LoCC: Detection and Localization of Lip-Syncing Deepfakes via Counterfactual Frame Consistency
Pith reviewed 2026-06-26 09:05 UTC · model grok-4.3
The pith
Each frame is tested against a counterfactual estimate from its temporal neighbors to expose lip-sync deepfake inconsistencies.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LoCC evaluates whether each frame aligns with a counterfactual estimate generated from its temporal neighbors. Real videos exhibit strong and stable consistency, whereas lip-sync deepfakes introduce localized inconsistencies. Following a teacher-student learning paradigm, the model captures these frame-level discrepancies for fine-grained detection and localization at both segment and frame levels.
What carries the argument
Counterfactual frame consistency, the mechanism that compares each frame to an estimate synthesized from its temporal neighbors to surface localized lip-motion mismatches.
If this is right
- Detection and localization become possible at both segment and frame levels rather than video-wide scores alone.
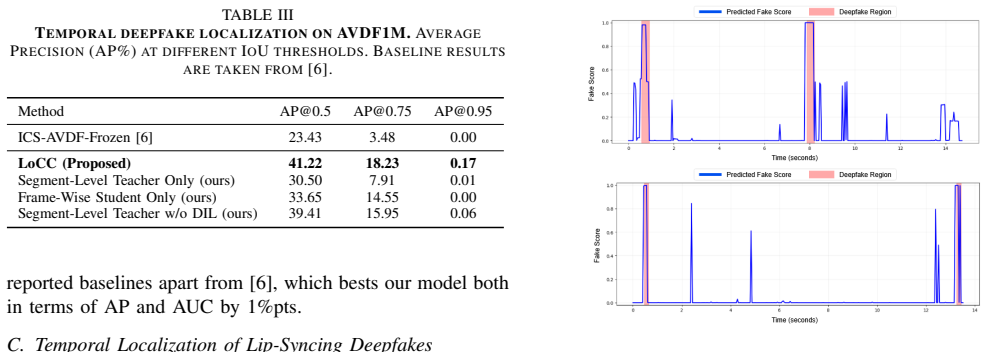
- Performance exceeds prior methods on the LAV-DF, AVDF1M, FakeAVCeleb, and KODF benchmarks.
- Results remain stable across varying compression levels and transfer between datasets.
- Localization focuses on the mouth region where lip-sync artifacts occur.
Where Pith is reading between the lines
- The same neighbor-based consistency test could be applied to other localized temporal edits such as eye blinks or facial expressions.
- Integration with audio features might create a joint audio-visual consistency metric without retraining the core frame checker.
- The frame-level scores could support downstream tasks like editing the inconsistent segments back to real motion.
Load-bearing premise
Real videos maintain strong and stable consistency across frames while lip-sync deepfakes produce localized inconsistencies that can be reliably measured by counterfactual estimates from temporal neighbors.
What would settle it
A real video that scores high inconsistency or a lip-sync deepfake that scores low inconsistency when evaluated by the counterfactual neighbor comparison would disprove the central claim.
Figures

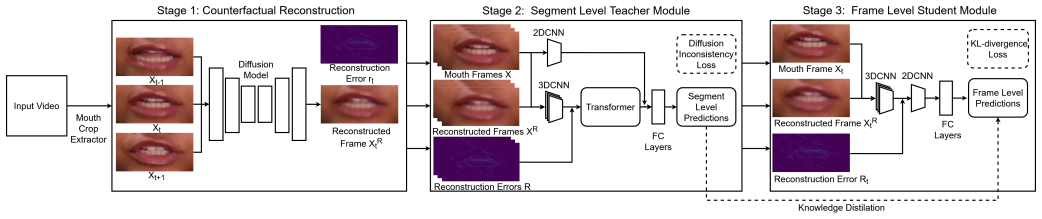
read the original abstract
Lip-syncing deepfakes are among the most challenging forms of manipulated media because their artifacts are localized almost exclusively to the mouth region and evolve dynamically over time. Detecting such deepfakes requires precise temporal and spatial modeling of lip motion. In this paper, we propose LoCC, a novel detection framework that performs fine-grained detection and localization of lip-syncing deepfakes at both segment and frame levels. Unlike prior approaches that analyze videos holistically, our method evaluates whether each frame aligns with a counterfactual estimate generated from its temporal neighbors. Real videos exhibit strong and stable consistency, whereas lip-sync deepfakes introduce localized inconsistencies. Following a teacher-student learning paradigm, our model effectively captures these frame-level discrepancies and achieves superior performance over state-of-the-art methods on multiple benchmark lip-syncing deepfake datasets, including LAV-DF, AVDF1M, FakeAVCeleb, and KODF, and generalizes well across compression levels and datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LoCC, a detection and localization framework for lip-syncing deepfakes that checks whether each frame is consistent with a counterfactual estimate synthesized from its temporal neighbors. Real videos are asserted to show strong, stable consistency while deepfakes produce localized inconsistencies; a teacher-student paradigm is used to learn these discrepancies, with claims of superior performance on LAV-DF, AVDF1M, FakeAVCeleb, and KODF plus generalization across compression levels.
Significance. If the core consistency assumption proves robust after targeted validation, the approach could meaningfully advance fine-grained, temporally localized deepfake detection for mouth-region artifacts that holistic methods struggle with. The counterfactual-neighbor idea is a distinct modeling choice that, if shown to be insensitive to natural motion statistics, would be a useful addition to the literature.
major comments (1)
- [Abstract] Abstract: the central claim that real videos exhibit 'strong and stable consistency' while deepfakes introduce detectable localized inconsistencies rests on the counterfactual generator being able to reconstruct plausible mouth appearance from temporal neighbors alone. Natural frame-to-frame lip-velocity and coarticulation variation in authentic footage can produce spurious inconsistencies; the manuscript provides no explicit regularization, ablation, or controlled test isolating manipulation artifacts from ordinary motion statistics, leaving open the possibility that reported gains partly reflect dataset motion biases rather than the proposed mechanism.
Simulated Author's Rebuttal
We thank the referee for the constructive comment regarding the central claim in the abstract. We address the point below and outline planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that real videos exhibit 'strong and stable consistency' while deepfakes introduce detectable localized inconsistencies rests on the counterfactual generator being able to reconstruct plausible mouth appearance from temporal neighbors alone. Natural frame-to-frame lip-velocity and coarticulation variation in authentic footage can produce spurious inconsistencies; the manuscript provides no explicit regularization, ablation, or controlled test isolating manipulation artifacts from ordinary motion statistics, leaving open the possibility that reported gains partly reflect dataset motion biases rather than the proposed mechanism.
Authors: We agree that the abstract's assertion would be strengthened by explicit evidence isolating deepfake-induced inconsistencies from natural lip motion variation. The teacher-student framework is intended to focus on discrepancies arising from manipulation, and the reported gains across four diverse datasets (LAV-DF, AVDF1M, FakeAVCeleb, KODF) plus compression robustness provide indirect support that the method is not merely capturing dataset-specific motion statistics. However, the manuscript indeed lacks a dedicated ablation or controlled test (e.g., comparing consistency scores on high-motion real videos versus manipulated ones with matched motion). In the revised manuscript we will add such an experiment, including regularization analysis and motion-matched controls, to directly address this concern. revision: yes
Circularity Check
No circularity: core claim is an empirical modeling assumption, not a self-referential derivation
full rationale
The paper's central premise—that real videos exhibit stable frame-to-neighbor consistency while lip-sync deepfakes produce localized inconsistencies—is presented as an observed property used to motivate the LoCC detector and teacher-student training. No equations, fitted parameters renamed as predictions, or self-citation chains are shown that reduce the claimed detection performance to the inputs by construction. The approach is a standard consistency-based anomaly detector; its validity rests on empirical validation across datasets rather than definitional equivalence. This is the most common non-circular case for detection papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Canadian pm mark carney targeted by viral deepfakes on social media,
Catalina Marchant de Abreu, “Canadian pm mark carney targeted by viral deepfakes on social media,”France 24, June 2025, https: //www.france24.com/en/tv-shows/truth-or-fake/20250506-canadian- pm-mark-carney-targeted-by-viral-deepfakes-on-social-media
-
[2]
California woman loses home after being scammed by ai deepfake posing as actor,
Vivian Chow, “California woman loses home after being scammed by ai deepfake posing as actor,”KTLA, Aug. 2025, https://ktla.com/news/local-news/woman-loses-home-scammed- by-ai-deepfake-scammer-pretending-to-be-general-hospital-actor/
2025
-
[3]
British engineering giant arup revealed as $25 million deepfake scam victim,
Kathleen Magramo, “British engineering giant arup revealed as $25 million deepfake scam victim,”CNN, May 2024, https://www.cnn.com/ 2024/05/16/tech/arup-deepfake-scam-loss-hong-kong-intl-hnk
2024
-
[4]
Lips don’t lie: A generalisable and robust approach to face forgery detection,
A Haliassos, K V ougioukas, S Petridis, and M Pantic, “Lips don’t lie: A generalisable and robust approach to face forgery detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 5039–5049
2021
-
[5]
Faceforensics++: Learning to detect manipulated facial images,
A Rossler, D Cozzolino, et al., “Faceforensics++: Learning to detect manipulated facial images,” inProceedings of the ICCV, 2019, pp. 1– 11
2019
-
[6]
Intra-modal and cross- modal synchronization for audio-visual deepfake detection and temporal localization,
A Anshul, S Gopal, D Rajan, and E S Chng, “Intra-modal and cross- modal synchronization for audio-visual deepfake detection and temporal localization,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 13826–13836
2025
-
[7]
Avff: Audio-visual feature fusion for video deepfake detection,
T Oorloff, S Koppisetti, N Bonettini, D Solanki, B Colman, Y Yacoob, A Shahriyari, and G Bharaj, “Avff: Audio-visual feature fusion for video deepfake detection,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27102–27112
2024
-
[8]
Pia: Deepfake detection using phoneme-temporal and identity-dynamic analysis,
S K Datta, T Ranga, C Sun, and S Lyu, “Pia: Deepfake detection using phoneme-temporal and identity-dynamic analysis,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 1596–1606
2025
-
[9]
A lip sync expert is all you need for speech to lip generation in the wild,
KR Prajwal, R Mukhopadhyay, V P Namboodiri, and CV Jawahar, “A lip sync expert is all you need for speech to lip generation in the wild,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 484–492
2020
-
[10]
Videoretalking: Audio-based lip synchronization for talking head video editing in the wild,
K Cheng, X Cun, Y Zhang, M Xia, F Yin, M Zhu, X Wang, J Wang, and N Wang, “Videoretalking: Audio-based lip synchronization for talking head video editing in the wild,” inSIGGRAPH Asia 2022 Conference Papers, 2022, pp. 1–9
2022
-
[11]
Runway ML,
Runway AI, Inc., “Runway ML,” 2025, https://runwayml.com/
2025
-
[12]
Sora 2: Advanced video and audio generation model,
OpenAI, “Sora 2: Advanced video and audio generation model,” 2025, https://openai.com/index/sora-2/
2025
-
[13]
Generative adversarial nets,
I J Goodfellow, J Pouget-Abadie, M Mirza, B Xu, D Warde-Farley, S Ozair, A Courville, and Y Bengio, “Generative adversarial nets,” Advances in neural information processing systems, vol. 27, 2014
2014
-
[14]
Diffusion models beat gans on image synthesis,
P Dhariwal and A Nichol, “Diffusion models beat gans on image synthesis,”Advances in neural information processing systems, vol. 34, pp. 8780–8794, 2021
2021
-
[15]
Diff2lip: Au- dio conditioned diffusion models for lip-synchronization,
S Mukhopadhyay, S Suri, R T Gadde, and A Shrivastava, “Diff2lip: Au- dio conditioned diffusion models for lip-synchronization,” inProceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2024, pp. 5292–5302
2024
-
[16]
Latentsync: Taming audio-conditioned latent diffusion models for lip sync with syncnet supervision,
C Li, C Zhang, W Xu, J Lin, J Xie, W Feng, B Peng, C Chen, and W Xing, “Latentsync: Taming audio-conditioned latent diffusion models for lip sync with syncnet supervision,”arXiv preprint arXiv:2412.09262, 2024
-
[17]
Exploring temporal coherence for more general video face forgery detection,
Y Zheng, J Bao, D Chen, M Zeng, and F Wen, “Exploring temporal coherence for more general video face forgery detection,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 15044–15054
2021
-
[18]
Self-supervised video forensics by audio-visual anomaly detection,
C Feng, Z Chen, and A Owens, “Self-supervised video forensics by audio-visual anomaly detection,” inproceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 10491–10503
2023
-
[19]
Ummaformer: A universal multimodal-adaptive trans- former framework for temporal forgery localization,
R Zhang, Hongxia Wang, Mingshan Du, Hanqing Liu, Yang Zhou, and Qiang Zeng, “Ummaformer: A universal multimodal-adaptive trans- former framework for temporal forgery localization,” inProceedings of the 31st ACM International Conference on Multimedia, 2023, pp. 8749–8759
2023
-
[20]
Circumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning,
S Smeu, D-A Boldisor, D Oneata, and E Oneata, “Circumventing shortcuts in audio-visual deepfake detection datasets with unsupervised learning,” inProceedings of the Computer Vision and Pattern Recogni- tion Conference, 2025, pp. 18815–18825
2025
-
[21]
Altfreezing for more general video face forgery detection,
Z Wang, J Bao, W Zhou, W Wang, and H Li, “Altfreezing for more general video face forgery detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 4129– 4138
2023
-
[22]
Dlib-ml: A machine learning toolkit,
Davis E King, “Dlib-ml: A machine learning toolkit,”The Journal of Machine Learning Research, vol. 10, pp. 1755–1758, 2009
2009
-
[23]
Learning spatiotemporal features with 3d convolutional networks,
D Tran, L Bourdev, R Fergus, L Torresani, and M Paluri, “Learning spatiotemporal features with 3d convolutional networks,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 4489–4497
2015
-
[24]
Attention is all you need,
A Vaswani, N Shazeer, N Parmar, J Uszkoreit, L Jones, A N Gomez, Ł Kaiser, and I Polosukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[25]
Unsupervised multimodal deepfake detection using intra-and cross-modal inconsisten- cies,
M Tian, M Khayatkhoei, J Mathai, and W AbdAlmageed, “Unsupervised multimodal deepfake detection using intra-and cross-modal inconsisten- cies,”arXiv preprint arXiv:2311.17088, 2023
-
[26]
Leveraging real talking faces via self-supervision for robust forgery detection,
Alexandros Haliassos, Rodrigo Mira, Stavros Petridis, and Maja Pantic, “Leveraging real talking faces via self-supervision for robust forgery detection,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 14950–14962
2022
-
[27]
Joint audio-visual deepfake detection,
Y Zhou and S Lim, “Joint audio-visual deepfake detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 14800–14809
2021
-
[28]
Taming transformers for high- resolution image synthesis,
P Esser, R Rombach, and B Ommer, “Taming transformers for high- resolution image synthesis,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12873–12883
2021
-
[29]
Fakeavceleb: A novel audio- video multimodal deepfake dataset,
H Khalid, S Tariq, M Kim, and S S Woo, “Fakeavceleb: A novel audio- video multimodal deepfake dataset,”arXiv preprint arXiv:2108.05080, 2021
-
[30]
S Barrington, M Bohacek, and H Farid, “Deepspeak dataset v1. 0,” arXiv preprint arXiv:2408.05366, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Do you really mean that? content driven audio-visual deepfake dataset and multimodal method for temporal forgery localization,
Z Cai, K Stefanov, A Dhall, and M Hayat, “Do you really mean that? content driven audio-visual deepfake dataset and multimodal method for temporal forgery localization,” in2022 International Conference on Digital Image Computing: Techniques and Applications (DICTA). IEEE, 2022, pp. 1–10
2022
-
[32]
Glitch in the matrix: A large scale benchmark for content driven audio– visual forgery detection and localization,
Z Cai, S Ghosh, A Dhall, T Gedeon, K Stefanov, and M Hayat, “Glitch in the matrix: A large scale benchmark for content driven audio– visual forgery detection and localization,”Computer Vision and Image Understanding, vol. 236, pp. 103818, 2023
2023
-
[33]
Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset,
Z Cai, S Ghosh, A P Adatia, M Hayat, A Dhall, T Gedeon, and K Stefanov, “Av-deepfake1m: A large-scale llm-driven audio-visual deepfake dataset,” inProceedings of the 32nd ACM International Conference on Multimedia, 2024, pp. 7414–7423
2024
-
[34]
Kodf: A large-scale korean deepfake detection dataset,
P Kwon, J You, G Nam, S Park, and G Chae, “Kodf: A large-scale korean deepfake detection dataset,” inProceedings of the ICCV, 2021, pp. 10744–10753
2021
-
[35]
Not made for each other-audio-visual dissonance-based deepfake detection and local- ization,
K Chugh, P Gupta, A Dhall, and R Subramanian, “Not made for each other-audio-visual dissonance-based deepfake detection and local- ization,” inProceedings of the 28th ACM international conference on multimedia, 2020, pp. 439–447
2020
-
[36]
Bmn: Boundary-matching network for temporal action proposal generation,
T Lin, X Liu, X Li, E Ding, and S Wen, “Bmn: Boundary-matching network for temporal action proposal generation,” inProceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 3889–3898
2019
-
[37]
Hear me out: Fusional approaches for audio augmented temporal action localization,
A Bagchi, J Mahmood, D Fernandes, and R K Sarvadevabhatla, “Hear me out: Fusional approaches for audio augmented temporal action localization,”arXiv preprint arXiv:2106.14118, 2021
-
[38]
Actionformer: Localizing moments of actions with transformers,
C-L Zhang, J Wu, and Y Li, “Actionformer: Localizing moments of actions with transformers,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 492–510
2022
-
[39]
Tridet: Temporal action detection with relative boundary modeling,
D Shi, Y Zhong, Q Cao, L Ma, J Li, and D Tao, “Tridet: Temporal action detection with relative boundary modeling,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 18857–18866
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.