta, and Bonan Min. Install: Context-aware instructional task assistance with multi-modal large language models.arXiv preprint arXiv:2501.12231, 2025. 1
-
[54]
Actionvos: Actions as prompts for video object segmentation
Liangyang Ouyang, Ruicong Liu, Yifei Huang, Ryosuke Furuta, and Yoichi Sato. Actionvos: Actions as prompts for video object segmentation. InEuropean Conference on Computer Vision, pages 216–235. Springer, 2024. 1
work page 2024
-
[55]
The unsurprising effectiveness of pre- trained vision models for control
Simone Parisi, Aravind Rajeswaran, Senthil Purushwalkam, and Abhinav Gupta. The unsurprising effectiveness of pre- trained vision models for control. Ininternational con- ference on machine learning, pages 17359–17371. PMLR,
-
[56]
Recon- structing hands in 3d with transformers
Georgios Pavlakos, Dandan Shan, Ilija Radosavovic, Angjoo Kanazawa, David Fouhey, and Jitendra Malik. Recon- structing hands in 3d with transformers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9826–9836, 2024. 5, 6, 7
work page 2024
-
[57]
Modeling fine-grained hand-object dynamics for egocentric video representation learning
Baoqi Pei, Yifei Huang, Jilan Xu, Guo Chen, Yuping He, Lijin Yang, Yali Wang, Weidi Xie, Yu Qiao, Fei Wu, et al. Modeling fine-grained hand-object dynamics for egocentric video representation learning. InInternational Conference on Learning Representations, 2025. 4, 5
work page 2025
-
[58]
Baoqi Pei, Yifei Huang, Jilan Xu, Yuping He, Guo Chen, Fei Wu, Yu Qiao, and Jiangmiao Pang. Egothinker: Un- veiling egocentric reasoning with spatio-temporal cot.arXiv preprint arXiv:2510.23569, 2025. 1
-
[59]
Hand interfaces: Using hands to imitate objects in ar/vr for expressive interactions
Siyou Pei, Alexander Chen, Jaewook Lee, and Yang Zhang. Hand interfaces: Using hands to imitate objects in ar/vr for expressive interactions. InProceedings of the 2022 CHI con- ference on human factors in computing systems, pages 1–16,
work page 2022
-
[60]
Rui Qian, Xiaoyi Dong, Pan Zhang, Yuhang Zang, Shuan- grui Ding, Dahua Lin, and Jiaqi Wang. Streaming long video understanding with large language models.Advances in Neu- ral Information Processing Systems, 37:119336–119360,
-
[61]
Xun Qian, Fengming He, Xiyun Hu, Tianyi Wang, and Karthik Ramani. Arnnotate: An augmented reality inter- face for collecting custom dataset of 3d hand-object inter- action pose estimation. InProceedings of the 35th Annual ACM Symposium on User Interface Software and Technol- ogy, pages 1–14, 2022. 1
work page 2022
-
[62]
Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsu- pervised multitask learners.OpenAI blog, 1(8):9, 2019. 4
work page 2019
-
[63]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 3, 5, 8
work page 2021
-
[64]
Real-world robot learn- ing with masked visual pre-training
Ilija Radosavovic, Tete Xiao, Stephen James, Pieter Abbeel, Jitendra Malik, and Trevor Darrell. Real-world robot learn- ing with masked visual pre-training. InConference on Robot Learning, pages 416–426. PMLR, 2023. 3, 5, 8
work page 2023
-
[65]
Learning complex dexterous manipulation with deep reinforcement learning and demonstrations
Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giu- lia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. Learning complex dexterous manipulation with deep reinforcement learning and demonstrations. InRobotics: Science and Systems, 2018. 2, 5
work page 2018
-
[66]
Generalized in- tersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized in- tersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666,
-
[67]
Em- bodied hands: Modeling and capturing hands and bodies to- gether
Javier Romero, Dimitrios Tzionas, and Michael J Black. Em- bodied hands: Modeling and capturing hands and bodies to- gether.arXiv preprint arXiv:2201.02610, 2022. 3, 5
-
[68]
Neu- ral machine translation of rare words with subword units
Rico Sennrich, Barry Haddow, and Alexandra Birch. Neu- ral machine translation of rare words with subword units. InProceedings of the 54th Annual Meeting of the Associa- tion for Computational Linguistics (Volume 1: Long Papers), pages 1715–1725, 2016. 5
work page 2016
-
[69]
Time-contrastive networks: Self-supervised learn- ing from video
Pierre Sermanet, Corey Lynch, Yevgen Chebotar, Jasmine Hsu, Eric Jang, Stefan Schaal, Sergey Levine, and Google Brain. Time-contrastive networks: Self-supervised learn- ing from video. In2018 IEEE international conference on robotics and automation (ICRA), pages 1134–1141. IEEE,
-
[70]
Online detection of action start in untrimmed, streaming videos
Zheng Shou, Junting Pan, Jonathan Chan, Kazuyuki Miyazawa, Hassan Mansour, Anthony Vetro, Xavier Giro-i Nieto, and Shih-Fu Chang. Online detection of action start in untrimmed, streaming videos. InProceedings of the Eu- ropean conference on computer vision (ECCV), pages 534– 551, 2018. 3
work page 2018
-
[71]
Cliport: What and where pathways for robotic manipulation
Mohit Shridhar, Lucas Manuelli, and Dieter Fox. Cliport: What and where pathways for robotic manipulation. InCon- ference on robot learning, pages 894–906. PMLR, 2022. 3
work page 2022
-
[72]
Oadtr: Online action detection with transformers
Xiang Wang, Shiwei Zhang, Zhiwu Qing, Yuanjie Shao, Zhengrong Zuo, Changxin Gao, and Nong Sang. Oadtr: Online action detection with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vi- sion, pages 7565–7575, 2021. 3
work page 2021
-
[73]
Xiaofeng Wang, Kang Zhao, Feng Liu, Jiayu Wang, Gu- osheng Zhao, Xiaoyi Bao, Zheng Zhu, Yingya Zhang, and Xingang Wang. Egovid-5m: A large-scale video-action dataset for egocentric video generation.arXiv preprint arXiv:2411.08380, 2024. 5
-
[74]
Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition
Chao-Yuan Wu, Yanghao Li, Karttikeya Mangalam, Haoqi Fan, Bo Xiong, Jitendra Malik, and Christoph Feichtenhofer. Memvit: Memory-augmented multiscale vision transformer for efficient long-term video recognition. InProceedings of the ieee/cvf conference on computer vision and pattern recognition, pages 13587–13597, 2022. 3
work page 2022
-
[75]
Penghao Wu, Li Chen, Hongyang Li, Xiaosong Jia, Junchi Yan, and Yu Qiao. Policy pre-training for autonomous driv- ing via self-supervised geometric modeling.arXiv preprint arXiv:2301.01006, 2023. 3
-
[76]
Yaozheng Xia, Zaiping Zhu, Bo Pang, Shaorong Wang, and Sheng Li. Timegazer: Temporal modeling of predic- tive gaze stabilization for ar interaction.arXiv preprint arXiv:2510.01561, 2025. 1
-
[77]
Jilan Xu, Yifei Huang, Baoqi Pei, Junlin Hou, Qingqiu Li, Guo Chen, Yuejie Zhang, Rui Feng, and Weidi Xie. Egoexo- gen: Ego-centric video prediction by watching exo-centric videos.arXiv preprint arXiv:2504.11732, 2025. 1
-
[78]
Temporal recurrent networks for online action detection
Mingze Xu, Mingfei Gao, Yi-Ting Chen, Larry S Davis, and David J Crandall. Temporal recurrent networks for online action detection. InProceedings of the IEEE/CVF inter- national conference on computer vision, pages 5532–5541,
-
[79]
Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition
Lijin Yang, Yifei Huang, Yusuke Sugano, and Yoichi Sato. Interact before align: Leveraging cross-modal knowledge for domain adaptive action recognition. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14722–14732, 2022. 3
work page 2022
-
[80]
Lijin Yang, Quan Kong, Hsuan-Kung Yang, Wadim Kehl, Yoichi Sato, and Norimasa Kobori. Deco: Decomposi- tion and reconstruction for compositional temporal ground- ing via coarse-to-fine contrastive ranking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 23130–23140, 2023. 3
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.