ConMem: Structured Memory-Guided Adaptation in Training-Free Multi-Agent Systems
Pith reviewed 2026-06-27 18:40 UTC · model grok-4.3
The pith
ConMem distills agent interaction histories into a graph of memory cards that coordinate strategies at runtime without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
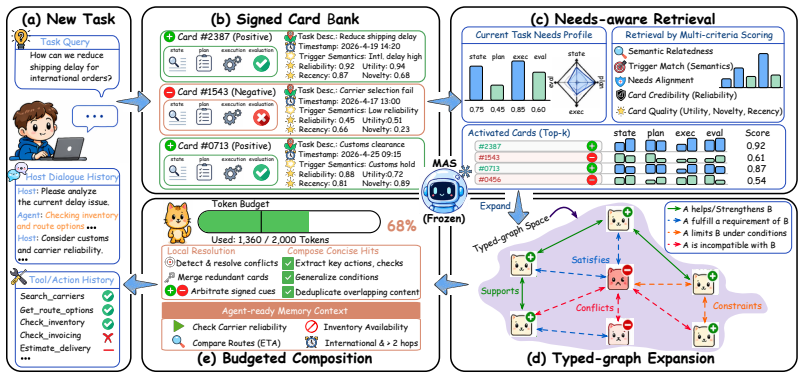
ConMem distills historical interaction trajectories into structured memory cards to capture reusable strategies and cues, organizing them into a relation-aware memory graph. At runtime, ConMem retrieves cards according to task needs and coordinates them through the card graph to resolve strategy conflicts and recover their dependencies, yielding structured and relation-aware guidance that enables robust, lightweight adaptation in multi-agent systems without additional training.
What carries the argument
The relation-aware memory graph, which stores distilled memory cards and supports their retrieval and coordination to resolve conflicts and recover dependencies.
If this is right
- Consistent gains over prior memory architectures on multiple benchmarks and mainstream MAS designs.
- Pruning of more than 50 percent of expanded candidate cards while preserving effectiveness.
- Reduction of planning overhead by over 80 percent through graph-guided retrieval.
- Lightweight, training-free operation that integrates with existing multi-agent frameworks.
Where Pith is reading between the lines
- If the graph successfully captures strategy relations, the same structure could be tested in single-agent settings to model an agent's own conflicting plans.
- Continuous addition of new trajectories to the graph might support agents in changing environments without periodic retraining.
- The emphasis on explicit relation modeling suggests experiments that compare graph coordination against volume-based memory alone in high-conflict collaboration tasks.
Load-bearing premise
Historical interaction trajectories contain cleanly distillable reusable strategies and cues whose relations form a graph that can reliably resolve conflicts and recover dependencies at runtime without noise or extra supervision.
What would settle it
Running ConMem on a standard multi-agent benchmark where the memory graph produces no performance gain over a simple retrieval baseline or where coordination steps increase rather than reduce planning time.
Figures



read the original abstract
Recent advances have improved the adaptive capabilities of LLM-based multi-agent systems (MAS) through memory-, skill-, and learning-based approaches, yet these approaches remain challenged by noisy trajectories, insufficient modeling of memory-skill relations, and reliance on additional training or high-quality supervision. To address these limitations, we propose ConMem, a relation-aware and training-free framework that enables efficient multi-agent adaptation through cross-experience coordination. Specifically, ConMem distills historical interaction trajectories into structured memory cards to capture reusable strategies and cues, organizing them into a relation-aware memory graph. At runtime, ConMem retrieves cards according to task needs and coordinates them through the card graph to resolve strategy conflicts and recover their dependencies. Combined, these modules yield structured and relation-aware guidance, enabling robust, lightweight adaptation in multi-agent systems without additional training. Extensive experiments across multiple benchmarks and mainstream MAS architectures show consistent gains over existing memory architectures, with improved inference-time efficiency through pruning more than 50% of expanded candidates and reducing planning overhead by over 80%. Our codes are available at https://anonymous.4open.science/r/ConMemCode
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes ConMem, a relation-aware and training-free framework for LLM-based multi-agent systems. It distills historical interaction trajectories into structured memory cards capturing reusable strategies and cues, organizes them into a relation-aware memory graph, and at runtime retrieves cards by task needs while coordinating via the graph to resolve strategy conflicts and recover dependencies. The approach is claimed to yield robust adaptation without additional training or high-quality supervision, with experiments across benchmarks and mainstream MAS architectures reporting consistent gains over existing memory methods plus efficiency improvements (pruning >50% of expanded candidates and reducing planning overhead by >80%). Code is stated to be available.
Significance. If the central claims hold, ConMem would offer a lightweight alternative to training- or supervision-heavy memory and skill-based adaptation methods in multi-agent systems, directly addressing noisy trajectories and insufficient relation modeling. The reported efficiency gains and code availability would strengthen its practical value for reproducible follow-up work.
major comments (2)
- [Abstract] Abstract: the central claims of 'consistent gains' and 'improved inference-time efficiency' (pruning >50% candidates, >80% overhead reduction) are asserted without any methods details, benchmarks, baselines, error bars, or verification steps supplied in the text, so the soundness of the empirical support for the framework cannot be assessed.
- [Abstract] Abstract (and implied methods): the framework's core mechanism—distilling trajectories into 'structured memory cards' and extracting relations for the memory graph—is described at a high level but without any specification of the distillation process, relation extraction procedure, or handling of noise, leaving the weakest assumption (cleanly distillable reusable strategies without supervision or noise propagation) unaddressed and load-bearing for the 'robust, lightweight adaptation' claim.
minor comments (1)
- [Abstract] The abstract mentions 'extensive experiments across multiple benchmarks and mainstream MAS architectures' but does not name them or provide any quantitative tables/figures in the visible text.
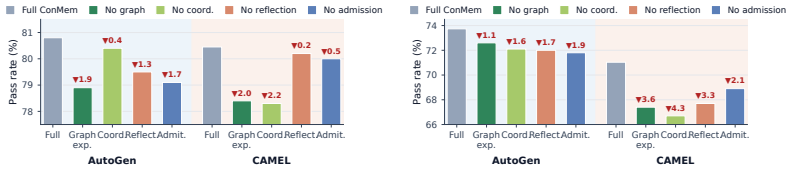
Simulated Author's Rebuttal
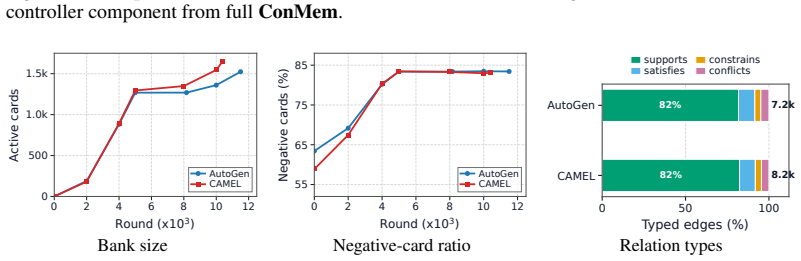
We thank the referee for the detailed feedback on the abstract and framework description. The manuscript body contains the requested experimental and methodological details, but we agree the abstract can be strengthened for standalone clarity. We respond to each major comment below.
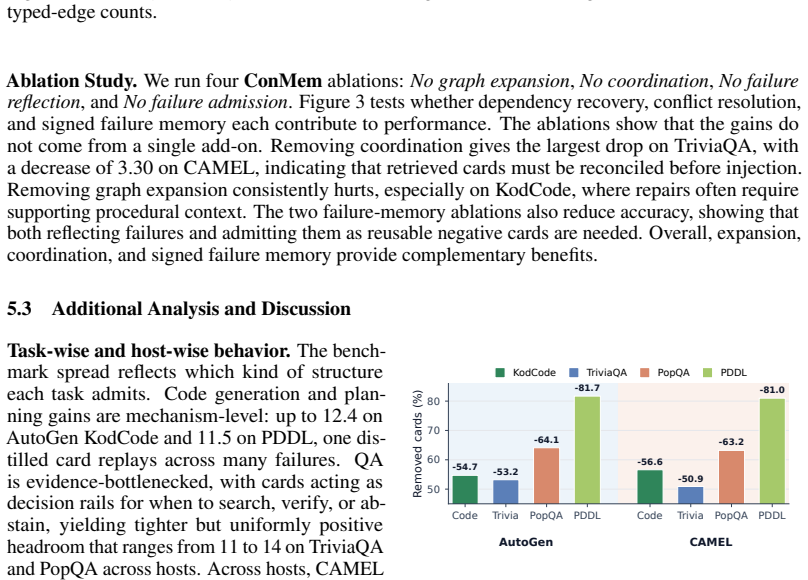
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of 'consistent gains' and 'improved inference-time efficiency' (pruning >50% candidates, >80% overhead reduction) are asserted without any methods details, benchmarks, baselines, error bars, or verification steps supplied in the text, so the soundness of the empirical support for the framework cannot be assessed.
Authors: The abstract is a concise summary; the full manuscript contains a dedicated Experiments section that specifies the benchmarks, baselines, metrics (including error bars), and verification procedures for both performance gains and efficiency claims (candidate pruning and planning overhead). These sections directly support the reported results. To improve the abstract's self-contained nature, we will revise it to include brief references to the evaluation protocol and key quantitative outcomes. revision: yes
-
Referee: [Abstract] Abstract (and implied methods): the framework's core mechanism—distilling trajectories into 'structured memory cards' and extracting relations for the memory graph—is described at a high level but without any specification of the distillation process, relation extraction procedure, or handling of noise, leaving the weakest assumption (cleanly distillable reusable strategies without supervision or noise propagation) unaddressed and load-bearing for the 'robust, lightweight adaptation' claim.
Authors: The abstract summarizes at a high level by design. The Methods section details the distillation procedure for creating structured memory cards from trajectories, the relation extraction process for building the memory graph, and explicit mechanisms for mitigating noise (via cue filtering and dependency recovery in the graph). These elements directly address the challenges of noisy trajectories and insufficient relation modeling without requiring supervision or training. The design choices are load-bearing but are substantiated in the body; we can add a short clarifying sentence to the abstract if helpful. revision: partial
Circularity Check
No circularity: framework proposal with no equations or self-referential reductions
full rationale
The paper presents ConMem as a novel training-free framework that distills trajectories into memory cards organized in a relation-aware graph for runtime retrieval and coordination. No equations, fitted parameters, predictions, or self-citations appear in the provided text that would reduce any claimed output to an input by construction. The description is architectural and procedural rather than a derivation chain; the central claims rest on the design choices themselves, not on re-labeling fitted quantities or importing uniqueness via author citations. This matches the default expectation of a non-circular paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical interaction trajectories contain reusable strategies and cues that can be distilled into structured memory cards without significant loss or noise.
invented entities (2)
-
Structured memory cards
no independent evidence
-
Relation-aware memory graph
no independent evidence
Reference graph
Works this paper leans on
-
[1]
CAMEL: Communicative agents for “mind” exploration of large scale language model society
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. CAMEL: Communicative agents for “mind” exploration of large scale language model society. InAdvances in Neural Information Processing Systems, 2023. URL https: //arxiv.org/abs/2303.17760
Pith/arXiv arXiv 2023
-
[2]
(2024) Chatdev: Communicative agents for software development
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. ChatDev: Communicative agents for software development. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, pages 15174–15186. Association for Computatio...
-
[3]
MetaGPT: Meta programming for a multi-agent collaborative framework
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and Jürgen Schmidhuber. MetaGPT: Meta programming for a multi-agent collaborative framework. InInternational Conference on Learning Represen- tations, 2024. URL htt...
2024
-
[4]
White, Doug Burger, and Chi Wang
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. AutoGen: Enabling next-gen LLM applications via multi-agent conversation. InConference on Language Modeling, 2024. URLhttps://arxiv.org/abs/2308.08155
Pith/arXiv arXiv 2024
-
[5]
Chen Qian, Zihao Xie, Yifei Wang, Wei Liu, Kunlun Zhu, Hanchen Xia, Yufan Dang, Zhuoyun Du, Weize Chen, Cheng Yang, Zhiyuan Liu, and Maosong Sun. Scaling large-language-model- based multi-agent collaboration.arXiv preprint arXiv:2406.07155, 2024. doi: 10.48550/arXiv. 2406.07155. URLhttps://arxiv.org/abs/2406.07155
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[6]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1–22, 2023. doi: 10.1145/3586183.3606763. URL https://dl.acm.org/doi/10. 1145/3586183.3606763
-
[7]
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in LLM agents via incremental multi-turn interactions.arXiv preprint arXiv:2507.05257, 2025. URL https://arxiv.org/ abs/2507.05257
Pith/arXiv arXiv 2025
-
[8]
Gaodan Fang, Vatche Isahagian, K. R. Jayaram, Ritesh Kumar, Vinod Muthusamy, Punleuk Oum, and Gegi Thomas. Trajectory-informed memory generation for self-improving agent systems. arXiv preprint arXiv:2603.10600, 2026. URLhttps://arxiv.org/abs/2603.10600
arXiv 2026
-
[10]
URLhttps://arxiv.org/abs/2601.02553
-
[11]
Lei Wei, Xiao Peng, Xu Dong, Niantao Xie, and Bin Wang. FadeMem: Biologically-inspired forgetting for efficient agent memory.arXiv preprint arXiv:2601.18642, 2026. URL https: //arxiv.org/abs/2601.18642
arXiv 2026
-
[12]
V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.Transactions on Machine Learning Research, 2024. URL https://openreview. net/forum?id=ehfRiF0R3a
2024
-
[13]
Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. MemSkill: Learning and evolving memory skills for self-evolving agents.arXiv preprint arXiv:2602.02474, 2026. URLhttps://arxiv.org/abs/2602.02474. 10
Pith/arXiv arXiv 2026
-
[14]
Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025
Runnan Fang, Yuan Liang, Xiaobin Wang, Jialong Wu, Shuofei Qiao, Pengjun Xie, Fei Huang, Huajun Chen, and Ningyu Zhang. Memp: Exploring agent procedural memory.arXiv preprint arXiv:2508.06433, 2025. URLhttps://arxiv.org/abs/2508.06433
Pith/arXiv arXiv 2025
-
[15]
A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-MEM: Agentic memory for LLM agents.arXiv preprint arXiv:2502.12110, 2025. URL https: //arxiv.org/abs/2502.12110
Pith/arXiv arXiv 2025
-
[16]
MIRIX: Multi-agent memory system for LLM-based agents.arXiv preprint arXiv:2507.07957, 2025
Yu Wang and Xi Chen. MIRIX: Multi-agent memory system for LLM-based agents.arXiv preprint arXiv:2507.07957, 2025. URLhttps://arxiv.org/abs/2507.07957
Pith/arXiv arXiv 2025
-
[17]
G-Memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025
Guibin Zhang, Muxin Fu, Guancheng Wan, Miao Yu, Kun Wang, and Shuicheng Yan. G-Memory: Tracing hierarchical memory for multi-agent systems.arXiv preprint arXiv:2506.07398, 2025. URLhttps://arxiv.org/abs/2506.07398
arXiv 2025
-
[18]
Taeyun Roh, Wonjune Jang, Junha Jung, and Jaewoo Kang. CLAG: Adaptive memory organization via agent-driven clustering for small language model agents.arXiv preprint arXiv:2603.15421, 2026. URLhttps://arxiv.org/abs/2603.15421
Pith/arXiv arXiv 2026
-
[19]
Remember Me, Refine Me: A Dynamic Procedural Memory Framework for Experience-Driven Agent Evolution
Zouying Cao, Jiaji Deng, Li Yu, Weikang Zhou, Zhaoyang Liu, Bolin Ding, and Hai Zhao. Remember me, refine me: A dynamic procedural memory framework for experience-driven agent evolution.arXiv preprint arXiv:2512.10696, 2025. doi: 10.48550/arXiv.2512.10696. URLhttps://arxiv.org/abs/2512.10696
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2512.10696 2025
-
[20]
Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma
Sikuan Yan, Xiufeng Yang, Zuchao Huang, Ercong Nie, Zifeng Ding, Zonggen Li, Xiaowen Ma, Jinhe Bi, Kristian Kersting, Jeff Z. Pan, Hinrich Schütze, V olker Tresp, and Yunpu Ma. Memory-R1: Enhancing large language model agents to manage and utilize memories via reinforcement learning.arXiv preprint arXiv:2508.19828, 2025. URL https://arxiv.org/ abs/2508.19828
Pith/arXiv arXiv 2025
-
[21]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, Feiyu Xiong, Yutao Qi, Bo Tang, and Muning Wen. MemRL: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026. URLhttps://arxiv.org/abs/2601.03192
Pith/arXiv arXiv 2026
-
[22]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-R1: Training LLMs to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516, 2025. URL https://arxiv.org/ abs/2503.09516
Pith/arXiv arXiv 2025
-
[23]
MemEvolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025
Guibin Zhang, Haotian Ren, Chong Zhan, Zhenhong Zhou, Junhao Wang, He Zhu, Wangchun- shu Zhou, and Shuicheng Yan. MemEvolve: Meta-evolution of agent memory systems.arXiv preprint arXiv:2512.18746, 2025. URLhttps://arxiv.org/abs/2512.18746
Pith/arXiv arXiv 2025
-
[24]
Meta context engineering via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026
Haoran Ye, Xuning He, Vincent Arak, Haonan Dong, and Guojie Song. Meta context engineering via agentic skill evolution.arXiv preprint arXiv:2601.21557, 2026. URL https://arxiv.org/abs/2601.21557
arXiv 2026
-
[25]
Agentic context engineering: Evolving contexts for self-improving language models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models. InInternational Conference on Learning Representations, 2026. URL https://arxiv.org/abs/2...
Pith/arXiv arXiv 2026
-
[26]
LatentMem: Customizing latent memory for multi-agent systems.arXiv preprint arXiv:2602.03036, 2026
Muxin Fu, Xiangyuan Xue, Yafu Li, Zefeng He, Siyuan Huang, Xiaoye Qu, Yu Cheng, and Yang Yang. LatentMem: Customizing latent memory for multi-agent systems.arXiv preprint arXiv:2602.03036, 2026. URLhttps://arxiv.org/abs/2602.03036
arXiv 2026
-
[27]
Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. InProceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1601–1611, 2017. doi: 10.18653/v1/P17-1147. URLhttps://aclanthology.org/P17-1147/. 11
-
[28]
In: Rogers, A., Boyd- Graber, J., Okazaki, N
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Daniel Khashabi, and Hannaneh Ha- jishirzi. When not to trust language models: Investigating effectiveness of parametric and non-parametric memories. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics, pages 9802–9822. Association for Computational Linguistics, 202...
-
[29]
KodCode: A diverse, challenging, and verifiable synthetic dataset for coding
Zhangchen Xu, Yang Liu, Yueqin Yin, Mingyuan Zhou, and Radha Poovendran. KodCode: A diverse, challenging, and verifiable synthetic dataset for coding. InFindings of the Association for Computational Linguistics: ACL 2025, pages 6980–7008. Association for Computational Linguistics, 2025. doi: 10.18653/v1/2025.findings-acl.365. URL https://aclanthology. org...
-
[30]
PDDLGym: Gym environments from PDDL problems.arXiv preprint arXiv:2002.06432, 2020
Tom Silver and Rohan Chitnis. PDDLGym: Gym environments from PDDL problems.arXiv preprint arXiv:2002.06432, 2020. doi: 10.48550/arXiv.2002.06432. URL https://arxiv. org/abs/2002.06432. ICAPS 2020 PRL Workshop
-
[31]
JoyAgent-JDGenie: Technical report on the GAIA.arXiv preprint arXiv:2510.00510, 2025
Jiarun Liu, Shiyue Xu, Shangkun Liu, Yang Li, Wen Liu, Min Liu, Xiaoqing Zhou, Hanmin Wang, Shilin Jia, Zhen Wang, Shaohua Tian, Hanhao Li, Junbo Zhang, Yongli Yu, Peng Cao, and Haofen Wang. JoyAgent-JDGenie: Technical report on the GAIA.arXiv preprint arXiv:2510.00510, 2025. URLhttps://arxiv.org/abs/2510.00510
arXiv 2025
-
[32]
OAgents: An empirical study of building effective agents
He Zhu, Tianrui Qin, King Zhu, Heyuan Huang, Yeyi Guan, Jinxiang Xia, Hanhao Li, Yi Yao, Ningning Wang, Pai Liu, Tianhao Peng, Xin Gui, Li Xiaowan, Yuhui Liu, Xiangru Tang, Jian Yang, Ge Zhang, Xitong Gao, Yuchen Eleanor Jiang, Changwang Zhang, Jun Wang, Jiaheng Liu, and Wangchunshu Zhou. OAgents: An empirical study of building effective agents. In Findin...
2025
-
[33]
doi: 10.18653/v1/2025.findings-emnlp.720. URL https://aclanthology.org/2025. findings-emnlp.720/. 12 Appendix Contents •A Additional Methodological Details –A.1 Update-Side Implementation Notes –A.2 Use-Side Implementation Notes –A.3 Profile Calibration, Run Configuration, and Evaluation Protocol •B Baseline Descriptions and Evaluation Settings –B.1 Compa...
-
[34]
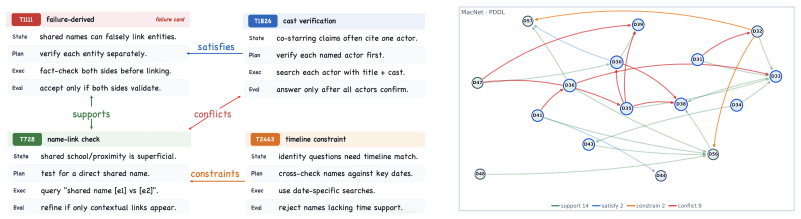
Memory structure:HowConMemorganizes historical interactions into a structured and relation-aware graph, making procedural dependencies explicit
-
[35]
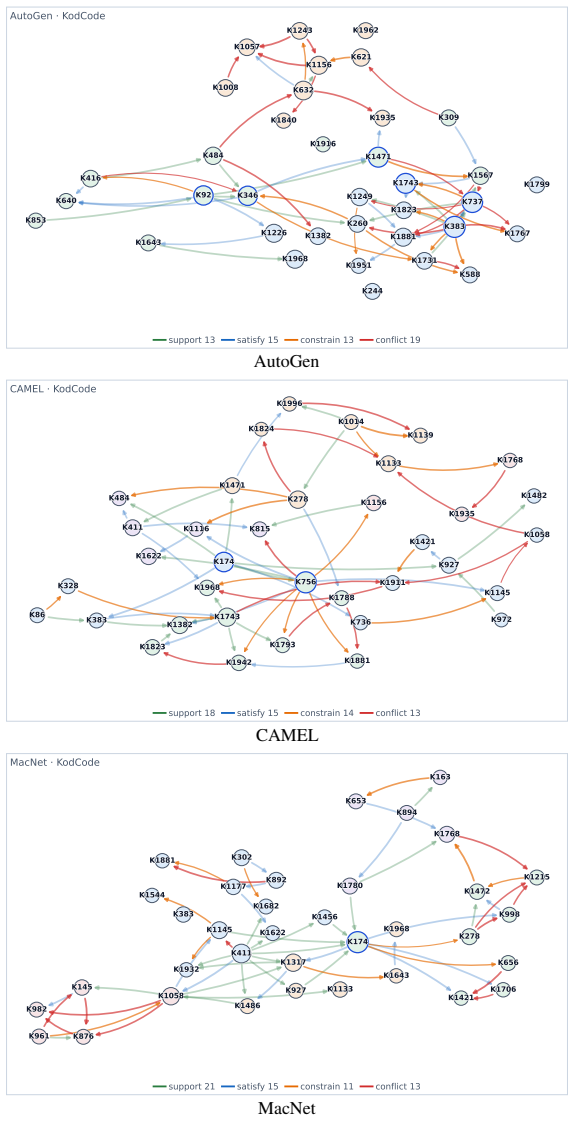
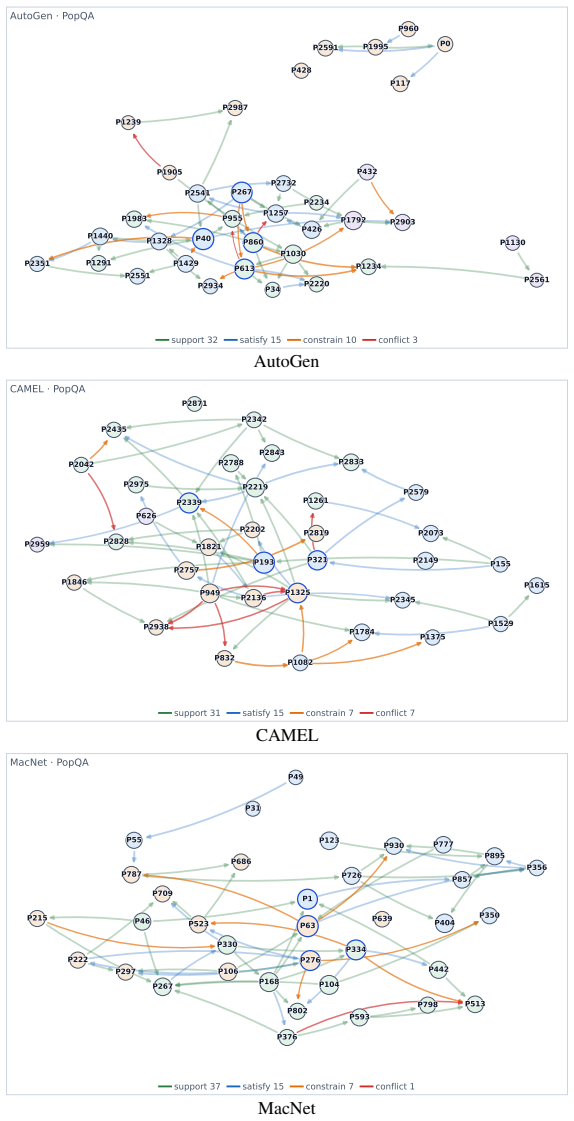
Cross-host consistency:Comparison across AutoGen, CAMEL, and MacNet shows which procedural strategies are reused or adapted under different host architectures. 17
-
[36]
Coordination mechanism validation:Constrains/conflicts edges indicate where the coor- dination module actively resolves conflicts or enforces precondition ordering
-
[37]
retrieving neighbors
Benchmark-specific patterns:QA panels are positive-edge-heavy, while KodCode and PDDL expose more control edges and therefore stress conflict and constraint handling. Summary:Figures 7–10 provide visual confirmation ofConMem’s relation-aware memory organi- zation. They show that the relative balance of positive and control edges changes across benchmarks ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.