Prompt Governance? On Governing Technologies Governed by Natural Language
Pith reviewed 2026-07-01 08:14 UTC · model grok-4.3
The pith
Divergent claims in research about what system prompts can achieve complicate their use as stable governance tools in AI policy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
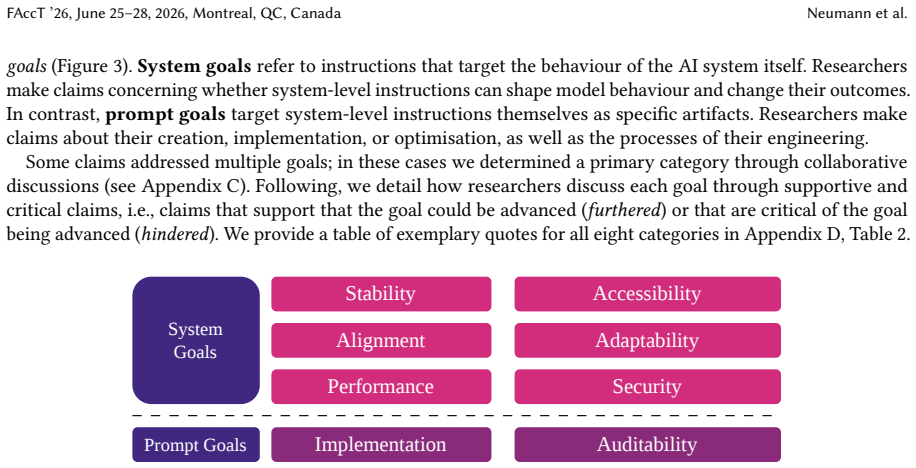
The literature on system-level instructions advances varying and contradictory claims about what goals those instructions can achieve; these claims are distilled into a typology. Policy frameworks position the same instructions as stable, interpretable control mechanisms. The resulting misalignments indicate that prompt governance approaches require careful consideration before they can reliably support regulatory objectives.
What carries the argument
Typology of claims drawn from the literature on system-level instructions, used to surface divergences from policy assumptions that treat prompts as behavioral controls.
If this is right
- Policy frameworks that rely on system prompts to enforce constraints or compliance may encounter unpredictable outcomes across different contexts.
- Natural language instructions cannot be assumed to function reliably enough to serve as primary intervention points for governing generative AI.
- The viability of using prompts for governance must be examined before extending such approaches to other technical systems controlled by natural language.
- Misalignments between research claims and policy positions call for closer inspection of prompt-based regulatory strategies.
Where Pith is reading between the lines
- Empirical measurements of prompt consistency across multiple models and prompt variations could test the typology's categories.
- Similar governance challenges may appear wherever natural language serves as the interface for directing complex technical systems.
- Regulators might need to develop supplementary oversight methods that do not depend on textual instructions.
Load-bearing premise
The selected literature and the two examined policy frameworks capture enough of the relevant researcher and policymaker perspectives to support conclusions about misalignments.
What would settle it
A broader review that finds largely consistent rather than contradictory claims across the literature on system prompt capabilities would weaken the case for misalignment with policy approaches.
Figures


read the original abstract
Generative artificial intelligence (GenAI) is increasingly operated by natural language instructions (prompts). Across the pipeline, stakeholders designate various forms, e.g. end-user guidelines, developer specifications, or system prompts, as prompt governance instruments. These textual artifacts are intended to shape model behaviour by specifying constraints, priorities, and compliance rules. Policymakers and regulators have begun to treat system-level instructions as accessible prompt-based GenAI intervention points, assuming they function (directly or indirectly) as behavioural control. Yet whether these instructions operate reliably and predictably enough across contexts to support such governance frameworks remains underexplored. Towards this, we systematically evaluate (i) how researchers discuss and treat system-level instructions in the literature, focusing on large language models (LLMs) as they isolate language effects; (ii) how policymakers position system-level instructions as governance objects, incorporating analysis of two policy frameworks (US Exec. Order on Preventing Woke AI, and EU General-Purpose AI Code of Practice); and (iii) whether misalignments between these perspectives warrant closer inspection of the viability of governing AI through natural language. We identify a fragmented literature advancing varying and contradictory claims about what goals system-level instructions can achieve, which we distil into a typology of claims. Further, we show how divergent claims complicate policy approaches that treat system-level instructions as stable, interpretable control mechanisms. We argue that given such misalignments, careful consideration must be given to prompt governance approaches. Our findings have broad implications, extending from a LLM policy context to the use of natural language as control mechanism in technical systems more generally.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that system-level instructions (prompts) are increasingly treated as governance instruments for GenAI/LLMs by both researchers and policymakers, but the literature advances fragmented and contradictory claims about their capabilities; a conceptual synthesis distills these into a typology, and analysis of the US Executive Order on Preventing Woke AI and the EU General-Purpose AI Code of Practice reveals misalignments that complicate treating prompts as stable, interpretable control mechanisms, warranting caution on prompt governance more broadly.
Significance. If the typology accurately captures the literature and the policy misalignment holds, the work usefully flags a practical obstacle for natural-language-based AI governance approaches, with implications for regulatory design beyond LLMs. The interdisciplinary bridge between technical claims and specific policy texts is a strength, though the absence of a reproducible review protocol limits how far the fragmentation claim can be taken as evidence.
major comments (2)
- [Abstract; literature synthesis section] Abstract and the section describing the literature analysis: the paper states it 'systematically evaluate[s]' researcher perspectives on system-level instructions and distills a typology of claims, yet provides no search strategy, databases, keywords, inclusion/exclusion criteria, or coding protocol for identifying contradictions. This is load-bearing for the central claim that the literature is fragmented, because without these details it is impossible to assess whether the typology reflects the full range of views or selected examples.
- [Policy frameworks analysis] Policy analysis section (analysis of US Exec. Order and EU Code of Practice): the claim that divergent literature claims 'complicate policy approaches' rests on these two documents being representative of policymaker perspectives. No justification is given for their selection over other national strategies or standards documents, nor is there discussion of how the typology maps onto them beyond the two cases; this weakens the policy-implication conclusion.
minor comments (2)
- [Abstract; Introduction] The abstract refers to 'system-level instructions' and 'prompt governance' without an early, explicit definition or scope (e.g., whether this includes only system prompts or also developer specs and end-user guidelines).
- [Typology section] The paper would benefit from a table or figure summarizing the typology of claims with representative citations from the literature for each category.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments, which identify important opportunities to enhance the transparency of our methods and the justification for our case selection. We address each major comment below and will make corresponding revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract; literature synthesis section] Abstract and the section describing the literature analysis: the paper states it 'systematically evaluate[s]' researcher perspectives on system-level instructions and distills a typology of claims, yet provides no search strategy, databases, keywords, inclusion/exclusion criteria, or coding protocol for identifying contradictions. This is load-bearing for the central claim that the literature is fragmented, because without these details it is impossible to assess whether the typology reflects the full range of views or selected examples.
Authors: We agree that the current description of the literature synthesis lacks sufficient methodological detail to support the claim of fragmentation. The typology was developed through close reading of prominent works on system prompts rather than a formal systematic review with predefined protocols. In revision, we will add a dedicated subsection describing the sources consulted, the criteria used to identify relevant claims, and the process for surfacing contradictions. We will also adjust the abstract language from 'systematically evaluate' to 'evaluate' to better reflect the scope of the synthesis. revision: yes
-
Referee: [Policy frameworks analysis] Policy analysis section (analysis of US Exec. Order and EU Code of Practice): the claim that divergent literature claims 'complicate policy approaches' rests on these two documents being representative of policymaker perspectives. No justification is given for their selection over other national strategies or standards documents, nor is there discussion of how the typology maps onto them beyond the two cases; this weakens the policy-implication conclusion.
Authors: The two documents were selected because they are recent, high-profile policy instruments that directly reference system-level instructions or equivalent mechanisms in major AI regulatory jurisdictions. We will revise the policy section to include explicit selection criteria, note their illustrative rather than exhaustive character, and provide a clearer, point-by-point mapping of the typology onto specific provisions in each document to demonstrate the misalignments more rigorously. revision: yes
Circularity Check
No circularity: conceptual synthesis of external literature and policies
full rationale
The paper performs a literature synthesis and policy comparison without equations, fitted parameters, derivations, or self-referential loops. It distills a typology from external researcher claims and contrasts it with two policy documents (US Exec. Order, EU Code of Practice). No self-citation is load-bearing for the central claim, and the analysis relies on external sources rather than reducing to its own inputs by construction. This is a standard non-circular conceptual paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adetayo Adebimpe, Helmut Neukirchen, and Thomas Welsh. 2025. SBASH: a Framework for Designing and Evaluating RAG vs. Prompt-Tuned LLM Honeypots. doi:10.48550/arXiv.2510.21459
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.21459 2025
-
[2]
Andrew Adiletta, Zane Weissman, Fatemeh Khojasteh Dana, Berk Sunar, and Shahin Tajik. 2025. Rubber Mallet: A Study of High Frequency Localized Bit Flips and Their Impact on Security. doi:10.48550/arXiv.2505.01518
-
[3]
Divyansh Agarwal, Alexander Fabbri, Ben Risher, Philippe Laban, Shafiq Joty, and Chien-Sheng Wu. 2024. Prompt Leakage effect and mitigation strategies for multi-turn LLM Applications. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, Franck Dernoncourt, Daniel Preoţiuc-Pietro, and Anastasia Shimorina...
-
[4]
Liberal, Miren Arrese, and Helena Matute
Ujué Agudo, Karlos G. Liberal, Miren Arrese, and Helena Matute. 2024. The impact of AI errors in a human-in-the-loop process. Cognitive Research: Principles and Implications9, 1 (Jan. 2024), 1. doi:10.1186/s41235-023-00529-3
-
[5]
Thea Lovise Ahlgren, Helene Fønstelien Sunde, Kai-Kristian Kemell, and Anh Nguyen-Duc. 2025. Assisting early-stage software startups with LLMs: Effective prompt engineering and system instruction design.Information and Software Technology187 (Nov. 2025), 107832. doi:10.1016/j.infsof.2025.107832
-
[6]
Ferit Akaybicen, Aaron Cummings, Lota Iwuagwu, Xinyue Zhang, and Modupe Akintomide. 2026. A Machine Learning Approach for Emergency Detection in Medical Scenarios Using Large Language Models. InProceedings of the International Symposium on Intelligent Computing and Networking 2025, Manuel Rodriguez Martinez, Kejie Lu, Feng Ye, and Yi Qian (Eds.). Springer...
2026
-
[7]
Ahmet Yusuf Alan, Enis Karaarslan, and Omer Aydin. 2025. Improving LLM Reliability with RAG in Religious Question-Answering: MufassirQAS. doi:10.48550/arXiv.2401.15378
-
[8]
Maimounah Alhujaili and Ruqayya Abdulrahman. 2025. Fine-Tuning OpenAI GPT Chatbot in Western Saudi Dialect: A Case Study of Taibah University.International Journal of Advanced Computer Science and Applications16, 6 (2025). doi:10.14569/IJACSA.2025.0160632
-
[9]
Muhammad Ali, Bixia Chen, and Gary Wong. 2025. Developing Alice: A Scaffolding Agent for AI-Mediated Computational Thinking. Proceedings of the 9th International Conference on Computational Thinking and STEM Education (CTE-STEM 2025), 9 (June 2025), 26–31. doi:10.5281/zenodo.15769853
-
[10]
Ali, Angèle Christin, Andrew Smart, and Riitta Katila
Sanna J. Ali, Angèle Christin, Andrew Smart, and Riitta Katila. 2023. Walking the Walk of AI Ethics: Organizational Challenges and the Individualization of Risk among Ethics Entrepreneurs. In2023 ACM Conference on Fairness Accountability and Transparency. ACM, Chicago IL USA, 217–226. doi:10.1145/3593013.3593990
-
[11]
Masoud, Alaa Alzahrani, Deema Alnuhait, Emad A
Mohammed Alkhowaiter, Norah Alshahrani, Saied Alshahrani, Reem I. Masoud, Alaa Alzahrani, Deema Alnuhait, Emad A. Alghamdi, and Khalid Almubarak. 2025. Mind the Gap: A Review of Arabic Post-Training Datasets and Their Limitations. InProceedings of The Third Arabic Natural Language Processing Conference, Kareem Darwish, Ahmed Ali, Ibrahim Abu Farha, Samia ...
-
[12]
Mina Almasi and Ross Deans Kristensen-McLachlan. 2025. Alignment Drift in CEFR-prompted LLMs for Interactive Spanish Tutoring. doi:10.48550/arXiv.2505.08351
-
[13]
Ayesha Amjad, Saurav Sthapit, and Tahir Qasim Syed. 2026. An Agentic System with Reinforcement-Learned Subsystem Improvements for Parsing Form-Like Documents. InEngineering Multi-Agent Systems, Sebastian Rodriguez, Lu Feng, and Jörg P. Müller (Eds.). Springer Nature Switzerland, Cham, 27–44
2026
-
[14]
Anthropic. 2025. Configuring and Using Styles | Claude Help Center — support.claude.com. https://support.claude.com/en/articles/ 10181068-configuring-and-using-styles [Accessed 26-11-2025]. Prompt Governance? On Governing Technologies Governed by Natural Language FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
2025
-
[15]
Anthropic. 2025. Effective context engineering for AI agents — anthropic.com. https://www.anthropic.com/engineering/effective- context-engineering-for-ai-agents [Accessed 11-01-2026]
2025
-
[16]
Anthropic. 2025. Giving Claude a role with a system prompt - Anthropic — docs.anthropic.com. https://docs.anthropic.com/en/docs/ build-with-claude/prompt-engineering/system-prompts [Accessed 07-09-2025]
2025
-
[17]
Anthropic. 2026. Statement on the comments from Secretary of War Pete Hegseth — anthropic.com. https://www.anthropic.com/ news/statement-comments-secretary-war [Accessed 17-03-2026]
2026
-
[18]
Anthropic. 2026. Where things stand with the Department of War — anthropic.com. https://www.anthropic.com/news/where-stand- department-war [Accessed 17-03-2026]
2026
-
[19]
Paula Akemi Aoyagui, Kelsey Stemmler, Sharon A Ferguson, Young-Ho Kim, and Anastasia Kuzminykh. 2025. A Matter of Perspective(s): Contrasting Human and LLM Argumentation in Subjective Decision-Making on Subtle Sexism. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems (CHI ’25). Association for Computing Machinery, New York, NY...
-
[20]
Tariq Arif and Md Rahim. 2025. Agentic AI for Real-Time Adaptive PID Control of a Servo Motor.Actuators14, 9 (Sept. 2025), 459. doi:10.3390/act14090459
-
[21]
Rauno Arike, Elizabeth Donoway, Henning Bartsch, and Marius Hobbhahn. 2025. Technical Report: Evaluating Goal Drift in Language Model Agents. doi:10.48550/arXiv.2505.02709
-
[22]
Suriya Ganesh Ayyamperumal and Limin Ge. 2024. Current state of LLM Risks and AI Guardrails. doi:10.48550/arXiv.2406.12934
-
[23]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El-Showk, Nelson Elhage, Zac Hatfield-Dodds, Danny Hernandez, Tristan Hume, Scott Johnston, Shauna Kravec, Liane Lovitt, Neel Nanda, Catherine Olsson, ...
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [24]
-
[25]
Rick Battle and Teja Gollapudi. 2024. The Unreasonable Effectiveness of Eccentric Automatic Prompts. doi:10.48550/arXiv.2402.10949
-
[26]
Álvaro Guglielmin Becker, Gabriel Bauer de Oliveira, Lana Bertoldo Rossato, and Anderson Rocha Tavares. 2025. Boardwalk: Towards a Framework for Creating Board Games with LLMs. InAnais do XXIV Simpósio Brasileiro de Jogos e Entretenimento Digital (SBGames 2025). 655–667. doi:10.5753/sbgames.2025.10222
-
[27]
Rebecca Bellan. 2025. OpenAI adds new teen safety rules to ChatGPT as lawmakers weigh AI standards for minors | TechCrunch — techcrunch.com. https://techcrunch.com/2025/12/19/openai-adds-new-teen-safety-rules-to-models-as-lawmakers-weigh-ai- standards-for-minors/ [Accessed 10-01-2026]
2025
- [28]
-
[29]
Shir Bernstein, David Beste, Daniel Ayzenshteyn, Lea Schonherr, and Yisroel Mirsky. 2025. Trust Me, I Know This Function: Hijacking LLM Static Analysis using Bias. doi:10.48550/arXiv.2508.17361
-
[30]
Mazal Bethany, Nishant Vishwamitra, Cho-Yu Jason Chiang, and Peyman Najafirad. 2025. CAMOUFLAGE: Exploiting Misinformation Detection Systems Through LLM-driven Adversarial Claim Transformation. doi:10.48550/arXiv.2505.01900
-
[31]
Abeba Birhane, Pratyusha Kalluri, Dallas Card, William Agnew, Ravit Dotan, and Michelle Bao. 2022. The Values Encoded in Machine Learning Research. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 173–184. doi:10.1145/3531146.3533083
- [32]
-
[33]
Bo, Harsh Kumar, Michael Liut, and Ashton Anderson
Jessica Y. Bo, Harsh Kumar, Michael Liut, and Ashton Anderson. 2024. Disclosures & Disclaimers: Investigating the Impact of Transparency Disclosures and Reliability Disclaimers on Learner-LLM Interactions.Proceedings of the AAAI Conference on Human Computation and Crowdsourcing12 (Oct. 2024), 23–32. doi:10.1609/hcomp.v12i1.31597
-
[34]
Sebastian Daniel Boie, Esther Glastetter, Michael Patrick Lux, Felix Balzer, Christof Von Kalle, Christian Lenz, and Ulrike Müller
-
[35]
Evaluating a Chatbot as a Companion for Patients With Breast Cancer: Collaborative Pilot Study.JMIR Cancer11 (Aug. 2025), e68426–e68426. doi:10.2196/68426
-
[36]
2020.The Brussels effect: How the European Union rules the world
Anu Bradford. 2020.The Brussels effect: How the European Union rules the world. Oxford University Press
2020
-
[37]
Christian Braun, Alexander Lilienbeck, and Daniel Mentjukov. 2025. The Hidden Structure – Improving Legal Document Understanding Through Explicit Text Formatting. doi:10.48550/arXiv.2505.12837
-
[38]
Maarten Buyl, Yousra Fettach, Guillaume Bied, and Tijl De Bie. 2025. Building and Measuring Trust between Large Language Models. doi:10.48550/arXiv.2508.15858 FAccT ’26, June 25–28, 2026, Montreal, QC, Canada Neumann et al
-
[39]
Maarten Buyl, Alexander Rogiers, Sander Noels, Guillaume Bied, Iris Dominguez-Catena, Edith Heiter, Iman Johary, Alexandru- Cristian Mara, Raphaël Romero, Jefrey Lijffijt, and Tijl De Bie. 2025. Large Language Models Reflect the Ideology of their Creators. arXiv:2410.18417 [cs.CL] https://arxiv.org/abs/2410.18417
-
[40]
Maarten Buyl, Alexander Rogiers, Sander Noels, Guillaume Bied, Iris Dominguez-Catena, Edith Heiter, Iman Johary, Alexandru-Cristian Mara, Raphaël Romero, Jefrey Lijffijt, and Tijl De Bie. 2026. Large language models reflect the ideology of their creators.npj Artificial Intelligence2, 1 (Jan. 2026), 7. doi:10.1038/s44387-025-00048-0
-
[41]
Jinyu Cai, Yusei Ishimizu, Mingyue Zhang, Munan Li, Jialong Li, and Kenji Tei. 2025. Simulation of Language Evolution under Regulated Social Media Platforms: A Synergistic Approach of Large Language Models and Genetic Algorithms. doi:10.48550/arXiv.2502.19193
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.19193 2025
-
[42]
Bochuan Cao, Changjiang Li, Yuanpu Cao, Yameng Ge, Ting Wang, and Jinghui Chen. 2025. You Can’t Steal Nothing: Mitigating Prompt Leakages in LLMs via System Vectors. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security (Taipei, Taiwan)(CCS ’25). Association for Computing Machinery, New York, NY, USA, 4423–4437. doi:10.11...
-
[43]
Jeshwanth Challagundla, Mantek Singh, Siddharth Raina, Smarth Behl, FNU Harsh, and Jasmin Jarsania. 2025. SI-Agent: An Agentic Framework for Feedback-Driven Generation and Tuning of Human-Readable System Instructions for Large Language Models. In2025 16th International Conference on Information, Intelligence, Systems & Applications (IISA). 1–9. doi:10.110...
-
[44]
Alan Chan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke, Nitarshan Rajkumar, David Krueger, Noam Kolt, Lennart Heim, and Markus Anderljung. 2024. Visibility into AI Agents. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency(Rio de Janeiro, Brazil)(FAccT ’24). Association for Computi...
-
[45]
Chun Fai Chan, Daniel Wankit Yip, and Aysan Esmradi. 2023. Detection and Defense Against Prominent Attacks on Preconditioned LLM-Integrated Virtual Assistants. In2023 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE). 1–5. doi:10.1109/CSDE59766.2023.10487759
-
[46]
Pantid Chantangphol, Pornchanan Balee, Kantapong Sucharitpongpan, Chanatip Saetia, and Tawunrat Chalothorn. 2025. FinMind- Y-Me at the Regulations Challenge Task: Financial Mind Your Meaning based on THaLLE. InProceedings of the Joint Workshop of the 9th Financial Technology and Natural Language Processing (FinNLP), the 6th Financial Narrative Processing ...
2025
-
[47]
Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong
Patrick Chao, Edoardo Debenedetti, Alexander Robey, Maksym Andriushchenko, Francesco Croce, Vikash Sehwag, Edgar Dobriban, Nicolas Flammarion, George J. Pappas, Florian Tramèr, Hamed Hassani, and Eric Wong. 2024. JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models. InAdvances in Neural Information Processing Systems, A. Glo...
-
[48]
Shreya Chappidi, Jatinder Singh, and Andra V Krauze. 2026. Who Does What? Archetypes of Roles Assigned to LLMs During Human-AI Decision-Making. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems. ACM, Barcelona, Spain. doi:10.1145/3772318.3791428
-
[49]
Alex Chen, Renato Geh, Aditya Grover, Guy Van den Broeck, and Daniel Israel. 2025. The Pitfalls of KV Cache Compression. doi:10.48550/arXiv.2510.00231
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.00231 2025
-
[50]
Bocheng Chen, Hanqing Guo, and Qiben Yan. 2024. FlexLLM: Exploring LLM Customization for Moving Target Defense on Black-Box LLMs Against Jailbreak Attacks. doi:10.48550/arXiv.2412.07672
-
[51]
Bocheng Chen, Nikolay Ivanov, Guangjing Wang, and Qiben Yan. 2024. Multi-Turn Hidden Backdoor in Large Language Model-powered Chatbot Models. InProceedings of the 19th ACM Asia Conference on Computer and Communications Security. ACM, Singapore Singapore, 1316–1330. doi:10.1145/3634737.3656289
-
[52]
Kedi Chen, Qin Chen, Jie Zhou, He Yishen, and Liang He. 2024. DiaHalu: A Dialogue-level Hallucination Evaluation Benchmark for Large Language Models. InFindings of the Association for Computational Linguistics: EMNLP 2024. Association for Computational Linguistics, Miami, Florida, USA, 9057–9079. doi:10.18653/v1/2024.findings-emnlp.529
-
[53]
Tong Chen, Faeze Brahman, Jiacheng Liu, Niloofar Mireshghallah, Weijia Shi, Pang Wei Koh, Luke Zettlemoyer, and Hannaneh Hajishirzi
-
[54]
ParaPO: Aligning Language Models to Reduce Verbatim Reproduction of Pre-training Data. doi:10.48550/arXiv.2504.14452
-
[55]
Zhangquan Chen, Chunjiang Liu, and Haobin Duan. 2024. A Three-Phases-LORA Finetuned Hybrid LLM Integrated with Strong Prior Module in the Education Context. InArtificial Neural Networks and Machine Learning – ICANN 2024, Michael Wand, Kristína Malinovská, Jürgen Schmidhuber, and Igor V. Tetko (Eds.). Vol. 15020. Springer Nature Switzerland, Cham, 235–250....
-
[56]
Xiang Cheng, Raveesh Mayya, and João Sedoc. 2025. To Err Is Human; To Annotate, SILICON? Reducing Measurement Error in LLM Annotation. doi:10.48550/arXiv.2412.14461
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.14461 2025
-
[57]
Simon Chesterman, Lyria Bennett Moses, and Ugo Pagallo. 2023. All Rise for the Honourable Robot Judge? Using Artificial Intelligence to Regulate AI: a debate.Technology and Regulation2023 (Oct. 2023), 45–57. doi:10.71265/0p137y60 Prompt Governance? On Governing Technologies Governed by Natural Language FAccT ’26, June 25–28, 2026, Montreal, QC, Canada
-
[58]
Cheng-Han Chiang, Wei-Chih Chen, Chun-Yi Kuan, Chienchou Yang, and Hung-yi Lee. 2024. Large Language Model as an Assignment Evaluator: Insights, Feedback, and Challenges in a 1000+ Student Course. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen (Eds.). Association ...
-
[59]
Jeffrey Yang Fan Chiang, Seungjae Lee, Jia-Bin Huang, Furong Huang, and Yizheng Chen. 2025. Why Are Web AI Agents More Vulnerable Than Standalone LLMs? A Security Analysis. doi:10.48550/arXiv.2502.20383
-
[60]
Yu Ying Chiu, Liwei Jiang, and Yejin Choi. 2025. DailyDilemmas: Revealing Value Preferences of LLMs with Quandaries of Daily Life. doi:10.48550/arXiv.2410.02683
-
[61]
Yumin Choi, Jinheon Baek, and Sung Ju Hwang. 2025. System Prompt Optimization with Meta-Learning. doi:10.48550/arXiv.2505.09666
-
[62]
Sora Chon, Jaehoon Kim, and Jaeho Kim. 2025. Multifaceted variability in LLM-driven stock recommendations.Finance Research Letters86 (Dec. 2025), 108923. doi:10.1016/j.frl.2025.108923
-
[63]
Chrome. 2025. The Prompt API | AI on Chrome | Chrome for Developers — developer.chrome.com. https://developer.chrome.com/ docs/ai/prompt-api [Accessed 13-01-2026]
2025
-
[64]
Gabriel Chua, Shing Yee Chan, and Shaun Khoo. 2025. A Flexible Large Language Models Guardrail Development Methodology Applied to Off-Topic Prompt Detection. doi:10.48550/arXiv.2411.12946
-
[65]
Peter Cihon, Jonas Schuett, and Seth D. Baum. 2021. Corporate Governance of Artificial Intelligence in the Public Interest.Information 12, 7 (2021). doi:10.3390/info12070275
- [66]
-
[67]
Claude. 2025. System Prompts — platform.claude.com. https://platform.claude.com/docs/en/release-notes/system-prompts [Accessed 07-01-2026]
2025
-
[68]
Jennifer Cobbe, Michelle Seng Ah Lee, and Jatinder Singh. 2021. Reviewable Automated Decision-Making: A Framework for Accountable Algorithmic Systems. InProceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’21). Association for Computing Machinery, New York, NY, USA, 598–609. doi:10.1145/3442188.3445921
-
[69]
Jennifer Cobbe, Michael Veale, and Jatinder Singh. 2023. Understanding accountability in algorithmic supply chains. InProceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency(Chicago, IL, USA)(FAccT ’23). Association for Computing Machinery, New York, NY, USA, 1186–1197. doi:10.1145/3593013.3594073
-
[70]
Kwesi Adu Cobbina and Tianyi Zhou. 2025. Where to show Demos in Your Prompt: A Positional Bias of In-Context Learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (Eds.). Association for Computational Linguistics, Suzhou, China, 295...
2025
-
[71]
Ofir Cohen, Gil Ari Agmon, Asaf Shabtai, and Rami Puzis. 2025. The Information Security Awareness of Large Language Models. doi:10.48550/arXiv.2411.13207
-
[72]
Luca Collini, Siddharth Garg, and Ramesh Karri. 2025. C2HLSC: Leveraging Large Language Models to Bridge the Software-to-Hardware Design Gap.ACM Trans. Des. Autom. Electron. Syst.30, 6, Article 96 (Oct. 2025), 24 pages. doi:10.1145/3734524
-
[73]
Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum
A. Feder Cooper, Emanuel Moss, Benjamin Laufer, and Helen Nissenbaum. 2022. Accountability in an Algorithmic Society: Relationality, Responsibility, and Robustness in Machine Learning. InProceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’22). Association for Computing Machinery, New York, NY, USA, 864–876. doi:10....
-
[74]
Rimom Costa. 2025. Instruction-Level Weight Shaping: A Framework for Self-Improving AI Agents. doi:10.48550/arXiv.2509.00251
-
[75]
Yuhao Dan, Zhikai Lei, Yiyang Gu, Yong Li, Jianghao Yin, Jiaju Lin, Linhao Ye, Zhiyan Tie, Yougen Zhou, Yilei Wang, Aimin Zhou, Ze Zhou, Qin Chen, Jie Zhou, Liang He, and Xipeng Qiu. 2023. EduChat: A Large-Scale Language Model-based Chatbot System for Intelligent Education. doi:10.48550/arXiv.2308.02773
-
[76]
Johan S. Daniel and Anand Pal. 2024. Impact of Non-Standard Unicode Characters on Security and Comprehension in Large Language Models. doi:10.48550/arXiv.2405.14490
-
[77]
Badhan Chandra Das, M. Hadi Amini, and Yanzhao Wu. 2025. System Prompt Extraction Attacks and Defenses in Large Language Models. doi:10.48550/arXiv.2505.23817
-
[78]
Davis and Florencia Marotta-Wurgler
Kevin E. Davis and Florencia Marotta-Wurgler. 2024. Filling the Void: How E.U. Privacy Law Spills Over to the U.S.Journal of Law & Empirical Analysis1, 1 (2024), 77–97. doi:10.1177/2755323X241237619
-
[79]
Íñigo de Troya, Jacqueline Kernahan, Neelke Doorn, Virginia Dignum, and Roel Dobbe. 2025. Misabstraction in Sociotechnical Systems. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency (FAccT ’25). Association for Computing Machinery, New York, NY, USA, 1829–1842. doi:10.1145/3715275.3732122
-
[80]
Edoardo Debenedetti, Javier Rando, Daniel Paleka, Fineas Silaghi, Dragos Albastroiu, Niv Cohen, Yuval Lemberg, Reshmi Ghosh, Rui Wen, Ahmed Salem, Giovanni Cherubin, Santiago Zanella-Beguelin, Robin Schmid, Victor Klemm, Takahiro Miki, Chenhao Li, Stefan Kraft, Mario Fritz, Florian Tramèr, Sahar Abdelnabi, and Lea Schönherr. 2024. Dataset and Lessons Lear...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.