MedCUA-Bench: A Screenshot-Only Benchmark for Clinical Computer-Use Agents
Pith reviewed 2026-06-28 10:11 UTC · model grok-4.3
The pith
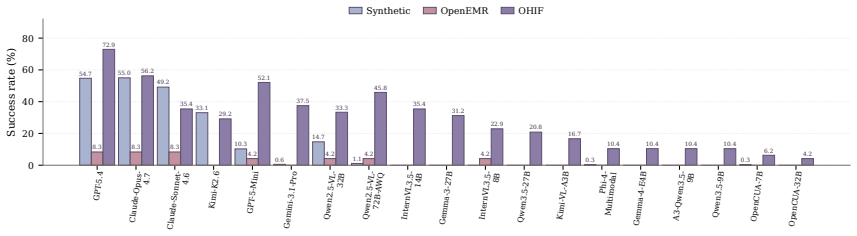
A benchmark of 18 clinical scenarios shows top AI agents complete only 54 percent of medical interface tasks and under 9 percent on real OpenEMR.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedCUA-Bench demonstrates that existing agents cannot reliably operate clinical software because medical interfaces differ in design, require specialized knowledge, and impose safety constraints that general web or desktop agents do not face, as shown by the low success rates across all tested models on both reconstructed and real systems.
What carries the argument
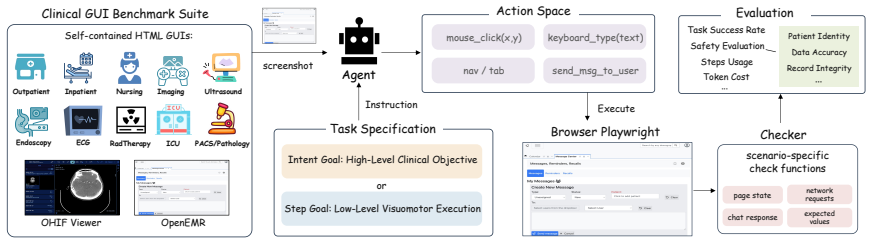
MedCUA-Bench, a screenshot-only interactive benchmark that supplies paired intent- and step-level goals and evaluates both task completion and five clinical safety dimensions on 18 scenarios reconstructed from real medical systems.
If this is right
- Agents must combine clinical reasoning with precise UI execution to reach usable reliability.
- Safety checks beyond task completion are required for any deployment in medical settings.
- Reproducible testbeds like this one enable targeted progress on domain-specific interfaces.
- Open-source agents lag closed-source ones by a wide margin on these tasks.
Where Pith is reading between the lines
- General-purpose agents trained on everyday web tasks will require substantial adaptation before they can handle specialized professional software.
- The gap between reconstructed and real-system performance points to missing real-world variability that future benchmarks should add.
- Low scores on intent-level goals suggest the main barrier is clinical understanding rather than pure screen navigation.
Load-bearing premise
The 18 scenarios built from product manuals and open-source medical systems accurately reflect the interfaces, knowledge needs, and safety rules of actual clinical software without missing constraints or adding artifacts.
What would settle it
Run the same 23 agents on a fresh installation of a medical system not used in the benchmark reconstruction and compare success rates and safety scores to those reported for OpenEMR.
Figures





read the original abstract
Computer-use agents could automate repetitive screen-based clinical work, but their reliability in medical graphical user interfaces remains largely unvalidated. Existing benchmarks focus on general web or desktop tasks and underrepresent medical software, which requires domain knowledge, exhibits markedly different UI design from mainstream applications, lacks public testing environments, and demands safety validation beyond task completion. We introduce MedCUA-Bench, an interactive benchmark for clinical computer-use agents. It covers 18 clinical scenarios across 10 medical domains, reconstructed from real product manuals and open-source medical systems to capture authentic clinical interfaces while avoiding licensing and privacy constraints. Each task ships with paired intent- and step-level goals to disentangle clinical reasoning from UI execution, and is evaluated by a deterministic checker over task completion and five clinical safety dimensions. Across 23 agents, the best closed-source model reaches 54.2% strict success, while all models remain below 9% on the real OpenEMR. Open-source agents average only 2.5%, with the best reaching 16.2%. MedCUA-Bench exposes the gap between current agents and reliable clinical software use, providing a reproducible testbed for future research.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MedCUA-Bench, a screenshot-only interactive benchmark for clinical computer-use agents consisting of 18 scenarios across 10 medical domains. Scenarios are reconstructed from product manuals and open-source systems to avoid licensing/privacy issues. Each task includes paired intent- and step-level goals and is scored by a deterministic checker on task completion plus five clinical safety dimensions. Evaluation of 23 agents shows the best closed-source model at 54.2% strict success, all models below 9% on real OpenEMR, and open-source agents averaging 2.5% (best 16.2%). The work positions the benchmark as exposing a reliability gap for future research.
Significance. If the reconstruction and checker are shown to be faithful, the benchmark would be a valuable contribution by supplying the first dedicated, reproducible testbed for clinical GUI agents in a domain where safety constraints and domain knowledge differ sharply from general web/desktop tasks. The explicit separation of intent vs. execution goals and the multi-dimensional safety scoring are positive design choices that could support targeted progress.
major comments (3)
- [§3] §3 (Benchmark Construction): No validation protocol is described for confirming that the 18 reconstructed scenarios preserve authentic UI state transitions, domain-specific validation rules, and safety edge cases from the source manuals and systems. Without side-by-side expert review or failure-mode coverage metrics, the headline claim that the benchmark exposes a genuine clinical gap cannot be assessed.
- [§4] §4 (Evaluation Protocol): The implementation of the deterministic checker and the precise operational definitions of the five clinical safety dimensions are not supplied. This directly affects interpretability of the strict-success metric and the reported 54.2% / <9% figures.
- [§5] §5 (Agent Evaluation): Selection criteria, prompting templates, and execution harness for the 23 agents are not detailed, so the comparability of closed-source vs. open-source results and the reproducibility of the 2.5% / 16.2% open-source numbers cannot be verified.
minor comments (2)
- [Table 2] Table 2: Column headers for safety dimensions should explicitly reference the definitions introduced in §4.1 to avoid ambiguity.
- [Figure 3] Figure 3: The OpenEMR comparison bar chart would be clearer with error bars or per-agent breakdowns rather than aggregate averages only.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and for recognizing the potential value of MedCUA-Bench as a dedicated testbed. We address each major comment point-by-point below, with planned revisions to improve transparency and reproducibility.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): No validation protocol is described for confirming that the 18 reconstructed scenarios preserve authentic UI state transitions, domain-specific validation rules, and safety edge cases from the source manuals and systems. Without side-by-side expert review or failure-mode coverage metrics, the headline claim that the benchmark exposes a genuine clinical gap cannot be assessed.
Authors: We agree that the current manuscript lacks an explicit validation protocol description. In the revised version we will add a dedicated subsection to §3 that documents the reconstruction and verification process, including how UI state transitions, domain rules, and safety edge cases were checked against the source manuals and open-source systems. This will include the internal review steps performed during construction. revision: yes
-
Referee: [§4] §4 (Evaluation Protocol): The implementation of the deterministic checker and the precise operational definitions of the five clinical safety dimensions are not supplied. This directly affects interpretability of the strict-success metric and the reported 54.2% / <9% figures.
Authors: The operational definitions and checker logic are essential for interpretability. We will expand §4 in the revision to provide the precise definitions of the five clinical safety dimensions and a detailed description (including pseudocode) of the deterministic checker. We will also release the checker implementation as supplementary open-source code to enable full reproducibility of the reported metrics. revision: yes
-
Referee: [§5] §5 (Agent Evaluation): Selection criteria, prompting templates, and execution harness for the 23 agents are not detailed, so the comparability of closed-source vs. open-source results and the reproducibility of the 2.5% / 16.2% open-source numbers cannot be verified.
Authors: We acknowledge that greater detail is required for reproducibility. The revised §5 will specify the selection criteria for the 23 agents, include the full prompting templates, and describe the execution harness in sufficient detail to allow independent replication of the closed-source and open-source comparisons. revision: yes
Circularity Check
Empirical benchmark paper with no derivations or fitted predictions exhibits no circularity.
full rationale
The manuscript introduces MedCUA-Bench as an empirical testbed for clinical agents, reporting success rates (e.g., 54.2% closed-source strict success) from direct evaluation on 18 reconstructed scenarios. No equations, parameter fits, predictions derived from subsets of data, or load-bearing self-citations appear in the abstract or described structure. All performance claims rest on explicit experimental runs against the benchmark and real OpenEMR, without any reduction of results to inputs by construction. This is the expected outcome for a pure benchmark paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reconstructed interfaces from product manuals and open-source systems capture authentic clinical UIs, domain knowledge, and safety requirements
Reference graph
Works this paper leans on
-
[1]
2024 , note =
Hong, Wenyi and Wang, Weihan and Lv, Qingsong and Xu, Jiazheng and Yu, Wenmeng and Ji, Junhui and Wang, Yan and Wang, Zihan and Zhang, Yuxuan and Lai, Hanyu and others , booktitle =. 2024 , note =
2024
-
[2]
2024 , note =
Zheng, Boyuan and Gou, Boyu and Kil, Jihyung and Sun, Huan and Su, Yu , booktitle =. 2024 , note =
2024
-
[3]
2024 , doi =
Niu, Runliang and Li, Jindong and Wang, Shiqi and Fu, Yali and Hu, Xiyu and Leng, Xueyuan and Kong, He and Chang, Yi and Wang, Qi , booktitle =. 2024 , doi =
2024
-
[4]
Proceedings of the 34th International Conference on Machine Learning (ICML) , series =
World of Bits: An Open-Domain Platform for Web-Based Agents , author =. Proceedings of the 34th International Conference on Machine Learning (ICML) , series =
-
[5]
International Conference on Learning Representations (ICLR) , year =
Reinforcement Learning on Web Interfaces Using Workflow-Guided Exploration , author =. International Conference on Learning Representations (ICLR) , year =
-
[6]
2022 , note =
Yao, Shunyu and Chen, Howard and Yang, John and Narasimhan, Karthik , booktitle =. 2022 , note =
2022
-
[7]
2023 , note =
Deng, Xiang and Gu, Yu and Zheng, Boyuan and Chen, Shijie and Stevens, Samuel and Wang, Boshi and Sun, Huan and Su, Yu , booktitle =. 2023 , note =
2023
-
[8]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle =. 2024 , note =
2024
-
[9]
2024 , note =
Koh, Jing Yu and Lo, Robert and Jang, Lawrence and Duvvur, Vikram and Lim, Ming Chong and Huang, Po-Yu and Neubig, Graham and Zhou, Shuyan and Salakhutdinov, Ruslan and Fried, Daniel , booktitle =. 2024 , note =
2024
-
[10]
2024 , note =
Xie, Tianbao and Zhang, Danyang and Chen, Jixuan and Li, Xiaochuan and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shin, Dongchan and Lei, Fangyu and others , booktitle =. 2024 , note =
2024
-
[11]
Bonatti, Rogerio and Zhao, Dan and Bonacci, Francesco and Dupont, Dillon and Abdali, Sara and Li, Yinheng and Lu, Yadong and Wagle, Justin and Koishida, Kazuhito and Bucker, Arthur and others , journal =
-
[12]
and Del Verme, Manuel and Marty, Tom and Boisvert, L
Drouin, Alexandre and Gasse, Maxime and Caccia, Massimo and Laradji, Issam H. and Del Verme, Manuel and Marty, Tom and Boisvert, L. Proceedings of the 41st International Conference on Machine Learning (ICML) , year =
-
[13]
2025 , eprint=
The BrowserGym Ecosystem for Web Agent Research , author=. 2025 , eprint=
2025
-
[14]
The Fourteenth International Conference on Learning Representations , year=
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows , author=. The Fourteenth International Conference on Learning Representations , year=
-
[15]
2024 , note =
Ma, Zeyao and Zhang, Bohan and Zhang, Jing and Yu, Jifan and Zhang, Xiaokang and Zhang, Xiaohan and Luo, Sijia and Wang, Xi and Tang, Jie , booktitle =. 2024 , note =
2024
-
[16]
Schmidgall, Samuel and Ziaei, Rojin and Harris, Carl and Reis, Eduardo and Jopling, Jeffrey and Moor, Michael , journal =
-
[17]
and Geng, Gloria and Park, Danny and Zou, James and Ng, Andrew Y
Jiang, Yixing and Black, Kameron C. and Geng, Gloria and Park, Danny and Zou, James and Ng, Andrew Y. and Chen, Jonathan H. , journal =
-
[18]
and Anwar, Zain and Sarfo-Gyamfi, Maame and Safranek, Conrad W
Khandekar, Nikhil and Jin, Qiao and Xiong, Guangzhi and Dunn, Soren and Applebaum, Serina S. and Anwar, Zain and Sarfo-Gyamfi, Maame and Safranek, Conrad W. and Anwar, Abid Ayaz and Zhang, Andrew and others , booktitle =. 2024 , note =
2024
-
[19]
2026 , eprint=
MedSPOT: A Workflow-Aware Sequential Grounding Benchmark for Clinical GUI , author=. 2026 , eprint=
2026
-
[20]
2024 , howpublished =
2024
-
[21]
Annals of Internal Medicine , volume =
Allocation of Physician Time in Ambulatory Practice: A Time and Motion Study in 4 Specialties , author =. Annals of Internal Medicine , volume =. 2016 , doi =
2016
-
[22]
and Beasley, John W
Arndt, Brian G. and Beasley, John W. and Watkinson, Michelle D. and Temte, Jonathan L. and Tuan, Wen-Jan and Sinsky, Christine A. and Gilchrist, Valerie J. , journal =. Tethered to the. 2017 , doi =
2017
-
[23]
Mayo Clinic Proceedings , volume =
Relationship Between Clerical Burden and Characteristics of the Electronic Environment With Physician Burnout and Professional Satisfaction , author =. Mayo Clinic Proceedings , volume =. 2016 , doi =
2016
-
[24]
and Zhang, Hao and Stoica, Ion , booktitle =
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , note =
2023
-
[25]
2026 , eprint=
HealthAdminBench: Evaluating Computer-Use Agents on Healthcare Administration Tasks , author=. 2026 , eprint=
2026
-
[26]
2026 , howpublished =
2026
-
[27]
arXiv preprint arXiv:2507.20534 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and others , journal =
-
[29]
Wang, Weiyun and Gao, Zhangwei and Gu, Lixin and Pu, Hengjun and Cui, Long and Wei, Xingguang and Liu, Zhaoyang and Jing, Linglin and Ye, Shenglong and Shao, Jie and others , journal =
-
[30]
arXiv preprint arXiv:2503.19786 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
arXiv preprint arXiv:2504.07491 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
2025 , howpublished =
2025
-
[33]
Structured Distillation of Web Agent Capabilities Enables Generalization
Structured Distillation of Web Agent Capabilities Enables Generalization , author =. arXiv preprint arXiv:2604.07776 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Wang, Xinyuan and Wang, Bowen and Lu, Dunjie and Yang, Junlin and Xie, Tianbao and Wang, Junli and Deng, Jiaqi and Guo, Xiaole and Xu, Yiheng and Wu, Chen Henry and others , journal =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.