When Correct Decisions Hide Internal Stress: Decision-State Probing in Multimodal Language Models
Pith reviewed 2026-06-27 19:00 UTC · model grok-4.3
The pith
Semantic stress produces excess hidden-state displacement in multimodal models even on strictly correct forced-choice trials.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
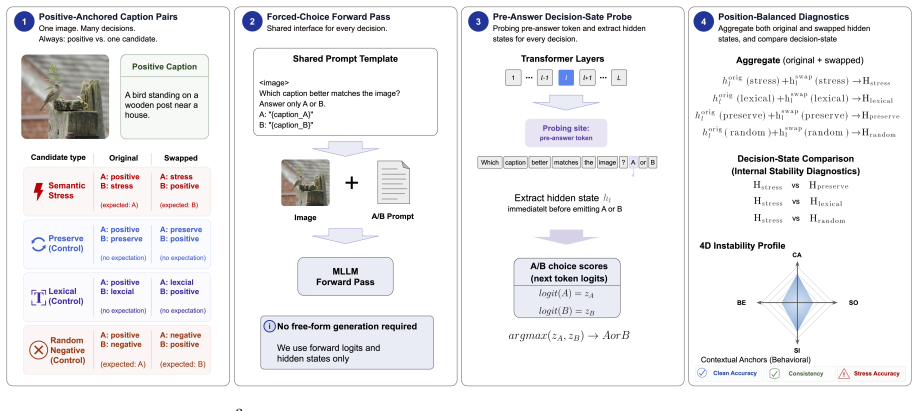
Across the three models, semantic-conflict candidates induce positive selected-layer excess displacement relative to meaning-preserving lexical controls in strict-correct trials, while random-negative comparisons remain model-dependent; the authors interpret the pattern as evidence of decision-state stress-sensitivity that is invisible to standard forced-choice accuracy.
What carries the argument
S³E (Structured Semantic Stress Evaluation): a positive-anchored A/B forced-choice setup that extracts hidden states at the pre-answer decision point and quantifies excess displacement of semantic-stress candidates over lexical controls.
If this is right
- Forced-choice correctness alone does not certify invariant internal decision geometry.
- Semantic stress produces positive selected-layer excess displacement over lexical controls in strict-correct trials.
- Comparisons against random negatives yield model-dependent patterns.
- The observed displacement is scoped to decision-state sensitivity rather than evidence of hallucination or downstream failure.
Where Pith is reading between the lines
- If the displacement measure generalizes, evaluations of multimodal models may need to incorporate internal-state probes in addition to behavioral accuracy.
- The pattern raises the possibility that models maintain multiple competing internal representations even when one wins the output selection.
- Extending the probe to open-ended generation or non-forced-choice settings could test whether the stress signal persists outside binary choice.
Load-bearing premise
Excess displacement in selected-layer hidden states at the pre-answer point specifically indexes decision-state stress rather than unrelated factors such as attention or token statistics.
What would settle it
A finding that semantic-stress candidates produce zero or negative excess displacement relative to lexical controls across the same strict-correct trials and models would falsify the central claim.
Figures

read the original abstract
Multimodal language models are typically evaluated through external behavior: selecting the correct image--text match, rejecting unsupported captions, or answering visual queries correctly. However, correct behavior alone does not show that the model's internal decision state remains stable under controlled semantic stress. We study this gap through S$^3$E (Structured Semantic Stress Evaluation), a framework for analyzing behavior-internal decoupling in multimodal language models. S$^3$E uses a positive-anchored A/B forced-choice setup in which an image-supported caption is contrasted against semantic stress candidates under both original and swapped option orders, while hidden states are extracted at the pre-answer decision state. We focus on strict-correct trials, where the model consistently selects the correct caption across both orders. Rather than treating arbitrary hidden-state variation as evidence of instability, we measure whether semantic-conflict candidates induce excess decision-state displacement relative to meaning-preserving controls. Across Qwen3VL, Gemma3, and InternVL3, semantic stress consistently produces positive selected-layer excess displacement over lexical controls despite correct forced-choice behavior, while comparisons against random negatives are model-dependent. We interpret this as a scoped decision-state stress-sensitivity signal rather than evidence of downstream failure or hallucination. Our results suggest that forced-choice correctness alone is not a sufficient certificate of invariant internal decision geometry.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the S³E (Structured Semantic Stress Evaluation) framework to probe whether correct forced-choice behavior in multimodal language models (Qwen3VL, Gemma3, InternVL3) conceals internal decision-state instability. It employs a positive-anchored A/B setup contrasting image-supported captions against semantic stress candidates (with order swaps), extracts hidden states at the pre-answer decision point, restricts analysis to strict-correct trials, and measures excess displacement relative to lexical and meaning-preserving controls. The central result is that semantic stress yields positive selected-layer excess displacement over lexical controls despite correct behavior, interpreted as a scoped stress-sensitivity signal rather than evidence of failure.
Significance. If the displacement measurements prove robust, the work would usefully demonstrate that external correctness is not a sufficient proxy for internal decision geometry stability in MLLMs. The explicit controls targeting token statistics and attention, combined with the strict-correct scoping and comparative (rather than absolute) framing, are methodological strengths that reduce circularity risks.
minor comments (2)
- Abstract: the phrase 'selected-layer excess displacement' is used without a brief parenthetical definition or pointer to the methods section where the metric, layer selection rule, and normalization are defined; this would aid immediate readability.
- Abstract: the model-dependent result versus random negatives is noted but not quantified (e.g., direction or magnitude); adding one sentence on the pattern would clarify the scope of the claim.
Simulated Author's Rebuttal
We thank the referee for the accurate summary of our S³E framework and for highlighting its methodological strengths, including the use of strict-correct scoping, positive-anchored A/B design, and comparative controls. We are pleased with the recommendation for minor revision.
Circularity Check
No significant circularity identified
full rationale
The paper introduces S³E as an explicit new framework with positive-anchored A/B forced-choice, strict-correct trial filtering, and comparative excess displacement against lexical and meaning-preserving controls. The central measurement is defined relative to those external controls rather than by self-reference or fitted parameters renamed as predictions. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked in the provided text; the derivation remains self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Hidden states extracted at the pre-answer decision state encode decision geometry that can be compared via displacement.
invented entities (1)
-
S³E framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Anonymous. 2026. A structured semantic-stress benchmark for multimodal model evaluation. Concurrent anonymous benchmark submission. An anonymized manuscript should be included in supplementary material
2026
-
[3]
Kawin Ethayarajh. 2019. https://doi.org/10.18653/v1/D19-1006 How contextual are contextualized word representations? comparing the geometry of BERT , ELMo , and GPT -2 embeddings . In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNL...
-
[5]
Atticus Geiger, Hanson Lu, Thomas Icard, and Christopher Potts. 2021. Causal abstractions of neural networks. In Advances in Neural Information Processing Systems
2021
-
[7]
Tianrui Guan, Fuxiao Liu, Xiyang Wu, Ruiqi Xian, Zongxia Li, Xiaoyu Liu, Xijun Wang, Lichang Chen, Furong Huang, Yaser Yacoob, Dinesh Manocha, and Tianyi Zhou. 2024. https://openaccess.thecvf.com/content/CVPR2024/html/Guan_HallusionBench_An_Advanced_Diagnostic_Suite_for_Entangled_Language_Hallucination_and_CVPR_2024_paper.html Hallusionbench: An advanced ...
2024
-
[8]
John Hewitt and Christopher D. Manning. 2019. A structural probe for finding syntax in word representations. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
2019
-
[9]
Cheng-Yu Hsieh, Jieyu Zhang, Zixian Ma, Aniruddha Kembhavi, and Ranjay Krishna. 2023. https://proceedings.neurips.cc/paper_files/paper/2023/hash/63461de0b4cb760fc498e85b18a7fe81-Abstract-Datasets_and_Benchmarks.html Sugarcrepe: Fixing hackable benchmarks for vision-language compositionality . In Advances in Neural Information Processing Systems, volume 36
2023
-
[10]
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. 2019. Similarity of neural network representations revisited. In Proceedings of the 36th International Conference on Machine Learning
2019
-
[11]
Yifan Li, Yifan Du, Kun Zhou, Jinpeng Wang, Xin Zhao, and Ji-Rong Wen. 2023. https://doi.org/10.18653/v1/2023.emnlp-main.20 Evaluating object hallucination in large vision-language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 292--305, Singapore. Association for Computational Linguistics
-
[13]
Yuanzhan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, Kai Chen, and Dahua Lin. 2024. Mmbench: Is your multi-modal model an all-around player? In European Conference on Computer Vision
2024
-
[14]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022. Locating and editing factual associations in gpt. In Advances in Neural Information Processing Systems
2022
-
[15]
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. 2017. Svcca: Singular vector canonical correlation analysis for deep learning dynamics and interpretability. In Advances in Neural Information Processing Systems
2017
-
[16]
Nina Rimsky, Nathan Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Matt Turner. 2024. Steering llama 2 via contrastive activation addition. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics
2024
-
[17]
Anna Rogers, Olga Kovaleva, and Anna Rumshisky. 2020. A primer in bertology: What we know about how bert works. Transactions of the Association for Computational Linguistics, 8:842--866
2020
-
[18]
Anna Rohrbach, Lisa Anne Hendricks, Kaylee Burns, Trevor Darrell, and Kate Saenko. 2018. https://doi.org/10.18653/v1/D18-1437 Object hallucination in image captioning . In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pages 4035--4045, Brussels, Belgium. Association for Computational Linguistics
-
[19]
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. 2022. https://doi.org/10.1109/CVPR52688.2022.00517 Winoground: Probing vision and language models for visio-linguistic compositionality . In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5238--5248
-
[20]
Jesse Vig, Sebastian Gehrmann, Yonatan Belinkov, Sharon Qian, Daniel Nevo, Yaron Singer, and Stuart Shieber. 2020. Investigating gender bias in language models using causal mediation analysis. In Advances in Neural Information Processing Systems
2020
-
[21]
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. 2024. Mm-vet: Evaluating large multimodal models for integrated capabilities. In Proceedings of the 41st International Conference on Machine Learning
2024
-
[22]
u ksekg \
Mert Y \"u ksekg \"o n \"u l, Federico Bianchi, Pratyusha Kalluri, Dan Jurafsky, and James Zou. 2023. https://openreview.net/forum?id=KRLUvxh8uaX When and why vision-language models behave like bags-of-words, and what to do about it? In The Eleventh International Conference on Learning Representations (ICLR)
2023
-
[24]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , pages =. 2022 , doi =
2022
-
[25]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =
Why is Winoground Hard? Investigating Failures in Visuolinguistic Compositionality , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages =. 2022 , doi =
2022
-
[26]
The Eleventh International Conference on Learning Representations (ICLR) , year =
When and Why Vision-Language Models Behave like Bags-of-Words, and What to Do About It? , author =. The Eleventh International Conference on Learning Representations (ICLR) , year =
-
[27]
Advances in Neural Information Processing Systems , volume =
SugarCrepe: Fixing Hackable Benchmarks for Vision-Language Compositionality , author =. Advances in Neural Information Processing Systems , volume =. 2023 , url =
2023
-
[28]
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =
Object Hallucination in Image Captioning , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =. 2018 , doi =
2018
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =
Evaluating Object Hallucination in Large Vision-Language Models , author =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages =. 2023 , doi =
2023
-
[30]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
HallusionBench: An Advanced Diagnostic Suite for Entangled Language Hallucination and Visual Illusion in Large Vision-Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[31]
Findings of the Association for Computational Linguistics: ACL 2024 , pages =
Aligning Large Multimodal Models with Factually Augmented RLHF , author =. Findings of the Association for Computational Linguistics: ACL 2024 , pages =. 2024 , doi =
2024
-
[32]
arXiv preprint arXiv:2410.03659 , year =
Unraveling Cross-Modality Knowledge Conflicts in Large Vision-Language Models , author =. arXiv preprint arXiv:2410.03659 , year =
-
[33]
arXiv preprint arXiv:2505.19616 , year =
Diagnosing and Mitigating Modality Interference in Multimodal Large Language Models , author =. arXiv preprint arXiv:2505.19616 , year =
-
[34]
How Contextual are Contextualized Word Representations? Comparing the Geometry of
Ethayarajh, Kawin , booktitle =. How Contextual are Contextualized Word Representations? Comparing the Geometry of. 2019 , doi =
2019
-
[35]
Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , address =
Anisotropy is Not Inherent to Transformers , author =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , address =. 2024 , doi =
2024
-
[36]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
Cross-modal Information Flow in Multimodal Large Language Models , author =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , year =
-
[37]
2026 , doi =
Kogilathota, Sai Akhil and G, Sripadha Vallabha E and Sun, Luzhe and Zhou, Jiawei , booktitle =. 2026 , doi =
2026
-
[38]
Same Answer, Different Representations: Hidden Instability in
Wani, Farooq Ahmad and Suglia, Alessandro and Saxena, Rohit and Gema, Aryo Pradipta and Kwan, Wai-Chung and Barez, Fazl and Bucarelli, Maria Sofia and Silvestri, Fabrizio and Minervini, Pasquale , journal =. Same Answer, Different Representations: Hidden Instability in. 2026 , url =
2026
-
[39]
arXiv preprint arXiv:2602.00710 , year =
Learning More from Less: Unlocking Internal Representations for Benchmark Compression , author =. arXiv preprint arXiv:2602.00710 , year =
-
[40]
arXiv preprint arXiv:2306.13394 , year =
MME: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models , author =. arXiv preprint arXiv:2306.13394 , year =
-
[41]
European Conference on Computer Vision , year =
MMBench: Is Your Multi-modal Model an All-around Player? , author =. European Conference on Computer Vision , year =
-
[42]
Proceedings of the 41st International Conference on Machine Learning , year =
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities , author =. Proceedings of the 41st International Conference on Machine Learning , year =
-
[43]
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
A Structural Probe for Finding Syntax in Word Representations , author =. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year =
2019
-
[44]
Transactions of the Association for Computational Linguistics , volume =
A Primer in BERTology: What We Know About How BERT Works , author =. Transactions of the Association for Computational Linguistics , volume =
-
[45]
Advances in Neural Information Processing Systems , year =
SVCCA: Singular Vector Canonical Correlation Analysis for Deep Learning Dynamics and Interpretability , author =. Advances in Neural Information Processing Systems , year =
-
[46]
Proceedings of the 36th International Conference on Machine Learning , year =
Similarity of Neural Network Representations Revisited , author =. Proceedings of the 36th International Conference on Machine Learning , year =
-
[47]
Advances in Neural Information Processing Systems , year =
Investigating Gender Bias in Language Models Using Causal Mediation Analysis , author =. Advances in Neural Information Processing Systems , year =
-
[48]
Advances in Neural Information Processing Systems , year =
Causal Abstractions of Neural Networks , author =. Advances in Neural Information Processing Systems , year =
-
[49]
Advances in Neural Information Processing Systems , year =
Locating and Editing Factual Associations in GPT , author =. Advances in Neural Information Processing Systems , year =
-
[50]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
Steering Llama 2 via Contrastive Activation Addition , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics , year =
-
[51]
2026 , note =
Anonymous , title =. 2026 , note =
2026
-
[52]
Xu, Quanxing and Tian, Yuhao and Zhou, Ling and Zhong, Xian and Huang, Xiaohua and Huang, Rubing and Lin, Chia-Wen , year =. 2605.19307 , archivePrefix=
-
[53]
Liang, Jiawei and Chen, Ruoyu and Jiao, Xianghao and Liang, Siyuan and Liu, Shiming and Zhang, Qunli and Hu, Zheng and Cao, Xiaochun , year =. Explaining multimodal. 2509.22415 , archivePrefix=
-
[54]
2026 , eprint =
Vision Inference Former: Sustaining Visual Consistency in Multimodal Large Language Models , author =. 2026 , eprint =
2026
-
[55]
Position: Uncertainty Quantification in
Chen, Tiejin and Da, Longchao and Liu, Xiaoou and Wei, Hua , year =. Position: Uncertainty Quantification in. 2605.19220 , archivePrefix=
-
[56]
arXiv preprint arXiv:2503.19786 , year =
Gemma 3 Technical Report , author =. arXiv preprint arXiv:2503.19786 , year =
-
[57]
arXiv preprint arXiv:2504.10479 , year =
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models , author =. arXiv preprint arXiv:2504.10479 , year =
-
[58]
arXiv preprint arXiv:2511.21631 , year =
Qwen3-VL Technical Report , author =. arXiv preprint arXiv:2511.21631 , year =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.