ToolFG: Towards Well-Grounded Fine-Grained Image Classification
Pith reviewed 2026-06-28 14:50 UTC · model grok-4.3
The pith
ToolFG equips MLLMs with external tools to collect verifiable visual evidence for distinguishing similar image categories.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
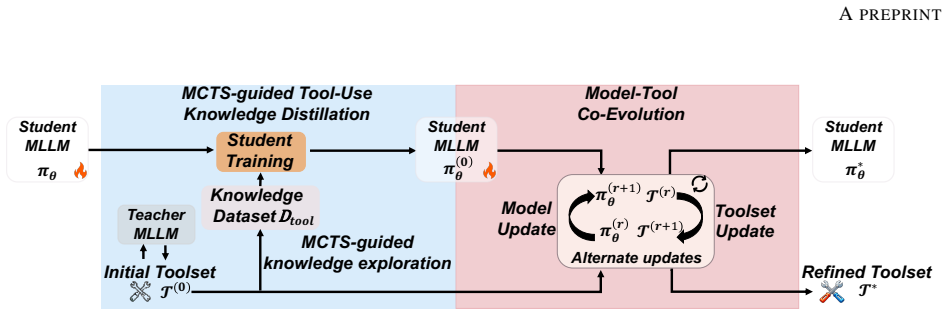
ToolFG enables MLLMs to autonomously and flexibly use external tools during the reasoning process, actively interact with images, and collect verifiable visual cues for distinguishing highly similar categories in a more reliable and well-grounded manner, achieved through MCTS-guided tool-use knowledge distillation from proprietary MLLMs and a model-tool co-evolution mechanism that jointly refines the toolset and policy.
What carries the argument
MCTS-guided tool-use knowledge distillation mechanism that mines tool-use and FGIC knowledge from proprietary MLLMs, paired with a model-tool co-evolution mechanism that adapts both components to FGIC.
If this is right
- Classifications become supported by explicit, inspectable visual interactions rather than internal model guesses alone.
- Open-source MLLMs can acquire tool-use capabilities previously limited to proprietary systems for this task.
- The toolset and model policy converge on FGIC-specific adaptations that improve handling of fine visual distinctions.
- Reasoning traces include verifiable cues that can be checked against the image content.
Where Pith is reading between the lines
- The same tool-interaction pattern could be applied to other vision tasks that require precise localization or measurement, such as medical image analysis.
- If tool outputs are logged, they provide an audit trail that could help debug or explain model decisions on ambiguous cases.
- Extending the co-evolution loop to include new tool types might further specialize the system beyond the initial toolset.
Load-bearing premise
The MCTS-guided distillation successfully transfers effective tool-use strategies from proprietary models to an open model that can then improve via co-evolution.
What would settle it
Training an open MLLM with the described distillation and co-evolution process yields no accuracy gain on standard FGIC benchmarks relative to the same model without tool integration.
Figures

read the original abstract
Fine-grained image classification (FGIC) has broad applications and has attracted significant research attention. In this paper, we explore a novel paradigm for solving FGIC by proposing \textbf{ToolFG}, the first tool-integrated MLLM-based framework tailored to FGIC. ToolFG enables MLLMs to autonomously and flexibly use external tools during the reasoning process, actively interact with images, and collect verifiable visual cues for distinguishing highly similar categories in a more \textit{reliable} and \textit{well-grounded} manner. To equip the model with such tool-use ability, we design a novel \textbf{MCTS-guided tool-use knowledge distillation mechanism}, which effectively mines tool-use- and FGIC-relevant knowledge from advanced proprietary MLLMs for model training. Furthermore, we propose a \textbf{model-tool co-evolution mechanism} that jointly refines the toolset and the model's tool-use policy, driving them toward a mutually adapted and FGIC-specialized state. Extensive experiments demonstrate the effectiveness of our framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ToolFG, the first tool-integrated MLLM-based framework for fine-grained image classification (FGIC). It introduces an MCTS-guided tool-use knowledge distillation mechanism to transfer tool-use and FGIC-relevant knowledge from proprietary MLLMs, along with a model-tool co-evolution mechanism that jointly refines the toolset and the model's tool-use policy. The framework claims to enable autonomous and flexible tool use during reasoning to collect verifiable visual cues, improving reliability for distinguishing highly similar categories. Extensive experiments are stated to demonstrate effectiveness.
Significance. If the distillation and co-evolution mechanisms function as described and yield measurable gains, ToolFG could advance FGIC by addressing grounding limitations in MLLMs through explicit tool integration and iterative adaptation. This approach has potential value in domains requiring precise visual distinctions, such as biodiversity monitoring or medical diagnostics, provided the claimed autonomy and verifiability are empirically validated.
major comments (1)
- [Abstract] Abstract (and overall manuscript as provided): The central claim that the framework enables 'more reliable and well-grounded' FGIC via tool use rests on the MCTS-guided distillation and co-evolution mechanisms, yet the text provides no equations, algorithmic details, quantitative results, baselines, or ablation studies. Without these, it is not possible to assess whether the mechanisms support the claims or reduce to effective transfer.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the opportunity to clarify aspects of our work. The concern raised focuses on the absence of technical specifics in the provided text; we address this directly below by pointing to the corresponding content in the full manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract (and overall manuscript as provided): The central claim that the framework enables 'more reliable and well-grounded' FGIC via tool use rests on the MCTS-guided distillation and co-evolution mechanisms, yet the text provides no equations, algorithmic details, quantitative results, baselines, or ablation studies. Without these, it is not possible to assess whether the mechanisms support the claims or reduce to effective transfer.
Authors: The full manuscript contains dedicated sections that supply the requested elements. Section 3.2 details the MCTS-guided tool-use knowledge distillation with the search tree formulation, reward function, and distillation loss equations. Section 3.3 presents the model-tool co-evolution algorithm, including the joint optimization objective and iterative update rules. Section 4 reports quantitative results across multiple FGIC benchmarks (e.g., CUB-200, Stanford Cars), direct comparisons to strong baselines including proprietary MLLMs and prior FGIC methods, and ablation studies isolating the contribution of the distillation and co-evolution components. These elements are what underpin the reliability claims; the abstract is intentionally concise and does not substitute for the technical body of the paper. revision: no
Circularity Check
No significant circularity detected
full rationale
The paper presents ToolFG as a descriptive framework consisting of an MCTS-guided knowledge distillation step and a model-tool co-evolution loop. No equations, parameter-fitting procedures, or derivation chains appear in the provided text. The central claims are architectural and procedural rather than mathematical reductions; success is evaluated via external experiments rather than by construction from fitted inputs or self-citations. The method is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report.ar...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Visual recognition with humans in the loop
Steve Branson, Catherine Wah, Florian Schroff, Boris Babenko, Peter Welinder, Pietro Perona, and Serge Belongie. Visual recognition with humans in the loop. InEuropean Conference on Computer Vision, pages 438–451. Springer, 2010
2010
-
[3]
SFT or RL? An Early Investigation into Training R1-Like Reasoning Large Vision-Language Models
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. Sft or rl? an early investigation into training r1-like reasoning large vision-language models.arXiv preprint arXiv:2504.11468, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Destruction and construction learning for fine-grained image recognition
Yue Chen, Yalong Bai, Wei Zhang, and Tao Mei. Destruction and construction learning for fine-grained image recognition. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5157–5166, 2019
2019
-
[5]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Efficient selectivity and backup operators in monte-carlo tree search
Rémi Coulom. Efficient selectivity and backup operators in monte-carlo tree search. InInternational conference on computers and games, pages 72–83. Springer, 2006
2006
-
[7]
Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning,
Guanting Dong, Yifei Chen, Xiaoxi Li, Jiajie Jin, Hongjin Qian, Yutao Zhu, Hangyu Mao, Guorui Zhou, Zhicheng Dou, and Ji-Rong Wen. Tool-star: Empowering llm-brained multi-tool reasoner via reinforcement learning.arXiv preprint arXiv:2505.16410, 2025
-
[8]
Fine- grained visual classification via progressive multi-granularity training of jigsaw patches
Ruoyi Du, Dongliang Chang, Ayan Kumar Bhunia, Jiyang Xie, Zhanyu Ma, Yi-Zhe Song, and Jun Guo. Fine- grained visual classification via progressive multi-granularity training of jigsaw patches. InEuropean conference on computer vision, pages 153–168. Springer, 2020
2020
-
[9]
Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition
Jianlong Fu, Heliang Zheng, and Tao Mei. Look closer to see better: Recurrent attention convolutional neural network for fine-grained image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 4438–4446, 2017
2017
-
[10]
Channel interaction networks for fine- grained image categorization
Yu Gao, Xintong Han, Xun Wang, Weilin Huang, and Matthew Scott. Channel interaction networks for fine- grained image categorization. InProceedings of the AAAI conference on artificial intelligence, volume 34, pages 10818–10825, 2020. 9 APREPRINT
2020
-
[11]
Code generation with large language models: a survey from neural program synthesis to autonomous software development.Applied Intelligence, 56(6):200, 2026
Burak Gülmez. Code generation with large language models: a survey from neural program synthesis to autonomous software development.Applied Intelligence, 56(6):200, 2026
2026
-
[12]
Fine-r1: Make multi-modal LLMs excel in fine-grained visual recog- nition by chain-of-thought reasoning
Hulingxiao He, Zijun Geng, and Yuxin Peng. Fine-r1: Make multi-modal LLMs excel in fine-grained visual recog- nition by chain-of-thought reasoning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[13]
Analyzing and boosting the power of fine- grained visual recognition for multi-modal large language models
Hulingxiao He, Geng Li, Zijun Geng, Jinglin Xu, and Yuxin Peng. Analyzing and boosting the power of fine- grained visual recognition for multi-modal large language models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[14]
Hulingxiao He, Zhi Tan, and Yuxin Peng. Taxonomy-aware representation alignment for hierarchical visual recognition with large multimodal models.arXiv preprint arXiv:2603.00431, 2026
-
[15]
Transfg: A transformer architecture for fine-grained recognition
Ju He, Jie-Neng Chen, Shuai Liu, Adam Kortylewski, Cheng Yang, Yutong Bai, and Changhu Wang. Transfg: A transformer architecture for fine-grained recognition. InProceedings of the AAAI conference on artificial intelligence, volume 36, pages 852–860, 2022
2022
-
[16]
Fine-grained image classification via combining vision and language
Xiangteng He and Yuxin Peng. Fine-grained image classification via combining vision and language. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 5994–6002, 2017
2017
-
[17]
Fine-grained visual-textual representation learning.IEEE Transactions on Circuits and Systems for Video Technology, 30(2):520–531, 2019
Xiangteng He and Yuxin Peng. Fine-grained visual-textual representation learning.IEEE Transactions on Circuits and Systems for Video Technology, 30(2):520–531, 2019
2019
-
[18]
In Defense of the Triplet Loss for Person Re-Identification
Alexander Hermans, Lucas Beyer, and Bastian Leibe. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Unlabeled data improves fine-grained image zero-shot classification with multimodal LLMs
Yunqi Hong, Sohyun An, Andrew Bai, Neil Lin, and Cho-Jui Hsieh. Unlabeled data improves fine-grained image zero-shot classification with multimodal LLMs. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[20]
Vision- r1: Incentivizing reasoning capability in multimodal large language models
Wenxuan Huang, Bohan Jia, Shaosheng Cao, Zheyu Ye, Fei zhao, Zhe Xu, Yao Hu, and Shaohui Lin. Vision- r1: Incentivizing reasoning capability in multimodal large language models. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[21]
A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. A survey on large language models for code generation.ACM Transactions on Software Engineering and Methodology, 35(2):1–72, 2026
2026
-
[22]
Fine-grained vehicle type detection and recognition based on dense attention network
Xiao Ke and Yufeng Zhang. Fine-grained vehicle type detection and recognition based on dense attention network. Neurocomputing, 399:247–257, 2020
2020
-
[23]
A survey of advances in vision-based vehicle re-identification.Computer Vision and Image Understanding, 182:50–63, 2019
Sultan Daud Khan and Habib Ullah. A survey of advances in vision-based vehicle re-identification.Computer Vision and Image Understanding, 182:50–63, 2019
2019
-
[24]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19113–19122, 2023
2023
-
[25]
Self-regulating prompts: Foundational model adaptation without forgetting
Muhammad Uzair Khattak, Syed Talal Wasim, Muzammal Naseer, Salman Khan, Ming-Hsuan Yang, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adaptation without forgetting. InProceedings of the IEEE/CVF international conference on computer vision, pages 15190–15200, 2023
2023
-
[26]
Finer: Investigating and enhancing fine-grained visual concept recognition in large vision language models
Jeonghwan Kim and Heng Ji. Finer: Investigating and enhancing fine-grained visual concept recognition in large vision language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 6187–6207, 2024
2024
-
[27]
Bandit based monte-carlo planning
Levente Kocsis and Csaba Szepesvári. Bandit based monte-carlo planning. InEuropean conference on machine learning, pages 282–293. Springer, 2006
2006
-
[28]
3d object representations for fine-grained categorization
Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. InProceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013
2013
-
[29]
DiVE-k: DIFFERENTIAL VISUAL REASONING FOR FINE- GRAINED IMAGE RECOGNITION
Raja Kumar, Arka Sadhu, and Ram Nevatia. DiVE-k: DIFFERENTIAL VISUAL REASONING FOR FINE- GRAINED IMAGE RECOGNITION. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[30]
Lisa: Reasoning segmentation via large language model
Xin Lai, Zhuotao Tian, Yukang Chen, Yanwei Li, Yuhui Yuan, Shu Liu, and Jiaya Jia. Lisa: Reasoning segmentation via large language model. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9579–9589, 2024
2024
-
[31]
Zhuoling Li, Jiarui Zhang, Ping Hu, Jason Kuen, Jiuxiang Gu, Hossein Rahmani, and Jun Liu. Automatic method illustration generation for ai scientific papers via drawing middleware creation, evolution, and orchestration.arXiv preprint arXiv:2603.29590, 2026. 10 APREPRINT
-
[32]
Bilinear cnn models for fine-grained visual recognition
Tsung-Yu Lin, Aruni RoyChowdhury, and Subhransu Maji. Bilinear cnn models for fine-grained visual recognition. InProceedings of the IEEE international conference on computer vision, pages 1449–1457, 2015
2015
-
[33]
Visual-rft: Visual reinforcement fine-tuning
Ziyu Liu, Zeyi Sun, Yuhang Zang, Xiaoyi Dong, Yuhang Cao, Haodong Duan, Dahua Lin, and Jiaqi Wang. Visual-rft: Visual reinforcement fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2034–2044, 2025
2034
-
[34]
Cross-x learning for fine-grained visual categorization
Wei Luo, Xitong Yang, Xianjie Mo, Yuheng Lu, Larry S Davis, Jun Li, Jian Yang, and Ser-Nam Lim. Cross-x learning for fine-grained visual categorization. InProceedings of the IEEE/CVF international conference on computer vision, pages 8242–8251, 2019
2019
-
[35]
Automated creation of reusable and diverse toolsets for enhancing llm reasoning
Zhiyuan Ma, Zhenya Huang, Jiayu Liu, Minmao Wang, Hongke Zhao, and Xin Li. Automated creation of reusable and diverse toolsets for enhancing llm reasoning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24821–24830, 2025
2025
-
[36]
Fine-Grained Visual Classification of Aircraft
Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classifica- tion of aircraft.arXiv preprint arXiv:1306.5151, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[37]
Compositional chain-of-thought prompting for large multimodal models
Chancharik Mitra, Brandon Huang, Trevor Darrell, and Roei Herzig. Compositional chain-of-thought prompting for large multimodal models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14420–14431, 2024
2024
-
[38]
Automated flower classification over a large number of classes
Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In 2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008
2008
-
[39]
Cats and dogs
Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012
2012
-
[40]
Object-part attention model for fine-grained image classification
Yuxin Peng, Xiangteng He, and Junjie Zhao. Object-part attention model for fine-grained image classification. IEEE Transactions on Image Processing, 27(3):1487–1500, 2017
2017
-
[41]
Detgpt: Detect what you need via reasoning
Renjie Pi, Jiahui Gao, Shizhe Diao, Rui Pan, Hanze Dong, Jipeng Zhang, Lewei Yao, Jianhua Han, Hang Xu, Lingpeng Kong, et al. Detgpt: Detect what you need via reasoning. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 14172–14189, 2023
2023
-
[42]
Counterfactual attention learning for fine-grained visual categorization and re-identification
Yongming Rao, Guangyi Chen, Jiwen Lu, and Jie Zhou. Counterfactual attention learning for fine-grained visual categorization and re-identification. InProceedings of the IEEE/CVF international conference on computer vision, pages 1025–1034, 2021
2021
-
[43]
Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal language models with a comprehensive dataset and benchmark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642, 2024
2024
-
[44]
Sim-trans: Structure information modeling transformer for fine- grained visual categorization
Hongbo Sun, Xiangteng He, and Yuxin Peng. Sim-trans: Structure information modeling transformer for fine- grained visual categorization. InProceedings of the 30th ACM international conference on multimedia, pages 5853–5861, 2022
2022
-
[45]
Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection
Grant Van Horn, Steve Branson, Ryan Farrell, Scott Haber, Jessie Barry, Panos Ipeirotis, Pietro Perona, and Serge Belongie. Building a bird recognition app and large scale dataset with citizen scientists: The fine print in fine-grained dataset collection. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 595–604, 2015
2015
-
[46]
Benchmarking representation learning for natural world image collections
Grant Van Horn, Elijah Cole, Sara Beery, Kimberly Wilber, Serge Belongie, and Oisin Mac Aodha. Benchmarking representation learning for natural world image collections. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12884–12893, 2021
2021
-
[47]
Multiclass recognition and part localization with humans in the loop
Catherine Wah, Steve Branson, Pietro Perona, and Serge Belongie. Multiclass recognition and part localization with humans in the loop. In2011 International Conference on Computer Vision, pages 2524–2531. IEEE, 2011
2011
-
[48]
The caltech-ucsd birds-200- 2011 dataset
Catherine Wah, Steve Branson, Peter Welinder, Pietro Perona, and Serge Belongie. The caltech-ucsd birds-200- 2011 dataset. 2011
2011
-
[49]
Fine-grained image analysis with deep learning: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(12):8927–8948, 2021
Xiu-Shen Wei, Yi-Zhe Song, Oisin Mac Aodha, Jianxin Wu, Yuxin Peng, Jinhui Tang, Jian Yang, and Serge Belongie. Fine-grained image analysis with deep learning: A survey.IEEE transactions on pattern analysis and machine intelligence, 44(12):8927–8948, 2021
2021
-
[50]
The emperor’s new reasoning: Format imitation overshadows genuine mathematical understanding in sft
Linyao Yang, Jian-Tao Huang, Yafei Lu, Zhenhui Jessie Li, and Guirong Xue. The emperor’s new reasoning: Format imitation overshadows genuine mathematical understanding in sft. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21098–21111, 2025. 11 APREPRINT
2025
-
[51]
Tooltree: Efficient llm tool planning via dual-feedback monte carlo tree search and bidirectional pruning
Shuo Yang, Caren Han, Yihao Ding, Shuhe Wang, and Eduard Hovy. Tooltree: Efficient llm tool planning via dual-feedback monte carlo tree search and bidirectional pruning. InThe Fourteenth International Conference on Learning Representations, 2026
2026
-
[52]
Learning to navigate for fine-grained classification
Ze Yang, Tiange Luo, Dong Wang, Zhiqiang Hu, Jun Gao, and Liwei Wang. Learning to navigate for fine-grained classification. InProceedings of the European conference on computer vision (ECCV), pages 420–435, 2018
2018
-
[53]
Hierarchical bilinear pooling for fine-grained visual recognition
Chaojian Yu, Xinyi Zhao, Qi Zheng, Peng Zhang, and Xinge You. Hierarchical bilinear pooling for fine-grained visual recognition. InProceedings of the European conference on computer vision (ECCV), pages 574–589, 2018
2018
-
[54]
Video-STAR: Reinforcing Open-Vocabulary Action Recognition with Tools
Zhenlong Yuan, Xiangyan Qu, Chengxuan Qian, Rui Chen, Jing Tang, Lei Sun, Xiangxiang Chu, Dapeng Zhang, Yiwei Wang, Yujun Cai, et al. Video-star: Reinforcing open-vocabulary action recognition with tools.arXiv preprint arXiv:2510.08480, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Part-based r-cnns for fine-grained category detection
Ning Zhang, Jeff Donahue, Ross Girshick, and Trevor Darrell. Part-based r-cnns for fine-grained category detection. InEuropean conference on computer vision, pages 834–849. Springer, 2014
2014
-
[56]
MA VIS: Mathematical visual instruction tuning with an automatic data engine
Renrui Zhang, Xinyu Wei, Dongzhi Jiang, Ziyu Guo, Yichi Zhang, Chengzhuo Tong, Jiaming Liu, Aojun Zhou, Shanghang Zhang, Peng Gao, and Hongsheng Li. MA VIS: Mathematical visual instruction tuning with an automatic data engine. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[57]
Picking deep filter responses for fine-grained image recognition
Xiaopeng Zhang, Hongkai Xiong, Wengang Zhou, Weiyao Lin, and Qi Tian. Picking deep filter responses for fine-grained image recognition. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 1134–1142, 2016
2016
-
[58]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[59]
Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.Advances in Neural Information Processing Systems, 36:5168–5191, 2023
Ge Zheng, Bin Yang, Jiajin Tang, Hong-Yu Zhou, and Sibei Yang. Ddcot: Duty-distinct chain-of-thought prompting for multimodal reasoning in language models.Advances in Neural Information Processing Systems, 36:5168–5191, 2023
2023
-
[60]
Learning attentive pairwise interaction for fine-grained classification
Peiqin Zhuang, Yali Wang, and Yu Qiao. Learning attentive pairwise interaction for fine-grained classification. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 13130–13137, 2020. 12
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.